高级车道线检测(Apollo微信公众号)
车道线检测是无人车系统里感知模块的重要组成部分。利用视觉算法的车道线检测解决方案是一种较为常见解决方案。视觉检测方案主要基于图像算法,检测出图片中行车道路的车道线标志区域。
基于图像处理相关技术的高级车道线检测(可适用于弯道,车道线颜色不固定,路面阴影,亮光)。其操作步骤有以下几点:
校准摄像头的畸变,使拍摄照片能够较完整的反映3D世界的情况。
对每一帧图片做透视转换(perspective transform),将摄像头的照片转换到鸟瞰图视角。
对鸟瞰图二值化,通过二值的像素点进一步区分左右两条车道线,从而拟合出车道线曲线。
用滑窗的方法检测第一帧的车道线像素点,然后拟合车道线曲线。
从第一帧的曲线周围寻找接下来的车道线像素点,然后拟合车道线曲线。
有了车道线曲线方程之后,可以计算斜率和车道线偏离中心的位置。
输入
一个连续的视频,视频中的左车道线为黄色实线,右车道线为白色虚线。无人车会经过路面颜色突变、路边树木影子干扰、车道线不清晰和急转弯的路况。(视频大小7.25M)
视频出处:https://github.com/udacity/CarND-Advanced-Lane-Lines/blob/master/project_video.mp4
输出
左、右车道线的三次曲线方程,及其有效距离。最后将车道线围成的区域显示在图像上,如下图所示。

摄像机标定
相信大家都多少听说过鱼眼相机,最常见的鱼眼相机是辅助驾驶员倒车的后向摄像头。也有很多摄影爱好者会使用鱼眼相机拍摄图像,最终会有高大上的大片效果,如下图所示。

使用鱼眼相机拍摄的图像虽然高大上,但存在一个很大的问题——畸变(Distortion)。如上图所示,走道上的栏杆应该是笔直延伸出去的。然而,栏杆在图像上的成像却是弯曲的,这就是图像畸变,畸变会导致图像失真。
使用车载摄像机拍摄出的图像,虽然没有鱼眼相机的畸变这么夸张,但是畸变是客观存在的,只是人眼难以察觉。使用有畸变的图像做车道线的检测,检测结果的精度将会受到影响,因此进行图像处理的第一步工作就是去畸变。
为了解决车载摄像机图像的畸变问题,摄像机标定技术应运而生。
摄像机标定是通过对已知的形状进行拍照,通过计算该形状在真实世界中位置与在图像中位置的偏差量(畸变系数),进而用这个偏差量去修正其他畸变图像的技术。
原则上,可以选用任何的已知形状去校准摄像机,不过业内的标定方法都是基于棋盘格的。因为它具备规则的、高对比度图案,能非常方便地自动化检测各个棋盘格的交点,十分适合标定摄像机的标定工作。如下图所示为标准的10x7(7行10列)的棋盘格。

OpenCV库为摄像机标定提供了函数cv2.findChessboardCorners(),它能自动地检测棋盘格内4个棋盘格的交点(2白2黑的交接点)。我们只需要输入摄像机拍摄的完整棋盘格图像和交点在横纵向上的数量即可。随后我们可以使用函数cv2.drawChessboardCorners()绘制出检测的结果。
原图:

角点检测图:

获取交点的检测结果后,使用函数cv2.calibrateCamera()即可得到相机的畸变系数。
为了使摄像机标定得到的畸变系数更加准确,我们使用车载摄像机从不同的角度拍摄20张棋盘格,将所有的交点检测结果保存,再进行畸变系数的的计算。
我们将读入图片、预处理图片、检测交点、标定相机的一系列操作,封装成一个函数,如下所示:
1#################################################################
2# Step 1 : Calculate camera distortion coefficients
3#################################################################
4def getCameraCalibrationCoefficients(chessboardname, nx, ny):
5 # prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
6 objp = np.zeros((ny * nx, 3), np.float32)
7 objp[:,:2] = np.mgrid[0:nx, 0:ny].T.reshape(-1,2)
8
9 # Arrays to store object points and image points from all the images.
10 objpoints = [] # 3d points in real world space
11 imgpoints = [] # 2d points in image plane.
12
13 images = glob.glob(chessboardname)
14 if len(images) > 0:
15 print("images num for calibration : ", len(images))
16 else:
17 print("No image for calibration.")
18 return
19
20 ret_count = 0
21 for idx, fname in enumerate(images):
22 img = cv2.imread(fname)
23 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
24 img_size = (img.shape[1], img.shape[0])
25 # Finde the chessboard corners
26 ret, corners = cv2.findChessboardCorners(gray, (nx, ny), None)
27
28 # If found, add object points, image points
29 if ret == True:
30 ret_count += 1
31 objpoints.append(objp)
32 imgpoints.append(corners)
33
34 ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_size, None, None)
35 print('Do calibration successfully')
36 return ret, mtx, dist, rvecs, tvecs调用之前封装好的函数,获取畸变参数
nx = 9
2ny = 6
3ret, mtx, dist, rvecs, tvecs = getCameraCalibrationCoefficients('camera_cal/calibration*.jpg', nx, ny)以畸变的棋盘格图像为例,进行畸变修正处理
1# Read distorted chessboard image
2test_distort_image = cv2.imread('./camera_cal/calibration4.jpg')
3
4# Do undistortion
5test_undistort_image = undistortImage(test_distort_image, mtx, dist)畸变图像如下图所示:

复原后的图像如下图所示:

1test_distort_image = cv2.imread('test_images/straight_lines1.jpg')
2
3# Do undistortion
4test_undistort_image = undistortImage(test_distort_image, mtx, dist)原始畸变图像如下所示:

畸变修正后的图像如下所示:

可以看到离镜头更近的左侧、右侧和下侧的图像比远处的畸变修正更明显
筛选图像
从我们作为输入的视频可以看出,车辆会经历颠簸、车道线不清晰、路面颜色突变,路边障碍物阴影干扰等复杂工况。因此,需要将这些复杂的场景筛选出来,确保后续的算法能够在这些复杂场景中正确地检测出车道线。
使用以下代码将视频中的图像数据提取,进行畸变修正处理后,存储在名为original_image的文件夹中,以供挑选。
1video_input = 'project_video.mp4'
2cap = cv2.VideoCapture(video_input)
3count = 1
4while(True):
5 ret, image = cap.read()
6 if ret:
7 undistort_image = undistortImage(image, mtx, dist)
8 cv2.imwrite('original_image/' + str(count) + '.jpg', undistort_image)
9 count += 1
10 else:
11 break
12cap.release()在original_image文件夹中,挑选出以下6个场景进行检测。这6个场景既包含了视频中常见的正常直道、正常弯道工况,也包含了具有挑战性的阴影、明暗剧烈变化的工况。如下图所示:






如果后续的高级车道线检测算法能够完美处理以上六种工况,那将算法应用到视频中,也会得到完美的车道线检测效果。
透视变换
在完成图像的畸变修正后,就要将注意力转移到车道线。与《无人驾驶技术入门(十四)| 初识图像之初级车道线检测》中技术类似,这里需要定义一个感兴趣区域。很显然,我们的感兴趣区域就是车辆正前方的这个车道。为了获取感兴趣区域,我们需要对自车正前方的道路使用一种叫做透视变换的技术。
“透视”是图像成像时,物体距离摄像机越远,看起来越小的一种现象。在真实世界中,左右互相平行的车道线,会在图像的最远处交汇成一个点。这个现象就是“透视成像”的原理造成的。
以立在路边的交通标志牌为例,它在摄像机所拍摄的图像中的成像结果一般如下下图所示:

在这幅图像上,原本应该是正八边形的标志牌,成像成为一个不规则的八边形。
通过使用透视变换技术,可以将不规则的八边形投影成规则的正八边形。应用透视变换后的结果对比如下图:

透视变换的原理:首先新建一幅跟左图同样大小的右图,随后在做图中选择标志牌位于两侧的四个点(如图中的红点),记录这4个点的坐标,我们称这4个点为src_points。图中的4个点组成的是一个平行四边形。
由先验知识可知,左图中4个点所围成的平行四边形,在现实世界中是一个长方形,因此在右边的图中,选择一个合适的位置,选择一个长方形区域,这个长方形的4个端点一一对应着原图中的src_points,我们称新的这4个点为dst_points。
得到src_points,dst_points后,我们就可以使用OpenCV中计算投影矩阵的函数cv2.getPerspective Transform(src_points,dst_points)算出src_points到dst_points的投影矩阵和投影变换后的图像了。
使用OpenCV库实现透视变换的代码如下:
1#################################################################
2# Step 3 : Warp image based on src_points and dst_points
3#################################################################
4# The type of src_points & dst_points should be like
5# np.float32([ [0,0], [100,200], [200, 300], [300,400]])
6def warpImage(image, src_points, dst_points):
7 image_size = (image.shape[1], image.shape[0])
8 # rows = img.shape[0] 720
9 # cols = img.shape[1] 1280
10 M = cv2.getPerspectiveTransform(src, dst)
11 Minv = cv2.getPerspectiveTransform(dst, src)
12 warped_image = cv2.warpPerspective(image, M,image_size, flags=cv2.INTER_LINEAR)
13
14 return warped_image, M, Minv同理,对于畸变修正过的道路图像,我们同样使用相同的方法,将我们感兴趣的区域做透视变换。
如下图所示,我们选用一张在直线道路上行驶的图像,沿着左右车道线的边缘,选择一个梯形区域,这个区域在真实的道路中应该是一个长方形,因此我们选择将这个梯形区域投影成为一个长方形,在右图横坐标的合适位置设置长方形的4个端点。最终的投影结果就像“鸟瞰图”一样。
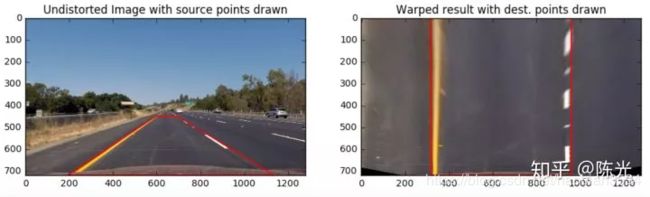
使用以下代码,通过不断调整src和dst的值,确保在直线道路上,能够调试出满意的透视变换图像。
1test_distort_image = cv2.imread('test_images/test4.jpg')
2
3# 畸变修正
4test_undistort_image = undistortImage(test_distort_image, mtx, dist)
5
6# 左图梯形区域的四个端点
7src = np.float32([[580, 460], [700, 460], [1096, 720], [200, 720]])
8# 右图矩形区域的四个端点
9dst = np.float32([[300, 0], [950, 0], [950, 720], [300, 720])
10
11test_warp_image, M, Minv = warpImage(test_undistort_image, src, dst)最终,我们把筛选出的6幅图统一应用调整好的src、dst做透视变换,结果如下:






可以看到,越靠图片下方的图像越清晰,越上方的图像越模糊。这是因为越远的地方,左图中的像素点越少。而无论是远处还是近处,需要在右图中填充的像素点数量是一样的。左图近处有足够多的点去填充右图,而左图远处的点有限,只能通过插值的方式创造“假的”像素点进行填充,所以就不那么清晰了。
提取车道线
在《无人驾驶技术入门(十四)| 初识图像之初级车道线检测》中,我们介绍了通过Canny边缘提取算法获取车道线待选点的方法,随后使用霍夫直线变换进行了车道线的检测。在这里,我们也尝试使用边缘提取的方法进行车道线提取。
需要注意的是,Canny边缘提取算法会将图像中各个方向、明暗交替位置的边缘都提取出来,很明显,Canny边缘提取算法在处理有树木阴影的道路时,会将树木影子的轮廓也提取出来,这是我们不愿意看到的。
因此我们选用Sobel边缘提取算法。Sobel相比于Canny的优秀之处在于,它可以选择横向或纵向的边缘进行提取。从投影变换后的图像可以看出,我们关心的正是车道线在横向上的边缘突变。
封装一下OpenCV提供的cv2.Sobel()函数,将进行边缘提取后的图像做二进制图的转化,即提取到边缘的像素点显示为白色(值为1),未提取到边缘的像素点显示为黑色(值为0)。
1def absSobelThreshold(img, orient='x', thresh_min=30, thresh_max=100):
2 # Convert to grayscale
3 gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
4 # Apply x or y gradient with the OpenCV Sobel() function
5 # and take the absolute value
6 if orient == 'x':
7 abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 1, 0))
8 if orient == 'y':
9 abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 0, 1))
10 # Rescale back to 8 bit integer
11 scaled_sobel = np.uint8(255*abs_sobel/np.max(abs_sobel))
12 # Create a copy and apply the threshold
13 binary_output = np.zeros_like(scaled_sobel)
14 # Here I'm using inclusive (>=, <=) thresholds, but exclusive is ok too
15 binary_output[(scaled_sobel >= thresh_min) & (scaled_sobel <= thresh_max)] = 1
16
17 # Return the result
18 return binary_output使用同一组阈值对以上6幅做过投影变换的图像进行x方向的边缘提取,可以得到如下结果:






由以上结果可以看出,在明暗交替明显的路面上,如图1和图2,横向的Sobel边缘提取算法在提取车道线的表现上还不错。不过一旦道路的明暗交替不那么明显了,如图3和图4的白色路面区域,很难提取到有效的车道线待选点。当面对有树木阴影覆盖的区域时,如图5和图6,虽然能提取出车道线的大致轮廓,但会同时引入的噪声,给后续处理带来麻烦。
因此,横向的Sobel边缘提取算法,无法很好地处理路面阴影、明暗交替的道路工况。
无法使用边缘提取的方法提取车道线后,我们开始将颜色空间作为突破口。
在以上6个场景中,虽然路面明暗交替,而且偶尔会有阴影覆盖,但黄色和白色的车道线是一直都存在的。因此,我们如果能将图中的黄色和白色分割出来,然后将两种颜色组合在一幅图上,就能够得到一个比较好的处理结果。
一幅图像除了用RGB(红绿蓝)三个颜色通道表示以外,还可以使用HSL(H色相、S饱和度、L亮度)和LAB(L亮度、A红绿通道、B蓝黄)模型来描述图像,三通道的值与实际的成像颜色如下图所示。

