sift特征提取算法
简介
SIFT算法是用来提取图像局部特征的经典算法,SIFT算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
主要步骤
1、构建DOG尺度空间
2、关键点搜索和定位
3、方向赋值
4、关键点描述子的生成
算法详细流程
————————————————————————————————————————————————————————————————1,构建DOG尺度空间
(1)基础知识
(a)尺度空间:
在视觉信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得不同尺度下的视觉处理信息,然后综合这些信息以深入地挖掘图像的本质特征。尺度空间方法将传统的单尺度视觉信息处理技术纳入尺度不断变化的动态分析框架中,因此更容易获得图像的本质特征。尺度空间的生成目的是模拟图像数据多尺度特征。
尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。大尺度对应图像的概貌特征,小尺度对应图像的细节特征。所以对不同尺度的图像检测关键点,最终得到的sift特征点具有尺度不变性。尺度空间是客观存在的,我们使用高斯卷积的形式来表现尺度空间。一幅二维图像的尺度空间可以定义为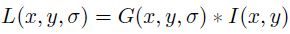
其中I(x,y)是图像区域,G(x,y,σ)是尺度可变高斯函数,x,y是空间坐标,σ大小决定图像的平滑程度。
参考材料:http://blog.csdn.net/tanxinwhu/article/details/7048370
(b)高斯模糊:
这里尺度空间的生成需要使用高斯模糊来实现,Lindeberg等人已经证明高斯卷积核是实现尺度变换的唯一线性核。高斯模糊是一种图像滤波器,它使用正态分布(高斯函数)计算模糊模板,并使用该模板与原图像做卷积运算,达到模糊图像的目的。N维空间正态分布方程为:
其中,是正态分布的标准差,
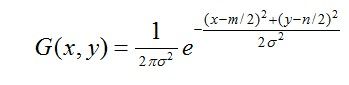
对图像做卷积运算可以看做是加权求和的过程,把使用到的图像区域中的每个元素分别与卷积核的每个对应位置的元素相乘,所有乘积之和作为区域中心的像素值。一个5*5的高斯模板: 可以看出高斯模板是圆对称的,且卷积的结果使原始像素值有最大的权重,距离中心越远的相邻像素值权重也越小。在实际应用中,在计算高斯函数的离散近似时,在大概3σ距离之外的像素都可以看作不起作用,这些像素的计算也就可以忽略。所以,通常程序只计算(6σ+1)*(6σ+1)就可以保证相关像素影响。
可以看出高斯模板是圆对称的,且卷积的结果使原始像素值有最大的权重,距离中心越远的相邻像素值权重也越小。在实际应用中,在计算高斯函数的离散近似时,在大概3σ距离之外的像素都可以看作不起作用,这些像素的计算也就可以忽略。所以,通常程序只计算(6σ+1)*(6σ+1)就可以保证相关像素影响。
参考材料:http://www.cnblogs.com/slysky/archive/2011/11/25/2262899.html
(2)构建高斯金字塔
金字塔是图像多尺度的表示形式,传统的金字塔中,每一层都是由上一层降采样得到,也就是长宽都隔一行(列)采样,最终得到原图的1/4。如下图:
而为了得到DOG图像,要先构造高斯金字塔,高斯金字塔就是在传统金字塔的基础上,对每一层用不同的参数σ做高斯模糊,使得每一层金字塔有多张高斯模糊图像,这样一组图像是一个octave。如下图,octave间是降采样关系,且octave(i+1)的第一张(从下往上数)图像是由octave(i)中德倒数第三张图像降采样得到。octave内的图像大小一样,只是高斯模糊使用的尺度参数不同。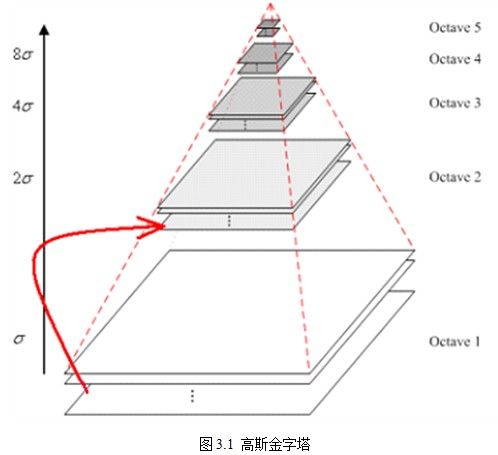
