利用深度学习(CNN)进行验证码(字母+数字)识别
本文方法针对的验证码为定长验证码,不包含中文。
本文的思路是:1. 使用keras中预训练好的模型,在python生成的验证码(5万条)上fine tune,得到python验证码模型;2. 使用python验证码模型,在实际验证码(500条)上fine tune;3. 增加样本,提高精度。
通俗的解释2个问题:
- keras中预训练好的模型是什么东西?
答: keras上有很多已经训练好的图像识别模型,诸如Alex Net,google net,VGG16,VGG19,ResNet50,Xception,InceptionV3,这些都是由ImageNet训练而来。那ImageNet又是什么的?ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库,超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象。说白了,上述已经训练好的图像识别模型是用来识别大千世界的各种物品的,如气球、草莓、汽车、楼房等等。这些个模型都能识别这么复杂的东西了,那我现在要识别一个验证码数据,岂不是很简单?这就是站在巨人的肩膀上,再微微调整一下模型就可以了。这其实就是迁移学习的概念。
- 为什么要先使用python生成得验证码进行fine tune?
答: 虽说我们站在巨人的肩膀上,利用已有的深度神经网络来微调我们的模型,但是从大千世界迁移到验证码图片,这两个样本集还是有很大的差别的。这就要求我们用“大量“的验证码数据再去训练我们的神经网络参数。这个”大量“我为什么用引号呢,因为其实只需要数万张(下文使用了5万)验证码图片就可以了,相对于ImageNet的1400万,这个数字其实很小,但是如果需要我们手工标记数万张验证码,那就是不小的工作量了。所以,我们先用python自动生成标记好的5万张验证码图片,先进行fine tune,保存好输出的模型,注意,这个模型已经不是识别大千世界的模型了,是识别数字和英文字母的模型了,但是直接应用于实际的验证码,效果还是很差,因为两种验证码长得不一样,然后我们进行再一次的迁移学习,再在我们手工标记好的、实际要识别的验证码(500条)进行fine tune,这样就可以识别很好的识别我们要识别的验证码了。
1. 利用python生成你所需要的验证码
一般的验证码都为4位,由数字和大小写字母构成。利用python的captcha模块,生成5万张样本图片:
from captcha.image import ImageCaptcha
from random import randint
def gen_captcha(num,captcha_len):
# # 纯数字,如果目标识别是10位数字,预训练用纯数字效果更好
# list = [chr(i) for i in range(48, 58)]
# # 10数字+26大写字母+26小写字母
list = [chr(i) for i in range(48, 58)] + [chr(i) for i in range(65, 91)] + [chr(i) for i in range(97, 123)]
for j in range(num):
if j % 100 == 0:
print(j)
chars = ''
for i in range(captcha_len):
rand_num = randint(0, 61)
chars += list[rand_num]
image = ImageCaptcha().generate_image(chars)
image.save('./train/' + chars + '.jpg')
num = 50000
captcha_len = 4
gen_captcha(num,captcha_len)这样我们就轻松的获取到了5万张样本数据

2. 使用python生成的样本进行预训练
keras_weight中Alex Net,google net,VGG16,VGG19,ResNet50,Xception,InceptionV3。都是由ImageNet训练而来。这里使用Xception模型
Xception模型
参考keras文档:https://keras.io/zh/applications/#xception
keras.applications.xception.Xception(include_top=True,
weights='imagenet', input_tensor=None,
input_shape=None, pooling=None, classes=1000)在 ImageNet 上预训练的 Xception V1 模型。
在 ImageNet 上,该模型取得了验证集 top1 0.790 和 top5 0.945 的准确率。
注意该模型只支持 channels_last 的维度顺序(高度、宽度、通道)。
模型默认输入尺寸是 299x299
参数
include_top: 是否包括顶层的全连接层。
weights: None 代表随机初始化, 'imagenet' 代表加载在 ImageNet 上预训练的权值。
input_tensor: 可选,Keras tensor 作为模型的输入(即 layers.Input() 输出的 tensor)。
input_shape: 可选,输入尺寸元组,仅当 include_top=False 时有效(否则输入形状必须是 (299, 299, 3),因为预训练模型是以这个大小训练的)。它必须拥有 3 个输入通道,且宽高必须不小于 71。例如 (150, 150, 3) 是一个合法的输入尺寸。
