springDataJpa入门教程(1)-基于springBoot的基本增删改查
springDataJpa入门教程
-
springDataJpa入门教程(1)-基于springBoot的基本增删改查
-
springDataJpa入门教程(2)-Specification动态条件查询+排序+分页
-
springDataJpa入门教程(3-1)-基于EntityManager原生sql多表联合查询+动态条件查询+分页
-
springDataJpa入门教程(3-2)-基于EntityManager原生sql多表联合查询+动态条件查询+分页返回自定义实体类对象
-
springDataJpa入门教程(4)-Example单表动态条件查询+分页
-
springDataJpa入门教程(5)-单表动态条件查询+分页
-
springDataJpa入门教程(6)-多表动态条件查询+分页
-
springDataJpa入门教程(7)-基于springDataJpa投影(Projection)返回自定义实体类对象
-
springDataJpa入门教程(8)-JPA EnableJpaAuditing 审计功能
-
springDataJpa入门教程(9)-spring jpa实体属性类型转换器AttributeConverter的用法
-
springDataJpa入门教程(10)-JPA使用过程中遇到的坑及解决方法
springDataJpa入门教程(1)-基于springBoot的基本增删改查
由于公司项目的原因开始接触springDataJpa,这个框架给开发带来了很多方便,比如说一些简单的查询不需要写sql语句就能完成,这一点上比hibernate更有吸引力,基于注解开发,相比于hibernate,除了配置下数据库连接池,几乎不需要写什么配置(个人看法),还可以实现自动建表,可以大大提高开发效率。工作中的学习比较零散,闲下来了决定对springDataJpa的学习做一个梳理。由于本人水平有限,教程中难免出现错误,敬请谅解,欢迎大家批评指正。源码地址:源码下载地址。java学习交流群:184998348,欢迎大家一起交流学习。
本教程是基于jdk1.8+springboot+springDataJpa+mysql5.6来介绍springDataJpa的使用。下面分别从Spring Data JPA简介、框架搭建、简单的增删改查操作来介绍springDataJpa的使用。
开发工具为idea+maven+lombok插件(这个插件可以自动为实体类生成setter、getter、toString以及构造方法,需要在idea中安装lombok插件,lombok插件安装教程)
1.Spring Data JPA简介
它是Spring基于ORM框架、JPA规范封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展。学习并使用Spring Data JPA可以极大提高开发效率。简单来说Spring Data JPA是一个持久层框架,可以简化对数据库的操作。
SpringData JPA只是SpringData中的一个子模块,JPA是一套标准接口,而Hibernate是JPA的实现,SpringData JPA 底层默认实现是使用Hibernate。
2.springboot+springDataJpa框架搭建
- 新建springboot项目
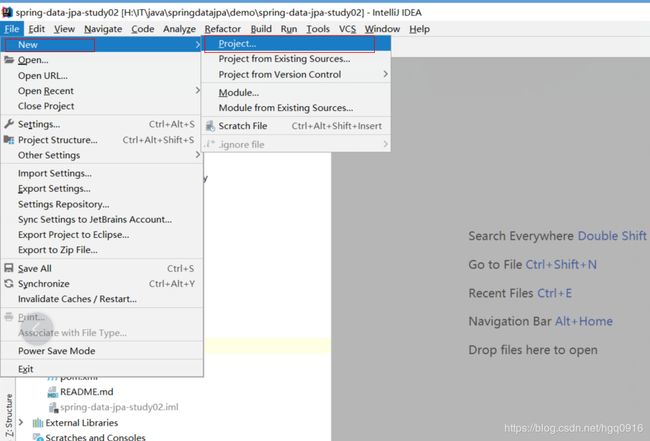
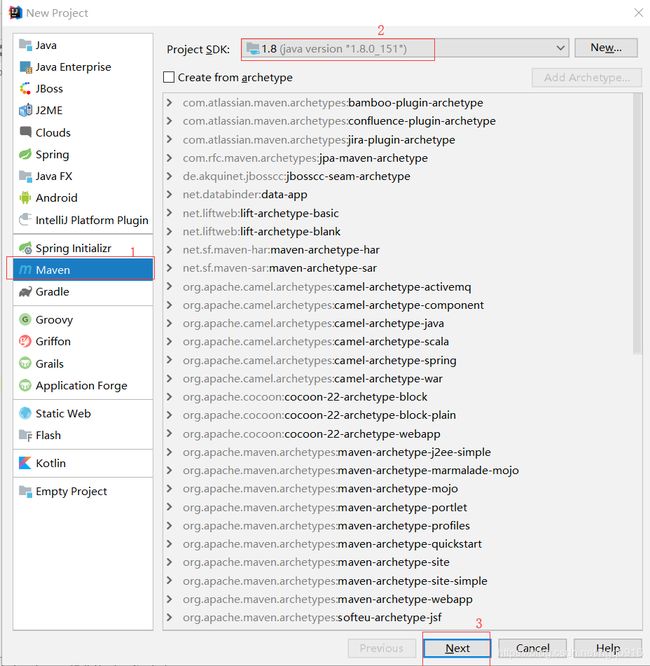
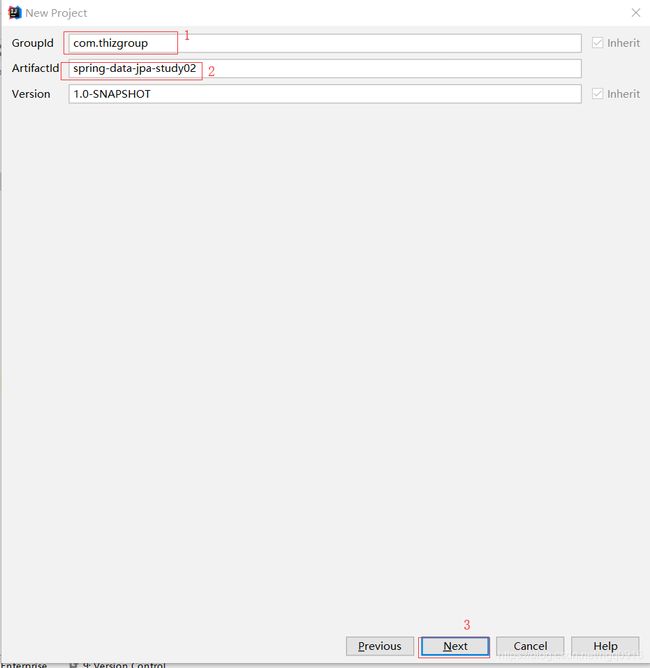
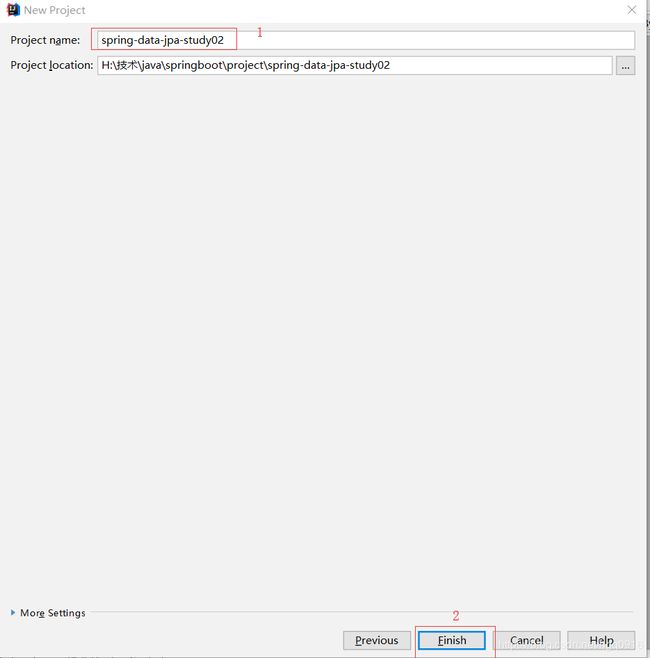
- 引入springboot及springdatajpa pom依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.thizgroupgroupId>
<artifactId>spring-data-jpa-study02artifactId>
<version>1.0-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.4.RELEASEversion>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.junit.jupitergroupId>
<artifactId>junit-jupiter-engineartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.0version>
dependency>
dependencies>
project>