我们可以根据HSL模型中的L(亮度)通道来分割出图像中的白色车道线,同时可以根据LAB模型中的B(蓝黄)通道来分割出图像中的黄色车道线,再将两次的分割结果,去合集,叠加到一幅图上,就能得到两条完整的车道线了。
使用OpenCV提供的cv2.cntColor()接口,将RGB通道的图,转为HLS通道的图,随后对L通道进行分割处理,提取图像中白色的车道线。封装成代码如下:
1 def hlsLSelect(img, thresh=(220, 255)):
2 hls = cv2.cvtColor(img, cv2.COLOR_BGR2HLS)
3 l_channel = hls[:,:,1]
4 l_channel = l_channel*(255/np.max(l_channel))
5 binary_output = np.zeros_like(l_channel)
6 binary_output[(l_channel > thresh[0]) & (l_channel <= thresh[1])] = 1
7 return binary_output使用同一组阈值对以上6种工况进行处理,处理结果如下图所示。






使用OpenCV提供的cv2.cvtColor()接口,将RGB通道的图,转为LAB通道的图,随后对B通道进行分割处理,提取图像中黄色的车道线。封装成代码如下:
1def labBSelect(img, thresh=(195, 255)):
2 # 1) Convert to LAB color space
3 lab = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)
4 lab_b = lab[:,:,2]
5 # don't normalize if there are no yellows in the image
6 if np.max(lab_b) > 100:
7 lab_b = lab_b*(255/np.max(lab_b))
8 # 2) Apply a threshold to the L channel
9 binary_output = np.zeros_like(lab_b)
10 binary_output[((lab_b > thresh[0]) & (lab_b <= thresh[1]))] = 1
11 # 3) Return a binary image of threshold result
12 return binary_output
使用同一组阈值对以上6种工况进行处理,处理结果如下图所示。






根据以上试验可知,L通道能够较好地分割出图像中的白色车道线,B通道能够较好地分割出图像中的黄色车道线。即使面对树木阴影和路面颜色突变的场景,也能尽可能少地引入噪声。
最后,我们使用以下代码,将两个通道分割的图像合并
1hlsL_binary = hlsLSelect(test_warp_image)
2labB_binary = labBSelect(test_warp_image)
3combined_binary = np.zeros_like(hlsL_binary)
4combined_binary[(hlsL_binary == 1) | (labB_binary == 1)] = 1
最终合并的效果如下图所示:






以上仅仅是车道线提取的方法之一。除了可以通过HSL和LAB颜色通道,这种基于规则的方法,分割出车道线外,还可以使用基于深度学习的方法。它们目的都是为了能够稳定地将车道线从图像中分割出来。
检测车道线
在检测车道线前,需要粗定位车道线的位置。为了方便理解,这里引入一个概念——直方图。
以下面这幅包含噪点的图像为例,进行直方图的介绍。

我们知道,我们处理的图像的分辨率为1280*720,即720行,1280列。如果我将每一列的白色的点数量进行统计,即可得到1280个值。将这1280个值绘制在一个坐标系中,横坐标为1-1280,纵坐标表示每列中白色点的数量,那么这幅图就是“直方图”,如下图所示:
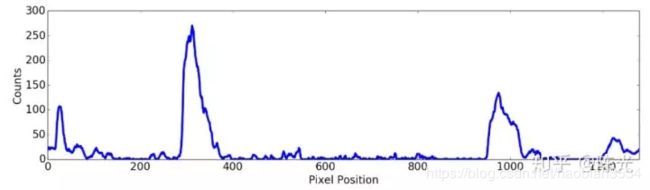
将两幅图叠加,效果如下:
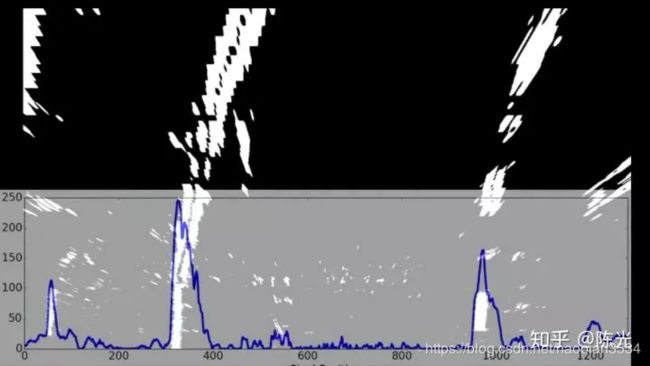
找到直方图左半边最大值所对应的列数,即为左车道线所在的大致位置;找到直方图右半边最大值所对应的列数,即为右车道线所在的大致位置。
使用直方图找左右车道线大致位置的代码如下,其中rightx_base和leftx_base即为左右车道线所在列的大致位置。
1# Take a histogram of the bottom half of the image
2histogram = np.sum(combined_binary[combined_binary.shape[0]//2:,:], axis=0)
3# Create an output image to draw on and visualize the result
4out_img = np.dstack((combined_binary, combined_binary, combined_binary))
5# Find the peak of the left and right halves of the histogram
6# These will be the starting point for the left and right lines
7midpoint = np.int(histogram.shape[0]//2)
8leftx_base = np.argmax(histogram[:midpoint])
9rightx_base = np.argmax(histogram[midpoint:]) + midpoint确定了左右车道线的大致位置后,使用一种叫做“滑动窗口”的技术,在图中对左右车道线的点进行搜索。先看一个介绍"滑动窗口"原理的视频(视频大小1.18M)。
滑动窗口原理
首先根据前面介绍的直方图方法,找到左右车道线的大致位置,将这两个大致位置作为起始点。定义一个矩形区域,称之为“窗口”(图中棕色的部分),分别以两个起始点作为窗口的下边线中点,存储所有在方块中的白色点的横坐标。

