- 2023-07-02
c8019ecedf64
我叫肖德茂,今天开始我搬到了L市,是为了一个人。她和我是大学同学,我暗恋了她六年,一直没有鼓起勇气,家庭和工作上的事情也抽不开身,但是现在,我毕业之后呆的第一家公司,破产了,我的家里人跟我闹了很大的矛盾,而她也刚结束一段感情。我想,这也许是个机会,我就独自一人来到了这里。可我没敢告诉艾莉——我失去了工作、和家里闹翻、又看到艾丽分手才敢来到这里的。所以我独自一人租了一个小房子,这里环境很好,空气清新
- F12去水印教程:使用开发者工具隐藏网页背景水印
Lin Hsüeh-ch'in
实用工具经验分享笔记
F12去水印教程:使用开发者工具隐藏网页背景水印原创文章,转载请注明出处一、前言在浏览某些网页新闻或文档时,网站为了防止内容被随意复制或截图,常常会在页面上添加水印(如背景图、半透明遮罩、文字层等),影响阅读体验。虽然这些措施有其合理性,但有时我们仅用于学习和临时查看,希望去掉水印以便更好地阅读内容。本文将介绍如何使用浏览器的开发者工具(F12)来临时去除网页背景水印,并提供一些进阶方法供参考。二
- 2019-08-04
chen晨辰
团建活动有趣一点就这么难吗?一说起”团建“,每个人都能说出几个方案:挑一个周末,在离公司不远的公园搞拓展活动;选一个晚上,公司出钱,一群人吃饭唱K;租一个别墅,全公司的人住进去搞轰趴。虽然这些活动听起来了无新意,但只要不占用员工的休息时间,不用员工掏钱,不听老板没完没了的讲话,员工在一起吃吃喝喝、说说笑笑,已经是及格的团建了。但也有不信邪的老板和HR,每次团建都能成功地得罪全公司的员工。这种起反作
- 2021-07-14 再次下定离职的决心
GuangHui
昨天公司大boss因为和BU签战略合作协议,来我目前驻场的公司了,我并没有参加会议,所以也就没有和大boss碰上面。而会后boss通过其他同事传话给我,说还是希望我留下来。同事也说了,毕竟boss已经找我当面谈过话了。我又不是什么高层领导,只是一个基层员工,boss不可能为了我的离去反复找我谈话,那样岂不是搞得好像离开,我公司就不能转动一样。我深知大boss的意思背后,还是项目经理和上级主管的意思
- 日更72–无关年龄
不等等
公司的保洁阿姨,活干的漂亮,人品也好,新来的小姑娘衣服换的勤每天都不重样的花枝招展。阿姨说:这姑娘天天的换衣服,省的让别人不知道她家有钱!女人的嫉妒心是不分年龄大小的,对女人的评头论足可能只会跳过自己的女儿吧。又说到陈叔,想起来去年一段时间天天与我作对,跟我爸同岁,但是给我涨工资没给他涨,不知道谁从中间挑拨的,天天给我找不痛快。人小气起来也是不分年龄的,才不管是不是公平,对方是不是才跟你女儿一样大
- 《赌在技术开发上》我的企业家精神坚信一定成功,拼命努力奋进
晋慧绍成
我是宁波百事达工具/格雷公司/宁波盛和塾诚敬组,格雷读书会同心队何绍成,这是我每天至少一篇文字的第845篇文字(2021/11/13)《赌在技术开发上》我的企业家精神坚信一定成功,拼命努力奋进摘要在开发这些新产品的时候,我们绝不半途而废。哪怕要花5年,10年时间,我们也绝不放弃,愚直地追求成功,一旦相信能够成功,就全力追求,坚韧不拔,直到成功。想要开展新事业,尝试了一下,遇到困难就撒手的人很多,如
- 「Tokens是胡扯」?Mamba作者炮轰Transformer,揭秘AI模型致命缺陷 | AI早报
未来世界2099
AI日报人工智能transformer深度学习业界资讯
1、OpenAI疯狂挖角反击!Meta华人科学家+马斯克三员大将集体跳槽2、清华&NTU突破性研究:仅需2张图,AI即可重构3D空间认知3、极智嘉港股上市首日破发!清华系机器人公司市值153亿引关注4、星海图融资超1亿美金!美团、今日资本领投,估值暴涨3倍5、华人团队用RL打造AIAgent,种子轮狂揽1200万美元融资6、Skywork-R1V3.0震撼开源:高考数学142分,多学科推理能力直逼
- 读活法第三十八天
格雷_Jacky张
宁波市北仑格雷塑料制品有限公司同心队张镇第三章磨练灵魂、提升心志——时时反省,不忘磨砺人格上一小节讲了作为领导者,要德重于才。而本小节中稻盛先生告诉我们,如何才能“有德”。对于领导者而言,要有基于明确哲学的深沉厚重人格才算“有德”。即:谦虚之心、内省之心、抑制自我的克己之心、坚持正义的勇气、持续自我磨砺的慈悲之心。这里的哲学即:明白“作为人,何为正确?”的正确的为人之道,即:道德心——不可说谎,要
- 2024最新外卖CPS分销微信小程序源码【前端+后台+数据库+分销功能】
云深不知处㊣
源码专区微信小程序小程序外卖CPS分销微信小程序源码CPS分销微信小程序源码
内容目录一、详细介绍二、效果展示三、源代码下载地址一、详细介绍外卖侠CPS全套源码是一款为外卖平台提供分销功能的微信小程序。用户可以通过你的链接去领取外卖红包,然后去下单点外卖,既能省钱,又能获得佣金。该小程序带有商城、影票、吃喝玩乐等多个模块,适合不同用户的需求。外卖CPS的势头猛得一塌糊涂,被称为23年最大的红利之一,也被称为2023最佳小白可实操项目。外卖公司的广告预算持续增加,因为比传统广
- 《史蒂夫·乔布斯传》读书笔记之二——苹果诞生
格桑德吉1024
AppleI1975年,沃兹尼亚克设计了一个蓝盒子——这就是AppleI,只用在键盘上按几个键,那些字母就可以显示在屏幕上。乔布斯看到这个神奇的蓝盒子时,大吃一惊,连问了他好几个问题:这台电脑能联网吗?是否有可能添加一块磁盘作为存储器?乔布斯打了几个电话,免费从英特尔得到了一些芯片(DRAM),他知道怎么跟销售代表说话。而沃兹不一样,他是个害羞的孩子。乔布斯和沃兹一起参加了家酿计算机俱乐部的会议,
- AI新贵崛起:Perplexity的估值为何两月飙升至180亿美元?
在美的苦命程序员
人工智能
在AI搜索领域的激烈竞争中,Perplexity的崛起令人瞩目。这家AI搜索初创公司在短短两个月内,估值从140亿美元激增至180亿美元,成为挑战谷歌的“潜力股”。这背后究竟有哪些驱动力?从商业化路径到未来市场布局,Perplexity的成功揭示了AI创业领域的新机遇和挑战。一、从5亿美元到180亿美元,Perplexity的惊人估值飙升Perplexity的估值在18个月内完成了五轮融资,尤其在
- 搭建网站选择阿里云服务器,云·速成美站,云·企业官网哪个更好?
阿里云最新优惠和活动汇总
很多企业和公司上云的第一步就是搭建自己的官网,搭建自己的官网是能够让客户看到公司的相关产品、服务和专业程度,很多对客户有价值的信息,都要通过企业网站传递到客户那里。随着阿里云服务器和建站产品的知名度越来越高,越来越多的用户选择阿里云的产品来搭建自己的官网。阿里云服务器,云·速成美站,云·企业官网最新优惠活动分享:阿里云新人特惠活动:云服务器0.6折起,云·速成美站500.00/年起,云·企业官网4
- 职场乾坤之坤卦
人生百态千悟
乾卦对应着天、男性、阳刚等,强调自强不息。坤卦对应着地、女性、阴柔等,强调厚德载物。坤卦为64卦中的第二卦,有了乾、坤这第一、第二卦,才有了后续的62卦。也因为有了天、地,便有了顶天立地创业的空间。图一01地位初爻为“履霜,坚冰至”。作为新入职的员工,为了尽快掌握公司的制度、工作内容,适应其节奏及方式等,必须要有举一反三的能力。当脚踩到初现的霜冻,那么就应该知道,很快深冬就要来临,厚厚的积冰即将出
- 2/5 碎碎念
卓橙爱读书
阿错这几天感冒,喉咙有点痛。感觉喉咙一痛就让他化身小公举了,这个不想吃,那个没胃口。想想自己怀孕时犯恶心依然狂吃海塞,我真是汉子心妹子身。也可能是因为我没给他煮稀饭端烂面条,所以控诉我了。但我怀孕时在公司没胃口每天都吃的辣酱拌饭啊。也许是我怀孕时责任太重,不能相提并论。但我感冒的时候好像也没有缺过一顿饭啊,真的想不起来了……即便胃口差也会逼着自己少吃点,好像刚刚感冒好不久,真的不记得自己有哪天没吃
- 潍柴雷沃拟登创业板募50亿,逆变器供应商古瑞瓦特再次递表港交所
洞察IPO
作者:周绘出品:洞察IPO上交所&深交所新股上市3月20日-3月26日,上交所主板有1家公司上市;深交所创业板有3家公司上市。数据来源:公开信息;图表制作:洞察IPO1.宿迁联盛:主要业务为高分子材料防老化助剂及其中间体的研发、生产与销售,主要产品包括受阻胺光稳定剂、复配助剂、中间体、阻聚剂等,上市首日收涨43.98%。数据来源:公开信息;图表制作:洞察IPO1.宏源药业:主要从事有机化学原料、医
- 六项精进
壹念百花開_
六项精进又一次迎来了6位新家人的家人,学习会时听到家人们发自肺腑的分享,自己也好像又参加了一次,当时的一幕幕也在脑海中闪现,那充实的三天,仿佛就在昨天。真的很感谢家人们的真诚分享,感谢公司不仅提供给我工作机会,还为我创造这么好的学习机会,感谢杜总给我们提供的这么好的平台,让我能够在工作中继续学习、锻炼、成长。当我真正的静下心来思考的时候,才发现自己肚子里的那点墨水与公司的需要存在着一定的差距,我只
- 内心强大
朴实李
每一次打击都能令内心更强大:生活不可能总是一帆风顺,碰上那些似乎不堪忍受的事情时,如果我们能借此动心忍性,把心灵提升到一个全新的高度,将会出现什么奇迹呢?遇事沉稳,勿扰内心:曾经提到过周五收到水费收费单问题,当我收到需交500多元的水费时,内心直接火爆气氛,直接受影响的当然是情绪,脑子中一片空白,啥也做不进去了,幸亏下午上班后立即去自来水公司解决。可是因周末原因必须等到周一才能彻底解决。周末这两天
- RTL8211FSI PHY电路设计
今朝无言
Ethernet原理图&PCBfpga开发嵌入式硬件
文章目录硬件设计引脚功能框图说明PHYADDRPageLED模式自动协商/速度/全半双工模式SoftReset上电顺序原理图设计参考软件控制(FPGA)硬件调试硬件设计引脚 笔者前代数字采集板采用的PHY芯片是博通Boardcom的B50610,其仅支持0∼70∘C0\sim70^\circC0∼70∘C的工作温度,不符合预期的工作环境温度范围,且没有可直接替换的低温版本。因此在新一版采集板设计
- 新一轮黑产打击:上亿简历大数据公司被警方一锅端
大数据的时代
近日,中国的简历大数据公司、曾获李开复旗下创新工场投资的“巧达科技”被警方一锅端,所有员工都被带走。随后,有部分员工被陆续放出。据悉,该公司被查可能缘起在没有获得授权下抓取用户简历。该公司此前曾获得天使轮、A轮和B轮融资,资方包括李开复的创新工场、中信产业基金等。有迹象显示,监管部门正在掀起对大数据灰产和黑产的新一轮打击。传公司被警方一锅端,网站已无法打开。3月23日,有网友在工商信息查询网站“天
- 粉象生活是正规平台吗?赚钱是不是真的?