pooling: 可选,当 include_top 为 False 时,该参数指定了特征提取时的池化方式。
None 代表不池化,直接输出最后一层卷积层的输出,该输出是一个 4D 张量。
'avg' 代表全局平均池化(GlobalAveragePooling2D),相当于在最后一层卷积层后面再加一层全局平均池化层,输出是一个 2D 张量。
'max' 代表全局最大池化。
classes: 可选,图片分类的类别数,仅当 include_top 为 True 并且不加载预训练权值时可用。
3. 模型训练
模型训练的代码如下:
import numpy as np
import glob
from keras.applications.xception import Xception,preprocess_input
from keras.layers import Input,Dense,Dropout
from keras.models import Model
from scipy import misc
samples = glob.glob('./train/*.jpg') # 获取所有样本图片
np.random.shuffle(samples) # 将图片打乱
nb_train = 45000 #共有5万样本,4.5万用于训练,5k用于验证
train_samples = samples[:nb_train]
test_samples = samples[nb_train:]
letter_list = [chr(i) for i in range(48, 58)] + [chr(i) for i in range(65, 91)] # 需要识别的36类
# CNN适合在高宽都是偶数的情况,否则需要在边缘补齐,把全体图片都resize成这个尺寸(高,宽,通道)
img_size = (60, 160)
input_image = Input(shape=(img_size[0],img_size[1],3))
#直接将验证码输入,做几个卷积层提取特征,然后把这些提出来的特征连接几个分类器(36分类,因为不区分大小写),
#输入图片
#用预训练的Xception提取特征,采用平均池化
base_model = Xception(input_tensor=input_image, weights='imagenet', include_top=False, pooling='avg')
#用全连接层把图片特征接上softmax然后36分类,dropout为0.5,因为是多分类问题,激活函数使用softmax。
#ReLU - 用于隐层神经元输出
#Sigmoid - 用于隐层神经元输出
#Softmax - 用于多分类神经网络输出
#Linear - 用于回归神经网络输出(或二分类问题)
predicts = [Dense(36, activation='softmax')(Dropout(0.5)(base_model.output)) for i in range(4)]
model = Model(inputs=input_image, outputs=predicts)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
#misc.imread把图片转化成矩阵,
#misc.imresize重塑图片尺寸misc.imresize(misc.imread(img), img_size) img_size是自己设定的尺寸
#ord()函数主要用来返回对应字符的ascii码,
#chr()主要用来表示ascii码对应的字符他的输入时数字,可以用十进制,也可以用十六进制。
def data_generator(data, batch_size): #样本生成器,节省内存
while True:
#np.random.choice(x,y)生成一个从x中抽取的随机数,维度为y的向量,y为抽取次数
batch = np.random.choice(data, batch_size)
x,y = [],[]
for img in batch:
x.append(misc.imresize(misc.imread(img), img_size)) # 读取resize图片,再存进x列表
real_num = img[-8:-4]
y_list = []
for i in real_num:
i = i.upper()
if ord(i) - ord('A') >= 0:
y_list.append(ord(i) - ord('A') + 10)
else:
y_list.append(ord(i) - ord('0'))
y.append(y_list)
#把验证码标签添加到y列表,ord(i)-ord('a')把对应字母转化为数字a=0,b=1……z=26
x = preprocess_input(np.array(x).astype(float))
#原先是dtype=uint8转成一个纯数字的array
y = np.array(y)
yield x,[y[:,i] for i in range(4)]
#输出:图片array和四个转化成数字的字母 例如:[array([6]), array([0]), array([3]), array([24])])
model.fit_generator(data_generator(train_samples, 100), steps_per_epoch=450, epochs=5, validation_data=data_generator(test_samples, 100), validation_steps=100)