随后对存储的横坐标取均值,将该均值所在的列以及第一个”窗口“的上边缘所在的位置,作为下一个“窗口”的下边线中点,继续搜索。

以此往复,直到把所有的行都搜索完毕

所有落在窗口(图中棕色区域)中的白点,即为左右车道线的待选点,如下图蓝色和红色所示。随后将蓝色点和红色点做三次曲线拟合,即可得到车道线的曲线方程。

使用直方图、滑动窗口检测车道线的代码如下:
1#################################################################
2# Step 5 : Detect lane lines through moving window
3#################################################################
4def find_lane_pixels(binary_warped, nwindows, margin, minpix):
5 # Take a histogram of the bottom half of the image
6 histogram = np.sum(binary_warped[binary_warped.shape[0]//2:,:], axis=0)
7 # Create an output image to draw on and visualize the result
8 out_img = np.dstack((binary_warped, binary_warped, binary_warped))
9 # Find the peak of the left and right halves of the histogram
10 # These will be the starting point for the left and right lines
11 midpoint = np.int(histogram.shape[0]//2)
12 leftx_base = np.argmax(histogram[:midpoint])
13 rightx_base = np.argmax(histogram[midpoint:]) + midpoint
14
15 # Set height of windows - based on nwindows above and image shape
16 window_height = np.int(binary_warped.shape[0]//nwindows)
17 # Identify the x and y positions of all nonzero pixels in the image
18 nonzero = binary_warped.nonzero()
19 nonzeroy = np.array(nonzero[0])
20 nonzerox = np.array(nonzero[1])
21 # Current positions to be updated later for each window in nwindows
22 leftx_current = leftx_base
23 rightx_current = rightx_base
24
25 # Create empty lists to receive left and right lane pixel indices
26 left_lane_inds = []
27 right_lane_inds = []
28
29 # Step through the windows one by one
30 for window in range(nwindows):
31 # Identify window boundaries in x and y (and right and left)
32 win_y_low = binary_warped.shape[0] - (window+1)*window_height
33 win_y_high = binary_warped.shape[0] - window*window_height
34 win_xleft_low = leftx_current - margin
35 win_xleft_high = leftx_current + margin
36 win_xright_low = rightx_current - margin
37 win_xright_high = rightx_current + margin
38
39 # Draw the windows on the visualization image
40 cv2.rectangle(out_img,(win_xleft_low,win_y_low),
41 (win_xleft_high,win_y_high),(0,255,0), 2)
42 cv2.rectangle(out_img,(win_xright_low,win_y_low),
43 (win_xright_high,win_y_high),(0,255,0), 2)
44
45 # Identify the nonzero pixels in x and y within the window #
46 good_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
47 (nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]
48 good_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
49 (nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]
50
51 # Append these indices to the lists
52 left_lane_inds.append(good_left_inds)
53 right_lane_inds.append(good_right_inds)
54
55 # If you found > minpix pixels, recenter next window on their mean position
56 if len(good_left_inds) > minpix:
57 leftx_current = np.int(np.mean(nonzerox[good_left_inds]))
58 if len(good_right_inds) > minpix:
59 rightx_current = np.int(np.mean(nonzerox[good_right_inds]))
60
61 # Concatenate the arrays of indices (previously was a list of lists of pixels)
62 try:
63 left_lane_inds = np.concatenate(left_lane_inds)
64 right_lane_inds = np.concatenate(right_lane_inds)
65 except ValueError:
66 # Avoids an error if the above is not implemented fully
67 pass
68
69 # Extract left and right line pixel positions
70 leftx = nonzerox[left_lane_inds]
71 lefty = nonzeroy[left_lane_inds]
72 rightx = nonzerox[right_lane_inds]
73 righty = nonzeroy[right_lane_inds]
74
75 return leftx, lefty, rightx, righty, out_img
76
77def fit_polynomial(binary_warped, nwindows=9, margin=100, minpix=50):
78 # Find our lane pixels first
79 leftx, lefty, rightx, righty, out_img = find_lane_pixels(
80 binary_warped, nwindows, margin, minpix)
81
82 # Fit a second order polynomial to each using `np.polyfit`
83 left_fit = np.polyfit(lefty, leftx, 2)
84 right_fit = np.polyfit(righty, rightx, 2)
85
86 # Generate x and y values for plotting
87 ploty = np.linspace(0, binary_warped.shape[0]-1, binary_warped.shape[0] )
88 try:
89 left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
90 right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
91 except TypeError:
92 # Avoids an error if `left` and `right_fit` are still none or incorrect
93 print('The function failed to fit a line!')
94 left_fitx = 1*ploty**2 + 1*ploty
95 right_fitx = 1*ploty**2 + 1*ploty
96
97 ## Visualization ##
98 # Colors in the left and right lane regions
99 out_img[lefty, leftx] = [255, 0, 0]
100 out_img[righty, rightx] = [0, 0, 255]
101
102 # Plots the left and right polynomials on the lane lines
103 #plt.plot(left_fitx, ploty, color='yellow')
104 #plt.plot(right_fitx, ploty, color='yellow')
105
106 return out_img, left_fit, right_fit, ploty对以上6种工况进行车道线检测,处理结果如下图所示。