氧惠佣金真的高
粉象生活是一个刚刚兴起的电商导购app,是由杭州粉象家科技有限公司开发,简单来说,通过这个app去购买某宝,某东等电商平台的产品,会有折扣。原理就是平台挣取推广费用,然后分一部份给买家,达到双赢。粉象生活是个什么东西,粉象生活app靠谱吗?目前这个粉象生活app因为小范围测试阶段,以邀请制才能注册,小编获取到一个有效邀请码,次数有限,大家需要的赶快使用喔。至于我为何转到氧惠了呢?当然是氧惠佣金更高
- 兜兜转转,我又开始研究 Windows 系统
刚毕业那会,软件开发几乎只有Windows这一条路。那时,DOS已被Windows完全取代,苹果公司深陷低谷、摇摇欲坠;Linux还在襁褓之中,只是极客们手中的玩物。至于Android和iOS,那更是遥不可及——那是诺基亚称王的时代,手机还在拼铃声、换外壳。随着移动互联网浪潮到来,谷歌、苹果、Facebook等崛起,微软渐渐淡出媒体焦点。进入AI时代后,人们的视线更多投向OpenAI这样的“新锐明
- 他用这个平淡无奇的442法则,在可转债上打败了大多数人
问井挖财
上期咱们讲了可转债套利的6种方法以及可转债几种策略研究还有可转债怎么买卖操作可转债虽然是一种低风险的投资品那是不是就可以无脑随便买了呢?另外还有小伙伴要问了那会不会出现公司倒闭,钱还不回来的时候?这写考虑都是有风险意识的为了应对这样的风险常规操作要多买几只,可转债组合想象下象棋,象和士是后卫保护核心老将,这类可转债为防御型,常见为一些低价债,有债底保护,车马炮是要过河攻城略地的,对我们来说,意味着
- 【免费下载】 RTL8211F(D)(I) 参考原理图:千兆以太网 PHY 设计的利器
富阔典
RTL8211F(D)(I)参考原理图:千兆以太网PHY设计的利器【下载地址】RTL8211FDI参考原理图本仓库提供了RTL8211F(D)(I)芯片的参考原理图,适用于电子工程师和硬件开发者进行电路设计和参考。RTL8211F(D)(I)是一款高性能的千兆以太网PHY芯片,广泛应用于网络设备和通信系统中。项目地址:https://gitcode.com/open-source-toolkit/
- 【代码】Matlab鸟瞰图函数
用matlab把图像转化为鸟瞰图代码clcclearcloseallI=imread('road.png');figure(1)imshow(I)bevSensor=load('birdsEyeConfig');birdsEyeImage=transformImage(bevSensor.birdsEyeConfig,I);figure(2)imshow(birdsEyeImage)效果
- 程序员抱怨:1万2的工资我真的活不下去了 网友:我3千工资说什么了嘛
心空如大海
程序员的薪资一直是大家讨论的话题,因为程序员的薪资一直高于其他行业的人。在2019年一季度中,北京的平均月薪是12590元,上海是11260元,要知道现在能够拿万元以上工资的人还是少数人,绝大多数人的收入还是在五千元以下。最近就有一位程序员离职了,在离职的时候,他很不舍,但是没办法,因为他对工资太不满意了。工资从7K到12K,我很爱公司,但是这点钱我真的活不下去了,拿到离职证明的那一刻,很轻松也很
- 【Azure 应用服务】Azure Web App 服务默认支持一些 Weak TLS Ciphers Suite,是否有办法自定义修改呢?
云中路灯
问题描述当AzureWebApp进行安全扫描后,发现依旧支持很多弱TLS加密套件(WeakTLSCiphersSuite),那么是否有办法来关闭这些弱的加密套件呢?在WindowsIIS环境中,可以通过修改注册表修改ForMicrosoftIIS,youshouldmakesomechangestothesystemregistry.Incorrectlyeditingtheregistrymay
- 天呐!创投杯量化私募周一丰马建军不能提现大揭秘!投资被骗可追回
公正公平
我们接到多起投资者举报,称有人冒充知名财经分析师(知名人物大学教授经济学家,上市企业公司及项目和高管)【创投杯量化私募周一丰马建军】,利用【创投杯量化私募周一丰马建军】的声誉和影响力进行诈骗活动。当你看到这篇文章的时候说明你正深陷一场精心准备的騙局之中!如果是还没有投资,千万不要抱有侥幸心理,一定要及时远离!一定不要打草惊蛇一旦遭遇下述相关投资交易资金出不来及时求助文章最下方联系电话!骗子冒充银龙
- 【python+SQLAlchemy】
ryanling河
python数据库sql
需要先安装pymysql模块,以便能够在SQLAlchemy中使用MySQL数据库。使用以下命令进行安装:pipinstallSQLAlchemypipinstallpymysql目前SQLAlchemy版本是2.0.0以上了以下是基本写法以便快速学习fromsqlalchemyimportcreate_engine,Column,Integer,Stringfromsqlalchemy.ormi
- 2018-11-25
TAO1202
2018-11-25六项精进打卡努力一组姓名:简彦涛单位:上海日朗门窗有限公司六项精进397期学员【日精进打卡第175天】【知~学习】《六项精进大纲》0遍共163遍《大学开篇》0遍共163遍【经典名句分享】付出不亚于任何人的努力【行~实践】一、修身今日步数11290步二、齐家跟家人视频通话三、建功:做了产品首件{积善}:发愿从2018年5月27日起1年内做善事。今日1善,累计175善。【省~觉悟】
- 启新教育趣辅导02052100315 罗子杰感悟
庭院深深深几许_0e69
【关键词】能够决策1.正如是人体的决策者、指挥部是军队的决策者一样,每一个行动在执行之前都需要一个决策者,小到家务,大到公司项目乃至国家事务。没有一个决策者,整个行动便无法正常进行。由于我们每个人扮演的角色多种多样,每个人都一定会在某个行动中成为决策者。因此,学会如何决策很有必要!2.文章中告诉我们四种决策方式,即命令式、顾问式、投票式和共识式,并且需要具体问题,具体分析,根据实际情况的不同选择不
- 分享100个最新免费的高匿HTTP代理IP
mcj8089
代理IP代理服务器匿名代理免费代理IP最新代理IP
推荐两个代理IP网站:
1. 全网代理IP:http://proxy.goubanjia.com/
2. 敲代码免费IP:http://ip.qiaodm.com/
120.198.243.130:80,中国/广东省
58.251.78.71:8088,中国/广东省
183.207.228.22:83,中国/
- mysql高级特性之数据分区
annan211
java数据结构mongodb分区mysql
mysql高级特性
1 以存储引擎的角度分析,分区表和物理表没有区别。是按照一定的规则将数据分别存储的逻辑设计。器底层是由多个物理字表组成。
2 分区的原理
分区表由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们可以直接访问各个分区。存储引擎管理分区的各个底层
表和管理普通表一样(所有底层表都必须使用相同的存储引擎),分区表的索引只是
- JS采用正则表达式简单获取URL地址栏参数
chiangfai
js地址栏参数获取
GetUrlParam:function GetUrlParam(param){
var reg = new RegExp("(^|&)"+ param +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null
- 怎样将数据表拷贝到powerdesigner (本地数据库表)
Array_06
powerDesigner
==================================================
1、打开PowerDesigner12,在菜单中按照如下方式进行操作
file->Reverse Engineer->DataBase
点击后,弹出 New Physical Data Model 的对话框
2、在General选项卡中
Model name:模板名字,自
- logbackのhelloworld
飞翔的马甲
日志logback
一、概述
1.日志是啥?
当我是个逗比的时候我是这么理解的:log.debug()代替了system.out.print();
当我项目工作时,以为是一堆得.log文件。
这两天项目发布新版本,比较轻松,决定好好地研究下日志以及logback。
传送门1:日志的作用与方法:
http://www.infoq.com/cn/articles/why-and-how-log
上面的作
- 新浪微博爬虫模拟登陆
随意而生
新浪微博
转载自:http://hi.baidu.com/erliang20088/item/251db4b040b8ce58ba0e1235
近来由于毕设需要,重新修改了新浪微博爬虫废了不少劲,希望下边的总结能够帮助后来的同学们。
现行版的模拟登陆与以前相比,最大的改动在于cookie获取时候的模拟url的请求
- synchronized
香水浓
javathread
Java语言的关键字,可用来给对象和方法或者代码块加锁,当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。当两个并发线程访问同一个对象object中的这个加锁同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。然而,当一个线程访问object的一个加锁代码块时,另一个线程仍然
- maven 简单实用教程
AdyZhang
maven
1. Maven介绍 1.1. 简介 java编写的用于构建系统的自动化工具。目前版本是2.0.9,注意maven2和maven1有很大区别,阅读第三方文档时需要区分版本。 1.2. Maven资源 见官方网站;The 5 minute test,官方简易入门文档;Getting Started Tutorial,官方入门文档;Build Coo
- Android 通过 intent传值获得null
aijuans
android
我在通过intent 获得传递兑现过的时候报错,空指针,我是getMap方法进行传值,代码如下 1 2 3 4 5 6 7 8 9
public
void
getMap(View view){
Intent i =
- apache 做代理 报如下错误:The proxy server received an invalid response from an upstream
baalwolf
response
网站配置是apache+tomcat,tomcat没有报错,apache报错是:
The proxy server received an invalid response from an upstream server. The proxy server could not handle the request GET /. Reason: Error reading fr
- Tomcat6 内存和线程配置
BigBird2012
tomcat6
1、修改启动时内存参数、并指定JVM时区 (在windows server 2008 下时间少了8个小时)
在Tomcat上运行j2ee项目代码时,经常会出现内存溢出的情况,解决办法是在系统参数中增加系统参数:
window下, 在catalina.bat最前面
set JAVA_OPTS=-XX:PermSize=64M -XX:MaxPermSize=128m -Xms5
- Karam与TDD
bijian1013
KaramTDD
一.TDD
测试驱动开发(Test-Driven Development,TDD)是一种敏捷(AGILE)开发方法论,它把开发流程倒转了过来,在进行代码实现之前,首先保证编写测试用例,从而用测试来驱动开发(而不是把测试作为一项验证工具来使用)。
TDD的原则很简单:
a.只有当某个
- [Zookeeper学习笔记之七]Zookeeper源代码分析之Zookeeper.States
bit1129
zookeeper
public enum States {
CONNECTING, //Zookeeper服务器不可用,客户端处于尝试链接状态
ASSOCIATING, //???
CONNECTED, //链接建立,可以与Zookeeper服务器正常通信
CONNECTEDREADONLY, //处于只读状态的链接状态,只读模式可以在
- 【Scala十四】Scala核心八:闭包
bit1129
scala
Free variable A free variable of an expression is a variable that’s used inside the expression but not defined inside the expression. For instance, in the function literal expression (x: Int) => (x
- android发送json并解析返回json
ronin47
android
package com.http.test;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import
- 一份IT实习生的总结
brotherlamp
PHPphp资料php教程php培训php视频
今天突然发现在不知不觉中自己已经实习了 3 个月了,现在可能不算是真正意义上的实习吧,因为现在自己才大三,在这边撸代码的同时还要考虑到学校的功课跟期末考试。让我震惊的是,我完全想不到在这 3 个月里我到底学到了什么,这是一件多么悲催的事情啊。同时我对我应该 get 到什么新技能也很迷茫。所以今晚还是总结下把,让自己在接下来的实习生活有更加明确的方向。最后感谢工作室给我们几个人这个机会让我们提前出来
- 据说是2012年10月人人网校招的一道笔试题-给出一个重物重量为X,另外提供的小砝码重量分别为1,3,9。。。3^N。 将重物放到天平左侧,问在两边如何添加砝码
bylijinnan
java
public class ScalesBalance {
/**
* 题目:
* 给出一个重物重量为X,另外提供的小砝码重量分别为1,3,9。。。3^N。 (假设N无限大,但一种重量的砝码只有一个)
* 将重物放到天平左侧,问在两边如何添加砝码使两边平衡
*
* 分析:
* 三进制
* 我们约定括号表示里面的数是三进制,例如 47=(1202
- dom4j最常用最简单的方法
chiangfai
dom4j
要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/目前最新dom4j包下载地址:http://nchc.dl.sourceforge.net/sourceforge/dom4j/dom4j-1.6.1.zip
解开后有两个包,仅操作XML文档的话把dom4j-1.6.1.jar加入工程就可以了,如果需要使用XPath的话还需要
- 简单HBase笔记
chenchao051
hbase
一、Client-side write buffer 客户端缓存请求 描述:可以缓存客户端的请求,以此来减少RPC的次数,但是缓存只是被存在一个ArrayList中,所以多线程访问时不安全的。 可以使用getWriteBuffer()方法来取得客户端缓存中的数据。 默认关闭。 二、Scan的Caching 描述: next( )方法请求一行就要使用一次RPC,即使
- mysqldump导出时出现when doing LOCK TABLES
daizj
mysqlmysqdump导数据
执行 mysqldump -uxxx -pxxx -hxxx -Pxxxx database tablename > tablename.sql
导出表时,会报
mysqldump: Got error: 1044: Access denied for user 'xxx'@'xxx' to database 'xxx' when doing LOCK TABLES
解决
- CSS渲染原理
dcj3sjt126com
Web
从事Web前端开发的人都与CSS打交道很多,有的人也许不知道css是怎么去工作的,写出来的css浏览器是怎么样去解析的呢?当这个成为我们提高css水平的一个瓶颈时,是否应该多了解一下呢?