(3)LOG和DOG
2002年Mikolajczyk在详细的实验比较中发现尺度归一化的高斯拉普拉斯函数的极大值和极小值能产生稳定的图像特征。但此处若使用LOG,则后续计算量较大,故使用DOG来代替LOG,用差分代替微分。
LOG就是对高斯函数做拉普拉斯变换:
Lindeberg早在1994年就发现高斯差分函数(Difference of Gaussian ,简称DOG算子)与尺度归一化的高斯拉普拉斯函数
和
利用差分近似代替微分,则有:

因此有
其中k-1是个常数,并不影响极值点位置的求取。
(a)是DoG的三维图,(b)是DoG与LoG的对比。
(4)构建DOG金字塔
为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。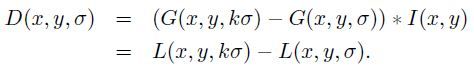 在检测极值点前对原始图像进行的高斯平滑以致图像丢失高频信息,所以原始论文中建议在建立尺度空间之前对原始图像的长宽扩展一倍,以保留原始图像信息,增加特征点数量。
在检测极值点前对原始图像进行的高斯平滑以致图像丢失高频信息,所以原始论文中建议在建立尺度空间之前对原始图像的长宽扩展一倍,以保留原始图像信息,增加特征点数量。
对于一幅图像,建立其在不同尺度scale下的图像,也称为octave,这是为了scale-invariant,也就是在任何尺度都能有对应的特征点。下图中右侧的DOG就是我们构建的尺度空间。
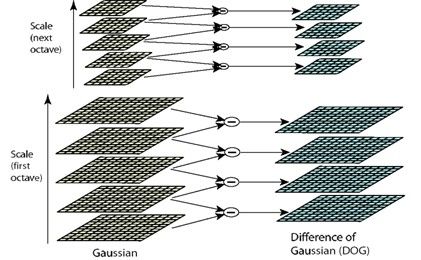 尺度scale的所有取值:
尺度scale的所有取值: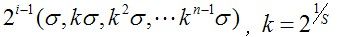 i是octave的序号,s是每组的层数(一般是3-5层),这个一般由图像size决定。
i是octave的序号,s是每组的层数(一般是3-5层),这个一般由图像size决定。
2,关键点搜索和定位
(1)关键点搜索
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点。下图中将叉号点要比较的26个点都标为了绿色。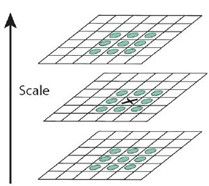 同一组的相邻尺度之间进行寻找:
同一组的相邻尺度之间进行寻找: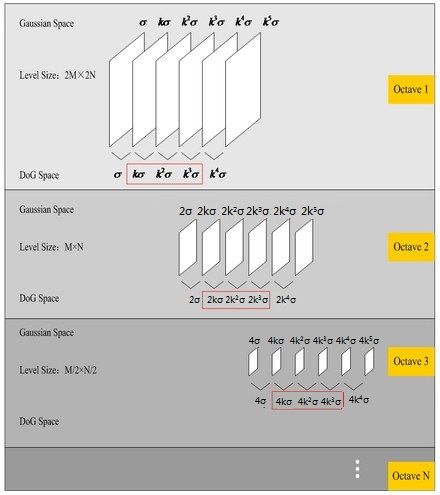 因为首尾两张图都只有一个相邻图,无法进行极值比较(因为极值定义中,极值点是连续的)。为了满足尺度变化连续性,要在octave每一组的顶层再生成3幅图像,则高斯金字塔有S+3幅图像,而DOG金字塔有S+2幅图像。
因为首尾两张图都只有一个相邻图,无法进行极值比较(因为极值定义中,极值点是连续的)。为了满足尺度变化连续性,要在octave每一组的顶层再生成3幅图像,则高斯金字塔有S+3幅图像,而DOG金字塔有S+2幅图像。
关于尺度变化连续性:(参考材料:http://blog.csdn.net/abcjennifer/article/details/7639681)假设s=3,也就是每个塔里有3层,则k=21/s=21/3,那么按照上图可得Gauss Space和DoG space 分别有3个(s个)和2个(s-1个)分量,在DoG space中,1st-octave两项分别是σ,kσ; 2nd-octave两项分别是2σ,2kσ;由于无法比较极值,我们必须在高斯空间继续添加高斯模糊项,使得形成σ,kσ,k2σ,k3σ,k4σ这样就可以选择DoG space中的中间三项kσ,k2σ,k3σ(只有左右都有才能有极值),那么下一octave中(由上一层降采样获得)所得三项即为2kσ,2k2σ,2k3σ,其首项2kσ=24/3。刚好与上一octave末项k3σ=23/3尺度变化连续起来,所以每次要在Gaussian space添加3项,每组(塔)共S+3层图像,相应的DoG金字塔有S+2层图像。