#参数:generator生成器函数,
#samples_per_epoch,每个epoch以经过模型的样本数达到samples_per_epoch时,记一个epoch结束
#step_per_epoch:整数,当生成器返回step_per_epoch次数据是记一个epoch结束,执行下一个epoch
#epochs:整数,数据迭代的轮数
#validation_data三种形式之一,生成器,类(inputs,targets)的元组,或者(inputs,targets,sample_weights)的元祖
#若validation_data为生成器,validation_steps参数代表验证集生成器返回次数
#class_weight:规定类别权重的字典,将类别映射为权重,常用于处理样本不均衡问题。
#sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode='temporal'。
#workers:最大进程数
#max_q_size:生成器队列的最大容量
#pickle_safe: 若为真,则使用基于进程的线程。由于该实现依赖多进程,不能传递non picklable(无法被pickle序列化)的参数到生成器中,因为无法轻易将它们传入子进程中。
#initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
#保存模型
model.save('CaptchaForPython.h5')
这里只跑了5个epoch,本机电脑cpu跑的话,大概需要跑24小时左右。有条件的可以使用gpu跑。
跑的时候输出如下:Epoch 1/5表示跑第一个epoch;1/450表示跑第一个step;ETA: 6:05:12表示跑完这个epoch的剩余时间,这边显示6小时,实际4个小时左右;接下来为总的loss值和四个预测值依次的loss值;然后为4个预测值的准确率。
Epoch 1/5
1/450 [..............................] - ETA: 6:05:12 - loss: 14.6667 - dense_1_loss: 3.6935 - dense_2_loss: 3.7089 - dense_3_loss: 3.6337 - dense_4_loss: 3.6307 - dense_1_acc: 0.0400 - dense_2_acc: 0.0100 - dense_3_acc: 0.0300 - dense_4_acc: 0.0400
2/450 [..............................] - ETA: 4:58:17 - loss: 14.6598 - dense_1_loss: 3.6988 - dense_2_loss: 3.6536 - dense_3_loss: 3.6569 - dense_4_loss: 3.6505 - dense_1_acc: 0.0300 - dense_2_acc: 0.0300 - dense_3_acc: 0.0300 - dense_4_acc: 0.0450
3/450 [..............................] - ETA: 4:30:12 - loss: 14.6189 - dense_1_loss: 3.6936 - dense_2_loss: 3.6495 - dense_3_loss: 3.6589 - dense_4_loss: 3.6168 - dense_1_acc: 0.0300 - dense_2_acc: 0.0333 - dense_3_acc: 0.0267 - dense_4_acc: 0.0500
4/450 [..............................] - ETA: 4:17:47 - loss: 14.5575 - dense_1_loss: 3.6768 - dense_2_loss: 3.6342 - dense_3_loss: 3.6384 - dense_4_loss: 3.6083 - dense_1_acc: 0.0325 - dense_2_acc: 0.0325 - dense_3_acc: 0.0300 - dense_4_acc: 0.0525
5/450 [..............................] - ETA: 4:11:03 - loss: 14.5314 - dense_1_loss: 3.6617 - dense_2_loss: 3.6261 - dense_3_loss: 3.6289 - dense_4_loss: 3.6146 - dense_1_acc: 0.0340 - dense_2_acc: 0.0300 - dense_3_acc: 0.0300 - dense_4_acc: 0.0520
6/450 [..............................] - ETA: 4:05:27 - loss: 14.4945 - dense_1_loss: 3.6480 - dense_2_loss: 3.6178 - dense_3_loss: 3.6207 - dense_4_loss: 3.6080 - dense_1_acc: 0.0350 - dense_2_acc: 0.0317 - dense_3_acc: 0.0267 - dense_4_acc: 0.0467
等跑完这5个epoch,4个预测值的准确率基本上到达95%以上了,保存下来的模型权重已经可以为我们所用了。
4. 获取你要识别的验证码图片
假设我们要识别中国电信(https://login.189.cn/web/login)登录时的验证码,该验证码是4位定长,10个数字+26个大写字母。