一、浏览器的发展与CSS
- 《阿甘正传》台词
dcj3sjt126com
Part Ⅰ:
《阿甘正传》Forrest Gump经典中英文对白
Forrest: Hello! My names Forrest. Forrest Gump. You wanna Chocolate? I could eat about a million and a half othese. My momma always said life was like a box ochocol
- Java处理JSON
dyy_gusi
json
Json在数据传输中很好用,原因是JSON 比 XML 更小、更快,更易解析。
在Java程序中,如何使用处理JSON,现在有很多工具可以处理,比较流行常用的是google的gson和alibaba的fastjson,具体使用如下:
1、读取json然后处理
class ReadJSON
{
public static void main(String[] args)
- win7下nginx和php的配置
geeksun
nginx
1. 安装包准备
nginx : 从nginx.org下载nginx-1.8.0.zip
php: 从php.net下载php-5.6.10-Win32-VC11-x64.zip, php是免安装文件。
RunHiddenConsole: 用于隐藏命令行窗口
2. 配置
# java用8080端口做应用服务器,nginx反向代理到这个端口即可
p
- 基于2.8版本redis配置文件中文解释
hongtoushizi
redis
转载自: http://wangwei007.blog.51cto.com/68019/1548167
在Redis中直接启动redis-server服务时, 采用的是默认的配置文件。采用redis-server xxx.conf 这样的方式可以按照指定的配置文件来运行Redis服务。下面是Redis2.8.9的配置文
- 第五章 常用Lua开发库3-模板渲染
jinnianshilongnian
nginxlua
动态web网页开发是Web开发中一个常见的场景,比如像京东商品详情页,其页面逻辑是非常复杂的,需要使用模板技术来实现。而Lua中也有许多模板引擎,如目前我在使用的lua-resty-template,可以渲染很复杂的页面,借助LuaJIT其性能也是可以接受的。
如果学习过JavaEE中的servlet和JSP的话,应该知道JSP模板最终会被翻译成Servlet来执行;而lua-r
- JZSearch大数据搜索引擎
颠覆者
JavaScript
系统简介:
大数据的特点有四个层面:第一,数据体量巨大。从TB级别,跃升到PB级别;第二,数据类型繁多。网络日志、视频、图片、地理位置信息等等。第三,价值密度低。以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒。第四,处理速度快。最后这一点也是和传统的数据挖掘技术有着本质的不同。业界将其归纳为4个“V”——Volume,Variety,Value,Velocity。大数据搜索引
- 10招让你成为杰出的Java程序员
pda158
java编程框架
如果你是一个热衷于技术的
Java 程序员, 那么下面的 10 个要点可以让你在众多 Java 开发人员中脱颖而出。
1. 拥有扎实的基础和深刻理解 OO 原则 对于 Java 程序员,深刻理解 Object Oriented Programming(面向对象编程)这一概念是必须的。没有 OOPS 的坚实基础,就领会不了像 Java 这些面向对象编程语言
- tomcat之oracle连接池配置
小网客
oracle
tomcat版本7.0
配置oracle连接池方式:
修改tomcat的server.xml配置文件:
<GlobalNamingResources>
<Resource name="utermdatasource" auth="Container"
type="javax.sql.DataSou
- Oracle 分页算法汇总
vipbooks
oraclesql算法.net
这是我找到的一些关于Oracle分页的算法,大家那里还有没有其他好的算法没?我们大家一起分享一下!
-- Oracle 分页算法一
select * from (
select page.*,rownum rn from (select * from help) page
-- 20 = (currentPag

”估计RMI的员工基本上不可能挣什么钱“ 老陈真体恤民情呀! 团队是fabless的根本,团队要散了,就啥都没有了。
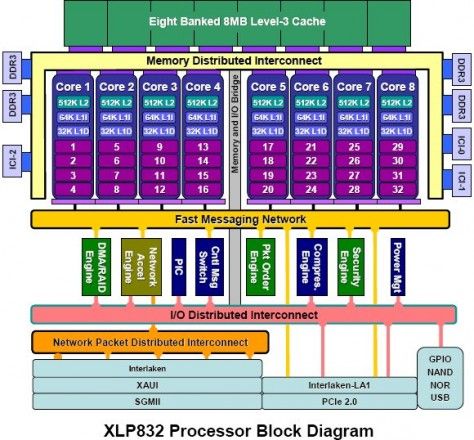
观察XLP和XLR,从网络的角度,最大的就是加了一个POE–Packet Order Engine。可以回顾一下Cavium芯片。。。我个人非常认可这一点。否则,拿软件做Packet Ordering,高端系统确实不好做。
应该说,XLP最大的变化是对CPU核的增强,据说单个XLP核,在同频率下较XLR性能高一倍以上
很想知道XLP的POE的详细参数和细节。不知道同Cavium的SSO比,有什么特点。
XLP vs. XLR
1.主要是cpu core上,XLR core是一个multi-threading标量处理器,主要面向network throughput优化(目标是memory/IO密集型业务)
而XLP core是一个4-issue,out of order,4-threading(SMT)超标量处理器,对于主控平面(计算密集型业务)和数据平面(memory访问密集型业务)都很合适。同时由于采用40nm技术,主频得以提高。所以简单地说,XLP 1 core性能是XLR 1 core 3倍。
2.POE(packet of order)引擎的引入
3.接口的变化.XLR算是10Gbps方案,XLP则是40Gbps方案。XLR support 2 XGMII/2 SPI4,4GMAC,HT.XLP support Interlaken(40Gbps),XAUI(40Gbps),pcie(16lane,2.0)
4.支持4片XLP芯片间full mesh互联(inter-chip-connect,ICI),并保证跨芯片cache一致性和芯片消息环(Fast message network,FMN)处理一致性,用于高性能计算和100Gbps
据说RMI的每个员工都有不少股票,这次他们能够赚不少钱了吧!
个人认为XLP内置的RAID5、6运算加速是重点。据说RMI行业收入的最大头是存储,存储无处不在,相比之下通信和安全太小了。而未来的存储一定是IP的天下,XLS已经做到了TCPOffload,加上丰富的接口和PCI-E 4x,做HBA没有问题。现在XLP再一出来,做存储控制器应该也没问题了。
通常而言,RMI完了。Game Over了。如果对投资有兴趣的话,可以考虑购入Cavium的一些股票。当然,我的意思你如果你觉得投资这个sector有兴趣。
可怜的RMI,事件是无情的,不知道Cavium会怎样
”估计RMI的员工基本上不可能挣什么钱“这句话应该是对的。据说RMI在中国的团队比较大,我想接下来就是裁员了,在中国!
本人接触过RMI的中国的技术支持,大部分都是从华为、中兴和当年的华三出去的。这些技术支持的技术能力还是很强的,RMI在中国凭借着支持团队优秀的支持能力战胜了Cavium,进入了无线、安全以及数通领域。
相比之下Cavium在中国市场的技术支持能力比较弱,在中国没有战胜RMI并不是因为的多核处理器本身,而是因为他们没有注重本地技术支持。
XLP能搞定的事情,我相信Cavium的多核处理器肯定同样能够搞定!只是我们关心的是使用哪一个会更容易,更迅速的产品化,那就不得不考虑本地支持能力。
Game Over了,也许这是Cavium的一个机会,在中国战胜RMI的好机会。他们裁员你就招人,用这些人重新占领。呵呵,看来Cavium的股票要涨价了。
这次收购RMI的员工可能要倒霉了,从技术上来说RMI比NetLogic强的多,也更有发展, 但是运营是Netlogic的强项。 老板是很爽的,但是RMI下面的员工恐怕股票要打水漂了。
我从RMI的结局,也在思考龙芯的命运。RMI的创办人和团队的技术实力与计算所打个平手应该不为过吧。你胡伟武为了中华民族复兴:-),RMI员工做startup为了生存与活命。不应该说人家工作不勤奋。这么多的account(客户),但volume上不去,结局仍然是这样的黯然出局。
龙芯,以MIPS ISA为起点,以Linux做宿主操作系统结果目标却是通用计算机和家庭上网本。即使龙芯3流片成功,x86指令系统能虚拟化成功,但到底市场在哪里?除了曙光,谁是买家?
我个人目前持谨慎乐观的态度。
呵呵,龙芯!又是一个打着民族旗号的产品。大跃进式的工作方式。
掂量出自己的分量,给自己合理的定位应该是做事情的首要解决的。难道像大跃进,喊亩产万斤,难道你的一亩山坡地就真能出产5000斤了?
我倒是佩服珠海炬力这个公司。
cavium下一代的处理器是65nm,这是他们致命缺陷。从投资角度来说,合并后的netlogic/rmi都
比各自更为强大,但是对rmi员工来说,这次贱卖
确实太惨了,意味着几年的辛苦都白费了
我相信通过这件事情,那些一心绑定在RMI或者CAVIUM上开发自己产品的二三线网络安全厂家就要仔细考虑了,这样的风险是否是自己可以承受的,也许,X86会重新抬头。
我同意Panabit的观点。特别是Intel的最新微结构Nehalem之后,x86确实很好的架构了。
我还是不看好Cavium,他们和XLP对应的处理器最快也得明年才能出来吧。通过RMI这件事情,会有很多人发现,X86可能更可靠(综合);同样,也会有人意识到自主知识产权处理器的重要。
hw,zte他们非常欢迎这次合并,这对他们是有好处的,因而,这次合并对cavium非常不利。在电信设备/网络设备市场,x86架构未来几年之内都没有机会。从接口丰富程度,从功耗来说,x86都相差太远太远。
whoknows应该改成Iknow。连华为与中兴很high这次合并都知道:)。圈内人呀。希望多让华为或者中兴的弟兄们访问弯曲评论:-)
我怎么听说很多华为的人已经开始唱衰这次贱卖了,而且听说RMI的很多员工已经开始跑路了,真是树倒猢狲散啊
就目前的技术层面而言,除了通用处理器是国内掣肘外,其它像POE或者局部加速的技术,国内都可以实现,因此,完全可以利用我们自身的技术,再加上X86等功能强的CPU来做一个系统。可以利用X86换掉RMI或CAVIUM的MIPS CORE。功耗方面,在高端系统,X86没有明显的劣势。至于你所说的接口丰富等方面,完全可以有外围硬件替代。另外,从长远角度看,对数据包做更高层次的检测室大势所趋,所以,数据包都经过通用CPU,而不是目前的防火墙所简单的SLOW/FAST模型,这也意味着需要功能更强的通用CPU来实现。还有,目前X86的外围网卡和芯片组已经做了很多方面的工作,比如Intel宣称的IOAT技术,就已经在网卡里增加了RSS来作为LOAD BALANCE,增加了DCA技术来将数据包DMA到内存的同时,加载到CACHE里,这些都是可以显著增强数据包处理性能的特性。
哪那些绑定在多核上的topsec,leadsec不变得前途未卜了啊?
HW,ZTE欢迎这次合作,这不太可能吧,这哪是一个积极信号,看看CISCO同这些公司的关系,难道不心存忧虑?我倒是觉得将这看着一个警钟比较好。至于国内那些将自己的全部产品线押宝在CAVIUM上的,就更加要注意了。CPU,还真是国之重器呀!
Panabit 没有真正去了解过电信网络设备领域这个行业,还在用PC领域的眼光去看问题。SOC为什么可以在网络设备大兴其道,整板成本是关键:不光是外围器件的数量可以上,加上PCB布线生产加工的难度降低。 btw,你说的intel哪些功能,cavium/rmi/freescale的芯片上都已经有了,而且在市场上卖的产品都用上了,不仅仅是一个概念而已。
员工跑路是可能的,但是,对于电信设备制造商来说,对他们是利好而不是利空。NETLOGIC在国内的业务最主要就是hw/zte,他们需要大量使用tcam+多核处理器的方案,两个公司合并以后,可以给他们提供更好的解决方案和参考设计。
功耗方面,在电信设备上的CPU是不能有风扇的。就一点你就想想跟x86架构功耗差别有多大。何况cavium/rmi都是soc,里面还集成了很多其他的接口和引擎,整版功耗比x86方案不只少一点两点
对于 OEM 厂商来说,应该是利好。说明 RMI 稳定了。
对于 RMI 员工来说,不做评论。一切皆有可能。
RMI 的技术值得尊重
现在那个电信厂家还在使用x86平台?
本人做了8年核心网,RNC和接入网,从TI/DSP+ Intel/NP,到今天到muti-core,还从来没有使用过x86,从前不会,现在不会,将来也不会选择x86。
但是听说Z公司核心网使用的是x86,但我们从来不用x86,x86适合PC但不是和嵌入式这个领域。
x86好好做pc吧!
RMI不知后续如何?XLR/XLS不以后知是否还能像今天这样风光!
很热闹。我问一个问题。为什么?
1.为什么x86更适合于PC和Server?
2.为什么MIPS和PowerPC更多用在通信?
3.为什么ARM更多用在移动设备handheld?
我个人认为我能回答2,3.但不能回答1说服我自己YET。
现在那个电信厂家还在使用x86平台?
————
Juniper的路由器都有x86系统做Routing Engine
:)
.为什么x86更适合于PC和Server?
2.为什么MIPS和PowerPC更多用在通信?
3.为什么ARM更多用在移动设备handheld?
还请说说看
各位千万别误会,我并没有说X86用在电信核心网。我主要是针对国内现在的二三线网络安全厂家所做的评论。另外,Juniper等已经在走通用处理器 + ASIC的模式了,只不过用的不是X86,而是PPC等。另外,要以发展的观点看待问题。X86现在的架构已经解决了IO问题,这正式发展自己的外围ASIC的好时机。
试回答陈首席的三个问题:
1:X86在PC和Server行业的地位,是历史形成的。最初业界IBM和Intel的联盟造成了这个现状。Intel的X86系统,及当时操作系统DOS是开放的,因此聚敛了很高的人气。
2:MIPS和PPC属于RISC架构,性能可以做得很高,因此在专用系统中比较好用。另外MIPS属于大端(Big Endian),与网络字节序相同,减少了转换字节序的开销。
3:ARM处理器可以做的功耗很低,很精简,因此适合没有固定电源,使用电池供电的移动设备。
不妥之处还望各位大侠指正。
我期待大家的讨论。我看一下大家的讨论。对Panabit对系统的理解比较欣赏。能说出x86解决了I/O问题这句话,说明确实有点功力:–)。是个搞技术的好苗子。也希望其他华为的同学们看看Nehalem的介绍。
当然,并不是说Nehalem微结构可以做NS5000E的Forwarding了。只是说,事情都在悄悄地演变着。。。。。。
首席对 Netronome的NFP32XX,EZchip的NP3,以及多核,有没有相关的比较,比如针对路由器这种应用,谢谢
X86的IO问题,我觉得根源在其体系结构,X86属于CISC,但演进到P3/P4时代实际上用RISC+微码来实现,这样造成内部晶体管数目和面积膨胀,放不下更多的I/O附件。(不能和RMI那样的SoC比啊)
因此,X86的I/O就要受外部总线的吞吐量限制了。最初是PCI,为解决这个问题又发明了PCI-X和AGP技术,但仍然是瓶颈。PCI-E出现以后好了一些,但是和RMI之类的处理器的内部IO互联、FMN还是不能相比。
如果Intel真的解决了这个问题,不清楚这种处理器功耗该有多大,价格该有多高?
