AISTATS2018|密歇根大学提出新型在线boosting算法用于多标签排序(已开源)
Online Boosting Algorithms for Multi-label Ranking
Young Hun Jung, Ambuj Tewari
University of Michigan
http://proceedings.mlr.press/v84/jung18a/jung18a.pdf
这篇文章主要讨论多标签排序。
Boosting是一种比较适合多标签排序的方法,它能够通过多数表决来聚合多个弱学习器的结果,这些结果可以直接当作评分,进而得到标签的排序。
作者们设计了在线boosting算法用于多标签排序,并且证明了损失下界。
该文章的第一个算法从学习器的个数来说是最优的,同时保证得到期望的准确率,但是该算法需要弱学习器的边缘知识。为了避免这个问题,作者们设计了一种不需要这种知识的自适应算法,这样就会更加实用。
实验结果表明,在真实数据集上,本文算法至少跟现有批式boosting算法一样好。
在线boosting跟离线的boosting区别如下

问题描述及符号约定如下

设计思路及框架如下

本文采用的boosting框架如下

算法伪代码如下

针对基学习器,可以定义以下属性,即学习器的边界

在线弱学习条件的相关定义如下

关于损失向量,具有以下特性

势函数的定义如下

进一步,需要进行归一化处理

算法详情如下

下面是对应的算法伪代码

相关定理
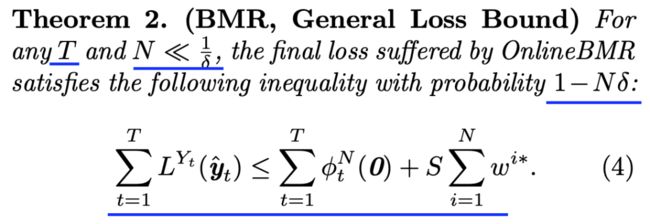
关于损失函数,可以利用hinge loss

下面是一些推论

OnlineBMR具有一定的局限性,比如势函数没有闭解等,作者们提出一种新的自适应选择权重的算法。

新算法所利用的损失函数如下

这种算法所对应的一些细节如下,其中依赖于累积逻辑损失

其中OLMR全称为
Online, Logistic, Multi-label, and Ranking
该算法依赖于在线梯度下降方法

该算法的伪代码如下

排序损失对应的下界为

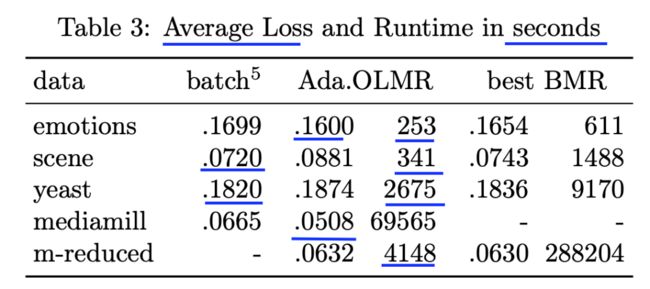
数据集信息统计如下

几种算法效果及运行时间对比如下
代码地址
https://github.com/yhjung88/OnlineMLRBoostingWithVFDT
 我是分割线
我是分割线
您可能感兴趣
KDD2019|基于注意力的深度学习如何实时预测购买还是浏览
AAAI2020|一种新型高效兼容多行为的推荐系统模型EHCF(已开源)
ICML2007|深度学习用于协同过滤的开篇作之一(出自深度学习鼻祖之一Hinton)
SIGIR2019|基于BERT的深度学习模型在信息检索中的应用(已开源)
SIGIR2019|基于注意力机制的新型深度学习模型(采莓树模型BIRD,已开源)
SIGIR2019|深度学习如何更好地用于学习排序(LTR)(已开源)
SIGIR2019|利用DeepSHAP来解释神经检索模型(已开源)
KDD2018|基于GBM的动态定价回归模型
KDD2018|超越deepfm的CTR预估模型深层兴趣网络DIN(已开源)
RecSys2019|优于DeepFM和XDeepFM的CTR模型FiBiNET
SIGIR2018|选择性GBDT(SelGB)用于排序学习(已开源)
IJCAI2019|基于对抗变分自编码的协同过滤框架VAEGAN
聊聊CatBoost
聊聊XGBoost CatBoost LightGBM RF GBDT
顶会中深度学习用于CTR预估的论文及代码集锦 (3)
ICML 2018 深度学习论文及代码集锦(5)
深度学习用于文本摘要的论文及代码集锦
深度学习用于机器翻译的论文及代码集锦
深度学习用于序列标注中的论文及代码集锦
深度学习在推荐系统中的应用及代码集锦(4)
深度学习在OCR中的应用论文及代码集锦 (2)