- 创建application.yml文件,并添加配置
在resource目录下创建application.yml
application.yml配置如下:
#数据库配置
spring:
datasource:
url: jdbc:mysql://localhost:3306/jpa_test?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
#注意:mysql的版本如果是5.5及以下,driver-class-name应该是com.mysql.jdbc.Driver
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
jpa:
hibernate:
#自动建表策略
ddl-auto: update
#打印sql语句
show-sql: true
properties:
hibernate:
#hibernate方言
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
server:
port: 2000
- 创建springboot启动类
在java目录下创建项目包结构,如下:
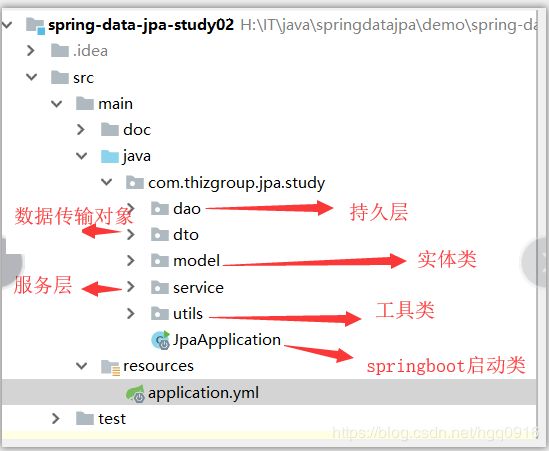
下面来看下springboot启动类JpaApplication的内容:
package com.thizgroup.jpa.study;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@SpringBootApplication
//配置springDataJpa扫描Repository的包路径
@EnableJpaRepositories("com.thizgroup.jpa.study.dao")
public class JpaApplication {
public static void main(String[] args) {
SpringApplication.run(JpaApplication.class,args);
}
}
至此,框架搭建完成了。要想项目跑起来,需要创建一个数据库,我这里数据库的名称是jpa_test。
3.创建实体类及包结构
在model目录下创建User类和Address类,
代码如下:
- User类
package com.thizgroup.jpa.study.model;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Entity
//这里User类对应的表是tb_user
@Table(name = "tb_user")
@Data//使用lombok生成getter、setter
@NoArgsConstructor//使用lombok生成无参构造方法
public class User {
@Id
//指定id生成策略为自增
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
//定义属性名对应的数据库表字段名称
@Column(name = "name",columnDefinition = "varchar(64)")
private String name;
@Column(name = "mobile",columnDefinition = "varchar(64)")
private String mobile;
@Column(name = "email",columnDefinition = "varchar(64)")
private String email;
@Column(name = "age",columnDefinition = "smallint(64)")
private Integer age;
@Column(name = "birthday",columnDefinition = "timestamp")
private Date birthday;
//地址
@Column(name = "address_id",columnDefinition = "bigint(20)")
private Long addressId;
@Column(name = "create_date",columnDefinition = "timestamp")
private Date createDate;
@Column(name = "modify_date",columnDefinition = "timestamp")
private Date modifyDate;
@Builder(toBuilder = true)//Builder注解可以实现链式编写,后面会用过