获取你需要识别的验证码,需要利用python将图片从网站上爬取下来。下面以中国电信为例,简单介绍如何爬取图片。
打开中国电信登录页面https://login.189.cn/web/login,单击右键,选择“检查”,在跳出来的页面中,选择“Network”。

在电话号码输入框,随便输一个电话号码,输完后便会跳出验证码,点击验证码,验证码会重新加载,同时右侧”Network”也抓取到了验证码的加载地址。

单击其中一条数据,查看Headers,我们就获取到了验证码的request url地址,以及request headers。
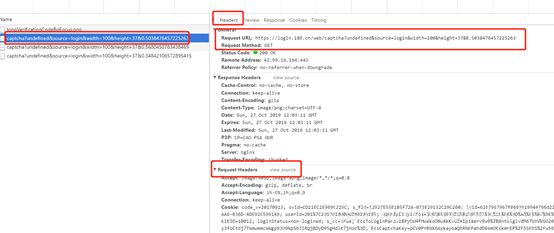
现在我们就可以利用python爬取中国电信的验证码图片了。由于验证码图片并没有设置反爬机制,所以我们在请求的时候只用到了request url,并没有用request headers包装我们的请求头。
import urllib.request
url = 'https://login.189.cn/web/captcha?undefined&source=login&width=100&height=37&0.564730904066772'
for i in range(500):
if i % 100 == 0:
print(i)
f = open('./dianxin/'+str(i)+'.jpg','wb')
f.write((urllib.request.urlopen(url)).read())
f.close()
获取到500张样本图片后呢,就要劳烦我们自个标记一下了。

5. 使用实际验证码进行再次训练
训练
现在我们使用我们手工标记的500张验证码图片,进行第二次的fine tune,代码如下。你会发现,这个代码跟上面的代码几乎一模一样,只是多了一步model.load_weights('CaptchaForPython.h5'),这就是在加载我们上一步保存的网络参数;同时Xception的weights设置为None了,就是没有加载Xception原来的网络参数,前面的过程,就是搭了一个深度网络的框架而已。
import numpy as np
from scipy import misc
from keras.applications.xception import Xception,preprocess_input
import glob
from keras.layers import Input,Dense,Dropout
from keras.models import Model
img_size = (70, 160)
input_image = Input(shape=(img_size[0],img_size[1],3))
base_model = Xception(input_tensor=input_image, weights=None, include_top=False, pooling='avg')
predicts = [Dense(36, activation='softmax')(Dropout(0.5)(base_model.output)) for i in range(4)]
model = Model(inputs=input_image, outputs=predicts)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.load_weights('CaptchaForPython.h5')
def data_generator(data, batch_size): #样本生成器,节省内存
while True:
batch = np.random.choice(data, batch_size)
x,y = [],[]
for img in batch:
im = misc.imread(img)
im = im[:, :, :3]
im = misc.imresize(im, img_size)
x.append(im)
real_num = img[-8:-4]
y_list = []
for i in real_num:
if ord(i)-ord('A') >= 0:
y_list.append(ord(i)-ord('A')+10)
else:
y_list.append(ord(i)-ord('0'))
y.append(y_list)
x = preprocess_input(np.array(x).astype(float))
y = np.array(y)
yield x,[y[:,i] for i in range(4)]
#获取指定目录下的所有图片
samples = glob.glob('dianxin/*.jpg')
np.random.shuffle(samples)
nb_train = 450
train_samples = samples[:nb_train]
test_samples = samples[nb_train:]
#Continue training
model.fit_generator(data_generator(train_samples, 30), steps_per_epoch=15, epochs=7, validation_data=data_generator(test_samples, 10), validation_steps=5)
model.save('CaptchaForDianxin_from_python_1.h5')
- 模型训练的时候几个指标怎么设置?
