【深度学习】分类神经网络发展 从LeNet到SeNet
最近学习了分类网络的发展,做了简单的整理,仅供自己学习笔记
LeNet:
由Yann LeCun等人在1998年提出,是cnn的基本架构,不包括输入共有7层,由卷积层、池化层、全链接层构成。
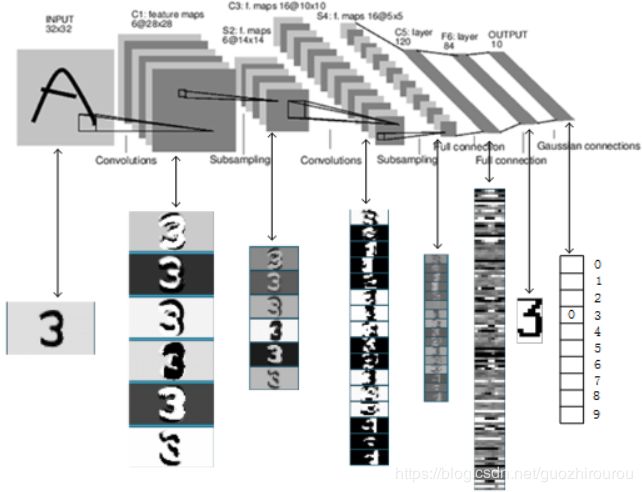
1、输入层:
输入为单通道,32*32大小的图像
2、c1层-卷积层:
输入大小为[1,32,32],
卷积核大小为5*5,
卷积核数目为6,
滑动步长为1,
输出图像尺寸为(32-5+1)*(32-5+1)*6,[6,28,28],
可训练参数数量为 每个滤波器5*5个unit参数和一个bias参数,共6个滤波器,即6*(5*5+1)
3、s2层-池化层:
Pool核尺寸为2*2,采样时,2*2个输入结果相加,乘以一个可训练参数,再加上bias,输出结果通过sigmoid函数,池化后图像尺寸减半,共6个pool核,得到6个14*14的特征图
4、c3层-卷积层:
卷积核大小为5*5,数目为16,得到特征图像尺寸为(14-5+1)*(14-5+1)=10*10
5、s4层-池化层:
Pool核为2*2,共16个pool核,采样时,2*2个输入结果相加,乘以一个可训练参数,再加上bias,输出结果通过sigmoid函数,尺寸减半,得到16个5*5大小特征图
6、c5层-卷积层:
卷积核大小为5*5,数目为120,得到120个(5-5+1)*(5-5+1)特征图
7、f6层-全连接层:
输入为c5层的120维向量,计算输入向量与权重向量之间的点积,加上一个偏置,输出结果通过sigmoid函数
8、Output层-全连接层:
由于LeNet用于数字识别,因此最后一层为10维的特征向量,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i,采用的是径向基函数(RBF)的网络连接方式。
AlexNet:
是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。
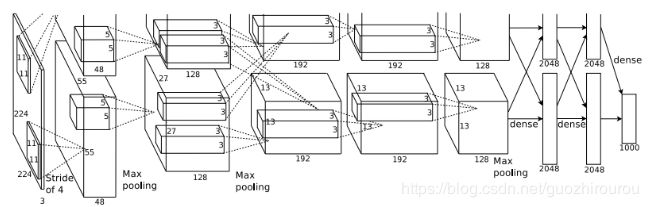
可分为上下两部分网络,分别在2块GPU上运行,到特定的网络层后才需要两块GPU交互,提高运算效率,但上下两部分结构差异不大。
相比于当时LeNet,特点:
1、更深的网络(虽然现在看不觉得多):共包含5层卷积层和3层全连接层,总流程没有改变,但深度增加;
2、数据广增:用于防止过拟合最简单的办法,通过对原始数据进行适当变换,得到更多有差异的数据。且作者采用随机剪裁思想对原图256*256进行随机剪裁,得到尺寸为3*224*224的图像,输入到网络训练。
3、ReLU:用ReLU代替sigmoid加快sgd收敛
4、Dropout:在全连接层中去掉一些神经元,以防止过拟合,在第六层和第七层均设有dropout。
5、Overlapping Pooling:覆盖池化操作,当滑动步长小于pool的size时,即发生覆盖的池化操作,类似于卷积,可以得到更准确的结果。
6、LRN,局部响应归一化:用ReLU激活函数得到的值没有区间范围,故对ReLU得到的激活结果进行归一化,即Local Response Normalization,使ReLU输出结果与其周围一定范围的邻居做一个局部的归一化。
VGG-Nets:
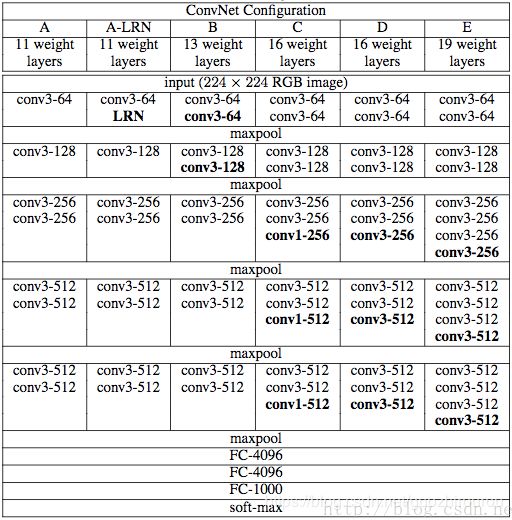
相比于AlexNet,VGG的特点主要在于:
1、更深的网络
