caffe python 图片训练识别 实例
本文主要是使用caffe python做图片识别的示例包括训练数据lmdb生成,训练,以及模型测试,主要内容如下:
-
训练,验证数据lmdb生成,主要包括:样本的预处理 (直方图均衡化,resize),训练样本以及验证样本的lmdb的生成,以及mean_file mean.binaryproto生成
-
caffe中模型的定义,主要是修改 caffe Alexnet 训练文件train_val.prototxt ,以及训练参数文件solver.prototxt ,还有部署文件deploy.prototxt
-
训练验证数据准备完成之后,就是模型的训练
-
得到训练模型之后,一般会进行本地测试以及从数据库获取url测试然后将结果写到数据库中
先上个代码的框架图,说明见图片(下面会有详细的讲解):

下面给出最终的识别结果:

注:本文做图像分类的时候大概是在2016年,第一个分类模型用的是
Alexnet这个模型现在基本不怎么用了。一般用的是googlenet v2版本。
而且caffe的
model zoohttps://github.com/BVLC/caffe/wiki/Model-Zoo中有不少新的模型,比如Towards Principled Design of Deep Convolutional Networks: Introducing SimpNet感兴趣的可以多多尝试下。
1. 训练,验证数据lmdb生成
-
对图片进行预处理包括直方图均衡化(Histogram equalization)以及resize到指定的大小,并生成lmdb格式,图片以及对于的标签(label)
-
按照一定的比例生成,训练样本lmdb以及验证样本lmdb,以及mean_file mean.binaryproto
-
在测试的时候,我们往往是从数据库中读取url以及id信息,然后将url转化为cv2 可以处理的图片样式,因此我们还要实现将url转化cv2可以处理的图片
1.1 图片进行预处理包括直方图均衡化,url->cv2 image 格式
下面通过代码来讲解(文件: utils->img_process.py):
# _*_coding:utf-8 _*_
import cv2
import urllib
import numpy as np
IMG_HEIGHT = 227
IMG_WIDTH = 227
# 对图片做直方图均衡化处理
def pre_process_img(img, img_height=IMG_HEIGHT, img_width=IMG_WIDTH):
# firstly histogram equalization
img[:, :, 0] = cv2.equalizeHist(img[:, :, 0])
img[:, :, 1] = cv2.equalizeHist(img[:, :, 1])
img[:, :, 2] = cv2.equalizeHist(img[:, :, 2])
# resize image to size
img = cv2.resize(img, (img_width, img_height), interpolation=cv2.INTER_CUBIC)
return img
# 通过图片url将其转化为cv2可以处理的形式
def get_cv_img__from_url(url):
"""
read image from url to cv codec
:param url:
:return:
"""
try:
url_response = urllib.urlopen(url)
img_array = np.array(bytearray(url_response.read()), dtype=np.uint8)
img = cv2.imdecode(img_array, -1)
return img
except Exception, e:
print e
return None
if __name__ == '__main__':
url = 'http://www.sanyarb.com.cn/images/attachement/jpg/site2/20161009/A121475977636942_change_ljx6a9_b.jpg'
img = get_cv_img__from_url(url)
cv2.imshow("zhan lang", img)
img = pre_process_img(img)
cv2.imshow("pre_process_img", img)
cv2.waitKey()
pass
下面是下载网上的图片,然后对其进行直方图均衡化以及resize的运行的结果:

1.2 图片按照一定的比例生成训练样本以及验证样本lmdb]
# _*_coding:utf-8 _*_
import sys
sys.path.insert(0, '../../caffe_train_test/')
import os
import glob
import random
import numpy as np
import cv2
import caffe
from caffe.proto import caffe_pb2
import lmdb
from utils.img_process import *
# 根据图片和标签转化为对应的lmdb格式
def make_datum(img, label):
# image is numpy.ndarray format. BGR instead of RGB
return caffe_pb2.Datum(
channels=3,
width=IMG_HEIGHT,
height=IMG_WIDTH,
label=label,
data=np.rollaxis(img, 2).tostring())
# 创建lmdb的基类
class GenerateLmdb(object):
def __init__(self, img_path):
"""
img_path -> multiple calss directory
like, class_1, class_2, class_3....
each class has corresponding class image like class_1_1.png
:param img_path:
"""
# get all the images in different class directory
# 获取到多有的图片列表
self.img_lst = glob.glob(os.path.join(img_path, '*', '*.png'))
print 'input_img list num is %s' % len(self.img_lst)
# shuffle all the images
# 需要对列表乱序
random.shuffle(self.img_lst)
# 根据标签,比例生成训练lmdb以及验证lmdb
def generate_lmdb(self, label_lst, percentage, train_path, validation_path):
"""
label_lst like ['class_1', 'class_2', 'class_3', .....]
percentage like is 5 (4/5) then 80% be train image, (1/5) 20% be validation image
train_path like that '/data/train/train_lmdb'
validation_path like '/data/train/validation_lmdb'
"""
print 'now generate train lmdb'
self._generate_lmdb(label_lst, percentage, True, train_path)
print 'now generate validation lmdb'
self._generate_lmdb(label_lst, percentage, False, validation_path)
print '\n generate all images'
def _generate_lmdb(self, label_lst, percentage, b_train, input_path):
"""
b_train is True means to generate train lmdb, or validation lmdb
"""
output_db = lmdb.open(input_path, map_size=int(1e12))
with output_db.begin(write=True) as in_txn:
for idx, img_path in enumerate(self.img_lst):
# create train data
if b_train:
# !=0 means validation data then skip loop
if idx % percentage != 0:
continue
# create validation data
else:
# ==0 means train data then skip
if idx % percentage == 0:
continue
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = pre_process_img(img)
# path like that '../../class_1/0001.png'
# so img_path.split('/')[-2] -> class_1
label = label_lst.index(img_path.split('/')[-2])
datum = make_datum(img, label)
in_txn.put('{:0>5d}'.format(idx), datum.SerializeToString())
print '{:0>5d}'.format(idx) + '->label: ', label, " " + img_path
output_db.close()
def get_label_lst_by_dir(f_dir):
"""
f_dir like 'home/user/class', sub dir 'class_1', 'class_2'...'class_n'
:return: ['class_1', 'class_2'...'class_n']
"""
return os.listdir(f_dir)
if __name__ == '__main__':
img_path = '../../ad_train/'
cl = GenerateLmdb(img_path)
train_lmdb = '/data6/light/storm_1_1/images/ad_train_py/input_data/train_lmdb'
validation_lmdb = '/data6/light/storm_1_1/images/ad_train_py/input_data/validation_lmdb'
# 删除原有的lmdb文件
os.system('rm -rf ' + train_lmdb)
os.system('rm -rf ' + validation_lmdb)
input_path = '/data6/light/storm_1_1/images/ad_train/'
label_lst = get_label_lst_by_dir(input_path)
print 'label_lst is: %s' % ', '.join(label_lst)
# (1/10)10% to be validation data, 90% to be train data
# 1/10的文件为验证lmdb, 9/10为训练lmdb
percentage = 10
cl.generate_lmdb(label_lst, percentage, train_lmdb, validation_lmdb)
pass
下面是实践的运行截图(这个代码好早前就运行了,这次写bolg做了一些处理)下面是一个三分类的目录(前面做过十几中的分类,这里写bolg,做了简化)
类别标签是: ad_text(文字广告), ad_web(网页广告),others(其他类)
类别目录如下:

下面是输出的label列表:
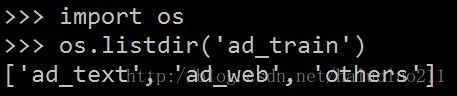
下面是运行 python create_lmdb.py 的部分日志结果(为了简便做了很多处理)

下面是最终生成的lmdb文件:
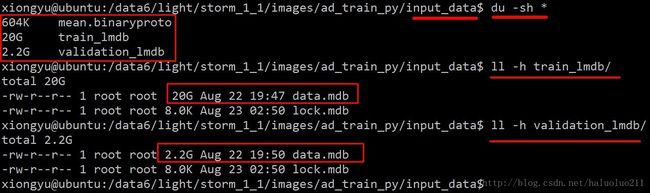
到此我们生成了,caffe训练需要的lmdb文件
1.3 mean_file mean.binaryproto
# _*_ coding:utf-8
import os
# 生成,生成mean_binaryproto文件的字符串命令
def get_mean_cmd(mean_tool_path, train_lmdb_path, mean_binaryproto_path):
# create train command
return '%s -backend=lmdb %s %s ' % (mean_tool_path, train_lmdb_path, mean_binaryproto_path)
if __name__ == '__main__':
# caffe mean 工具的路径
mean_tool_path = '/home/ubuntu/caffe/build/tools/compute_image_mean'
train_lmdb_path = '/home/xiongyu/input/train_lmdb'
mean_binaryproto_path = '/home/xiongyu/input/mean.binaryproto'
cmd = get_mean_cmd(mean_tool_path, train_lmdb_path, mean_binaryproto_path)
print cmd
# 执行生成命令
os.system(cmd)
cmd合成的字符串