(2)关键点精确定位
以上极值点的搜索是在离散空间进行搜索的,由下图可以看到,在离散空间找到的极值点不一定是真正意义上的极值点。可以通过对尺度空间DoG函数进行曲线拟合寻找极值点来减小这种误差。 利用DoG函数在尺度空间的Taylor展开式:
利用DoG函数在尺度空间的Taylor展开式: 则极值点为:
则极值点为:
(3)删除边缘效应
除了DoG响应较低的点,还有一些响应较强的点也不是稳定的特征点。DoG对图像中的边缘有较强的响应值,所以落在图像边缘的点也不是稳定的特征点。一个平坦的DoG响应峰值在横跨边缘的地方有较大的主曲率,而在垂直边缘的地方有较小的主曲率。主曲率可以通过2×2的Hessian矩阵H求出: D值可以通过求临近点差分得到。H的特征值与D的主曲率成正比,具体可参见Harris角点检测算法。为了避免求具体的值,我们可以通过H将特征值的比例表示出来。令
D值可以通过求临近点差分得到。H的特征值与D的主曲率成正比,具体可参见Harris角点检测算法。为了避免求具体的值,我们可以通过H将特征值的比例表示出来。令为最大特征值,
为最小特征值,那么:

Tr(H)表示矩阵H的迹,Det(H)表示H的行列式。令表示最大特征值与最小特征值的比值,则有:
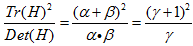 上式与两个特征值的比例有关。随着主曲率比值的增加,
上式与两个特征值的比例有关。随着主曲率比值的增加,也会增加。我们只需要去掉比率大于一定值的特征点。Lowe论文中去掉r=10的点。
边缘效应的删除能够更进一步的得到稳定的特征点。因为一个物体的边缘在不同的图像中或者在同一副图像中都可能会有变化。E.g. 一个正方形,在一幅图像中可以是两条水平线以及两条垂直的线组成,而在另一幅图像中,可以是有角度的旋转,类似于普通菱形。而其实它们都是同一个图像,如果利用边缘去做识别的话,因为4条边完全不一样,那就有可能识别错误。所以我们需要将这些边缘特征尽可能的删除,留下最具代表性的角上的点。在SIFT中,DOG算子近似拉普拉斯算子,对边缘都有很强的检测效果,那当然需要从这些特征点中删除哪些是具有强边缘效应的点。
至此,我们得到了关键点的位置信息和尺度信息(x,y,σ)。
3,方向赋值
为了实现图像的旋转不变性,需要根据检测到的关键点的局部图像结构为特征点方向赋值。(1)梯度直方图
方向直方图的核心是统计以关键点为原点,一定区域内的图像像素点对关键点方向生成所作的贡献。在上一步,精确定位关键点后,可以得到该特征点的尺度值σ,根据这一尺度值,得到最接近这一尺度值的高斯图像:
使用有限差分,计算以关键点为中心,以3×1.5σ为半径的区域内图像梯度的幅角和幅值,公式如下:
梯度方向直方图的横轴是梯度方向角,纵轴是剃度方向角对应的梯度幅值累加值。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。
在计算直方图时,每个加入直方图的采样点都使用圆形高斯函数函数进行了加权处理,也就是进行高斯平滑。这主要是因为SIFT算法只考虑了尺度和旋转不变形,没有考虑仿射不变性。通过高斯平滑,可以使关键点附近的梯度幅值有较大权重,从而部分弥补没考虑仿射不变形产生的特征点不稳定。
这里的直方图统计,我在阅读了labelme中实现的源码之后发现具体做法是,把每个梯度向量分解到这8个方向,然后将这8个方向每个方向分到的幅值加在这个方向对应的直方图柱上。
(2)关键点方向