补充上面的:
如果,市面上出现了某种x86架构的多核处理器,具有强大计算能力同时,也集成了很多IO部件,性能可能优于RMI/Cavium,但由于成本、采购量等各种原因,其性价比一直低于MIPS/PPC的多核处理器,那么,在市场上Survive也是有难度的。
这里面还是用户需求的问题。光具备超强的技术/性能,傻快傻快/傻多傻多,而不能抓住用户需求,那么只可能是业界的流星。
“x86解决了I/O问题这句话,说明确实有点功力:–)”
===呵呵,首席也没有必要这样损人吧?x86 IO扩展能力问题由来已久,路人皆知,了解这个问题需要功力?
新进的PCIE算是很大程度上解决了这个问题,但是PCIE在Qos方面(通道化等等)还是有瓶颈,还有一段路要走。
===
x86作为route engine没有问题,计算能力强,但是也就说明了控制平面的可行性。
===
1.x86以前没有soc方案,需要外挂桥片,这个对成本和pcb设计是一个问题(特别是中低端方案,对价格敏感)。当然去年intel也出了一个soc的片子,还集成了安全加速引擎和低速遗留接口的支持(T1,E1),说明Intel又有做通信的想法了。
2.x86平台的功耗问题,一直让人头疼。高端的至强平台,功耗到100w+,客户单板设计相当头疼。不说100w+,就是50w,现有客户都抱怨不断!
RMI是一家技术导向型公司,从多线程到现在的4 issue等都体现了追求技术决心,但其在芯片内部实现了这些东西固然有其好处,但是考虑一下功耗,成本,据了解RMI给客户的芯片都是LP版本的,die size都很大,成本相对都比较高。
公司毕竟是商业的,完全追求技术路线的公司很难取得最后的成功。这方面,感觉RMI输给CAvium。
再论功耗问题,freescale一个宣传策略:30w功耗作为嵌入平台功耗的分界线。肯定是有一定道理滴
有没有介绍下Freescale的PowerPC平台特点的
想不到我关于X86的一序话居然是丢下了一颗炸弹,呵呵。
intel Ep80579
二三线网络安全厂商也会转RISC平台。台湾传统工控板厂商都在积极开发和推行cavium/rmi的中低端的标准板。x86平台在网络设备上的可应用范围会越来越窄。 网络设备这个行业的生态跟传统的pc/server 完全不一样。
看了很多评论,发现很多人的理解还是很肤浅.X86有它的优势也有缺点.至少在通信领域,嵌入式以MIPS和PPC为架构的多核处理器还是主流,这里有很多原因,功耗,BOM成本,IO接口,IO处理的能力,多核配套软硬件环境,IO处理能力,任何一样,X86目前都没有优势,X86的计算性能,我做过和RMI,OCTEON对比,基本上如果同主频,OCTEON的CORE和X86一致,RMI的CORE设计相对性能较差(10级流水线,单issue).RMI的下一代,应该讲从路标的角度讲,要比OCTEON的下一代更吸引人,多issue,多线程,加入类似OCTEON硬件保续单元等等,基本上在保留自身特点的基础上把原先OCTEON的优点都抄袭下来了.就是具体的流片时间要人担心,另外功耗也是一个主要的问题,而OCTEON的下一代相对应该更可靠,基本上只是升级工艺,更多的内核而已.现在市场上,不是你画个图给大家就可以,推出的时间点,稳定性都很重要.目前从纯计算的角度讲,如论是RMI还是CAVIUM,相对于X86也并不吃亏.
1,这个价格是不是贱卖不一定,现在的形势太差了,IPO基本无望,投资者退出无门,合并是一个不错的选择。合并(Merge)后如果整合成功,RMI的前途或许更光明,至少投资者看好-$NETL随着消息的宣布上涨10%+, $CAVM这两天倒是在跌。同样是上周,另一家MIPS厂商SiCortex,虽然增长势头很猛(HPC市场)-但没有新的投资进来,不得不宣布变卖资产,停止运营了。
2, x86在通信市场的看点不是Nehalem,而是将来基于Atom的SOC。上面kkk提到了Intel去年发布的EP80579,这个是Atom之前的产品,基于Pentium M “Dothan”内核的单核SoC,这个芯片TDP在11w-21w之间,90nm工艺,主频600M-1.2G,集成度丝毫也不亚于其他通信处理器。采用Atom之后,只怕每个通信处理器厂商都得紧张一下了。Intel的优势实在太多了-制造,研发力量,以及x86的低成本,但能否在通信市场成功还得看商务(business)方面的因素。
3, US半导体初创公司的美好时光已经一去永不复返了,尤其是处理器公司,再也不要想有QED那种几十亿美金的收购案了。希望在东方……:)
结论: no idea on RMI, long Intel. My two cents
To Panabit:
为什么说通用处理器是国内OEM的瓶颈,从MIPS授权IP受出口限制吗?比如最高端的MIPS 1004K。当然,即使有核,到SoC/系统也有很多工程困难。
x86的I/O问题是个什么问题?是指FSB?PCI-E等也只属于系统结构层次吧,跟ISA是不是x86没关系.
ft
为什么Natal的评论需要被审核?
系统的AI智能决定是否审核:-)。可见机器人永远不能战胜人。
tektalk明天也系统维护吧。
好像凡是明天不处于技术维护状态的网站,都属于不怎么样的网站 :)
atom性能太差,而且intel都将其生产外包给台积电,可见其在intel中的地位。 intel在通信市场近期难有作为,即便是传统的防火墙厂商(topsec/网御/网神),他们也都认识到了这个问题,正在积极转型。
EP80579是比较失败的产品,自身不过硬,又在错误的时间出现,天时地利人和都不占便宜,据说到现在几乎没有国内安全厂商采用。平心而论,我认为那个平台还是不错的。
“x86的I/O问题是个什么问题?是指FSB?PCI-E等也只属于系统结构层次吧,跟ISA是不是x86没关系.”
===显然,上述讨论不是讨论ISA之间优劣。
这里讨论的是具体的产品—采用x86架构的Intel的片子和采用mips架构的RMI CAVM的片子,FSL ppc产品线.
KISS大大,对于以高集成度为卖点的SoC来说,难道我们只会关注它说采用的ISA?
看看这些
Netlogic <—RMI
Netronome <— Intel IXP
IDT <— Tundra
寒冬呀,日子不好过。
个人不看好RMI, Netronome,小厂家。
做方案还是用大厂家的多核吧.
我觉得,从RMI被贱卖这件事情,看到的不是对谁有利亦或不利,而是一个信号,就是一个我们产品所依赖的第三方是否稳定的信号。我们可以想一想,如果当自己的产品线全部采用RMI或者CAVIUM的时候,一旦出现不稳定的信号,自己是否可以承受。当然这个能否承受与否,是因公司而异的。我并不是竭力推荐X86,我只是说,X86同以前相比,已经有了很多积极的变化,而且这种变化还在持续下去,比如最新出现的i7,其QPI,总线方面,PCIE 2.0的支持已经多通道内存的支持,这些都是积极的变化。从CPU的角度看,X86无疑是强劲的,当然接口肯定不能同通信处理器相比。不过我认为,如果厂家自己有能力丰富接口而弥补这些不足,X86倒不失为中高(高-)端安全产品一个较好的选择。现在的安全产品有一个趋势是朝应用层发展,这也对更多的CPU处理能力提出了要求,X86在这方面无疑是有优势的。至于matrix兄,陈首席可不是在损我,你要相信这一点,呵呵。大家都在以自己的经验去看待事情,有时不妨适当跳出一下自己的圈子,呵呵。
回KISS兄弟,我说的X86 IO问题主要是指:
1)内存带宽和CPU之间的扩展性
2)CPU和外部设备之间的连接扩展性
早期大家也知道,通过FSB和北桥,内存带宽不具备同CPU同步的扩展性(当然现在也不是100%同步,但是已经是一个极大的变化了)。至于2)QPI和PCIE虽然不是那么完美,但是至少已经足以对付相当大的IO带宽要求了。
还有一个积极的变化是,IOAT。我觉得IOAT中最值得欣赏的特性是DCA(Direct Cache Access),这个特性用的得好,对小包的吞吐会有相当大的贡献量。其它的特性如RSS,如果自己做外围ASIC或FPGA的话,完全可以自由发挥,倒没有DCA那么明显了。
说实在的,个人感觉panabit兄对cavium/rmi/freescale的芯片不是很了解,甚至对x86也不是很了解,所以才不能正确去比较它们的优势和劣势。 感觉你是在安全行业,但是对安全产品的硬件方面,也不是太了解,所以,觉得很多看法感觉只是隔靴搔痒,说不到点子上。x86在安全产品有市场,完全是历史的原因,现在这个市场正在远离它。随着安全厂商的成熟,他们有能力去构建自己的软件平台的时候,基于非x86平台的解决方案会占越来越多的份额。 就拿高端来说,用 risc加内容过滤芯片的组合,性能上会比x86 纯软件的方案会强很多。 拿 I/O 说,pcie总线由于协议复杂,有效数据的吞吐量只有理论值50%左右。这个对于高端系统会成为吞吐的瓶颈。
当然,最终的胜者还是要靠市场来决定,就像当年HT/PCIE之争,rambus/ddr之争,最终胜出的不是性能最好的,而是市场能接受最快的。
panabit兄,供应商的稳定性问题,肯定是设备商最关心的问题。当年H3C在greenfield上栽了大跟斗,所以HW,ZTE等大客户在风险控制方面的经验肯定多多。
btw,我们也要破除供应商就一定是大厂商的迷思。Intel不是也把IXP系列给倒手了吗?对于像Intel这样大恐龙,瞧得上通信处理器(甚至是通信多核处理器)这个细分市场吗?
退一步说即便是Intel重新玩通信处理器这个市场,Intel这个级别的公司,按照它的运营模式一定能够在这个细分市场赚得盆满钵盈吗?
startup在创新肯定有可取之处,否则在美国这个充分竞争市场,根本就没有存在的必要。
其实这方面可以学习cisco,对于有价值的startup加以收购(当然,这个又要考虑米国政府同意与否了)。
panabit 兄,我觉得你需要认真研究一下cavium/rmi的芯片再来讨论会更有意义些,因为我感觉你似乎完全不了解他们。如果我说错了,请见谅
“拿 I/O 说,pcie总线由于协议复杂,有效数据的吞吐量只有理论值50%左右。这个对于高端系统会成为吞吐的瓶颈”
===guest兄,吞吐真还不是大问题。pcie 2.0 5Gbps per lane,multi-lanes问题不大。再说传说中的pcie 3.0,8-10Gbps per lane,就更不是问题。
pcie的问题还是Qos,通道化支持channelization suppport),flow control弱。作为packet interface,先天不足,不能和SPI4 Interlaken接口pk。
行,文人相轻的老毛病快要出来了。其实,技术观点通常都是各有道理。这与个人的经历有关。所以不要勉强。互相学习才是王道:-)。
我现在有个好的习惯。我特别讨厌开会。但只要我去参加一个会,我事先会想尽方法告诉自己我要学到点东西。否则,我参加会议是受罪:-)
关于Matrix的“其实这方面可以学习cisco,对于有价值的startup加以收购(当然,这个又要考虑米国政府同意与否了)。”。如果您阅读我这些年关于华为的文章,其实是在劝他们在技术上做好准备,购买公司,扩展起来。
华为目前山头林立。藩王遍地。而且许多人极端自信。认为什么都可以和应该自己做。
我拭目以待。
会58楼:
guest,谢谢你善意的提醒。Cavium和RMI的东西,我很早就有研究过了。当时国外一家公司在国内的Cavium性能验证工作也是我做的(当初是CN38XXX刚出来的时候)。关于它的那个POE改成SSO这个名称,我也知道其为什么改的,呵呵。
这篇文章本身一般,就是报道一个业界收购。但引发的讨论相当优秀。基本上涉及到了目前通信业界的精华。而且人员参与感觉来自各大通信公司的骨干人员。我自己也学习到了许多东西。我会把这篇文章标注为“弯曲推荐”。
Panabit 兄,”我觉得IOAT中最值得欣赏的特性是DCA(Direct Cache Access),这个特性用的得好”
===
Intel的DCA特性不清楚,DCA哪年推出不知道。
但是这个玩意不是新东东。RMI XLR推出之时,就有一个L2 cache Allocate功能,报文DMA到内存的同时,可以把报文同步搬运到L2 cache,后续软件处理可以有效减少cache miss rate,从而提高性能。
注意这玩意XLR一直都有,XLR是多少年前的产品了?
