MFS分布式文件系统的高可用(pacemaker+corosync)+磁盘共享(iscsi)+fence(解决脑裂)
本次部署是基于MFS文件系统环境已经搭建好,具体可参考博文:https://blog.csdn.net/hetoto/article/details/92200785
1.实验环境
rhel 7.3 firewalld is disabled
| 主机名 | IP | 服务 |
|---|---|---|
| server1 | 172.25.12.1 | mfs master corosync+pacemaker |
| server2 | 172.25.12.2 | chunk server |
| server3 | 172.25.12.1 | chunk server |
| server4 | 172.25.12.4 | mfs master corosync+pacemaker |
| 物理机 | 172.25.12.250 | client |
由于MFS自身的Mfslogger本身的的不可靠性,这里的高可用是对于单节点mfs master来进行配置的,mfs master 处理用户的挂载请求,并且分发数据,很容易成为节点的故障所在
一,mfsmaster的高可用
1、配置master,先获取高可用yum源,下载所需软件
[root@server1 ~]# vim /etc/yum.repos.d/rhel7.repo
[rhel7.3]
name=rhel7.3
baseurl=http://172.25.12.250/rhel7.3
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.12.250/rhel7.3/addons/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.12.250/rhel7.3/addons/ResilientStorage
gpgcheck=0
[root@server1 ~]# yum clean all
[root@server1 ~]# yum repolist
下载pacemaker、corosync、pcs服务:
[root@server1 ~]# yum install pacemaker corosync pcs -y
[root@server1 ~]# rpm -q pacemaker
pacemaker-1.1.15-11.el7.x86_64
2、配置免密登陆
[root@server1 ~]# ssh-keygen
[root@server1 ~]# ssh-copy-id server4

 3、启动pcsd服务,设置hacluster用户密码
3、启动pcsd服务,设置hacluster用户密码
[root@server1 ~]# systemctl start pcsd
[root@server1 ~]# systemctl enable pcsd
Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
[root@server1 ~]# passwd hacluster
Changing password for user hacluster.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.

4、配置backup-mfsmaster
[root@server4 ~]# ls
moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
[root@server4 ~]# rpm -ivh moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
warning: moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID cf82adba: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:moosefs-master-3.0.103-1.rhsystem################################# [100%]

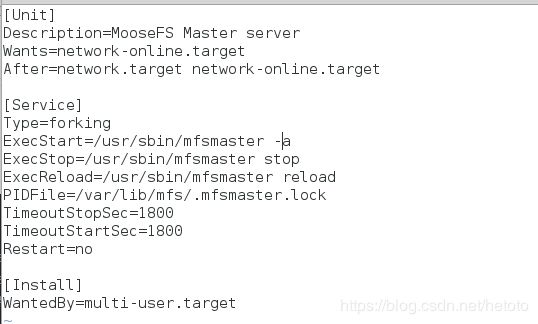
[root@server4 ~]# vim /usr/lib/systemd/system/moosefs-master.service
[Unit]
Description=MooseFS Master server
Wants=network-online.target
After=network.target network-online.target
[Service]
Type=forking
ExecStart=/usr/sbin/mfsmaster -a
ExecStop=/usr/sbin/mfsmaster stop
ExecReload=/usr/sbin/mfsmaster reload
PIDFile=/var/lib/mfs/.mfsmaster.lock
TimeoutStopSec=1800
TimeoutStartSec=1800
Restart=no
[Install]
WantedBy=multi-user.target
[root@server4 ~]# systemctl daemon-reload
配置yum源
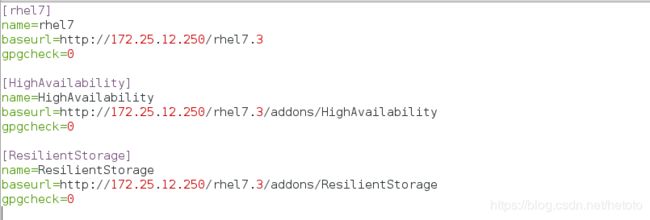
[root@server4 ~]# vim /etc/yum.repos.d/rhel7.repo
[rhel7.3]
name=rhel7.3
baseurl=http://172.25.12.250/rhel7.3
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.12.250/rhel7.3/addons/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.12.250/rhel7.3/addons/ResilientStorage
gpgcheck=0
测试yum源,及下载相关软件
[root@server4 ~]# yum repolist
[root@server4 ~]# yum install -y pacemaker corosync pcs
启动服务,配置hacluster用户密码(主备的密码需要相同)
[root@server4 ~]# systemctl start pcsd
[root@server4 ~]# systemctl enable pcsd
Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
[root@server4 ~]# passwd hacluster
Changing password for user hacluster.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.