2、小卷积核:VGGNet中使用3*3或1*1卷积核,卷积层的参数数量减少;用三个conv3*3可以分解先前一个conv7*7的感受野,且同时能增加非线性激活函数,增强非线性表达能力;1*1卷积核在不影响输入输出维数的情况下,对输入进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力;每层卷积后都伴有激活函数,则可拥有更多的激活函数和更丰富的特征
3、小pool核:全部使用2*2max pool核,滑动步长为2,更小pool核能够更好的捕捉信息细节,max-pooling更容易捕捉图像上的变化,梯度的变化,带来更大的局部信息差异性,更好地描述边缘、纹理等构成语义的细节信息,图像任务大多数使用max-pooling
网络迁移:其他基于VGG-16的网络或者修改最后一层全连接层的大小(不同的分类数量),或者删除最后一层全连接层或删除所有全连接层,后面接上自己设计的网络,可把VGG-16作为图片的特征提取器。
GoogLeNet:
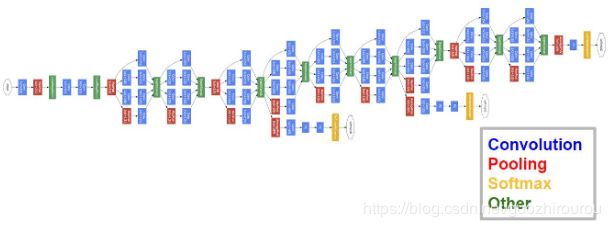
GoogLeNet为22层,参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,在内存或计算资源有限以及模型结果来看,GoogLeNet的性能却更加优越。GoogLeNet的特点在于:
Inception结构
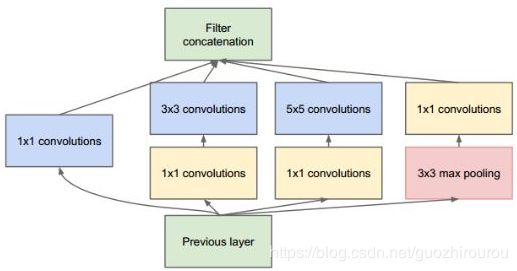
Inception结构里的卷积滑动步长都是1,为了保持特征图大小一致,都用了零填充,同时在每个卷积层后面都立刻接了个ReLU函数。在输出前有个叫concatenate的层,直译的意思是“并置”,即把4组不同类型但大小相同的特征响应图一张张并排叠起来,形成新的特征响应图。Inception结构里主要做了两件事:1. 通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。2. 为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。
1x1的卷积核的作用:
1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。比如,上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256= 819200。而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256= 204800,大约减少了4倍。
1、Average pooling代替全连接层:可以帮助减少参数,网络结构的最后仍有一个全连接层,主要为了方便对输出进行灵活调整,此外全连接层虽然被移除,但依然使用了Dropout
2、增加两个辅助的softmax:为避免梯度消失,增加2个辅助softmax用于前向传导梯度。
ResNet:
2015年由何恺明提出,它通过使用多个有参层来学习输入输出之间的残差,而非像一般CNN网络(如Alexnet/VGG等)使用有参层来直接尝试学习输入、输出之间的映射。实验表明使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射要容易得多(收敛速度更快),也有效得多(可通过使用更多的层来达到更高的分类精度)。
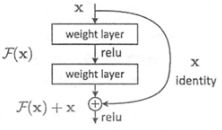
特点:
1、更深的网络层数
2、引入残差单元来解决退化问题
解决问题:
传统的卷积网络随着网络深度的增加,由于梯度消失的问题会导致靠前层的学习停滞,使网络无法训练。且此外,较深的网络需要更大的参数空间,使优化更加困难,而简单的增加网络的深度,因此简单地去增加网络深度反而出现更高的训练误差,深层网络虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差,出现网络退化问题。ResNet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,通过引入残差模块,使整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度,可帮助训练更深的网络。
bottleneck模块:
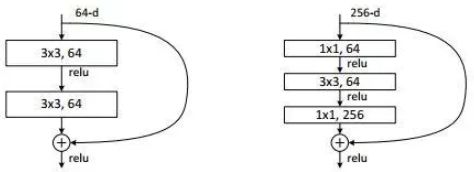
左图是常规残差模块,有两个3×3卷积核卷积核组成,但是随着网络进一步加深,这种残差结构在实践中并不是十分有效。针对这问题,右图的“瓶颈残差模块”(bottleneck residual block)可以有更好的效果,它依次由1×1、3×3、1×1这三个卷积层堆积而成,这里的1×1的卷积能够起降维或升维的作用,从而令3×3的卷积可以在相对较低维度的输入上进行,以达到提高计算效率的目的。
Xception:
Xception 是 Google 继 Inception 后提出的对 Inception-v3 的另一种改进。Xception 的结构基于 ResNet,但是将其中的卷积层换成了Separable Convolution(极致的 Inception模块)。作者通过借鉴(非采用)depthwise separable convolution结构对Inception V3进行改进。
作者提出:the mapping of cross-channels correlations and spatial correlations in the feature maps of convolutional neural networks can be entirely decoupled.可理解为,将通道卷积和空间卷积进行分离。
Inception-v3的结构:
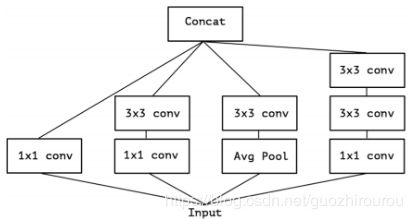
对 Inception-v3 进行简化,去除 Inception-v3 中的 avg pool:

提取公共1*1卷积部分:
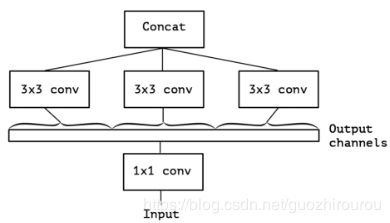
Xception结构:对1*1卷积后的每个通道进行3*3的卷积操作,将最后的结果进行concatenate操作
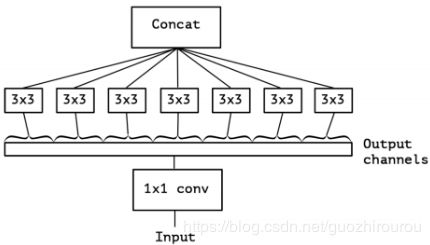
Depthwise Separable Convolution 与 Xception 区别:
1、Depth-wise convolution是先逐通道卷积,再进行1*1卷积,Xception是先进行1*1卷积,再逐通道卷积
2、Depth-wise convolution中两个卷积之间不含有激活函数,而Xception中经过1*1卷积后会带上一个ReLU激活函数
作者认为带激活函数的Xception相比于没有激活函数的Depth-wise convolution收敛过程更快、准确率更高,而两者关于1*1卷积和3*3通道卷积的顺序差异,作者认为影响不大。
实验对比结果:

ResNext:
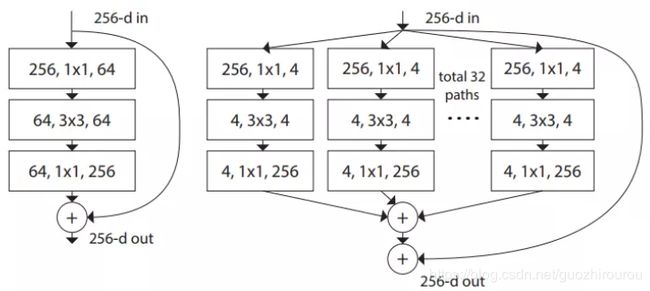
与ResNet相比,作者提出了aggregated transformations结构,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,ResNext中block里每个分支都是一模一样的,ResNet与ResNext网络整体结构如下:

其中,提出了cardinality概念,即指每个block中的分支的个数。
在实验中表明:
1、增加cardinality比增加网络宽度和深度更加有效
2、ResNeXt和ResNet的参数复杂度差不多,但前者的准确率更高,超参数减少
SENet:
SENet的核心思想:
通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SE block嵌在原有的一些分类网络中虽增加了一些参数和计算量,但是相较于实验效果是可以接受的。Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。
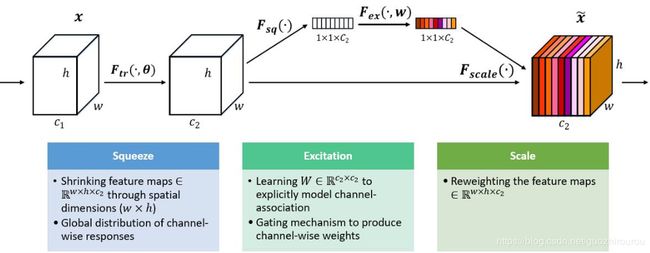
SENet结构组成:
1、Squeeze:顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
2、Excitation:类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
3、Reweight:将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
将 SE 模块嵌入到 Inception 结构的示例:
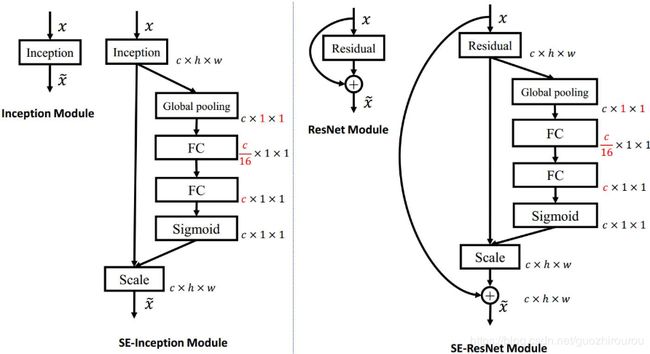
这里使用 global average pooling 作为 Squeeze 操作,紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。这里将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
SENet构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。
Refference
分类神经网络发展:
https://www.cnblogs.com/skyfsm/p/8451834.html
LeNet:
https://cuijiahua.com/blog/2018/01/dl_3.html
AlexNet:
https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
VGGNet:
https://blog.csdn.net/weixin_40031404/article/details/80133583
GoogLeNet
https://my.oschina.net/u/876354/blog/1637819
ResNet:
https://www.jianshu.com/p/93990a641066
ResNext:
https://blog.csdn.net/hejin_some/article/details/80743818
Xception:
https://blog.csdn.net/lk3030/article/details/84847879
https://blog.csdn.net/u011995719/article/details/78889335
SENet:
https://www.cnblogs.com/bonelee/p/9030092.html
https://blog.csdn.net/weixin_41923961/article/details/88983505