public User(Long id,String name, String mobile, String email, Integer age, Date birthday,
Long addressId) {
this.id = id;
this.name = name;
this.mobile = mobile;
this.email = email;
this.age = age;
this.birthday = birthday;
this.addressId = addressId;
}
}
- Address类
package com.thizgroup.jpa.study.model;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.Data;
@Entity
@Table(name="tb_address")
@Data//使用lombok生成getter、setter
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "country",columnDefinition = "varchar(64)")
private String country;
@Column(name = "province",columnDefinition = "varchar(64)")
private String province;
@Column(name = "city",columnDefinition = "varchar(64)")
private String city;
}
这两个实体类建好后,重新启动项目,springDatajpa会自动建表,建好的表如下:
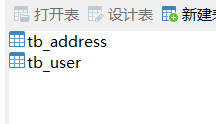
往数据库表插入几条数据,用于后面查询操作。
sql脚本如下:
-- ----------------------------
-- Records of tb_user
-- ----------------------------
BEGIN;
INSERT INTO `tb_user` (`id`, `name`, `age`, `birthday`, `email`, `mobile`, `address_id`, `create_date`, `modify_date`) VALUES (1, '张三', 35, '2008-09-16 00:00:00', '[email protected]', '156989989', 11, '2019-08-05 21:50:01', '2019-08-07 21:46:11'), (2, '狄仁杰', 50, '1988-09-16 00:00:00', '[email protected]', '158789989', 22, '2019-07-05 21:50:01', '2019-08-05 22:20:48'), (3, '诸葛亮', 54, '2001-09-16 00:00:00', '[email protected]', '158989989', 22, '2019-09-05 21:50:01', '2019-08-07 21:46:17');
COMMIT;
-- ----------------------------
-- Records of tb_address
-- ----------------------------
BEGIN;
INSERT INTO `tb_address` (`id`, `city`, `country`, `province`) VALUES (11, '上海', '中国', '上海'), (22, '武汉', '中国', '湖北'), (33, '信阳', '中国', '河南');
COMMIT;
4.简单查询操作
4.1先来个简单的查询:根据用户id查询用户信息
- 在dao目录下创建一个UserRepository接口
让UserRepository继承 JpaRepository和JpaSpecificationExecutor接口,继承这两个接口的原因是这两个接口为我们提供一些通用的增删改查操作,不需要我们再手动编写。
代码如下:
package com.thizgroup.jpa.study.dao;
import com.thizgroup.jpa.study.model.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
public interface UserRepository extends JpaRepository<User,Long>, JpaSpecificationExecutor<User> {
}
