如何通过WebRTC开发实时互动AI视频应用
项目背景
前段时间负责一个人脸和手势识别的可视化大屏项目,前端需要负责的主要任务是:通过获取摄像机实时视频流,将获取到的视频流在canvas上播放,然后每隔1000ms抽帧,并在压缩后通过保持WebSocket连接发送给后端服务器。经过服务器上的AI视觉模型算法处理后,前端接收人脸识别、手势识别及其他相关结构化数据,根据业务场景完成人机交互和数据展示。
基于最初的调研结果和实现条件,我们先后尝试了两种解决方案。
解决方案
方案1:websocket获取网络视频流
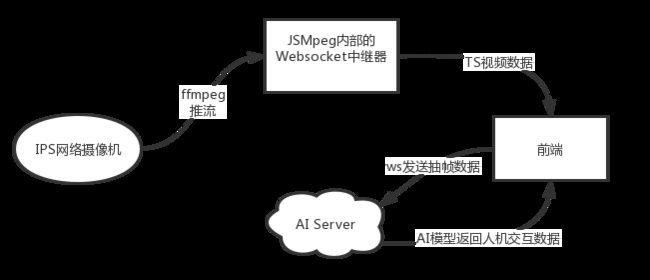
使用 IPC 网络摄像头,其标准视频输出格式为 RTSP (Real Time Streaming Protocol)。原生的video播放器肯定是无法满足使用的,所以需要对源视频流进行编解码。经过调研后,采用了轻量级的纯JS解码器JSMpeg ,其支持将Hevc编码的rtsp视频流解码并以MPEG1视频编码格式输出,本项目不对音频做分析即丢弃不做编码,然后JSMpeg可以连接到WebSocket服务器并发送二进制MPEG-TS数据。前端保持长连接接收视频流TS分片,并在Canvas上播放。经过测试,我们发现JSMpeg可以满足以30fps的速度处理720p视频。
方案2:webrtc获取本地媒体
使用USB驱动或内置摄像头,通过WebRTC提供的API直接获取本地媒体MediaSteam,直接捕获视频流在canvas上播放。由于获取的是本地媒体流,不需要网络传输和解码,相比于方案1,前端的处理工作大大减少,接下来不间断地保持抽帧发送给服务端即可。

不难看出,方案1与方案2的差别在于视频流的来源。方案1中的视频流是通过JSMpeg 内置的Node中继服务器将其推送至前端,而方案2的视频流是通过WebRTC获取。看上去似乎方案2似乎省事儿一些,的确如此,方案2的实际效果比方案1要更加出色。关于两种方案中主要用到的JSMpeg和WebRTC,接下来和童鞋们一起讨论学习下。
JSMpeg
JSMpeg是一个用JavaScript编写的视频解码器。它由 MPEG-TS 分离器,MPEG1 视频和 MP2 音频解码器,WebGL 和 Canvas2D 渲染器以及 WebAudio 声音输出组成。它通过 Ajax 加载静态视频,并可以通过 WebSocket 进行低延迟流式传输(~50ms)。
看起来这个解码器非常完美,作者也声称可以在 iPhone 5S 上以 30fps 解码 720p 视频,适用于任何现代浏览器(Chrome,Firefox,Safari,Edge),gzip 压缩之后只有 20kb。但是JSMpeg 仅支持使用 MPEG1 视频编解码器和 MP2 音频编解码器的 MPEG-TS 视频流。视频解码器无法正确处理 B-Frames,并且视频的宽度必须是 2 的倍数。
JSMpeg自带一个Node.js实现的WebSocket中继器,通过HTTP接受MPEG-TS源,并通过WebSocket将其广播给所有连接的浏览器,主要代码如下:
// HTTP服务器接收来自ffmpeg的MPEG-TS流
var streamServer = http.createServer( function(request, response) {
request.on('data', function(data){
socketServer.broadcast(data);
});
request.on('end',function(){
console.log('close');
});
}).listen(STREAM_PORT);
关于推流,可以使用ffmpeg,gstreamer或其他方法生成传入的HTTP流,这里使用的是 FFmpeg:
ffmpeg -f v4l2 -framerate 25 -video_size 640x480 -i /dev/video0 -f mpegts -codec:v mpeg1video -s 640x480 -b:v 1000k -bf 0 http://127.0.0.1:8081
简而言之,它的工作原理如下:
- 使用NodeJS起一个中继服务websocket-relay.js(这里看源码);
- 运行ffmpeg,将视频输出发送至中继的HTTP端口;
- 浏览器中的JSMpeg连接到中继的Websocket端口;
- 通过WebSocket 对客户端广播MPEG-TS数据。
然鹅,介绍完了JSMpeg,这里差不多该放弃了。乍一看,上述的思路相当于直播,过程繁琐,效果也不是特别理想。后面,我们果断放弃,开始了新的方案。
原因有三:
- 视频存在1000ms左右的延迟问题;
- 由于MPEG1的效能极低,视频质量较低;
- JS耗能问题,客户端浏览器需要解析mpeg1格式进行播放,cpu占用过多。
由于视频质量较低,且在代码层面优化了几版之后,收效甚微。于是我们转变了一下思路,从硬件层面入手,换了一个USB摄像头,视频清晰度显著上升。由于抛弃了原有的有线网卡摄像头,理论上前端就可以通过WebRTC 提供的API直接获取本地媒体捕获视频流,剩余的工作就是定时抽帧任务。