Matrix兄,你说得很对,的确是这样的。正是由于这些,所以我说X86正在发生积极的变化。IOAT的推出我想有3年左右吧(所以应该比XLR晚一些,至于DCA,应该是07年出来的,是IOAT2中的内容,所以就更晚了)。另外,据我所知,XLR刚开始推出的时候,是将小于112 Bytes的包放在内存中,所以当时Cavium在这方面的测试结果要差于RMI。后来Cavium也做了这一点(但是好像是98 Bytes以下的报文,这两个数字我需要再考证一下)。Intel的这个DCA特性强在什么地方,就是它拥有相比CAVIUM或者RMI大得多的L2和L3 CACHE,所以能够同步更多的报文。
Panabit兄,你对RMI packet L2 cache allocate功能理解有误。
它有一个寄存器,可以控制报文头部多少字节同步搬运到L2 cache。比如说,设置寄存器为0xf,则搬运packet header 15个cacheline(32 byte)= 480字节进入L2 cache。
报文整体都在内存中,但是报文头在cache,而一般报文处理显然处理报文头的几率大得多!
DCA?
Freescale叫它为cache stash.
从MPC8560, 03年就有了。
到了P4080,都能stash到指定的L1, L2, L3 cache。
还是matrix是行家里手
Matrix兄,“报文整体都在内存中,但是报文头在cache,而一般报文处理显然处理报文头的几率大得多”,我赞成你的观点。可以控制SIZE的特性是刚开始就有的吗?这是一个非常好的特性,Intel的DCA目前还缺乏这方面的东西,或者说目前支持IOAT的网卡或其它外围设备还不支持这个可控SIZE的特性。另外我想再阐述的是,我的观点并不是否定或完全肯定任何一种架构,我的核心观点是,当我们一直对某个东西熟悉,并心里否定另外一个东西的同时,不妨想一想,“我这样对不对?”。另外,架构的选择也同自己面向的领域和产品形态息息相关(当然这都是废话了,呵呵)。通过X86这个“炸弹”,我学到了很多东西,也希望弯曲评论越办越好!:)
aaa兄,P4080 宣传今年Q2样片。现在能够sample了吗?
FSL通信处理器老大哥做惯了,市场需求反应有些迟钝呀。
Matrix兄,“报文整体都在内存中,但是报文头在cache,而一般报文处理显然处理报文头的几率大得多!”,我非常赞同你的这个观点。另外,XLR的这个控制SIZE的寄存器是一直就有的吗?这个特性是非常有用的,它可以让你在CACHE POLUTION和性能之间自己来做平衡。Intel的DCA,或者支持DCA的网卡或其它设备缺乏这种特性。
Matrix兄,有兴趣的话,私聊一下,我的MSN: [email protected]。
感谢弯曲评论这个平台,让我认识到这么多高手,衷心祝愿弯曲评论越办越好!!!
matrix兄,有同感。
FSL确实是有点钝。
这不,被Cavium和RMI的多核逼上梁山。
问陈首席的问题,貌似netlogic买断rim是为了增强其 multicore processor+tcam业务,这个业务与np+tcam在交换路由或者其它领域会有冲突吗,国内的厂家像HW,ZTE,DATANG,H3C现在用的主要是cavium还是rim为主(与tcam结合的部分)?
前面Matrix兄和Panabit兄提到RMI packet L2 cache allocate功能,确实可以通过配置将部分报文直接放到L2 cache里,但问题是此时报文还没进入CPU内部进行处理,仍然积压在其硬件加速单元里。大量尚未开始处理的报文占用L2 cache,必然会导致正在处理的报文出现cache miss的可能性增大,对性能也没有好处。
当然在流量较低时,使用这个特性可以降低单个报文的处理周期。
所以个人感觉这个功能没啥用,呵呵
@老韩: EP80579确实算是比较初级的SoC产品-只是把传统的Core+北桥+南桥+加速器做到一个die上,感觉并没太多系统级优化,例如互联设计等。
你说的失败的地方主要是哪里?芯片指标不过关,还是软件栈支持不好,或是系统开发方面?
—————————————-
老韩 于 2009-06-03 8:16 am
EP80579是比较失败的产品,自身不过硬,又在错误的时间出现,天时地利人和都不占便宜,据说到现在几乎没有国内安全厂商采用。平心而论,我认为那个平台还是不错的。
Racoon兄,你说得对,的确有这样的情况出现,所以那个可配置特性就很重要了,不过这个功能对小包贡献还是挺大的。X86由于CACHE比较大,所以会稍微好一些。
Racoon兄,你说得对,会有这样的问题的,所以那个可配置的SIZE寄存器是一个很好的特性。这个对小包的贡献还是挺大的,X86的CACHE比较大,也会好一些。
Racoon兄,你说得很对,的确有这样的问题,这实际上是对CACHE产生的POLLUTION了。所以那个可配置SIZE的寄存器就很重要。这个特性对小包的贡献是蛮大的。特别是在做性能测试的时候,呵呵。
@matrix大大
隔行如隔山啊,术语涵义不同,看到x86的第一反应就是ISA,不是系统,呵呵
—————————————-
matrix 于 2009-06-03 6:41 pm
这里讨论的是具体的产品—采用x86架构的Intel的片子和采用mips架构的RMI CAVM的片子,FSL ppc产品线.
KISS大大,对于以高集成度为卖点的SoC来说,难道我们只会关注它说采用的ISA?
顺便搭车问各位大大几个问题:
1,从OEM系统用户角度看,FSL的e500比e600的优势有哪些,对于通信应用来说?
2,FSL的e700是不是取消开发了?QorIQ的roadmap里有没非e500的产品?
EP80579,简而言之就是性价比不高。我一开始觉得最有可能的应用是SMB级的存储,Netgear,Linksys之流可能感兴趣,可一直没有看到。
Intel现在已经把80579边缘化了,后期传说中加入IXP RISC核的计划也停了,现在推的是Atom和ce600/1G。
得,Intel买断Windriver。x86进入什么市场?嵌入式:-)
今天简直太匪夷所思—Intel 收购windriver
难道intel要大举进入嵌入处理器市场(通信处理器算是其中的细分市场)?
难道要首先收购windriver,给powerpc和mips一个下马威?
服了,真是混乱年代,必须神经彪悍!
我期待大家的讨论。我看一下大家的讨论。对Panabit对系统的理解比较欣赏。能说出x86解决了I/O问题这句话,说明确实有点功力:–)。是个搞技术的好苗子。也希望其他华为的同学们看看Nehalem的介绍。
当然,并不是说Nehalem微结构可以做NS5000E的Forwarding了。只是说,事情都在悄悄地演变着。。。。。。
————————–
1,字节序
2,x86作为通用处理器。架构优先考虑内存带宽。IO性能差,接口不够丰富。总体价格高。通信处理器瓶颈不在计算能力。
3,不过freescale继续熊下去,相信不远ppc就会被x86和mips消灭掉。。。
这两天还在与windriver的人交流Wind River Test Management。我还说难道Wind River也要学Thoughtworks做咨询公司了。不想晚上就看到被Intel收购的消息。
世界变化之快,真是 太刺激了。
Intel想干嘛?
一统天下?干掉arm/ppc/mips?
不知与ATOM芯片的长期发展是否有关系。反正,加强软件力量,获得一大批已经存在的客户account意思是事实了。换言之,华为的VRP vxworks是捏在Intel的手上了。咔咔:-)
这桩收购,带来很多变数.
投奔QNX?
Freescale这下该找谁(montavisa, Green Hills, QNX???)来支持它的芯片?
Cavium还有Netlogic(RMI)它们该如何面对呢?
montavisa我记得好像是Intel是背后最大支持者,powerpc这几年确实有些没落了。。。
华为对intel的芯片很清楚的,有专门的团队在研究,intel也有一个专门团队跟华为负责接口。而且,华为内部也作了intel的刀片,跑suse linux, 供内部使用,以及搭售服务器的时候顺带卖卖。
做设备厂商,性能不是最重要(能满足市场规格就可以),整板,整框设备成本能降下来才最重要。买一个设备挣一笔钱,在选型的时候,某个方案可能因为多一个FPGA片子都可能会导致出局。所以,intel不做soc,基本上没有可能能赢通信市场。
不过,收购windriver,倒是增加了很多变数。
VRP只是数通的软件平台。其他产品线不是基于这个。更底层的是Dopra。不过,hw所有的东西都是工程化很好: 模型简单,上手快(新员工能很快干活),调式手段丰富(出了问题可以有很多追踪/排查手段,这个很对工程化及其重要)。但是,从纯软件设计角度看,结构很差,很混乱,效率/性能也是非常低。
1. X86的对于嵌入式系统来讲,是综合性的欠佳,不是单一的某个方面.比如讲功耗,有人说ATOM的功耗很低,可是你仔细看下ATOM的功耗低是只它这颗芯片的功耗,没有包涵外部的桥芯片等等.而现在的嵌入式系统都是SOC,我们讲RMI还是OCTEON,这些芯片是都是直接出几十G的外围接口,在看看通信设备的需求,有XAUI/PCIE/SERDES等等不同的接口,但是X86就需要挂桥,还是桥,这个整板的功耗是多少?这个成本又变成多少.所以大家看问题要站在系统设计的角度去看,而不是只是单纯的从一颗CPU,单纯的看它的CACHE有多大,主频有多高.真正有系统设计经验,熟悉多核的架构师,应该会明白我的意思.而不是只是简单的测试一下.
2. 至于安全厂商大量应用X86架构是有历史原因的.而且目前众多的安全厂商正在转入MIPS多核领域.
3. 目前对于华为这类通信厂商,其平台软件是综合支持各类体系的CPU,无论你是MIPS还是X86,这个无论哪家厂商出问题,华为收到的影响有,单不是绝对的,只要软件适应多核架构,有被选的方案,并不是主要问题.RMI被收购,其实从可靠性来讲,倒是更好了,要不作为私有股权,RMI就像是一颗炸弹,这回加入NETLOGIC,反而应该会有更好的发展,倒是CAVIUM面临的竞争会更激烈,因为相对来讲CAVIUM芯片从将来讲,可能整合性会弱于RMI.比如RMI+TCAM?一切皆有可能
4. 风河也被收购了,又一颗炸弹.大家都能看到上网本的火爆,导致了嵌入式超便携系统的可能,而这个系统,intel还是微软都没有绝对的把握,所以收购风河,加强自己的软件能力,也许有一天intel会收购CAVIUM,who knows.
@hope:
1,你可以用Intel EP80579和Cavium CN52xx或PQ III MPC854x做一个详细的比较-外围接口,价格。另外,Atom的设计功耗是Dothan的1/10,相信基于Atom的SoC也会解决SoC的架构问题。或许x86作为通信处理器的最大障碍是software stack支持的问题,性能scaling对于Intel来说不是问题-只是来自非系统工程师的看法。
2,IMHO,Intel绝对不会收购non-x86的半导体公司了-肯定也不会收购AMD 我觉得XScale/IXP的出售都说明了他对x86的信心。
@kiss
Tolapai平台在国内已经发布快一年,跟intel一贯的做事风格类似,发布时就已经携带了很多合作伙伴做好的应用来展示,基本上是已经成型的产品。 但是,目前市场上用于这个平台的产品并不多,在二三线安全厂商有一些产品,不过也不知道市场卖的如何。Tolapai的双核版本好像还没有发布。至少目前从市场看,Tolapai还不能说有多大成功。
和你的观点恰恰相反,如果x86是software stack的问题,intel很容易去解决。想当年IXP多么庞大的软件库,intel都做得非常好,所有通信厂商都对此赞不绝口。我以为还是和硬件/系统设计相关部分的才是目前x86的弱点。
Xscale/IXP出售不是对x86的信心,而是迫于无奈:看不到获胜的前景。在出售他们之后很长一段时间内,直到现在,intel对于如何重新进入这一市场没有明确路线图。
而当初intel进入NP市场,软件/硬件/文档/客户培训都是做的非常到位,所以很快能把其他家NP拉在身后。
很热闹,在下也来班门弄斧一把。
X86当前来看在通信领域的应用作为控制面比较合适,而且是在对CPU性能要求比较高的控制面应用,以及对高层业务处理比较多的特定领域,例如DPI。
Intel在Embedded领域是有大的动作,X86也在向SOC方向发展,但其主要基于PC应用的视角设计的处理器确实不适合作为数据转发应用,个人判断未来几年内Intel的X86处理器在转发领域难有所作为。如果Intel确实想进入这一块市场,只能通过收购一家合适的公司,靠自己的得看3-5后的X86新架构如何做了
Intel收购WindRiver的影响估计通信业界都会在看,看Intel的后续策略,如果其能保持原有的第三方态度,能够很好的支持PPC/MIPS的后续发展的话,Vxworks在通信领域会得到继续的发展。但这点很难,这和intel想在Embedded领域大展拳脚是冲突的。
linux和FreeBSD之类的软件可能会对此次并购持欢迎态度。相信有长远目标的公司对是否继续使用vxworks会进行深入的评估,很可能会转型,因为PPC/MIPS的新一代处理器如果Intel不支持,其后续的产品是没有发展的。
X86在数据面的应用,先不考虑其性能如何,首先产品的系统方案就会很复杂,需要配合大量的外围芯片,硬件综合成本非常高,工程实现也是一个很大的挑战。
@随便扯两句:
thanks for your information
我想问个问题,如果Software stack等等不是问题的话,Tolapai(1088-FCBGA)的封装-比CN52xx(729-BGA)和PQ III(783 FC-PBGA)多了300+个pin-对系统设计的芯片选型大概有多大影响? 是不是对board cost/reliability等等方面来说。
顺便请教一下各位大大:一般来说本土厂商系统工程师选择芯片大概是个什么样的优先级?