训练样本是450个,可以看到我的batch_size(即每次batch训练的样本数量)是30,每个epoch是15步,看出来了么,30*15=450。同样,测试集是50个,所以validation的test_sample*validation_steps=30。同样适用于上面对5w张验证码进行训练的代码,大家可以翻上去看一下。
- 为什么保存模型'CaptchaForDianxin_from_python_1.h5'?
因为这个模型只用了450张图片进行训练,后面还需要增加样本再进一步fine tune,所以用了“_1“来命名模型。
训练结果如下,可以看到,由于训练样本小(450张),训练速度很快,一个epoch大概3分钟不到,且到第一个epoch结束,测试集的四位准确率已经到达80%左右(val_dense_1_acc: 0.8200 - val_dense_2_acc: 0.9000 - val_dense_3_acc: 0.7400 - val_dense_4_acc: 0.8400)。
Epoch 1/7
1/15 [=>............................] - ETA: 5:21 - loss: 26.9934 - dense_1_loss: 8.0300 - dense_2_loss: 5.5903 - dense_3_loss: 5.8983 - dense_4_loss: 7.4748 - dense_1_acc: 0.1667 - dense_2_acc: 0.2333 - dense_3_acc: 0.2667 - dense_4_acc: 0.1333
2/15 [===>..........................] - ETA: 3:49 - loss: 24.8148 - dense_1_loss: 7.4826 - dense_2_loss: 5.0729 - dense_3_loss: 5.8344 - dense_4_loss: 6.4249 - dense_1_acc: 0.2667 - dense_2_acc: 0.2667 - dense_3_acc: 0.2333 - dense_4_acc: 0.1667
3/15 [=====>........................] - ETA: 3:08 - loss: 22.7996 - dense_1_loss: 7.3436 - dense_2_loss: 5.0177 - dense_3_loss: 5.0447 - dense_4_loss: 5.3936 - dense_1_acc: 0.2889 - dense_2_acc: 0.2667 - dense_3_acc: 0.2556 - dense_4_acc: 0.2444
4/15 [=======>......................] - ETA: 2:41 - loss: 21.4098 - dense_1_loss: 7.0998 - dense_2_loss: 4.7698 - dense_3_loss: 4.8378 - dense_4_loss: 4.7024 - dense_1_acc: 0.2833 - dense_2_acc: 0.2917 - dense_3_acc: 0.2917 - dense_4_acc: 0.3167
5/15 [=========>....................] - ETA: 2:19 - loss: 19.5361 - dense_1_loss: 6.6055 - dense_2_loss: 4.2805 - dense_3_loss: 4.5223 - dense_4_loss: 4.1277 - dense_1_acc: 0.3000 - dense_2_acc: 0.3400 - dense_3_acc: 0.3200 - dense_4_acc: 0.3733
6/15 [===========>..................] - ETA: 2:01 - loss: 17.2208 - dense_1_loss: 5.8171 - dense_2_loss: 3.8086 - dense_3_loss: 4.0312 - dense_4_loss: 3.5639 - dense_1_acc: 0.3611 - dense_2_acc: 0.4000 - dense_3_acc: 0.3667 - dense_4_acc: 0.4500
7/15 [=============>................] - ETA: 1:45 - loss: 16.1136 - dense_1_loss: 5.5105 - dense_2_loss: 3.5737 - dense_3_loss: 3.7542 - dense_4_loss: 3.2753 - dense_1_acc: 0.3905 - dense_2_acc: 0.4333 - dense_3_acc: 0.4048 - dense_4_acc: 0.4857
8/15 [===============>..............] - ETA: 1:30 - loss: 15.0458 - dense_1_loss: 5.1275 - dense_2_loss: 3.3375 - dense_3_loss: 3.5751 - dense_4_loss: 3.0056 - dense_1_acc: 0.4250 - dense_2_acc: 0.4708 - dense_3_acc: 0.4375 - dense_4_acc: 0.5208