5、开始创建集群
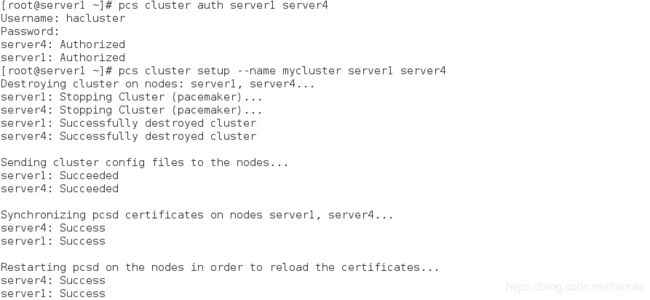
[root@server1 ~]# pcs cluster auth server1 server4
[root@server1 ~]# pcs cluster setup --name mycluster server1 server4
[root@server1 ~]# pcs status nodes
Error: error running crm_mon, is pacemaker running?
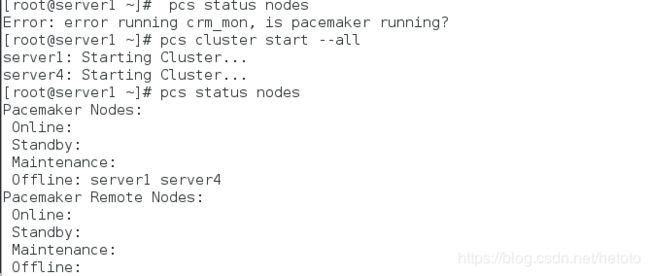
[root@server1 ~]# pcs cluster start --all
[root@server1 ~]# pcs status nodes
Pacemaker Nodes:
Online: server1 server4
Standby:
Maintenance:
Offline:
Pacemaker Remote Nodes:
Online:
Standby:
Maintenance:
Offline:
验证corosync是否正常:
[root@server1 ~]# corosync-cfgtool -s
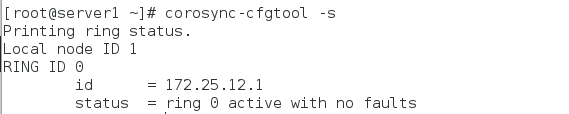
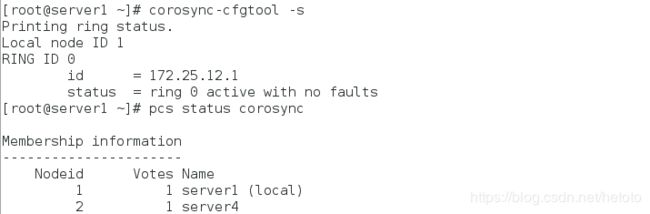
查看corosync的状态:
[root@server1 ~]# pcs status corosync
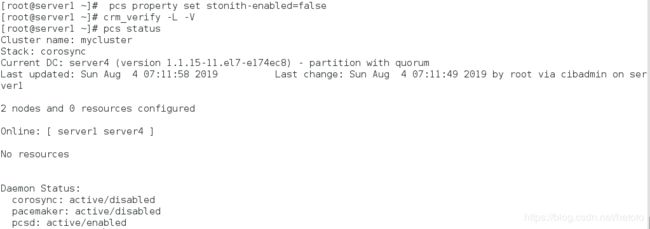
6、创建主备集群
[root@server1 ~]# pcs property set stonith-enabled=false
[root@server1 ~]# crm_verify -L -V
[root@server1 ~]# pcs status
创建vip:
[root@server1 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.12.100 cidr_netmask=32 op monitor interval=30s
[root@server1 ~]# ip a
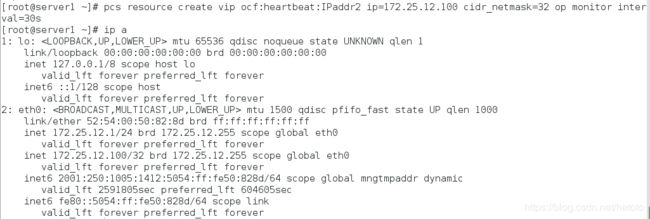
查看监控:
crm_mon
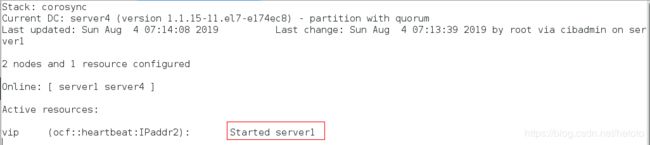
7、执行故障转移
[root@server1 ~]# pcs cluster stop server1
server1: Stopping Cluster (pacemaker)...
server1: Stopping Cluster (corosync)...