RMI要被卖掉在圈子里面已经流传了很久,应该是一个半公开的秘密,可能最大的秘密就是谁来接盘了,没想到突然爆出Netlogic来。
TCAM由于其优异的查找性能在转发领域的贡献是有目共睹的。由于TCAM的功耗与其容量基本是线性增加,随着路由表和转发表越来越大,在核心路由器领域,TCAM的容量问题已经成为转发表的一个瓶颈。
在中低端领域,10G以下处理能力的设备,低成本的解决方案还是比较多的,RMI的竞争力并不是很明显。
如果如前面的大侠所评论的那样,Netlogic希望通过收购RMI来增强其TCAM的竞争力,用处多大实在难说。一句话,Netlogic收购RMI的效果有待继续观察。
根据个人的经验,大厂是不能迷信的,这年头,挂羊头卖狗肉的多去了。观察某个产品的长远发展要看这个产品在其公司的地位,只有其核心产品的保障性才强一些,外围产品特别是跟风想赚一把的,前景都不太美妙。
IBM实力强吧,但因为NP得市场对于IBM来说实在太小了,发展又要投入很强大的力量,最终还是放弃了。
Intel更是前科不少,在光通信一片火热的岁月,Intel也毫不犹豫的进入,收购一些公司,不知道有没有听说过Intel的10G光收发模块,但现在早就解散了,其相关的IC业务也卖完了。还有IXP的例子,前面的大大已经说了不少。
Cavium在下一代多核的进展上好像碰到困难,其路标已经再三推迟。。。Cavium在这个领域能走多远,也许很大程度上就决定于其下一代多核的成败上面。
Freescal在多核上反应比较慢,不过终于还是反应过来了,不管是CORE还是芯片规划,在后续的发展上有着相对清晰的路标。在下一代多核上,FSL除了延续在控制面的竞争力之外,在IO处理上也在大幅跟上,同时其节能和安全加速引擎看起来也还可以。
也许在1年前Cavium/RMI还能够比较轻松,但相信09年10年后,FSL的压力应该是很明显的。注意啊,是FSL侵入Cavium/RMI领先的领域,而不是全面的竞争。
只要FSL的内部不发生问题,从长远看,能够和Intel抗衡的还是FSL。
还有一个ARM,现在发展势头还是比较猛的。ARM携其在消费领域的霸主地位,正在向更高端的领域发起冲击,这是其发展的必然,也是终端消费领域发展的需要(各种智能终端产品的功能越来越强大,对CPU的处理能力必然要求更高)。
因此,在低端市场,PPC必将面对ARM的竞争。
这样看来,PPC以后的日好像不会太好过啊,前有狼后有虎,高端有Intel虎视眈眈,低端ARM在发起冲击,中间还要和MIPS周旋,苦啊。。。。。。。
观察处理器的时间不长,上面乱七八糟写了一些,有不对的地方欢迎各位大大指正。
此外,建议弯曲开辟一个处理器专栏,以便朋友们交流各种信息和讨论
ALL IP分析的很有道理,建议也很有价值。支持。
谢谢建议。会讨论。Stay Tuned。
赞同ALL IP的观点,未来处理器的一定是X86和ARM的天下。
intel的技术就不用多讲了,那些到现在还认为x86不适合嵌入式通信领域的就大错特错了,intel 一直没有停止过在通信市场的脚步,尽管放弃了IXP产品线,现在intel 把面向嵌入式的产品都转到X86上,后续的路标完全可以取代PPC和MIPS多核。
ARM给人的印象一直是消费电子的性能,现在新的ARM多核的DMIPS已经和PPC,64位MIPS的性能相当。ARM支持厂家众多,从纯技术的角度考虑,ARM的寿命肯定超过MIPS。
MIPS面临的困境是其性能不能和网络处理器类的产品抗衡,不能做到高端数据转发平面平台中去,如果做控制平面根本不能和Intel的多核对比。另外,基于Mips架构的芯片的性能根本不能达到厂家宣传的规格,基本上缩水三分之二。我说的是全业务流量处理,不是简单的一个没有跳转的pipeline的转发。尽管集成一些硬件加速器,个人认为还是归为通用CPU类吧。
和网络处理器相比,MIPS多核在基于通用C编程性上不可否认有一定优势,但是其问题是性能优化,问题定位,代码维护方面远不如网络处理器方便。
MIPS多核的成功在中国,没有H和Z公司的支持,RMI,Cavium估计早就坚持不住了。在无线接入,中低端路由,安全等领域占领了一步分市场,这是以前都是PPC和网络处理器的市场。
在说说网络处理器,其硬件的性能,软件的编程性,经过十几年的发展,其市场空间并没有大家预想的那么大,很多都退出了这个市场,现存的占据市场三分之一的是intel的IXP系列处理器,其次是LSI(agere),wintegra,Ezchip,AMCC等。由于intel放弃了IXP的后续研发,在高端市场上Ezchip,Xelerated两家逐渐成长起来,不过Netronome(获得IXP技术的公司)也开始发力继续开发基于IXP技术的新产品,正在迎头赶上。Xelerated 的客户就是H公司,没有H,X公司早就game over了,Ezchip尽管没有拿下H公司,但在Z公司也占有了一定市场。这两家公司主要在核心路由,光传输等项目。
高端市场上,随着Netronome的后来据上,相信高端市场的竞争更加激烈。在编程灵活性上没有一家网络处理器能和基于intel的IXP架构相比。
第一次访问弯曲评论,简单拙见,纯属个人意见,欢迎深度交流。
楼上的口气很大,感觉你对网络处理器比较熟,且对其有某种偏见。
笔者认为,
1. x86不可能在通讯数据平面有所作为,这个大家已经说得很多了。纵观intel的历史,它曾经也想进入通信市场,但结果呢?然而在控制平面还是有极大的可能。Intel收购windriver,其目的很明显。用它的atom去侵入arm的已有市场。
2.PPC/MIPS不可能消亡。embedded是个细分的市场, x86, arm不可能通吃.但ppc/mips来自x86,arm的威胁会越来越大.将来的日子肯定不会太好过. PPC,现在该叫Power了. 目前主要有IBM, Freescale, AMCC支持.曾经有个PA semi,最后Apple买断了. 还有xilinx FPGA也集成了IBM的4xx core,但貌似xilinx准备抛弃它了. Freescale应当是Power的主力军,如果它哪天倒了,那莫Power(ppc) 阵营也即将瓦解. Power在IBM也就是它的server/supercomupter在用,其出货量很有限.再说,IBM现在大量采用x86作为它的处理器. AMCC就不用说了,它的主力都来自IBM.没有完整的产品线,市场份额也不大.一句话,PPC的未来就靠Freescale了.
PPC太自大,不open.相反MIPS跟PPC不一样, 它的license模式比Power要强一百倍.不少公司license了,在STB, HDTV, networking还是有不小的份额.在相当长的时间了,MIPS ISA不应该会倒.(对了不是还有个ICT的Godson??? :)), ARM是其最大的对手了.
3.个人很看好ARM的前景, 其商业模式和产品技术上都值得称赞. 它的ecosystem很庞大很完善.其规模不亚于x86在PC市场.
技术层面,arm汲取其他体系的精华, superscaler, mutli-core,.. (mutli-thread?)还有SoC bus. AXI总线(split, out of order)..
重要的是open….成打的IP基于ARM的总线标准.
intel要打败ARM还是很难. 个人觉得intel cash flow太多, 烧得慌!
4.NP专著与data plan, 目前高端市场固然有一定市场. 但随作 mulit-core GPU with network acceleration地加入, 和设备商的ASIC/FPGA for dataplan.
市场份额下滑是一种趋势。
未来的处理器一定是谁的天下估计还是很难说的吧,从目前来看,Embedded处理器市场3-5年内应该是群雄争霸的时代,X86、MIPS、ARM、PPC都有一定的机会更进一步。
如果Intel真正打算向做PC一样来做Embedded的话,几年以后倒是很可能成为一支强大的力量,前提是Intel的处理器架构会为Embedded而改变吗
ARM在低端消费领域是无敌的,但要向上走,其成本功耗的优势还能有多少,还需要观察,性能要求越高,相对的对成本的敏感就相对低一些。特别是进入通信领域,可靠性要求越高。。。ARM任重而道远矣
NP最大的优势是灵活性,但灵活性也就决定了其技术的复杂性和可实现性,到目前10G/20G NP才比较成熟,而40G NP等了n年了都没有出来,100G就更不知道在哪儿了。。。在IP领域顶峰还是得靠ASIC+FPGA来搞定。NP在中低端市场还比较现实。但随着多核CPU时代的到来,在这个领域NP和多核CPU(MIPS/PPC)有得争。。。
不少大侠对Intel的IPX好像很推崇。据本人的了解,IXP12xx、24xx的市场表现还可以,可能很多安全领域的在应用。
而ixp28xx,则是一种无奈的选择,当时在10G NP市场也很是热闹,可惜AMCC半途而废、IBM不干了、好像还有一个Agere,但28xx好不好可能只有用它的人才有发言权。28xx其实本质还是一个5G的NP,10G还真是难为它了,cisco后来用它做了一个5G的处理平台
同意楼上的。。。
得。这几天x86派的得势,MIPS选手不吭声了:-)。PowerPC的人马就没有出现:–(。
怎么这么快就划分势力范围了,陈首席觉得在下应该是哪一派呢,呵呵
吐血敲了这么多键盘,没有入得高人法眼,几无响应,积极性都有点受挫的感觉了。。。。。
在通信和网络市场,我个人觉得可以从设备商的decision maker的角度看这个问题, 他们不会太关注powerpc Core还是MIPS Core, 重要的是SOC, 是接口, 是feather, 是功耗, 是die size, 是内部加速器; 如在存储市场, 额外卖点在RAID接口, TOE功能等; 在无线市场, 额外卖点在SRIO, SNOW3G等; 在网络interface Card,卖点在于接口(如XAUI, SPI4), 保序,流原子, QOS等等; 从这个市场看, 并不是power跟mips的PK, 而是cavium, rmi, freescale公司之间的PK.
所以X86,ARM怎能一统天下呢???
不同的maket segment有不同的需求,
设备商的需求是多样的。
die size设备商还关心?他们更关心money, price.
还有
* roadmap
是否有持续发展的能力。不会那天我量产时,你都关门了。
* 价格/供货
* 技术支持。
等等
ALL IP,我一回到家就是看是否有讨论。你们的每个发言我都是反复看和想。自己也学习了许多。
我对IA32,ARM/xScale(4xx,23xx), MIPS(5K,7K),PowerPC(4xx,7xx,74xx)都有工程级别的实战接触。这里面,我对xSCale是不太满意。换言之对IXP不太感冒。MIPS其实对系统软件工程师不太方便做大系统,特别是如果是32位系统。PowerPC和IA32不错。另外,我对EM64T,也就是x86的64位计算看过一些东西,感觉很decent(干净)。
在最近的评论中,关于ARM要朝通信和高端设备上抢饭吃,是非常重要的,而且是在发生的。。。
die size设备商当然关心啊; 比如无线市场, 很小一块板需要放入一个多核cpu, 多块dsp和fpga, die size也是很重要的; money, price, roadmap, 支持当然都是非常非常重要的, 我前面的意思是一个当前产品的卖点, 不是说公司的卖点; 设备商选型当然是全方位的, 我前面更多的是指产品这一块;
那是package和pin的规模.不是die size.
40G NP已经商用。
@陈怀临: 我挺ppc的-曾经吃饭的玩意 :_ )
@螺丝钉: 多谢解答。继续请教一下,如果core不是differentiator的话,从应用角度来说,目前要使设备商迁移到另一种处理器/SoC是不是不存在太大困难?另外,对于芯片供应商来说,那些接口,feature,功耗,加速器也不容易差异化吧?