至此,这个接口就创建好了,我们就可以使用这个接口进行一些简单的查询操作了。你可能会惊讶,我们并没有创建实现类,只是创建一个接口就可以进行查询操作,没错,JPA就是这么神奇(其实背后的原理就是动态代理,JPA为我们生成了实现类,我们无需关心)。
2.在service包下创建IUserService接口,并创建UserServiceImpl实现类,UserServiceImpl实现IUserService接口。
IUserService代码如下:
package com.thizgroup.jpa.study.service;
import com.thizgroup.jpa.study.dto.PageRecord;
import com.thizgroup.jpa.study.dto.UserDTO;
import com.thizgroup.jpa.study.dto.UserProjection;
import com.thizgroup.jpa.study.model.User;
import java.util.List;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
/**
* 用户服务
*/
public interface IUserService {
/**
* 根据id查询用户
* @param id
* @return
*/
User findById(Long id);
}
UserServiceImpl类的代码如下:
package com.thizgroup.jpa.study.service.impl;
import com.thizgroup.jpa.study.dao.UserRepository;
import com.thizgroup.jpa.study.model.User;
import com.thizgroup.jpa.study.service.IUserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service
@Transactional(readOnly = false,propagation = Propagation.REQUIRED)
public class UserServiceImpl implements IUserService {
@Autowired
private UserRepository userRepository;
@Override
public User findById(Long id) {
Optional<User> userOptional = userRepository.findById(id);
User user = userOptional.orElseGet(() -> null);
return user;
}
}
至此,根据id查询用户信息的方法就创建好了。
下面,我们来创建一个单元测试类,来验证这个方法的正确性。
在test目录下创建一个包名为com.thizgroup.jpa.study.service的package,
在com.thizgroup.jpa.study.service目录下创建一个名为UserServiceImplTest的单元测试类,
UserServiceImplTest类的代码如下:
package com.thizgroup.jpa.study.service;
import com.thizgroup.jpa.study.JpaApplication;
import com.thizgroup.jpa.study.model.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@SpringBootTest(classes={JpaApplication.class})
@RunWith(SpringJUnit4ClassRunner.class)
@Transactional(readOnly = false,propagation = Propagation.REQUIRED)
public class UserServiceImplTest {
@Autowired
private IUserService userService;
@Test
public void findByIdTest(){
User user = userService.findById(1L);
System.out.println(user);
}
}
单元测试类创建好后,执行单元测试,

可以看到输入结果:
User(id=1, name=张三, mobile=156989989, [email protected], age=35, birthday=2008-09-16 08:00:00.0, addressId=11, createDate=2019-08-06 05:50:01.0, modifyDate=2019-08-08 05:46:11.0)