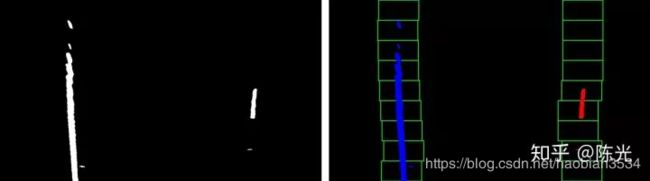
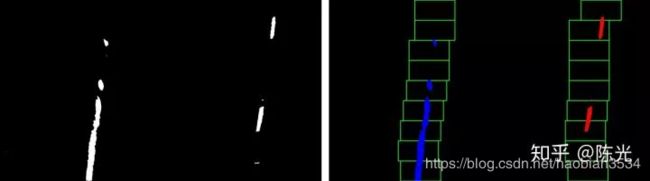

跟踪车道线
视频数据是连续的图片,基于连续两帧图像中的车道线不会突变的先验知识,我们可以使用上一帧检测到的车道线结果,作为下一帧图像处理的输入,搜索上一帧车道线检测结果附近的点,这样不仅可以减少计算量,而且得到的车道线结果也更稳定,如下图所示。

图中的细黄线为上一帧检测到的车道线结果,绿色阴影区域为细黄线横向扩展的一个区域,通过搜索该区域内的白点坐标,即可快速确定当前帧中左右车道线的待选点。
使用上一帧的车道线检测结果进行车道线跟踪的代码如下:
1#################################################################
2# Step 6 : Track lane lines based the latest lane line result
3#################################################################
4def fit_poly(img_shape, leftx, lefty, rightx, righty):
5 ### TO-DO: Fit a second order polynomial to each with np.polyfit() ###
6 left_fit = np.polyfit(lefty, leftx, 2)
7 right_fit = np.polyfit(righty, rightx, 2)
8 # Generate x and y values for plotting
9 ploty = np.linspace(0, img_shape[0]-1, img_shape[0])
10 ### TO-DO: Calc both polynomials using ploty, left_fit and right_fit ###
11 left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
12 right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
13
14 return left_fitx, right_fitx, ploty, left_fit, right_fit
15
16def search_around_poly(binary_warped, left_fit, right_fit):
17 # HYPERPARAMETER
18 # Choose the width of the margin around the previous polynomial to search
19 # The quiz grader expects 100 here, but feel free to tune on your own!
20 margin = 60
21
22 # Grab activated pixels
23 nonzero = binary_warped.nonzero()
24 nonzeroy = np.array(nonzero[0])
25 nonzerox = np.array(nonzero[1])
26
27 ### TO-DO: Set the area of search based on activated x-values ###
28 ### within the +/- margin of our polynomial function ###
29 ### Hint: consider the window areas for the similarly named variables ###
30 ### in the previous quiz, but change the windows to our new search area ###
31 left_lane_inds = ((nonzerox > (left_fit[0]*(nonzeroy**2) + left_fit[1]*nonzeroy +
32 left_fit[2] - margin)) & (nonzerox < (left_fit[0]*(nonzeroy**2) +
33 left_fit[1]*nonzeroy + left_fit[2] + margin)))
34 right_lane_inds = ((nonzerox > (right_fit[0]*(nonzeroy**2) + right_fit[1]*nonzeroy +
35 right_fit[2] - margin)) & (nonzerox < (right_fit[0]*(nonzeroy**2) +
36 right_fit[1]*nonzeroy + right_fit[2] + margin)))
37
38 # Again, extract left and right line pixel positions
39 leftx = nonzerox[left_lane_inds]
40 lefty = nonzeroy[left_lane_inds]
41 rightx = nonzerox[right_lane_inds]
42 righty = nonzeroy[right_lane_inds]
43
44 # Fit new polynomials
45 left_fitx, right_fitx, ploty, left_fit, right_fit = fit_poly(binary_warped.shape, leftx, lefty, rightx, righty)
46
47 ## Visualization ##
48 # Create an image to draw on and an image to show the selection window
49 out_img = np.dstack((binary_warped, binary_warped, binary_warped))*255
50 window_img = np.zeros_like(out_img)
51 # Color in left and right line pixels
52 out_img[nonzeroy[left_lane_inds], nonzerox[left_lane_inds]] = [255, 0, 0]
53 out_img[nonzeroy[right_lane_inds], nonzerox[right_lane_inds]] = [0, 0, 255]
54
55 # Generate a polygon to illustrate the search window area
56 # And recast the x and y points into usable format for cv2.fillPoly()
57 left_line_window1 = np.array([np.transpose(np.vstack([left_fitx-margin, ploty]))])
58 left_line_window2 = np.array([np.flipud(np.transpose(np.vstack([left_fitx+margin,
59 ploty])))])
60 left_line_pts = np.hstack((left_line_window1, left_line_window2))
61 right_line_window1 = np.array([np.transpose(np.vstack([right_fitx-margin, ploty]))])
62 right_line_window2 = np.array([np.flipud(np.transpose(np.vstack([right_fitx+margin,
63 ploty])))])
64 right_line_pts = np.hstack((right_line_window1, right_line_window2))
65
66 # Draw the lane onto the warped blank image
67 cv2.fillPoly(window_img, np.int_([left_line_pts]), (0,255, 0))
68 cv2.fillPoly(window_img, np.int_([right_line_pts]), (0,255, 0))
69 result = cv2.addWeighted(out_img, 1, window_img, 0.3, 0)
70
71 # Plot the polynomial lines onto the image
72 #plt.plot(left_fitx, ploty, color='yellow')
73 #plt.plot(right_fitx, ploty, color='yellow')
74 ## End visualization steps ##
75
76 return result, left_fit, right_fit, ploty对以上6种工况进行车道线跟踪,处理结果如下图所示。