WebRTC
WebRTC , 全名(Web Real-Time Communications),为浏览器量身打造用以实时音视频通讯的技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流、音频流或其他任意数据的传输。

WebRTC包含了若干相互关联的API和协议以达到实时通讯的目标,下文主要介绍在项目中涉及到的MediaDevices API。
获取可访问的媒体设备
MediaDevices.enumerateDevices请求一个可用的媒体输入和输出设备的列表,例如麦克风,摄像机,耳机设备等。 返回的 Promise 完成时,会带有一个描述设备的 MediaDeviceInfo 的数组。
使用enumerateDevices输出一个带有标签(有标签的情况下)的 device ID的列表:
if (!navigator.mediaDevices || !navigator.mediaDevices.enumerateDevices) {
console.log("不支持 enumerateDevices() .");
return;
}
// 列出相机和麦克风.
navigator.mediaDevices.enumerateDevices()
.then(function (devices) {
devices.forEach(function (device) {
console.log(device.kind + ": " + device.label +
" id = " + device.deviceId);
});
})
.catch(function (err) {
console.log(err.name + ": " + err.message);
});

enumerateDevices返回一个 Promise 对象。当完成时,它接收一个 MediaDeviceInfo 对象的数组。每个对象描述一个可用的媒体输入输出设备。如果枚举失败,Promise 将失败rejected。
获取可使用的媒体流
1. MediaDevices.getUserMedia()
getUserMedia API是由最初的navigator.getUserMedia(已废弃),变更为navigator.mediaDevices.getUserMedia。getUserMedia使用时,首先会提示用户授权媒体输入许可,然后生成MediaStream。

一个 MediaStream 包含零个或更多的 MediaStreamTrack 对象,代表着各种视频轨(来自硬件或者虚拟视频源,比如相机、视频采集设备和屏幕共享服务等)和声轨(来自硬件或虚拟音频源,比如麦克风、A/D转换器等)。 每一个 MediaStreamTrack 可能有一个或更多的通道。这个通道代表着媒体流的最小单元,比如一个音频信号对应着一个对应的扬声器,像是在立体声音轨中的左通道或右通道。
var video = document.createElement('video');
var constraints = {
audio: false,
video: true
};
function successCallback(stream) {
window.stream = stream; //MediaStream对象
video.srcObject = stream;
}
function errorCallback(error) {
console.log('navigator.getUserMedia error: ', error);
}
function getMedia(constraints) {
if (window.stream) {
video.src = null;
window.stream.getVideoTracks()[0].stop();
}
navigator.mediaDevices.getUserMedia(
constraints
).then(
successCallback,
errorCallback
);
}
注意:
Chrome 47以后,getUserMedia API只能允许来自“安全可信”的客户端的视频音频请求,如HTTPS和本地的Localhost。如果页面的脚本从一个非安全源加载,navigator对象中则没有可用的mediaDevices对象,Chrome抛出错误。
constraints
constraints作为一个MediaStreamConstraints 对象,指定了请求的媒体类型和相对应的参数。它包含了video 和 audio两个成员的MediaStreamConstraints 对象,必须至少一个类型或者指定这两个关键字。
注意:如果为某种媒体类型设置了 true ,得到的结果的流中就需要有此种类型的轨道。如果其中一个由于某种原因无法获得,getUserMedia() 将会产生一个错误。
比如你想要使用1280x720的摄像头分辨率:
{
audio: true,
video: { width: 1280, height: 720 }
}