好了,一个简单的查询就搞定了。
4.2 根据用户名查询用户信息
- 在UserRepository接口中创建一个查询用户信息的方法,如下:
package com.thizgroup.jpa.study.dao;
import com.thizgroup.jpa.study.model.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
public interface UserRepository extends JpaRepository<User,Long>, JpaSpecificationExecutor<User> {
/**
* 根据用户名查询用户信息
* @param name
* @return
*/
User findTopByName(String name);
}
这样,根据用户名查询用户信息的方法就写好了。可以看到,我们并没有书写sql语句,那么JPA是怎么实现查询的呢?原因是JPA会根据方法名为我们自动生成sql语句,生成的sql语句(查询的字段我用星号(*)代替)如下:
select * from tb_user where name=? limit ?
我们来分析这个sql语句是怎么生成的,
首先,findTopByName中的find开头表示这是一个查询操作,Top的意思是只返回结果集的第一条记录,与Top1等价,Top2就是返回结果集的前两条记录,依次类推。Top对应的sql就是“limit ?”,这个问号的值JPA会为我们填入1,也就是"limit 1",By后面跟着查询条件,表示按照哪些查询条件查询,By相当于sql语句中的"where",Name对应sql语句中的"name=?"。
2.在IUserService接口中添加一个方法,
/**
* 根据用户名查询用户信息
* @param name
* @return
*/
User findUserByName(String name);
然后UserServiceImpl类实现这个方法,
@Override
public User findUserByName(String name) {
return userRepository.findTopByName(name);
}
3.在单元测试类UserServiceImplTest中添加一个方法,如下:
@Test
public void findUserByNameTest(){
User user = userService.findUserByName("狄仁杰");
System.out.println(user);
}
执行单元测试,可以看到查询结果:
User(id=2, name=狄仁杰, mobile=158789989, email=di@qq.com, age=50, birthday=1988-09-16 08:00:00.0, addressId=22, createDate=2019-07-06 05:50:01.0, modifyDate=2019-08-06 06:20:48.0)
上面的方法之所以不用书写sql语句,因为这个方法命名遵循了SpringData方法定义规范,下面来简单讲下SpringData方法定义规范。
4.3 SpringData方法定义规范
通过上面的findUserByName的案例,我们了解到在使用SpringData时只需要定义Dao层接口及定义方法就可以操作数据库。但是,这个Dao层接口中的方法也是有定义规范的,只有按这个规范来,SpringData才能识别并实现该方法。下面来说说方法定义的规范。
(1)简单的条件查询的方法定义规范
方法定义规范如下:
- 简单条件查询:查询某一个实体或者集合
- 按照SpringData规范,查询方法于find|read|get开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:属性首字母需要大写。
- 支持属性的级联查询;若当前类有符合条件的属性, 则优先使用, 而不使用级联属性。 若需要使用级联属性, 则属性之间使用 _ 进行连接。
下面来看个案例吧,操作的实体依旧是上面的User,下面写个通过AddressId和age查询出User列表的案例。
在UserRepository这个接口中,定义一个通过AddressId和age查询的方法。
/**
* 使用jpql语句查询,jpa根据方法名生成sql语句
* @param addressId
* @param age
* @return
*/
//相当于sql语句:
// select * from tb_user where address_id = ? and age = ?