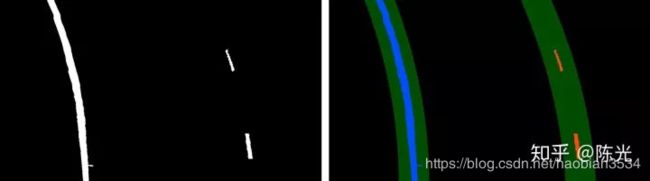

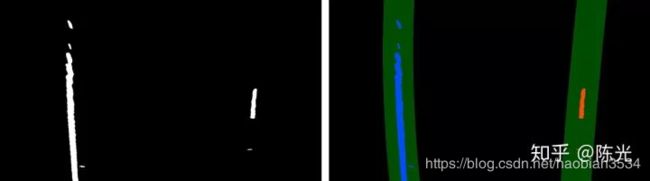
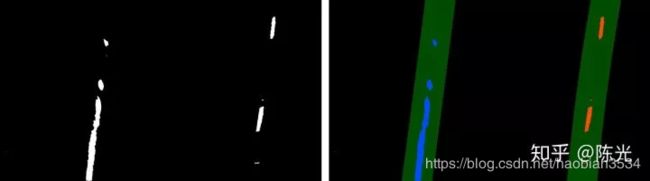
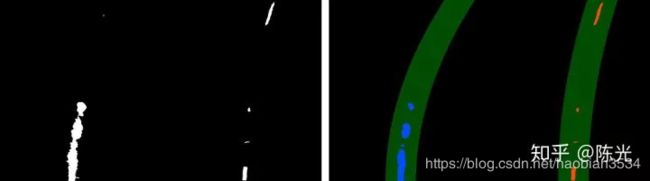
以上,我们就完成了在透视变换结果上的车道线检测和跟踪。
逆投影到原图
我们在计算透视变换矩阵时计算了两个矩阵M和Minv,使用M能够实现透视变换,使用Minv能够实现逆透视变换。
1M = cv2.getPerspectiveTransform(src, dst)
2Minv = cv2.getPerspectiveTransform(dst, src)我们将两条车道线所围成的区域涂成绿色,并将结果绘制在“鸟瞰图”上后,使用逆透视变换矩阵反投到原图上,即可实现在原图上的可视化效果。代码如下:
1#################################################################
2# Step 8 : Draw lane line result on undistorted image
3#################################################################
4def drawing(undist, bin_warped, color_warp, left_fitx, right_fitx):
5 # Create an image to draw the lines on
6 warp_zero = np.zeros_like(bin_warped).astype(np.uint8)
7 color_warp = np.dstack((warp_zero, warp_zero, warp_zero))
8
9 # Recast the x and y points into usable format for cv2.fillPoly()
10 pts_left = np.array([np.transpose(np.vstack([left_fitx, ploty]))])
11 pts_right = np.array([np.flipud(np.transpose(np.vstack([right_fitx, ploty])))])
12 pts = np.hstack((pts_left, pts_right))
13
14 # Draw the lane onto the warped blank image
15 cv2.fillPoly(color_warp, np.int_([pts]), (0,255, 0))
16
17 # Warp the blank back to original image space using inverse perspective matrix (Minv)
18 newwarp = cv2.warpPerspective(color_warp, Minv, (undist.shape[1], undist.shape[0]))
19 # Combine the result with the original image
20 result = cv2.addWeighted(undist, 1, newwarp, 0.3, 0)
21 return result
以上6个场景的左右车道线绘制结果如下所示:






处理视频
在一步步完成摄像机标定、图像畸变校正、透视变换、提取车道线、检测车道线、跟踪车道线后,我们在图像上实现了复杂环境下的车道线检测算法。现在我们将视频转化为图片,然后一帧帧地对视频数据进行处理,然后将车道线检测结果存为另一段视频。
处理代码如下:
1nx = 9
2ny = 6
3ret, mtx, dist, rvecs, tvecs = getCameraCalibrationCoefficients('camera_cal/calibration*.jpg', nx, ny)