直方图峰值代表该关键点邻域内图像梯度的主方向,当存在另一个相当于主峰值 80%能量的峰值时,则认为这个方向是该关键点的辅方向。所以一个关键点可能检测得到多个方向,这可以增强匹配的鲁棒性。Lowe的论文指出大概有15%关键点具有多方向,但这些点对匹配的稳定性至为关键。
具有多个方向的关键点可以复制成多份,然后将方向值分别赋给复制后的关键点。
至此,我们得到了关键点的位置、尺度、方向信息(x,y,σ,θ)。h(x,y,θ)是一个三维矩阵,但通常经过矩阵压缩后用一个向量表示。
4,关键点描述子的生成
这个描述子不但包括关键点,也包括关键点周围对其有贡献的像素点。这样可使关键点有更多的不变特性,提高目标匹配效率。
(1)描述子采样区域
特征描述子与关键点所在尺度有关,因此对梯度的求取应在特征点对应的高斯图像上进行。将关键点附近划分成d×d个子区域,每个子区域尺寸为mσ个像元(d=4,m=3,σ为尺特征点的尺度值)。考虑到实际计算时需要双线性插值,故计算的图像区域为mσ(d+1),再考虑旋转,则实际计算的图像区域为,如下图所示:
 关于双线性插值:(参考材料:http://blog.sina.com.cn/s/blog_73428e9a0101ibin.html)
关于双线性插值:(参考材料:http://blog.sina.com.cn/s/blog_73428e9a0101ibin.html)在opencv中旋转图片时,旋转后的图片中会出现许多白点,对这些白点进行填充,就是插值处理。在二维图像中,就是做双线性插值。
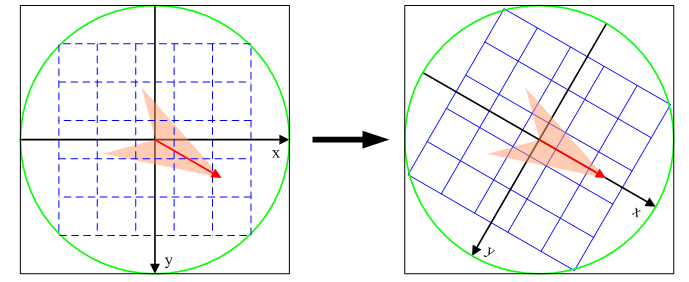
下图模拟图像的旋转过程中,坐标变换和像素点位置变化:
(2)区域坐标旋转
为了使sift特征点具有旋转不变性,要以特征点为中心,在附近邻域内旋转θ角,即旋转为特征点的方向。
 旋转后区域内采样点新的坐标为:
旋转后区域内采样点新的坐标为: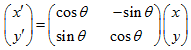
(3)计算采样区域梯度直方图
将旋转后区域划分为d×d个子区域(每个区域间隔为mσ像元),在子区域内计算8个方向的梯度直方图,绘制每个方向梯度方向的累加值,形成一个种子点。与求主方向不同的是,此时,每个子区域梯度方向直方图将0°~360°划分为8个方向区间,每个区间为45°。即每个种子点有8个方向区间的梯度强度信息。然后对子区域的像素的梯度大小采用mσd/2的高斯加权函数加权。由于存在d×d,即4×4个子区域,所以最终共有4×4×8=128个数据,形成128维SIFT特征矢量。特征向量形成后,为了去除光照变化的影响,需要对它们进行归一化处理。
 ——————————————————————————————————————————————————————Reference:主要学习思路和大部分图片来自这里:http://blog.csdn.net/xiaowei_cqu/article/details/8069548这里的数学推导很详细:http://blog.csdn.net/zddblog/article/details/7521424一些sift相关资源集合:http://www.360doc.com/content/10/0708/09/1472642_37587082.shtml
——————————————————————————————————————————————————————Reference:主要学习思路和大部分图片来自这里:http://blog.csdn.net/xiaowei_cqu/article/details/8069548这里的数学推导很详细:http://blog.csdn.net/zddblog/article/details/7521424一些sift相关资源集合:http://www.360doc.com/content/10/0708/09/1472642_37587082.shtml