在server4查看监控:
crm_mon
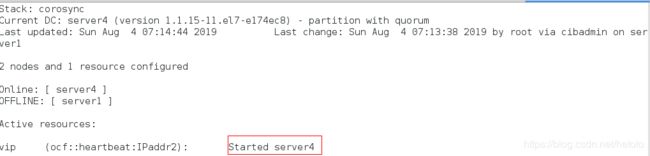
当server1的master重新开启时,服务还是在server4上不会抢占资源:
[root@server1 ~]# pcs cluster start server1
server1: Starting Cluster...
![]()
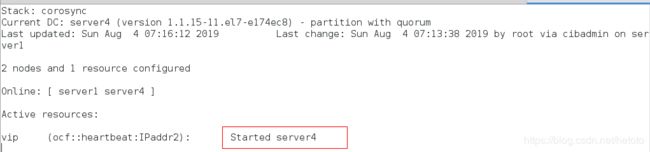
关闭server4,此时vip移到server1:
[root@server4 ~]# pcs cluster stop server4
server4: Stopping Cluster (pacemaker)...
server4: Stopping Cluster (corosync)...
实验实现了mfs的高可用,当master出现故障时,资源会自动转移到master-backup,当master恢复后,资源不会回切,保障了客户端服务的稳定性。
获取可用资源标准列表:
[root@server1 ~]# pcs resource standards
ocf
lsb
service
systemd

查看资源提供者的列表:
[root@server1 ~]# pcs resource providers
heartbeat
openstack
pacemaker

查看特定的可用资源代理:
[root@server1 ~]# pcs resource agents ocf:heartbeat
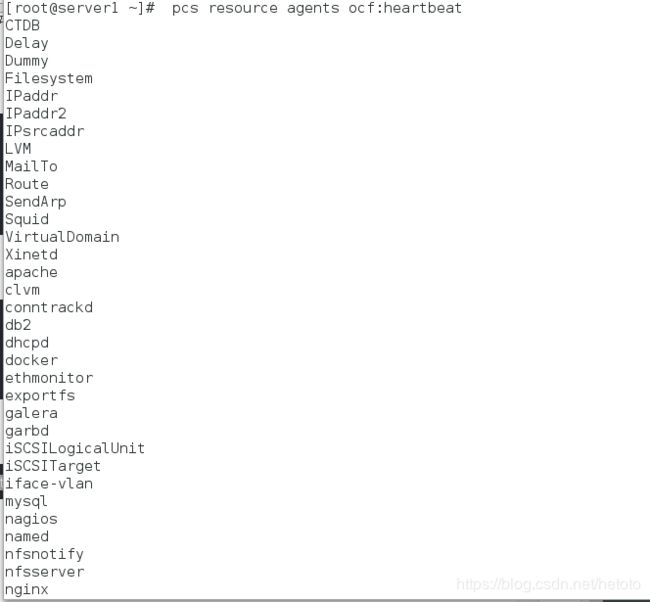
二、存储共享(使用vip的方式实现)
1、关闭服务,卸载目录。
客户端:
[root@foundation1 ~]# umount /mnt/mfs
root@foundation1 ~]# umount /mnt/mfsmeta/
[root@foundation1 ~]# vim /etc/hosts
172.25.12.100 mfsmaster
server1:
[root@server1 ~]# systemctl stop moosefs-master
[root@server1 ~]# vim /etc/hosts
172.25.12.100 mfsmaster
server2:
[root@server2 ~]# systemctl stop moosefs-chunkserver
[root@server2 ~]# vim /etc/hosts
172.25.12.100 mfsmaster
server3:
[root@server3 ~]# systemctl stop moosefs-chunkserver
[root@server3 ~]# vim /etc/hosts
172.25.12.100 mfsmaster
server4:
[root@server4 ~]# systemctl stop moosefs-master
[root@server4 ~]# vim /etc/hosts
172.25.12.100 mfsmaster
2、使用server2为iscsi的服务端,添加一块磁盘
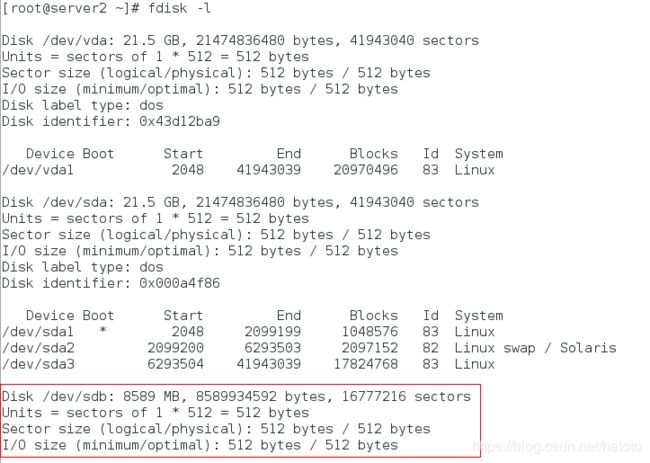
检测硬盘是否添加成功:
[root@server2 ~]# fdisk -l
3、server2下载iscsi软件,及共享磁盘的配置
[root@server2 ~]# yum install -y targetcli #安装远程快存储设备
[root@server2 ~]# systemctl start target #开启服务
[root@server2 ~]# targetcli
Warning: Could not load preferences file /root/.targetcli/prefs.bin.