注意:浏览器会试着满足这个请求参数,但是如果无法准确满足此请求中参数要求或者用户选择覆盖了请求中的参数时,有可能返回其它的分辨率。
当你只要求特定的尺寸时,可以使用关键字min,max或者 exact(即 min == max)。比如要求获取最低为1280x720的分辨率。
{
audio: true,
video: {
width: { min: 1280 },
height: { min: 720 }
}
}
如果摄像头不支持请求的或者更高的分辨率,返回的Promise会处于rejected状态,NotFoundError作为rejected回调的参数,而且用户将不会得到要求授权的提示。
相对于ideal而言,关键字min, max, 和 exact有着内在关联的强制性。当请求包含一个ideal(应用最理想值)时,这个值拥有更高的权重,浏览器会先尝试找到最接近理想值的设定或者摄像头(存在多个摄像头时):
{
audio: true,
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
}
当你的设备存在多个摄像头时,可以优先选择前置:
{ audio: true, video: { facingMode: "user" } }
或者强制使用后置摄像头:
{
audio: true,
video: {
facingMode: {
exact: "environment"
}
}
}
任性的你也许只想要某个特定设备,那你需要用deviceId来约束,浏览器会优先获取此设备。
{ video: { deviceId: myPreferredCameraDeviceId } }
好了,以上将返回你需要的媒体设备。
当你对deviceId使用了exact, 且指定的设备不存在或者约束无法满足时,浏览器会抛出一个OverconstrainedError错误:

常见异常抛出
若用户拒绝了使用权限,或者需要的媒体源不可用,promise会reject回调一个NotFoundError 或者 PermissionDeniedError 。没错,getUserMedia就是通过将DOMException错误对象传递给promise的失败处理程序来处理异常的。除NotFoundError 之外,当你使用getUserMedia的时候可能出现各种奇奇怪怪的异常,常见的错误有以下几种:
var promise = navigator.mediaDevices.getUserMedia({
video: true,
audio: false
});
promise.then(function (MediaStream) {
video.srcObject = MediaStream;
}).catch(err => {
if (err.name == 'NotFoundError' || err.name == 'DeviceNotFoundError') {
// 找不到满足请求参数的媒体类型
console.log(err.name, 'require track is missing');
} else if (err.name == 'NotReadableError' || err.name == 'TrackStartError') {
// 设备已经授权,但是某个硬件、浏览器或者网页层面发生的错误导致设备无法被访问
console.error(err.name, 'webcam or mic are already in use');
} else if (err.name == 'OverconstrainedError' || err.name == 'ConstraintNotSatisfiedError') {
// 指定的要求无法被设备满足,此异常是一个类型为OverconstrainedError的对象
console.error(err.name, 'constraints can not be satisfied by avb.device');
} else if (err.name == 'NotAllowedError' || err.name == 'PermissionDeniedError') {
// 用户拒绝了浏览器实例的访问请求
console.error(err.name, 'permission denied in browser');
} else if (err.name == 'TypeError' || err.name == 'TypeError') {
// constraints对象未设置,或者都被设置为false
console.error(err.name, 'empty constraints object');
} else {
// 其他错误
console.error(err.name, 'other errors');
}
});
2. MediaDevices.getDisplayMedia()
这个 MediaDevices 接口的 getDisplayMedia 方法提示用户去选择和授权捕获展示的内容或部分内容(如一个窗口)在一个 MediaStream 里。其中包含一个视频轨道(视频轨道的内容来自用户选择的屏幕区域以及一个可选的音频轨道),然后流能被用 MediaStream Recording API 记录或传输一部分去一个WebRTC 会话。
