手把手带你开启机器学习之路——房价预测(二)
点击上方“超哥的杂货铺”,轻松关注
在前一篇文章手把手带你开启机器学习之路——房价预测(一)中我们以加州住房价格数据集为基础,学习了数据抽样,数据探索性分析和可视化,数据预处理(缺失值填充,增加新特征,特征缩放,分类变量编码)等步骤,接下来继续深入,最终建立预测模型。可以在公众号后台回复“房价”获取两篇文章的数据,代码,PDF文件和思维导图。
认识数据预处理流水线
前面我们使用过sklearn的SimpleImpute类来进行缺失值填充。步骤为:
① 先创建imputer实例
② 调用fit方法将实例适配到训练集
③ 调用transform方法进行缺失值填充,最终返回包含转换后特征的一个numpy数组。
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
#删除类别变量
housing_num = housing.drop("ocean_proximity", axis=1)
#这一步可以计算所有数值型属性的中位数
imputer.fit(housing_num)
#这一步会自动进行中位数填充,结果是一个numpy数组
X = imputer.transform(housing_num)
其中后面两步可以合并起来:
imputer = SimpleImputer(strategy="median")
X = imputer.fit_transform(housing_num)sklearn API 在设计的时候遵循了一致性的设计原则。所有的类(对象)可以分为估算器,转换器,预测器三种。上面的步骤就涉及到前两种。
估算器。根据数据集对某些参数进行估算的任意对象都可以成为估算器。估算器调用fit方法,传入数据集(有时会有数据标签),结合适当的超参数就可以对数据集进行“估算”。本例中,imputer就是估算器,以数据集为参数,strategy是超参数,对源数据的中位数做出预估。
转换器。能够转换数据集的估算器称为转换器。转换器调用transform方法,传入待转换数据集,返回转换后的数据集。本例中,imputer也是转换器,把数据集转换为了x,x是填充缺失值后的数据集。调用fit_transform方法相当于先调用fit然后调用transform。但有时候fit_transform是被优化过的,运行会快一些。
预测器。(先列出来,后文会涉及到)能够对于给定的数据集进行预测的估算器,包含了predict方法。
这样设计的好处是方便我们使用sklearn中的流水线(pipeline),还允许我们自定义转换器,这样能够把一系列的步骤统一起来。
自定义添加属性的转换器
为了能与sklearn中的流水线无缝衔接,我们需要实现一个含有fit,transform,fit_transform方法的类。继承BaseEstimator, TransformerMixin类通常比较方便。代码介绍如下:
数据准备(点击图片查看大图)

自定义转换器

我们在自定义了添加属性转换器类时,继承了TransformerMixin类,该类就有了fit_transform()方法。
调用自定义转换器添加特征

实现的自定义转换器有一个超参数add_bedrooms_per_room,也可以不用添加。添加的好处是很方便地控制是否在最终的数据集中保留该特征。可以看到housing_num本来是8列,调用自定义转换器之后,变成了11列。这是因为add_bedrooms_per_room=True,添加了3个特征,如果为False,则会只添加两个特征。
构造转换流水线
sklearn中提供了Pipeline类,称为流水线类。它的构造函数会通过一系列的名称/估算器配对来定义步骤的序列,使数据转换按照正确的步骤来执行。除了最后一个是估算器之外,前面都必须是转换器。也就是必须要含有fit_transform()方法。命名可以随意。
当调用流水线的fit方法时,会在所有转换器上依次调用fit_transform方法,将上一个调用的输出作为参数传递给下一个调用方法。到最后一个估算器时,只会调用fit()方法。
流水线的方法与最终估算器的方法相同。当最后一个估算器是转换器时,它含有transform方法,那么流水线也含有该方法。看下面的流水线例子:

num_pipeline调用了fit_transform方法,相当于一次对housing_num进行了填充缺失值,添加属性,特征缩放三个步骤。在前面的文章中我们对一个类别变量ocean_proximity进行了OneHotEncoder编码处理,同样可以定义流水线。并且可以将类别变量和数值变量定义看作是两条并行的流水线,最后组合起来。sklearn中提供了相应的FeatureUnion类。注意两条流水线需要从选择转换器开始,选择出相应的待处理属性。完整的代码如下:
自定义选择转换器