看了各位大大的帖子,也凑个数,纯属抛砖引玉
从通用core/processor的角度来说,接下来五年内的竞争非常有意思,太长远的就算了-”The long run is a misleading guide to current affairs. In long run we are all dead”。个人觉得,x86和arm现在的位置都处于上升势头。因为都有killer customer,有volume可以支撑继续投入: arm统治mobile handset,x86是pc/server。而ppc/power的位置有待持续观察,mips的形势就不太妙了。
MIPS:商业模式跟ARM雷同,缺乏占垄断性地位的市场,消费类市场高端部分肯定受arm的侵蚀,通信市场受ppc压迫,还有新进入者x86。目前来看处理器方面有完备的产品组合(低中高端),但一些MIPS vendor,如Broadcom/PMC等都不在core上继续投入了,而反观ARM,除了ARM本身,Qualcomm/Marvel等作为ARM的架构受权者都在积极推动处理器内核的研发。MIPS Technologies作为公司能不能生存下去我都觉得是个问题-最近买了chipidea又卖了就是个证据,他自己都还在寻找战略。实话实说的说,MIPS卖给ICT/Godson倒是个非常好的归宿-跟党走,大富大贵不一定,衣食无忧是肯定的,这样才可以保留一个“通用”处理器的名分。
ppc/power: 在部分市场(通信,Game Console,HPC)占一定统治地位,还有个强大的爹娘-但都三心二意。但各厂商之间研发重合,同样存在互相竞争。
IBM,嵌入式系列卖给AMCC-但却依然继续开发4xx系列内核,桌面处理器在apple那里被干掉了,服务器的POWER系列处于防御状态,mainframe也一样面临x86/IPF的进攻,而且他自身还有个强大的x86产品线。
Freescale作为公司也是有麻烦,基带部分没卖出去,公司除了占据较大市场份额的网络通信处理器,还有mcu/Arm-based应用处理器等产品线,在保证roadmap的情况下,通信处理器的统治地位短期内应该不会有什么变化。
AMCC的ppc好像是专注于storage市场?P.A.Semi有一个卓越的设计,但Apple买来就砍了。
随着市场环境的变化-arm/x86对处理器市场的渗透,各个ppc厂商都需要回答一个问题-能否保持足够的市场份额和收入来保证持续的研发投入?未来或许ppc厂商面临巨变-个人觉得成立power.org远远不够,”what if”整合成一家厂商?
顺便再搭车问一下:
1,FSL的e700是不是砍掉了?全部转到e500/e500mc?这个应该没有NDA吧,我记得2006年之前的FTF还有谈e700,2007年好像没说了,后面的FTF没关注了。
2,Xilinx嵌入405/440的FPGA主要是用在哪方面?系统厂商方面的对这种产品的感受如何?
x86: AMD几乎给不了Intel任何压力,本身已经自宫-”only real men have fabs”,如果本身的设计再出麻烦,生存都是个问题。所以Intel现在可以聚焦于“x86 anywhere”了,Intel在芯片设计和制造上的优势明显-领先6-12个月(?),技术上的两个短板low power x86 and SoC-目前有14款32nm工艺的atom-based soc正处于开发中(source: EETimes),针对嵌入式市场的software stack的软件链都正在解决中。接下来主要的PK,一是在mobile internet device上跟arm,虽说击败arm不可能,但占据部分市场份额是一定的。而且这一次必须要狠狠地打,应该是首要目标,也是接下来最大的看点。二是GPU,x86-based Larrabee Vs NVidia。三是非MID的消费类电子,其中包括game console(这是个量很大的市场,如果赢了,可以烧掉ibm微电子的一个大粮仓了)。与上面一位大大提到的相反,在Atom上和TSMC的合作,并非不重视,而是一个战略性的举动,适当的时候可以将Atom直接授权给系统厂商(Atom的IP不对半导体公司开放的),抢占市场。另外,Intel的力量还不仅仅在技术方面,市场力量同样强大,Pentium 4可以说是一个比较失败的产品,但却依然是市场上一个成功的产品。但x86是否将通信市场视作tier-one目标就是一个问题了。
结论:long x86 and ARM, no idea on ppc, short MIPS, as general-purpose processor
@KISS, ,个人觉得core不是differentiator,从应用角度来说,目前要使设备商迁移到另一种处理器/SoC应该难度不大,大公司一般会做一些多核支撑平台,减少各种产品差异性; 而且迁移更多是工作量问题; 当然如果厂商特有的feather, 移植需要费点劲, 如用到octeon的定时器功能,flow atomic功能的话, 迁移到rmi上就需要使用软件或者换实现方法;
对于芯片供应商来说,那些接口,feature,功耗,加速器差异化技术上讲也容易互相学习模仿, 但是市场的原因会有个继承性和一些取舍问题; 比如从路标上看, rmi更侧重作更强的内核,更多的cache; cavium更侧重更多应用加速器; FSL更中规中距一些, 没看到太多出彩之处; MIPS多核在安全,通信,存储等领域应该会有一席之地;
同意24层whoknows.
不能用PC的视角来看通信设备。
25层“NETLOGIC在国内的业务最主要就是hw/zte,他们需要大量使用tcam+多核处理器的方案,两个公司合并以后,可以给他们提供更好的解决方案和参考设计。”
1。问题是有多少RMI的核心成员能留下?
通常startup被收购后,人员会大量流失。
2。两家公司整合roadmap, IP merge也得需要时间。
hw/zte能等多久呢?
29层陈怀临
”
很热闹。我问一个问题。为什么?1.为什么x86更适合于PC和Server?但不能回答1说服我自己YET。”
个人认为,
1. 历史
2. 生态系统.
46层KISS
“x86在通信市场的看点不是Nehalem,而是将来基于Atom的SOC。…采用Atom之后,只怕每个通信处理器厂商都得紧张一下了。Intel的优势实在太多了-制造,研发力量,以及x86的低成本,但能否在通信市场成功还得看商务(business)方面的因素。”
我们不得不承认Intel有强大研发制造实力.但用一个in-order, single issue的atom集成tolapai的外设,很难想象它在网络通信市场能有多大作为.
@ JackBauer: 40G NP已经商用?方便透露一下吗。。。。
kiss也是一位资深人士啊,据了解,FSL后续可能专注于e500mc了
@ KISS:据了解FSL可能专注于e500mc了
补充一个有意思的说法:在80s-90s初RISC热潮兴起的时候,一度占据了server市场的很大份额,但pc上失败了,原因是:MS的OS代码较烂,而且使用了大量汇编,x86也较复杂很难移植到新平台,而服务器系统一般采用unix,代码很容易进行移植,RISC也很简单,所以小型机就挂了。
后来,随着x86的发展,同样是因为服务器上unix移植性好,而且risc也较简单,于是又转到性价比更高的x86平台了。
ps: IBM去年有一个防御性收购-Transitive,最著名的就是支持了Apple Rosetta系统背后的公司,专门用软件干这种事。
—————————————
很热闹。我问一个问题。为什么?1.为什么x86更适合于PC和Server?但不能回答1说服我自己YET。”
40G NP: Bay Chesapeake和Broadcom BCM88025/QE-2000都量产了.
Xelerated的HX330有望成为第一颗100G NP,
原计划2009 Q2 sample,不知道现在如何?
@aaa: 这里确实值得商量-free post,价值是free :_ )
1, atom不是针对网络通信市场的核,主要针对ARM。而且intel如何看待通信市场,通信系统厂商肯定更清楚。
2,atom是多线程,从指令集效率来看,或许x86的single issue可以与MIPS的1.x issue相当-不过这得根据具体应用特性
3,从低端入手,得到volume,再向高端演进是很好的做法。至于x86会否有所作为,大家一起观察…
@ALL IP?:thanks。这么说来freescale短期内是不会有64bit的ppc了
大地址空间,大内存的需要越来越迫切,尤其在高端的系统.64bit core 是一种发展趋势.
Freescale不可能miss它.无论是叫e700还是e500xx,
64bit core迟早会上.
谢谢aaa!
我说的40G是指上行/下行都为40G,而不是上行+下行=40G。
QE-2000就是一个20G的TM,88025估计也是20G的吧,虽然提供了24GE+2×10GE接口,但实际上应该是收敛到20G,而且是以太,同时不知道性能如何?
HX330也是如此吧
—————————————
aaa 于 2009-06-07 6:23 am 40G NP: Bay Chesapeake和Broadcom BCM88025/QE-2000都量产了.
Xelerated的HX330有望成为第一颗100G NP,
原计划2009 Q2 sample,不知道现在如何?
确实如此!
—————–
aaa 于 2009-06-07 6:35 am 大地址空间,大内存的需要越来越迫切,尤其在高端的系统.64bit core 是一种发展趋势.
Freescale不可能miss它.无论是叫e700还是e500xx,
64bit core迟早会上.
Xelerated的HX330,2009 Q2 sample,确实现在没有update了。100G的目标,基本上是cut-through,因为HX330内部TM只有50G能力的限制。
还有Ezchip 的NP4,估计也延迟了。
Bay Chesapeake基本上没有什么市场,Broadcom BCM88025/QE-2000在国内只有一个项目。
@aaa:
可据我所知,e500mc只是用一个传统FPU取代了SPE,最大的变动是增加了hypervisor支持。不过e500v2已经支持36bit物理地址空间了。
e700是一个64bit,4-issue(?)设计,流水也比e600长-一时找不到那篇文章了。
@螺丝钉: thanks
and…
e500mc
* 128KB backside L2 cache per core虽然个人认为少了点。
* CoreNet接口,这个很重要。
* new core to core signaling (msgsend/msgclr).
* 中断优化, interrupt proxy.
“e700是一个64bit,4-issue(?)设计,流水也比e600长”
pipeline长不是件好事.如何能达到主频要求.个人希望Freescale还能保持它的7段流水.
我会在美西时间星期天的晚上8点,将这次大家对多核系统,处理器方面的讨论整理出来,并且发文。
我觉得是非常好的一次讨论。
我个人对处理器接触比较多,也参与设计芯片。但感觉真是天外有天。你们说的许多我都不懂。
这就是集体的力量。
期待陈先生的整理结果,从前面各位大侠的发言中可以看出,很多人都是行内的资深人士,可能受限于职业操守和NDA的限制,在很多话题上不能深入透彻,但也可以看出不少有用的信息。
希望关于处理器的讨论能够继续下去,更希望早日能够用到我中华自主之处理器芯片!!
螺丝钉:
在通信和网络市场,我个人觉得可以从设备商的decision maker的角度看这个问题, 他们不会太关注powerpc Core还是MIPS Core, 重要的是SOC, 是接口, 是feather, 是功耗, 是die size, 是内部加速器; 如在存储市场,额外卖点在RAID接口, TOE功能等; 在无线市场, 额外卖点在SRIO, SNOW3G等; 在网络interface Card,卖点在于接口(如XAUI, SPI4), 保序,流原子, QOS等等; 从这个市场看, 并不是power跟mips的PK,而是cavium, rmi, freescale公司之间的PK.
===
这个我要顶,一看就是专家
1,大家对ISA讨论得很带劲。其实说白了,ISA之间的PK就一口水坑。同意KISS大大的引用—“从长远看,人都是要死的”,所以不太关心ISA之间的pk
2,我认为讨论一些更实际的东东则更有意义。上面的螺丝钉大大已经开了一个好头。各位大侠继续……
112楼 陈怀临
“
得。这几天x86派的得势,MIPS选手不吭声了:-)。PowerPC的人马就没有出现:–(。
”
===
首席,
windriver都让intel给收了,这几天x86自然很得势了。
mips吧,就看rmi和cavium撑撑门面,自然势单力薄。
至于powerpc吧,fsl的兄弟老大哥做惯了,不屑讨论此类问题了。
诸位贤弟为什么从来不提及IBM当讨论PPC的时候?
@matrix:
===
这个我要顶,一看就是专家
===
hehe, 偶不是专家, 只是个行业的螺丝钉;
另外我觉得MIPS多核的优势就是在多核SOC上先行了一步, 形成了一定的客户群和生态系统; 缺点在于rmi和cavium都是小公司, 在下一代路标上行动有点慢, 不过总体还是看好MIPS在通信网络等行业的发展。
这个讨论值得收藏细细品味,实在受益匪浅!
是的,曲径通幽处,禅房花木深。这次大讨论,其中蕴含之精华对于做芯片的,做网络的,做系统的和even做应用的都是很值得阅读的思考的。当然,各人的悟性和收获多少就看各位施主自己了:-)我已经cut并且在整理了。Stay tuned。给我2个小时at maximum。
首席在第117 comments 提到:MIPS其实对系统软件工程师不太方便做大系统,特别是如果是32位系统。
我对这个观点很感兴趣,能否展开详细说一下,跟首席好好学学:-)
是的,MIPS32其实是个大事情。。。。。。等我的总结。谢谢各位贤弟。
netlogic不是推过正则表达式的chip么?
http://www.en-genius.net/site/zones/networkZONE/product_reviews/netp_040609
窃以为 netlogic的收购跟它的TCAM关系不大,到是跟上面说的安全chip有关系.
想想greefiled吧.如果你做的好思科直接就拿过来了
看了很多评论,发现一个有意思的地方,对于通信背景的人来讲,普遍会提出接口,BOM成本,配套软件等等的质疑,这些都是X86体系的缺陷。
而力挺X86的技术人员都会说:如果我做成SOC,如果我支持软件等等。
注意这些都是如果,不是实现。不要说英特尔会不会迈出这一步都需要考虑(出售网络处理器部门)就是X86真的改作SOC,它的功耗会是多少?基本上ATOM要2.5W。与ARM相比毫无优势,与MIPS相比,目前一个16核的CAVIUM MIPS,在40W左右,这是包含接口的功耗。X86如果在加上桥的功耗,在加上外围接口的功耗,会是多少?在说ATOM目前还不是多核,MIPS已经64个核心了,如何对比?