navigator.getDisplayMedia({ video: true })
.then(stream => {
// 成功回调的流,将它赋给video元素;
videoElement.srcObject = stream;
}, error => {
console.log("Unable to acquire screen capture", error);
});
constraints
和getUserMedia一样,getDisplayMedia也有一个可选的MediaStreamConstraints对象指定返回的MediaStream的要求。 不同的是,getDisplayMedia需要视频轨道,即便constraints没有明确要求,返回的流中仍会存在。
异常
与getUserMedia一致,来自返回的Promise的拒绝是通过将DOMException错误对象传递给Promise的失败处理程序来进行。
3. getUserMedia与getDisplayMedia比较
getDisplayMedia不作过多赘述,因为这两个难兄难弟大部分操作是相同的,除了以下几点:
getUserMedia
- 获取的
MediaStream可以包括例如视频轨道(来自硬件或者虚拟视频源,比如相机、视频采集设备和屏幕共享服务等),音频轨道(来自硬件或虚拟音频源,比如麦克风、A/D转换器等)以及可能的其他轨道类型。 - 可以实现约束,接受
MediaStreamConstraints约束参数对捕获的MediaStream进行限制。
getDisplayMedia
MediaStream对象只有一个MediaStreamTrack用于捕获的视频流,没有MediaStreamTrack对应捕获的音频流。- 不能实现约束,
constraints参数不接受MediaTrackConstraints值。 - 不能保持权限,确认要分享的屏幕内容后,不能发生更改,除非
reload重新唤醒Screen Capture。
其他
说完了视频流,再来简单说下抽帧。这里的抽帧指的是每隔一段时间从视频中抽取图片,将大屏前实时的人脸和手势数据发送给后端。前面讲到,我们最终是把视频流在canvas上绘制。通过canvas提供的drawImageAPI绘制当前图像,配合定时器通过WebSocket发送至后端,即可达到抽帧目的。
function drawImage(drawImageRate) {
context.drawImage(video, 0, 0, width, height);
let base64Image = canvas.toDataURL('image/jpeg', 1); //格式为image/jpeg或image/webp时,从0到1的区间定制图的质量
... //压缩等处理后
window.rws.send(JSON.stringify({ image: base64Image }));
}
window.drawInter = setInterval(drawImage, drawImageRate = 1000);
关于canvas画布转换成img图像,除了base64外,也可以选择Blob格式,因为是二进制的,对后端更加友好。
canvas.toBlob(callback, mimeType, qualityArgument)
这里是关于抽帧的小demo
WebRTC使用感受
总而言之,其具备几个优点:
- 基于浏览器的实时音视频通信。
- 免费开源(且已被W3C纳入HTML5标准)。
- 使用成本低,免插件。
- 跨平台,跨浏览器,跨移动应用。
然而这个世界上没有绝对完美的东西, WebRTC 自身仍存在一些缺憾:
- 兼容性问题。在 Web 端存在浏览器之间的兼容性问题,虽然WebRTC组织在GitHub上提供了WebRTC适配器,但除此之外仍要面临浏览器行为不一致的问题。
- 传输质量不稳定。由于WebRTC 使用的是对点对传输,跨运营商、跨地区、低带宽、高丢包等场景下的传输质量基本听天由命。
- 移动端适配差。针对不同机型需要做适配,很难有统一的用户体验。
讲到这里就结束了,WebRTC着实让我体会了一次它在音视频领域的强大。在浏览器支持上,除了 IE 之外, Chrome、Firefox、Safari、Microsoft Edge 等主流浏览器都已支持 WebRTC,多种音视频开发场景如在线课堂、远程屏幕等也得到广泛应用。在未来,希望它能给我们带来更多惊喜!
参考链接
https://webrtc.org
https://developer.mozilla.org/en-US/docs/Web/API/Screen_Capture_API/Using_Screen_Capture
https://developer.mozilla.org/en-US/docs/Web/API/Media_Streams_API
https://www.w3.org/TR/webrtc/
https://www.jianshu.com/p/57fd3b5d2f80