List<User> findByAddressIdAndAge(Long addressId, int age);
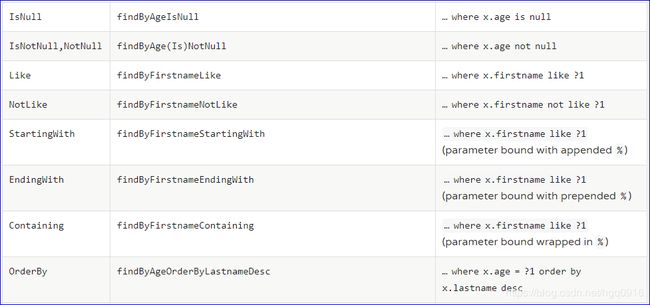
(2)支持的关键字
直接在接口中定义方法,如果符合规范,则不用写实现。目前支持的关键字写法如下:

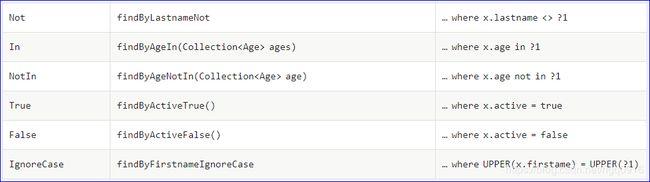
下面直接展示个案例来介绍下这些方法吧,UserRepository接口新增代码如下:
//1.LessThan用法
// where id < ? or birthday < ?
List<User> findByIdIsLessThanOrBirthdayLessThan(Long id, Date birthday);
//2.like的用法
// where email like ?
List<User> findByEmailLike(String email);
// 3.count查询
//select count(id) from tb_user where email like ?
long countByEmailLike(String email);
(3)查询方法解析流程
通过以上的学习,掌握了在接口中定义方法的规则,我们就可以定义出很多不用写实现的方法了。这里再介绍下查询方法的解析的流程吧,掌握了这个流程,对于定义方法有更深的理解。
3.1)方法参数不带特殊参数的查询
假如创建如下的查询:findByUserDepUuid(),框架在解析该方法时,流程如下:
首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc
- 先判断 userDepUuid(根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续往下走
- 从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复这一步,继续从右往左截取;最后假设 user 为查询实体的一个属性
- 接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 “Doc.user.depUuid” 的取值进行查询;否则继续按照步骤3的规则从右往左截取,最终表示根据 “Doc.user.dep.uuid” 的值进行查询。
可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在级联的属性之间加上 “_” 以显式表达意图,比如 “findByUser_DepUuid()” 或者 “findByUserDep_uuid()”。
方法参数带特殊参数的查询
特殊的参数: 还可以直接在方法的参数上加入分页或排序的参数,比如:
Page<UserModel> findByName(String name, Pageable pageable);
List<UserModel> findByName(String name, Sort sort);
4.4 使用@Query注解查询-自定义JPQL语句
(1)使用Query结合jpql语句实现自定义查询
在UserRepository接口中声明方法,放上面加上Query注解,注解里面写jpql语句,代码如下:
/**
* 根据城市名称和年龄范围查询用户列表
* @param city
* @param age
* @return
*/
//select u.* from tb_user u left join tb_address a on u.address_id=a.id
//where a.city=? and u.age=?
@Query("from User u left join Address a on u.addressId=a.id "
+ " where a.city=?1 and u.age<=?2 ")
List<User> findUserByCityAndAge(String city,String age);
上面的@Query注解中书写的sql语句是JPQL语句,和hibernate的hql很相似,JPA会把上述语句转换为数据库查询需要的sql,比如User会被转换为tb_user,u.addressId会被转换为u.address_id。?1表示第一个参数city,?2表示第二个参数age。因此,上面jpql语句会被解析如下:
//这里用u.*代替User的所有字段
select u.* from tb_user u left join tb_address a
on u.address_id=a.id where a.city=? and u.age<=?