9/15 [=================>............] - ETA: 1:16 - loss: 14.1483 - dense_1_loss: 4.6975 - dense_2_loss: 3.2369 - dense_3_loss: 3.3625 - dense_4_loss: 2.8515 - dense_1_acc: 0.4630 - dense_2_acc: 0.4815 - dense_3_acc: 0.4630 - dense_4_acc: 0.5370
10/15 [===================>..........] - ETA: 1:02 - loss: 13.1816 - dense_1_loss: 4.3671 - dense_2_loss: 2.9939 - dense_3_loss: 3.1700 - dense_4_loss: 2.6506 - dense_1_acc: 0.4900 - dense_2_acc: 0.5067 - dense_3_acc: 0.4933 - dense_4_acc: 0.5700
11/15 [=====================>........] - ETA: 49s - loss: 12.4837 - dense_1_loss: 4.0982 - dense_2_loss: 2.8409 - dense_3_loss: 3.0433 - dense_4_loss: 2.5012 - dense_1_acc: 0.5091 - dense_2_acc: 0.5212 - dense_3_acc: 0.5091 - dense_4_acc: 0.5939
12/15 [=======================>......] - ETA: 36s - loss: 11.7352 - dense_1_loss: 3.8170 - dense_2_loss: 2.6642 - dense_3_loss: 2.8542 - dense_4_loss: 2.3998 - dense_1_acc: 0.5278 - dense_2_acc: 0.5500 - dense_3_acc: 0.5333 - dense_4_acc: 0.6139
13/15 [=========================>....] - ETA: 24s - loss: 11.1570 - dense_1_loss: 3.6193 - dense_2_loss: 2.5443 - dense_3_loss: 2.7291 - dense_4_loss: 2.2644 - dense_1_acc: 0.5410 - dense_2_acc: 0.5641 - dense_3_acc: 0.5487 - dense_4_acc: 0.6333
14/15 [===========================>..] - ETA: 12s - loss: 10.6230 - dense_1_loss: 3.4717 - dense_2_loss: 2.4350 - dense_3_loss: 2.5624 - dense_4_loss: 2.1538 - dense_1_acc: 0.5476 - dense_2_acc: 0.5857 - dense_3_acc: 0.5690 - dense_4_acc: 0.6500
15/15 [==============================] - 185s 12s/step - loss: 10.0801 - dense_1_loss: 3.2947 - dense_2_loss: 2.3047 - dense_3_loss: 2.4300 - dense_4_loss: 2.0507 - dense_1_acc: 0.5689 - dense_2_acc: 0.6022 - dense_3_acc: 0.5867 - dense_4_acc: 0.6600 - val_loss: 3.1664 - val_dense_1_loss: 0.8683 - val_dense_2_loss: 0.3158 - val_dense_3_loss: 0.7921 - val_dense_4_loss: 1.1902 - val_dense_1_acc: 0.8200 - val_dense_2_acc: 0.9000 - val_dense_3_acc: 0.7400 - val_dense_4_acc: 0.8400
Epoch 2/7
1/15 [=>............................] - ETA: 2:36 - loss: 1.3170 - dense_1_loss: 0.3431 - dense_2_loss: 0.4282 - dense_3_loss: 0.4664 - dense_4_loss: 0.0792 - dense_1_acc: 0.9000 - dense_2_acc: 0.9000 - dense_3_acc: 0.9333 - dense_4_acc: 1.0000
2/15 [===>..........................] - ETA: 2:24 - loss: 1.8133 - dense_1_loss: 0.5713 - dense_2_loss: 0.5021 - dense_3_loss: 0.5045 - dense_4_loss: 0.2354 - dense_1_acc: 0.8500 - dense_2_acc: 0.9000 - dense_3_acc: 0.9000 - dense_4_acc: 0.9667
3/15 [=====>........................] - ETA: 2:13 - loss: 1.8234 - dense_1_loss: 0.4772 - dense_2_loss: 0.4436 - dense_3_loss: 0.5648 - dense_4_loss: 0.3379 - dense_1_acc: 0.8667 - dense_2_acc: 0.8889 - dense_3_acc: 0.8778 - dense_4_acc: 0.9222