4
5src = np.float32([[580, 460], [700, 460], [1096, 720], [200, 720]])
6dst = np.float32([[300, 0], [950, 0], [950, 720], [300, 720]])
7
8video_input = 'project_video.mp4'
9video_output = 'result_video.mp4'
10
11cap = cv2.VideoCapture(video_input)
12
13fourcc = cv2.VideoWriter_fourcc(*'XVID')
14out = cv2.VideoWriter(video_output, fourcc, 20.0, (1280, 720))
15
16detected = False
17
18while(True):
19 ret, image = cap.read()
20 if ret:
21 undistort_image = undistortImage(image, mtx, dist)
22 warp_image, M, Minv = warpImage(undistort_image, src, dst)
23 hlsL_binary = hlsLSelect(warp_image)
24 labB_binary = labBSelect(warp_image, (205, 255))
25 combined_binary = np.zeros_like(sx_binary)
26 combined_binary[(hlsL_binary == 1) | (labB_binary == 0)] = 1
27 left_fit = []
28 right_fit = []
29 ploty = []
30 if detected == False:
31 out_img, left_fit, right_fit, ploty = fit_polynomial(combined_binary, nwindows=9, margin=80, minpix=40)
32 if (len(left_fit) > 0 & len(right_fit) > 0) :
33 detected = True
34 else :
35 detected = False
36 else:
37 track_result, left_fit, right_fit, ploty, = search_around_poly(combined_binary, left_fit, right_fit)
38 if (len(left_fit) > 0 & len(right_fit) > 0) :
39 detected = True
40 else :
41 detected = False
42
43 result = drawing(undistort_image, combined_binary, warp_image, left_fitx, right_fitx)
44
45 out.write(result)
46 else:
47 break
48
49cap.release()
50out.release()最终的视频车道线检测结果如下所示(视频大小7.59M):
视频中左上角出现的道路曲率和车道偏离量的计算都是获取车道线曲线方程后的具体应用,这里不做详细讨论
以上就是《再识图像之高级车道线检测》的全部内容,本次分享中介绍的摄像机标定、投影变换、颜色通道、滑动窗口等技术,在计算机视觉领域均得到了广泛应用。
处理复杂道路场景下的视频数据是一项极其艰巨的任务。仅以提取车道线的过程为例,使用设定规则的方式提取车道线,虽然能够处理项目视频中的场景,但面对变化更为恶劣的场景时,还是无能为力。现阶段解决该问题的方法就是通过深度学习的方法,拿足够多的标注数据去训练模型,才能尽可能多地达到稳定的检测效果。
文章中所使用的图片、视频素材,技术细节和部分代码来自《优达学城(Udacity)无人驾驶工程师学位》的第二个项目。