实际生成的结果

2. caffe中模型的配置文件的定义以及说明
2.1 训练模型定义
caffe中模型的定义,主要是修改 caffe Alexnet 训练文件train_val.prototxt
。主要修改mean_file mean.binaryproto,source train lmdb 路径,




由于这个示例主要讲的是3分类,因此还要修改num_output为3(记得修改对应的 部署文件)

2.2 部署文件
部署文件deploy.prototxt 记得修改对应的num_output为3和训练文件一致

2.3 训练运行参数文件
训练运行参数文件solver.prototxt
net: "/data6/light/storm_1_1/images/ad_train_py/caffe_model/caffenet_train_val_1.prototxt"
test_iter: 1000
# 每1000次做一次验证
test_interval: 1000
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 2500
display: 50
# 最大迭代次数
max_iter: 30000
momentum: 0.9
# 权重衰减因子
weight_decay: 0.0005
# 每训练6000次生成一次模型快照
snapshot: 5000
# 模型快照前缀
snapshot_prefix: "/data6/light/storm_1_1/images/ad_train_py/caffe_model/caffe_model_1"
# GPU模式
solver_mode: GPU
下面看下最终生成的模型文件(文件太大删除了很多,只保留一个运行时的)

3. 训练验证数据准备完成之后,就是模型的训练
代码类似与mean 文件的生成,这里就不解释了
command |& tee out.log
, 将结果输出到标准输出流以及out.log文件中
# _*_ coding:utf-8
import os
def get_train_cmd(caffe_path, solver_path, log_path):
# create train command
return '%s train --solver %s |& tee %s ' % (caffe_path, solver_path, log_path)
if __name__ == '__main__':
caffe_path = "/home/xiongyu/caffe/build/tools/caffe"
solver_path = "/home/xiongyu/caffe_models/caffe_model_1/solver_1.prototxt"
log_path = "/home/xiongyu/caffe_models/caffe_model_1/model_1_train.log"
train = get_train_cmd(caffe_path, solver_path, log_path)
print train
# use caffe to train model
os.system(train)
pass
下面是训练时的部分截图:
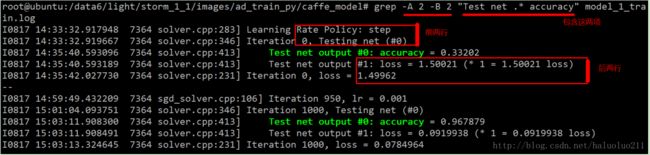
4. 本地测试以及从数据库获取url测试然后将结果写到数据库中
4.1 测试基类文件predict_base.py
为了保证代码的模块性,测试的便捷性,这个基类提供给测试本地文件以及数据库文件调用
# _*_coding:utf-8 _*_
import sys
sys.path.insert(0, '../../caffe_train_test/')
import os
import glob
import cv2
import caffe
import lmdb
import numpy as np
from caffe.proto import caffe_pb2
from utils.img_process import *
class CaffePredict(object):
def __init__(self, b_gpu, mean_path, deploy_path, model_path):
# cpu或者是gpu模式
if b_gpu:
caffe.set_mode_gpu()
else:
caffe.set_mode_cpu()
mean_blob = caffe_pb2.BlobProto()
with open(mean_path) as f:
mean_blob.ParseFromString(f.read())
mean_array = np.asarray(mean_blob.data, dtype=np.float32).\
reshape((mean_blob.channels, mean_blob.height, mean_blob.width))
self.net = caffe.Net(deploy_path, model_path, caffe.TEST)
# Define image transformers
self.transformer = caffe.io.Transformer({'data': self.net.blobs['data'].data.shape})
self.transformer.set_mean('data', mean_array)
# puts the channel as the first dimention
self.transformer.set_transpose('data', (2, 0, 1))
# predict只需要输入cv2 image格式图片即可
def predict(self, img):
img = pre_process_img(img)
self.net.blobs['data'].data[...] = self.transformer.preprocess('data', img)
out = self.net.forward()
pred_probas = out['prob']
# predict result
ret_lst = [round(f, 4) for f in pred_probas[0].tolist()]
return ret_lst
# 获取默认的caffe模型
def get_default_caffe_predict():
# Read model architecture and trained model's weights
mean_path = "/data6/light/storm_1_1/images/ad_train_py/input_data/mean.binaryproto"
deploy_path = "/data6/light/storm_1_1/images/ad_train_py/caffe_model/caffenet_deploy_1.prototxt"
model_path = "/data6/light/storm_1_1/images/ad_train_py/caffe_model/caffe_model_1_iter_10000.caffemodel"
b_gpu = True
caffe_predict = CaffePredict(b_gpu, mean_path, deploy_path, model_path)
return caffe_predict
if __name__ == '__main__':
# 使用默认的模型识别
caffe_predict = get_default_caffe_predict()
img_path = '/data6/light/storm_1_1/images/ad_train_py/test_data/0.png'
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
print caffe_predict.predict(img)
pass
识别一张图片,运行结果如下:

4.2 测试本地目录所有图片文件
predict_from_local.py 读取目录下的所有文件,并输出识别结果
import sys
sys.path.insert(0, '../../caffe_train_test/')
from predict_base import CaffePredict, get_default_caffe_predict
import glob
import cv2
def get_img_lst(img_dir):
"""
img_dir: /data6/light/storm_1_1/images/ad_train_py/test_data/
lots of images like '0.jpg, 1.jpg ......'
"""
return glob.glob(img_dir + "*.png")
def predict_all():
path = '/data6/light/storm_1_1/images/ad_train_py/test_data/'
img_lst = get_img_lst(path)
caffe_predict = get_default_caffe_predict()
for path in img_lst:
try:
img = cv2.imread(path, cv2.IMREAD_COLOR)
# caffe_predict.predict is not thread safe,so can't be used in multiple thread
# python is dummy multiple threads
ret_lst = caffe_predict.predict(img)
print path, ret_lst
except Exception, e:
print e
if __name__ == '__main__':
predict_all()
pass
运行结果如下:

4.3 测试数据库所有图片文件
当然在实际的运行中我们往往测试几十万张图片,一般上传到服务器也很麻烦(图片要下载下来,然后打包在sz到linux目录,这样很麻烦而且,打包文件太大的话上传到服务器往往报错)。所以我们一般在数据库上面读取url然后识别,在把识别的结果写回到数据库,例如这样:

# _*_ coding:utf-8 _*_
import sys
sys.path.insert(0, '../../caffe_train_test/')
from utils.DbBse import DbService, get_default_db
from utils.img_process import get_cv_img__from_url
from predict_base import CaffePredict, get_default_caffe_predict
def predict_from_db():
"""
get all the url and id from database and
then predict, write predict result to database
:return:
"""
db = get_default_db()
# [(1, 'http://xxx.1.jpg'), (2, 'http://xxx.2.jpg).....]
url_id_lst = db.get_ad_info()
print 'url_id_lst length is %s: ' % len(url_id_lst)
print 'url_id_lst first is', url_id_lst[0]
caffe_predict = get_default_caffe_predict()
for item in url_id_lst:
img = get_cv_img__from_url(item[1])
if img is None:
continue
ret_lst = caffe_predict.predict(img)
# item[0] is id
ret_lst.append(item[0])
# write result to database
print item[1], ret_lst
db.update_ad_info(ret_lst)
if __name__ == '__main__':
predict_from_db()
pass
下面是运行结果:

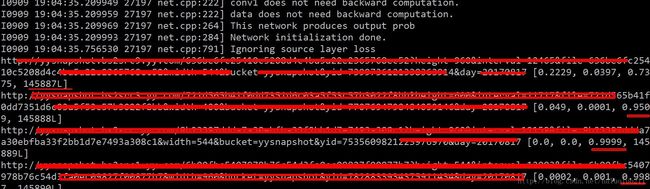
本文主要参考了下面这两个英文bolg,同时做了大量修改,主要是分享给使用caffe做图片学习需要的人:
http://adilmoujahid.com/posts/2016/06/introduction-deep-learning-python-caffe/
https://software.intel.com/en-us/articles/training-and-deploying-deep-learning-networks-with-caffe-optimized-for-intel-architecture
本文代码在个人的github上面,感觉不错的话记得start一下哈。
http://blog.csdn.net/haluoluo211/article/details/77918156!