targetcli shell version 2.1.fb41
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> cd backstores/block
/backstores/block> create my_disk1 /dev/sdb
Created block storage object my_disk1 using /dev/sdb.
/backstores/block> cd ..
/backstores> cd ..
/> cd iscsi
/iscsi> create iqn.2019-05.com.example:server2
Created target iqn.2019-05.com.example:server2.
Created TPG 1.
Global pref auto_add_default_portal=true
Created default portal listening on all IPs (0.0.0.0), port 3260.
/iscsi> cd iqn.2019-05.com.example:server2
/iscsi/iqn.20...ample:server2> cd tpg1/luns
/iscsi/iqn.20...er2/tpg1/luns> create /backstores/block/my_disk1
Created LUN 0.
/iscsi/iqn.20...er2/tpg1/luns> cd ..
/iscsi/iqn.20...:server2/tpg1> cd acls
/iscsi/iqn.20...er2/tpg1/acls> create iqn.2019-05.com.example:client
Created Node ACL for iqn.2019-05.com.example:client
Created mapped LUN 0.
/iscsi/iqn.20...er2/tpg1/acls> cd ..
/iscsi/iqn.20...:server2/tpg1> cd ..
/iscsi/iqn.20...ample:server2> cd ..
/iscsi> cd ..
/> exit
Global pref auto_save_on_exit=true
Last 10 configs saved in /etc/target/backup.
Configuration saved to /etc/target/saveconfig.json
 4、在iscsi的客户端:server1上安装iscsi客户端软件,对共享磁盘进行分区使用
4、在iscsi的客户端:server1上安装iscsi客户端软件,对共享磁盘进行分区使用
[root@server1 ~]# yum install -y iscsi-*
[root@server1 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-05.com.example:client
[root@server1 ~]# iscsiadm -m discovery -t st -p 172.25.12.2
172.25.12.2:3260,1 iqn.2019-05.com.example:server2
[root@server1 ~]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2019-05.com.example:server2, portal: 172.25.12.2,3260] (multiple)
Login to [iface: default, target: iqn.2019-05.com.example:server2, portal: 172.25.12.2,3260] successful.

![]() [root@server1 ~]#
[root@server1 ~]# fdisk -l ##查看远程共享出来的磁盘
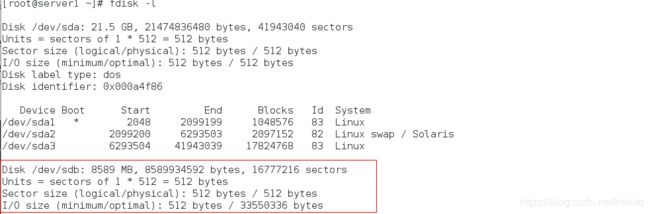
[root@server1 ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x1c160cb8.