我们来创建一个单元测试验证上述查询,service层没什么代码,故此省略。
@Test
public void findUserByCityAndAgeTest(){
List<User> userList = userService.findUserByCityAndAge("武汉", 50);
if(userList!=null){
userList.forEach(u->System.out.println(u));
}
}
查询结果如下:
User(id=2, name=狄仁杰, mobile=158789989, [email protected], age=50, birthday=1988-09-16 08:00:00.0, addressId=22, createDate=2019-07-06 05:50:01.0, modifyDate=2019-08-06 06:20:48.0)
(2)索引参数和命名参数
在写jpql语句时,查询条件的参数的表示有以下2种方式:
- 索引参数方式如下图所示,索引值从1开始,查询中’?x’的个数要和方法的参数个数一致,且顺序也要一致;
@Query("from User u left join Address a on u.addressId=a.id "
+ " where a.city=?1 and u.age<=?2 ")
List<User> findUserByCityAndAge(String city,String age);
- 命名参数方式(推荐使用这种方式)如下图所示,可以用’:参数名’的形式,在方法参数中使用@Param(“参数名”)注解,这样就可以不用按顺序来定义形参;
@Query("from User u left join Address a on u.addressId=a.id "
+ " where a.city=:city and u.age<=:age ")
List<User> findUserByCityAndAge(@Param("city") String city,
@Param("age") int age);
说一个特殊情况,那就是自定义的Query查询中jpql语句有like查询时,可以直接把%号写在参数的前后,这样传参数就不用把%号拼接进去了。使用案例如下,调用该方法时传递的参数直接传就ok。
@Query("from User where name like %:name%")
List<User> findUserByNameLike(@Param("name") String name);
4.5 使用@Query注解查询-自定义原生sql语句
使用@Query注解书写JPQL语句虽然很方便,但是有的时候无法满足复杂查询的要求,这个时候,我们需要手动书写原生sql语句来实现。示例如下,在@Query注解上只要加上nativeQuery = true就可以实现原生sql查询。
/**
* jpa原生sql查询返回实体类对象
* @param loginName 登录名
* @return
*/
@Query(nativeQuery = true,value = "select * from tb_user"
+" where (email =:loginName or name = :loginName) ")
User findUserByLoginName(@Param("loginName") String loginName);
5.新增数据操作
接下来讲讲怎么使用JPA往数据库插入数据库,插入数据很简单,JPA为我们提供了save和saveAndFlush方法来保存数据。当然这两个方法还可以做数据更新。示例如下:
首先,我们在IUserService接口中添加一个插入用户数据的方法,
/**
* 添加用户
* @param userDTO
* @return
*/
User addUser(UserDTO userDTO);
这里用到了UserDTO 对象,UserDTO 类的代码如下:
package com.thizgroup.jpa.study.dto;
import java.util.Date;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data//使用lombok生成getter、setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class UserDTO {
private Long id;
private String name;
private Integer age;
private String mobile;
private String email;
private Date birthday;
private AddressDTO addressDTO;
private Date createDate;
private Date modifyDate;
private Date startTime;
private Date endTime;
}
还有AddressDTO 对象,AddressDTO 类的代码如下:
package com.thizgroup.jpa.study.dto;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data//使用lombok生成getter、setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class AddressDTO {
private Long id;
private String country;
private String province;
private String city;
}
创建完成后的包结构如下:
然后在UserServiceImpl类中实现addUser方法,
@Override
public User addUser(UserDTO userDTO) {
userDTO.setId(null);
User user = convertDtoToEntity(userDTO);
user.setCreateDate(new Date());
user.setModifyDate(new Date());
//保存后JPA会把id设置到user对象中返回