4/15 [=======>......................] - ETA: 2:02 - loss: 1.8447 - dense_1_loss: 0.4957 - dense_2_loss: 0.4421 - dense_3_loss: 0.5911 - dense_4_loss: 0.3159 - dense_1_acc: 0.8583 - dense_2_acc: 0.8917 - dense_3_acc: 0.8833 - dense_4_acc: 0.9250
等我们跑完7个epoch的时候,测试集上的准确率已经达到了90%+:val_dense_1_acc: 0.9800 - val_dense_2_acc: 1.0000 - val_dense_3_acc: 0.9600 - val_dense_4_acc: 0.9800
模型验证
那么,上面这个模型实际的效果到底怎么样呢?我们再抓取50张图片并标记,来验证这个模型:
from keras.models import load_model
import numpy as np
from scipy import misc
from keras.applications.xception import preprocess_input
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
import glob
img_size = (60, 170)
model = load_model('./CaptchaForDianxin_from_python_1.h5')
letter_list = [chr(i) for i in range(48,58)] + [chr(i) for i in range(65,91)]
def data_generator_test(data, n): #样本生成器,节省内存
while True:
batch = np.array([data[n]])
x,y = [],[]
for img in batch:
im = misc.imread(img)
im = im[:, :, :3]
im = misc.imresize(im, img_size)
x.append(im) #读取resize图片,再存进x列表
y_list = []
real_num = img[-8:-4]
for i in real_num:
if ord(i)-ord('A') >= 0:
y_list.append(ord(i)-ord('A')+10)
else:
y_list.append(ord(i)-ord('0'))
y.append(y_list) #把验证码标签添加到y列表,ord(i)-ord('a')把对应字母转化为数字a=0,b=1……z=26
# print('real_1:',img[-8:-4])
x = preprocess_input(np.array(x).astype(float)) #原先是dtype=uint8转成一个纯数字的array
y = np.array(y)
yield x,[y[:,i] for i in range(4)]
def predict2(n):
x,y = next(data_generator_test(test_samples, n))
z = model.predict(x)
z = np.array([i.argmax(axis=1) for i in z]).T
result = z.tolist()
v = []
for i in range(len(result)):
for j in result[i]:
v.append(letter_list[j])
#输出测试结果
str = ''
for i in v:
str += i
real = ''
for i in y:
for j in i:
real += letter_list[j]
return (str,real)
test_samples = glob.glob(r'dianxin_test_sample/*.jpg')
n = 0
n_right = 0
for i in range(len(test_samples)):
n += 1
print('~~~~~~~~~~~~~%d~~~~~~~~~'%(n))
predict,real = predict2(i)
if real == predict:
n_right += 1
else:
print('real:', real)
print('predict:',predict)
image = mpimg.imread(test_samples[i])
plt.axis('off')
plt.imshow(image)
plt.show()
print(n,n_right,n_right/n)
最后的结果,50张图片,正确预测45张,错误预测5张,准确率90%。
7. 增加样本,继续fine tune
按照上述步骤,我们已经得到了一个不错的结果。
那么,如果验证码比较复杂,仅仅靠450张图片训练后,得到的结果不满意,或者我需要更高的精度呢?很简单,我们只要增加样本量,按照上述步骤,继续在新生成的模型上fine tune,就可以了,而且这个模型的训练会很快,也不需要多个epoch,基本2-3个epoch就可以了。
至于如何更加轻松的标记样本,此时我们已经由一个准确率90%的模型,可以用模型预测的结果去请求需要验证码的网址,让网站为你识别你的预测是否准确,并将预测错误的验证码手工标记,获取更多的样本。
参考:
https://www.jianshu.com/p/9d233a45f53b
keras官方文档:https://keras.io