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1): 1
First sector (65528-16777215, default 65528):
Using default value 65528
Last sector, +sectors or +size{K,M,G} (65528-16777215, default 16777215):
Using default value 16777215
Partition 1 of type Linux and of size 8 GiB is set
Command (m for help): p
Disk /dev/sdb: 8589 MB, 8589934592 bytes, 16777216 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 33550336 bytes
Disk label type: dos
Disk identifier: 0x1c160cb8
Device Boot Start End Blocks Id System
/dev/sdb1 65528 16777215 8355844 83 Linux
Command (m for help): wq
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
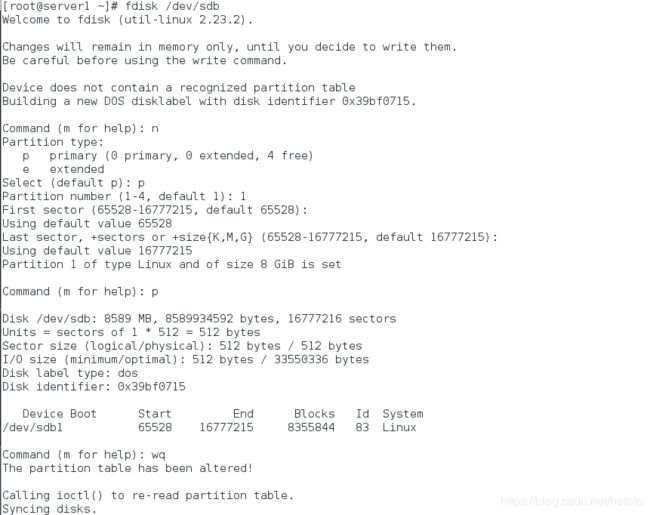
5、格式化分区及使用
[root@server1 ~]# mkfs.xfs /dev/sdb1 #格式化分区
[root@server1 ~]# dd if=/dev/zero of=/dev/sdb bs=512 count=1 #破坏分区
[root@server1 ~]# fdisk -l /dev/sdb #查看不到分区
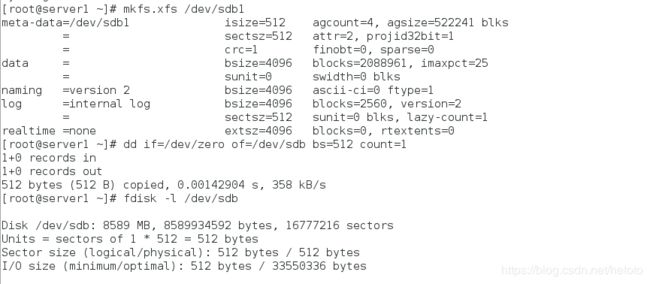
因为截取速度太快,导致分区被自动删除,因为把/dev/sda下的所有空间都分给了/dev/sda1,只需要重新建立分区即可。
[root@server1 ~]# mount /dev/sdb1 /mnt # 查看到分区不存在
mount: special device /dev/sdb1 does not exist
[root@server1 ~]# fdisk /dev/sdb
Command (m for help): n
Select (default p): p
Partition number (1-4, default 1):
First sector (65528-16777215, default 65528):
Using default value 65528
Last sector, +sectors or +size{K,M,G} (65528-16777215, default 16777215):
Device Boot Start End Blocks Id System
/dev/sdb1 65528 16777215 8355844 83 Linux
Command (m for help): wq
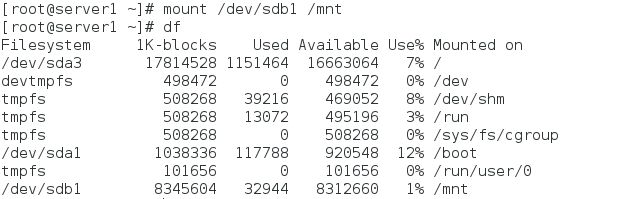
[root@server1 ~]# mount /dev/sdb1 /mnt
[root@server1 ~]# df
[root@server1 ~]# cd /var/lib/mfs/ # 这是mfs的数据目录
[root@server1 mfs]# ls
changelog.1.mfs changelog.5.mfs metadata.mfs metadata.mfs.empty
changelog.4.mfs metadata.crc metadata.mfs.back.1 stats.mfs
[root@server1 mfs]# cp -p * /mnt # 带权限拷贝/var/lib/mfs的所有数据文件到/dev/sdb1上
[root@server1 mfs]# cd /mnt
[root@server1 mnt]# ll
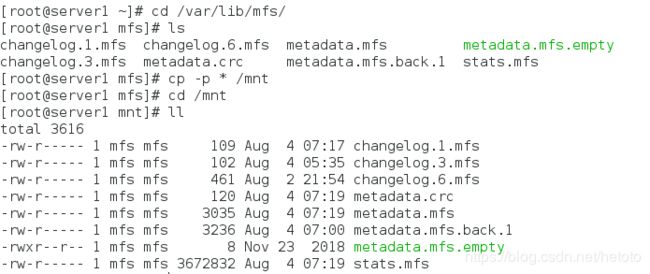
[root@server1 mnt]# chown mfs.mfs /mnt # 当目录属于mfs用户和组时,才能正常使用
[root@server1 mnt]# ll -d /mnt