如果一切讨论都是建立在如果上,那是没有任何意义的。
目前形式是:
ARM 坚守功耗优势,在消费类电子领先
PPC 在各类嵌入式设备上具有优势,但是由于飞思卡尔的研发速度缓慢,这是值得担心的地方。
MIPS 大量startup公司的出现,包括目前64核都已经出现,在通信市场越来越成为主流,了解的人应该知道,目前通信设备大量控制面的主控CPU将来都会被MIPS替代。至于说X86做控制面,目前来讲,没有一个型号合适。
X86, 其实和上面的CPU根本就是不同领域的,复杂指令集,坚守PC,服务器等领域,目前在大力发展上网本,手持MID等消费类电子,这才是英特尔收购风河的根本原因。降低ATOM的功耗,借助风河的软件,大力挤占原先PPC的市场。不过nvida也加入进来插了一脚。而对于通信市场,目前来看,X86这几年不会进入,除非改作SOC,而相对于MIPS来讲,也没有必胜的把握,因为在多核数量上,MIPS已经走在前面了。
to 大力水手和all ip
首先CAVIUM的路标就我知道并没有推迟。CN63系列已经流片发布。
其次讲用X86做通信设备的控制CPU,我只能说一厢情愿。第一你讲到华为中兴的应用成就了RMI这类公司,这不是本身就证明了在通信市场,目前的X86CPU 没有竞争力,要不为何不选择X86?第二,不要说华为成就了CAVIUM,CAVIUM的成功是在于抓住了思科,和华为没关系。
再次,不要把MIPS归入通用处理器,你这么划分,只有龙芯会偷着乐。
最后,希望大家能明白,处理器和人一样,术业有专攻。MIPS,PPC,ARM能够存在这么久,是由原因的,在于功耗,在于告集成度等等。
X86有自己的优势,但不是说它一定就适合所有的应用场景。目前市场上X86,你用它去做通信设备就和你用龙芯去做笔记本一样,没有竞争力。
@ hope:
Cavium的新一代路标虽然低端发布了,但高端产品推迟了吧?FSL的P4080同样推迟了一些时间。。。。
关于X86在Embedded领域的应用,请仔细看我得评论,我个人认为在短期内难有作为,其前途要看Intel在3-5后的新架构。但在控制平面领域,特别是在最高端的路由器应用上,其计算性能优势是极其明显的,实际应用的例子可以看Juniper的TX plus的新一代RE 2.66G 双核 支持16GB内存、cisco ASR1000系列RP从第一代的PPC迁移到双核X86、N7000的RP板直接用X86,抛开Juniper,就ASR1000和N7000的网络定位来看,PPC确实不能满足要求,MIPS就更不用说了。
但是,上面这些也仅仅是说明在某些要求很高的场合会用到X86,在大部分场合还是用PPC(X86的性价比不合适),这也是X86的路子还很长的原因。
cisco 在早期的路由器和交换机的CPU用的就是MIPS,直到12XXX系列的前几代RP还是,到后全面被PPC替代了,这是不是可以说明PPC更适合作为控制面应用呢
Juniper的RE一直用X86,但其线卡和其他管理CPU用的却是PPC。
MIPS的优势在IO、在集成了业务的硬件加速,但在控制面,计算性能是最重要的,MIPS在这方面的表现如何做MIPS的大大心里都有数,hope大侠MIPS将在主控CPU领域替代PPC的判断依据或信心来自哪里呢?
BTW,caivium一年的收入是多少,cisco一年处理器的采购金额会是多少?二者根本就不是一个数量级的吧。。。。
对于ARM,如果还是认为其是低端的大大,建议了解分析一下其最新的版本,据说其性能已经可以达到2~2.4DMIPS,这已经和FSL的e500 core性能差不多了。。。。
此外,多核并不是MIPS的专利,ARM同样可以做。
补充一下,X86的SOC化已经是必然,不管其是否用于Embedded通信领域,至少CPU+MCH是合一的,相信了解X86最新进展的大大都知道。
此外,我个人并不认为SOC了,X86就适合通信应用了,还是和其功耗、方案的性价比密切相关的。
@ALL IP, 看财报的话, cisco应该占cavium全部产品整个销售的25%左右, 多核这块的比例具体不清楚; 中国市场应该还没有起量, 连RMI 08年中国的量都非常少; 多核MIPS应该首先在美国市场成功的。
另外如果同样是45nm技术的话, MIPS作控制能力也不会弱于X86的; 比如rmi xlp支持4issue, out of order, 主频可2G以上, 并且多核, 功耗还低。
多核ARM好象也有听说, 好象Marvell推出了多核arm?, 也在通信领域推? 具体规格不太清楚;
@螺丝钉,谢谢!
cisco对于cavium很重要,占了cavium很大的收入比重,但cavium对于cisco的重要性又有多少呢,10%?胡乱猜测的,有了解情况的大大指点一下。
MIPS人马终于出现了. 是Cavium? or customer of cavium?
@hope
“了解的人应该知道,目前通信设备大量控制面的主控CPU将来都会被MIPS替代。”
学小沈阳问一句 “为什莫呢?”
@hope
“降低ATOM的功耗,借助风河的软件,大力挤占原先PPC的市场。”
Atom目前的功耗已经比PPC要低,问题不是Atom本身,
是它的套片,它仅仅是个core而已.
marvell dual core chip: MV78200
http://www.linuxdevices.com/news/NS6658204257.html
大家仔细看下,
ATOM功耗低,你们也承认仅仅是个CORE。
不要忘记当它开始集成外围IO的时候,它的功耗就不低了!目前MIPS还是PPC的功耗都是说的SOC的功耗。没有可比性。
对于控制面,我不方便明说,但是在通信数据领域,控制面应用多核处理器的趋势已经确定,后面大家一定会看到多核MIPS的应用,计算性能,我不知道你们认为MIPS低的原因是来自哪里,是参与过计算性能的评估,还是参与过控制面的选型?在我经手的项目,我不明说,但是MIPS在同主频下,并不比X86低,目前X86的计算性能的优势主要体现在高主频和浮点等,这些在通信市场,比如浮点,并不关注,而主频的问题,会在明年解决,众所周知,突破2G主频后,在提升的余地就不多了,这时候多核才是方向,而这一点,目前MIPS是远远走在前面,这才是MIPS的核心优势。
CAVIUM之所以先发布63系列,呵呵,我不明说,这是有客户方面的原因的。根本就不是技术上的问题。你看看CAVIUM的3系和5系,原先哪个不是先发布高端的。
我并不是CAVIUM的,也不是RMI的,但是我是负责通信设备选型的,做过多次相关的评估而已。
X86的人总是认为将来我有SOC,可是这一竿子就支到几年后了,几年的时间对于半导体行业是多久,谁能知道几年后,PPC和MIPS又会发展成什么样子。所以谈问题,还是不要纸上谈兵。
目前无论PPC还是MIPS的厂商,基本都是无晶圆厂商,这导致他们在工艺上处于落后,这点才是英特尔的最强的地方,对于代工厂,随着工艺的提升,PPC和MIPS的主频也会逐步提升,预计明年主频就不会和X86相差这么多。
ATOM关注的是消费类电子,当ATOM也想SOC而转作通信市场的话,第一我不太认为英特尔会这么做,英特尔曾经想进入通信市场,但是他的研发成本太高,这个市场竞争也过于激烈,不合算。第二当他开始进入,就需要解决功耗,IO,软件等等问题,这些只有等真的片子出来才能和对应的芯片对比,要不没有实际意义。
总结,X86不是不好,是不适合通信领域,至少在目前的市场上,并没有一款处理器适合通信市场,凭借英特尔的实力,我并不否认他可以拿出一款极具竞争力的X86芯片,但是这一切都建立在虚拟的基础上,在通信领域,群狼并立,英特尔再强也会有弱点。北电当年的设备,为了个E1接口,不得不单独加一个PPC,通信市场的需求太多样化,决定了英特尔很难进入垄断地位,而英特尔的目标肯定是要不不进入,一旦进入就会是这个市场的TOP。从这个角度讲,进入嵌入式消费类电子相对于通信市场将会更合适。
PS:cavium的大部分收入来自思科的采购,北美市场多核的应用走在国内的前面,国内华为中兴紧跟步伐,但是没看到X86的应用。思科对CAVIUM很重要,cavium对于思科,不是很重要,呵呵。
多核ARM,cavium已经在做了,不过总体上arm的多核要落后MIPS的发展,其实PPC也落后了。
而且目前对于低端的交换机,MARVEL这类交换芯片,已经开始集成CPU了,这对于BOM成本敏感的低端设备来讲,无论是cavium还是PPC,都会收到进一步的挤压。对于传统的中高端路由器上的控制面CPU,目前看来多核会是将来的趋势
另外从市场的角度讲,真正起量的,还是中低端设备,这里每块通信设备上的子卡都会有一颗CPU做控制面,在这个领域上,基本上是嵌入式的天下,成本,功耗,IO接口等等。多核的出现,提出了新的思路,原有的中低端交换机路由器,可以考虑在控制面集成更多的安全特性。而对于量极少的高端应用,有的公司由于软件还无法支持多核,这时候主频就变得越发重要,这也是X86的一个优势,但是随着软件的成熟,和PPC,MIPS的主频的提升,对于这类选型,多核会变成最重要的一点。另外高端的这点量,对于英特尔,根本就没进入的必要。他根本就看不起,通信设备的采购量和联想,DELL这类厂商相比,根本就是九牛一毛,毫无议价能力。
matrix 于 2009-06-07 8:53 am 螺丝钉:
在通信和网络市场,我个人觉得可以从设备商的decision maker的角度看这个问题, 他们不会太关注powerpc Core还是MIPS Core, 重要的是SOC, 是接口, 是feather, 是功耗, 是die size, 是内部加速器; 如在存储市场,额外卖点在RAID接口, TOE功能等; 在无线市场, 额外卖点在SRIO, SNOW3G等; 在网络interface Card,卖点在于接口(如XAUI, SPI4), 保序,流原子, QOS等等; 从这个市场看, 并不是power跟mips的PK,而是cavium, rmi, freescale公司之间的PK.
===
这个才是通信市场和通用处理器市场的本质区别!
core的数量多在并行处理较多的场合是有优势的,但core数量的越多,其开销也是比较大的,对软件的设计要求是一个挑战,实际应用效果并不是1+1=2,对于控制面的应用来说,很多进程或路由算法是串行的,从目前来看,2-4核可能是比较合适的,8核以上就意义不大了
从这一点看,MIPS的16核甚至32核,在控制面上应用并没有太大的意义。
此外,随着MIPS芯片主频的提升,其功耗也大幅度提高,在这一点上,并不见得是好事,ARM其实也存在类似的问题
不同意ALL IP的观点,对于网络设备来说,最耗资源的不是控制平面的部分,而是转发平面的部门。多核在并行转发方面的优势是巨大的。
一台路由器只用RMI的8核CPU,不用任何加速芯片,优化后,快速转发就可以达到10G左右。如果只用一块X86的cpu,那么是无论如何达不到这个数值的。
另外,通讯厂商看重功耗,不简简单单是为了降低耗电量,散热也是非常重要的因此。尤其在框式的设备上,一块板子只有那么一点的空间,根本装不上风扇,只能靠风扇模块+散热器,以现在X86的发热量,十有八九是要烧板子的。难道以后的网络设备都要改成水冷的不成?Intel要想在不损失性能的前提下,解决功耗问题,个人认为可能性不大。其超低电压的笔记本CPU,主频甚至不到1G。
ATOM的功耗是降低了不少,可是同样性能降低的更多,最近大量的上网本不是因为性能原因被退货了吗?
同意HOPE的观点,对于网络设备来说,浮点运算的性能并不是很重要,X86在浮点方面的优势完全没有意义。
FYI:
“RMI has not been successful at Cisco. RMI’s largest customer is Dell (EqualLogic)”
http://www.linleygroup.com/Newsletters/LinleyWire/wire090610.html
记得几年前有分析师说过NetLogic的60-70%营收来自Cisco,现在不知道,有兴趣的可以去翻财报。
回头翻了下Linley的一个数据(http://www.linleygroup.com/Seminars/pnc_program.html)
“General-purpose processors for networking and comms”
2007 全球市场容量总共 $1.08B
第一,Freescale,接近50%
第二,Intel,约20%
后面是依次是IBM>AMCC>Broadcom>PMC-Sierra
还有个其他(Cavium,RMI,Marvell)合起来和IBM的份额差不多
根据处理器核架构(这里的统计方法不清楚,是根据core数量还是营收?)
PowerPC约占60%+
后面依次是x86>MIPS>ARM
@hope, @螺丝钉:
请教个问题,如果方便回答的话
你们做性能评估和选型,是跑自己的整个应用?或是有自己的workload模型?
会不会参考某些基准benchmark的数据,比如eembc等?还有会不会请第三方专门的评估公司参与?
先行谢过
EEMBC这种测试可以参考,最好是根据自己的实际情况测试,能跑自己的代码就比较理想了
EEMBC对做芯片的层面上是很好的。做多核方面,有EEMBC MutliBench.是专门为多核芯片的Benchmark。
对做系统(system)而已,EEMBC都不够。必须用自己的应用来测试。
更正一下128层。
atom是two issue and excute.不是single issue.
一般来讲,目前在选型中更倾向与移植完整的应用程序进行测试,主要是不同的通信设备,业务较复杂,普通的测试数据,参考意义有限。