User savedUser = userRepository.save(user);
return savedUser;
}
单元测试代码如下:
@Test
@Rollback(value = false)//默认情况下单元测试会回滚操作,
//要想在数据库看到添加的数据库,则需要使用@Rollback(value = false)注解
public void addUserTest(){
UserDTO userDTO = UserDTO.builder()
.name("李元芳")
.email("[email protected]")
.birthday(DateUtils.parse("1998-09-08 12:14:15", "yyyy-MM-dd HH:mm:ss"))
.age(30)
.mobile("18755634343")
.build();
userService.addUser(userDTO);
}
这里用到了一个工具类DateUtils,代码如下:
package com.thizgroup.jpa.study.utils;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author gangquan.hu
* @Package: com.thizgroup.mybatis.study.utils.DateUtils
* @Description: 日期工具类
* @date 2019/8/12 15:57
*/
public class DateUtils {
public static Date parse(String dateStr,String pattern){
SimpleDateFormat dateFormat = new SimpleDateFormat(pattern);
try {
return dateFormat.parse(dateStr);
} catch (ParseException e) {
throw new RuntimeException("date string format error");
}
}
}
注意:如果开启了事务,则@Transactional注解的readOnly属性应当设置为 false,否则不能正常保存。
顺便说说save和saveAndFlush方法的区别:
- 在saveAndFlush上,此命令中的更改将立即刷新到DB。使用save,就不一定了,它可能只暂时保留在内存中,直到发出flush或commit命令。
- 但是要注意的是,即使在事务中刷新了更改并且未提交它们,这些更改对于外部事务仍然不可见,直到,提交这个事务。
6.修改数据操作
(1)使用save方法更新数据
首先,我们在IUserService接口中添加一个更新用户数据的方法,
/***
*
* 更新用户
* @param userDTO
*/
void updateUser(UserDTO userDTO);
然后在UserServiceImpl类中实现该方法,
@Override
public void updateUser(UserDTO userDTO) {
User user = convertDtoToEntity(userDTO);
//查询用户信息
User userOld = findById(user.getId());
if(userOld == null) throw new RuntimeException("user not found");
userOld.setModifyDate(new Date());
userOld.setEmail(user.getEmail());
userOld.setName(user.getName());
userOld.setAddressId(user.getAddressId());
userOld.setMobile(user.getMobile());
userOld.setAge(user.getAge());
userOld.setBirthday(user.getBirthday());
userRepository.save(user);
}
(2)@Modifying注解的使用
@Query与@Modifying这两个注解一起使用时,可实现个性化更新操作及删除操作;例如只涉及某些字段更新时最为常见。
下面演示一个案例,把id为1的用户的name值改为"张三丰",
@Modifying
@Query("update User set name = :name where id = :id")
int updateUserNameById(@Param("name") String name,@Param("id") Long id);
service层代码省略,下面是单元测试的代码如下:
@Test
public void updateUserNameByIdTest(){
userService.updateUserNameById("张三丰",1L);
}
同上,如果开启了事务,则@Transactional注解的readOnly属性应当设置为 false,否则不能正常更新。
7.删除数据操作
删除数据就很简单了,下面来个示例,
首先,我们在IUserService接口中添加一个删除用户数据的方法,
void deleteById(Long id);
然后在UserServiceImpl类中实现该方法,
@Override
public void deleteById(Long id) {
userRepository.deleteById(id);
}
单元测试代码如下:
@Test
public void deleteByIdTest(){
userService.deleteById(1L);
}
另外,JPA还提供了其他的删除方法,如下:
void delete(User user);//根据user对象删除用户信息
void deleteAll(Iterable<Long> ids);//根据id列表批量删除用户
void deleteAll();//删除所有用户
至此,springDataJpa基本的增删改查操作就介绍完了,有需要源码的朋友,请到git上下载源码,源码地址:https://github.com/hgq0916/springdatajpa-study.git。java学习交流群:184998348,欢迎大家一起交流学习。