drwxr-xr-x 2 mfs mfs 185 May 18 20:55 /mnt
[root@server1 mnt]# cd
[root@server1 ~]# umount /mnt
[root@server1 ~]# mount /dev/sdb1 /var/lib/mfs/ # 使用分区,测试是否可以使用共享磁盘
[root@server1 ~]# df
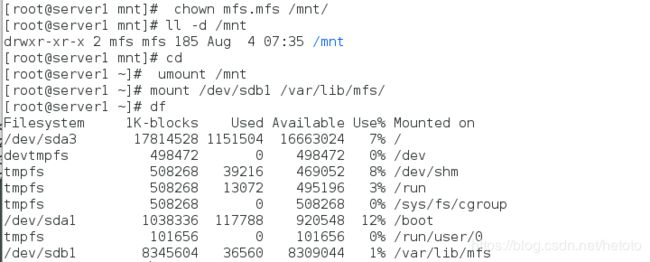
[root@server1 ~]# systemctl start moosefs-master # 服务开启成功,就说明数据文件拷贝成功,共享磁盘可以正常使用
[root@server1 ~]# ps ax
![]()
测试成功后关闭服务:
[root@server1 ~]# systemctl stop moosefs-master
6、配置backup-master,是之也可以使用共享磁盘
[root@server4 ~]# vim /etc/hosts
172.25.12.1 server1 mfsmaster
[root@server4 ~]# yum install -y iscsi-*
[root@server4 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-05.com.example:client
[root@server4 ~]# iscsiadm -m discovery -t st -p 172.25.12.2
172.25.12.2:3260,1 iqn.2019-05.com.example:server2
[root@server4 ~]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2019-05.com.example:server2, portal: 172.25.12.2,3260] (multiple)
Login to [iface: default, target: iqn.2019-05.com.example:server2, portal: 172.25.12.2,3260] successful.

[root@server4 ~]# fdisk -l
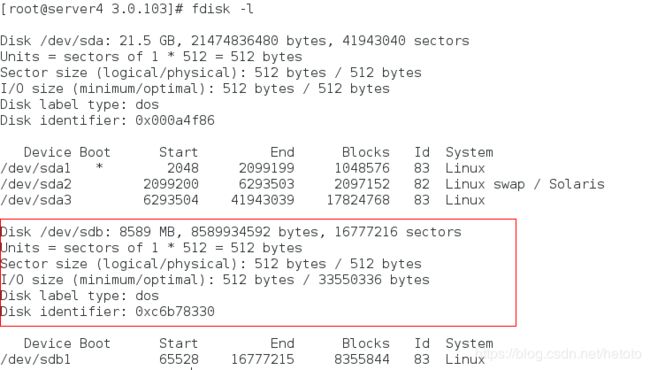
[root@server4 ~]# mount /dev/sdb1 /var/lib/mfs/
[root@server4 ~]# systemctl start moosefs-master
[root@server4 ~]# systemctl stop moosefs-master
[root@server4 ~]# pcs cluster start server4
server4: Starting Cluster...

7、在master上创建mfs文件系统
[root@server1 ~]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/var/lib/mfs fstype=xfs op monitor interval=30s
[root@server1 ~]# pcs resource show
vip (ocf::heartbeat:IPaddr2): Started server4
mfsdata (ocf::heartbeat:Filesystem): Started server1
![]()
crm_mon
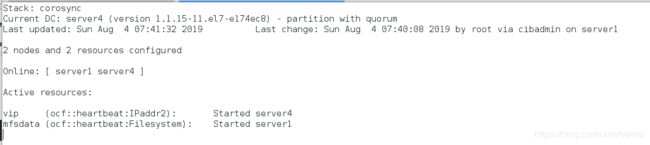
vip和mfsdata在不同主机。
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min
创建mfsd系统
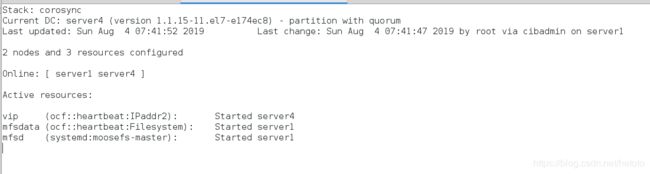
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd # 把vip,mfsdata,mfsd 集中在一个组中
[root@server1 ~]# pcs cluster stop server1 # 当关闭master之后,master上的服务就会迁移到backup-master上
server1: Stopping Cluster (pacemaker)...
server1: Stopping Cluster (corosync)...

在server4上查:
crm_mon
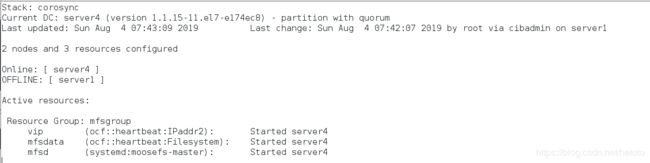
三、fence解决脑裂问题
(1)先在客户端测试高可用
先在客户端测试高可用
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server2 ~]# ping mfsmaster # 保证解析可以通信
[root@server3 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# ping mfsmaster # 保证解析可以通信
查看vip的位置
[root@server4 ~]# ip a
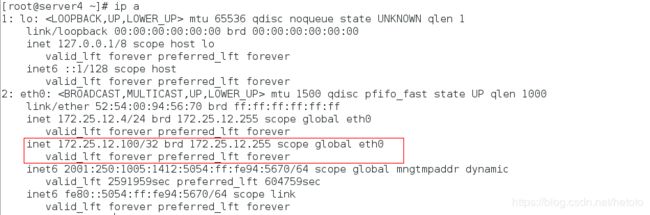
开启master
[root@server1 ~]# pcs cluster start server1
server1: Starting Cluster...
![]()
在客户端进行分布式存储测试
[root@foundation1 ~]# cd /mnt/mfs/
[root@foundation1 mfs]# ls
[root@foundation1 mfs]# mfsmount #有可能挂载失败,是因为这个目录不为空
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@foundation1 mfs]# mkdir dir{1..2}
[root@foundation1 mfs]# ls
dir1 dir2
[root@foundation1 mfs]# cd /mnt/mfs/dir1/
[root@foundation1 dir1]# dd if=/dev/zero of=file2 bs=1M count=2000 # 我们上传一份大文件
2000+0 records in
2000+0 records out
2097152000 bytes (2.1 GB) copied, 10.9616 s, 191 MB/s
[root@server4 ~]# pcs cluster stop server4 # 在客户端上传大文件的同时,关闭正在提供服务的服务端
server4: Stopping Cluster (pacemaker)...
server4: Stopping Cluster (corosync)...

[root@foundation1 dir1]# mfsfileinfo file2 # 我们查看到文件上传成功,并没有受到影响
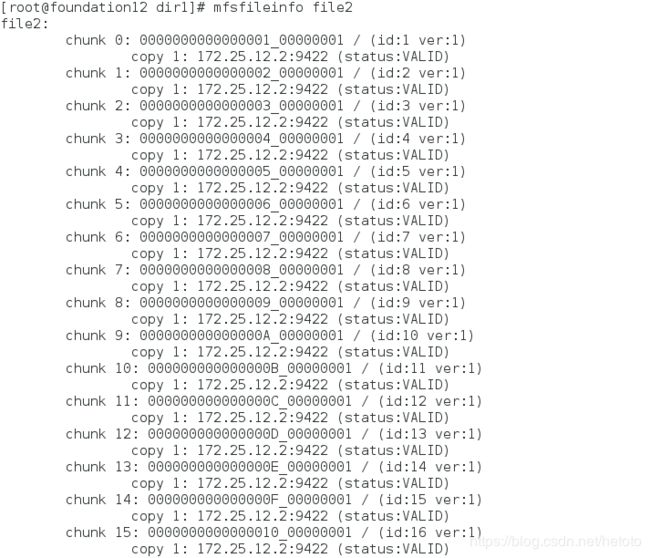
当master挂掉之后,backup-master会立刻接替master的工作,保证客户端可以进行正常访问,但是,当master重新运行时,master可能会抢回自己的工作,从而导致master和backup-master同时修改同一份数据文件从而发生脑裂,此时使用fence。
(2)安装fence服务
[root@server1 ~]# yum install fence-virt -y
[root@server1 ~]# mkdir /etc/cluster
[root@server4 ~]# yum install fence-virt -y
[root@server4 ~]# mkdir /etc/cluster
(3)生成一份fence密钥文件,传给服务端
[root@foundation1 ~]# yum install -y fence-virtd
[root@foundation1 ~]# yum install fence-virtd-libvirt -y
[root@foundation1 ~]# yum install fence-virtd-multicast -y
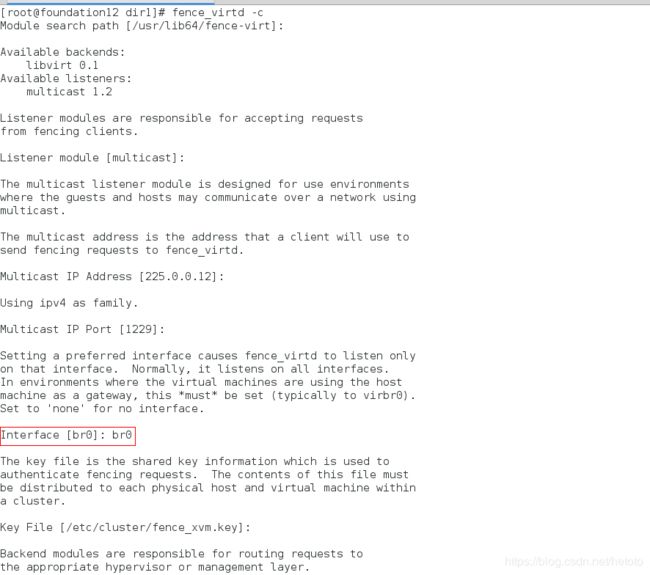
[root@foundation1 ~]# fence_virtd -c
Listener module [multicast]:
Multicast IP Address [225.0.0.12]:
Multicast IP Port [1229]:
Interface [br0]: br0
Key File [/etc/cluster/fence_xvm.key]:
Backend module [libvirt]:

![]()
[root@foundation1 ~]# mkdir /etc/cluster # 这是存放密钥的文件,需要自己手动建立
[root@foundation1 ~]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
[root@foundation1 ~]# systemctl start fence_virtd
[root@foundation1 ~]# cd /etc/cluster/
[root@foundation1 cluster]# ls
fence_xvm.key
[root@foundation1 cluster]# scp fence_xvm.key [email protected]:/etc/cluster/
[root@foundation1 cluster]# scp fence_xvm.key [email protected]:/etc/cluster/
查看域名
[root@foundation1 cluster]# virsh list 查看域名

查看是否匹配域名。
在master查看监控crm_mon
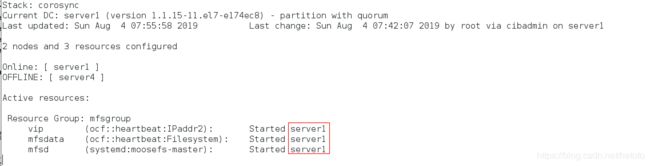
这是主机名。与主机所对应的域名一致。
[root@server1 ~]# cd /etc/cluster/
[root@server1 cluster]# pcs stonith create vmfence fence_xvm pcmk_host_map=":server1;server4:server4" op monitor interval=1min
[root@server1 cluster]# pcs property set stonith-enabled=true
[root@server1 cluster]# crm_verify -L -V
[root@server1 cluster]# fence_xvm -H server4 # 使server4断电重启
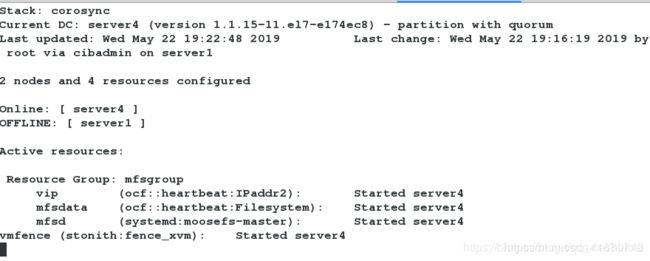
[root@server1 cluster]# crm_mon # 查看监控,server4上的服务迁移到master的server1上
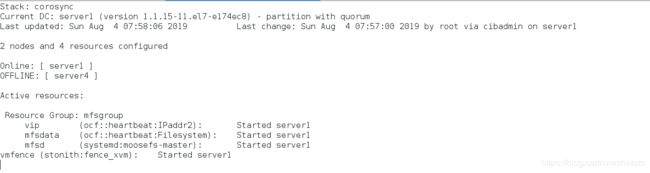
[root@server1 cluster]# echo c > /proc/sysrq-trigger # 模拟master端内核崩溃![在这里插入图片描述]
查看监控,server4会立刻接管master的所有服务
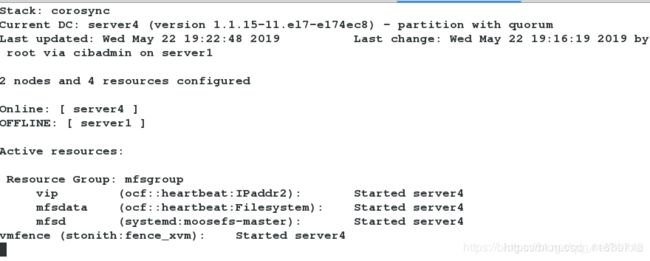
server1重启成功后,不会抢占资源,不会出现脑裂的状况。
查看监控发现,master重启成功之后,并不会抢占资源,服务依旧在backup-master端正常运行,说明fence生效。