定义两条流水线,然后合并

除了自定义选择转换器,新版本的sklearn中也有可以直接使用的ColumnTransformer,这样就省去了自己定义选择器的步骤,代码如下所示,可以看到两种方式的结果是完全一样的(最后一行的代码返回True的结果)

初步训练模型
首先建立一个简单的线性模型并查看训练误差。如下面代码所示,主要使用了sklearn里的linear_model模块和metrics模块。
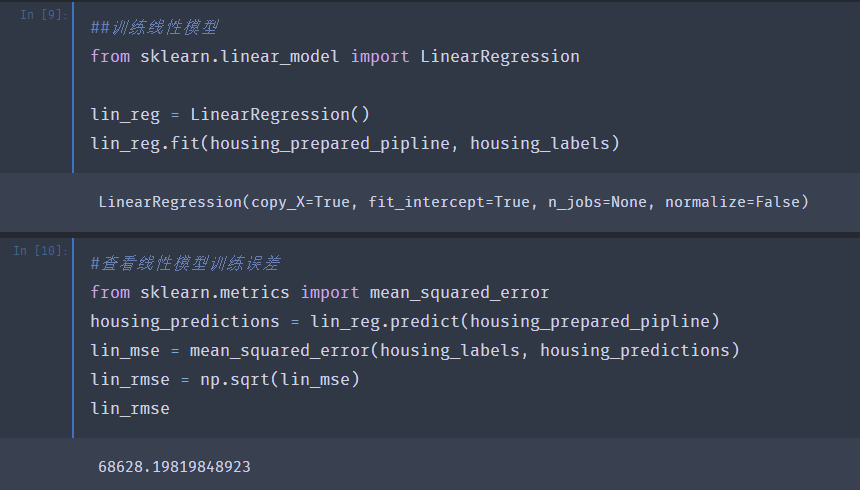
评估的标准我们使用的是RMSE,这里给出误差值是68628美元,在前一篇文章中给出了median_housing_values的两个四分位数大约分别是12w和26.5w,因此这个误差值并不理想,是一种“欠拟合”的情况。可以尝试添加新的特征或者训练更强大的模型来改善这种情况。本文不做过多的特征工程,主要来对比一下不同模型的效果。下面我们尝试一下决策树模型。
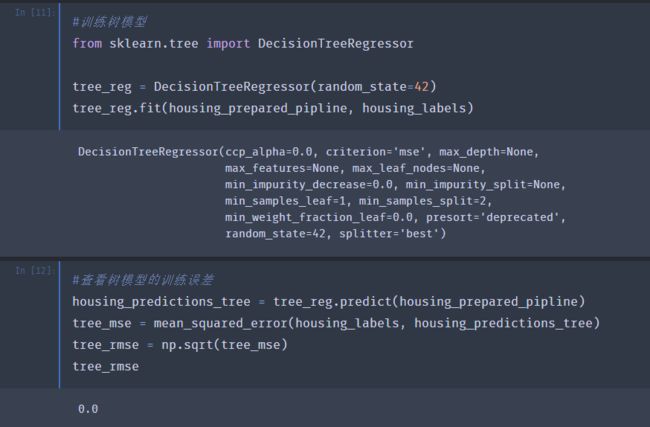
可以看到,决策树模型确实很强大,做到了0训练误差。通常这是一种“过拟合”的情况。
使用交叉验证评估模型
sklearn中提供了交叉验证的功能。K-折交叉验证的过程是,将训练集随机分割成K个不同的子集。每个子集称为一折(fold)。接下来训练K次,每次训练时,选其中一折为验证集,另外的K-1折为训练集。最终输出一个包含K次评估分数的数组。下图表示了5折交叉验证的过程。

我们采用K=10时的代码,进行评估:

交叉验证功能更倾向于使用效用函数(越大越好),而不是成本函数(越小越好)。因此得出的分数实际上是负分MSE。可以参考文档的参数说明
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
对比树模型和线性模型的交叉验证结果,树模型的误差平均值较大,方差较小,线性模型的误差平均值较小,方差较大。线性模型略好于树模型。
尝试其他模型:随机森林和SVM
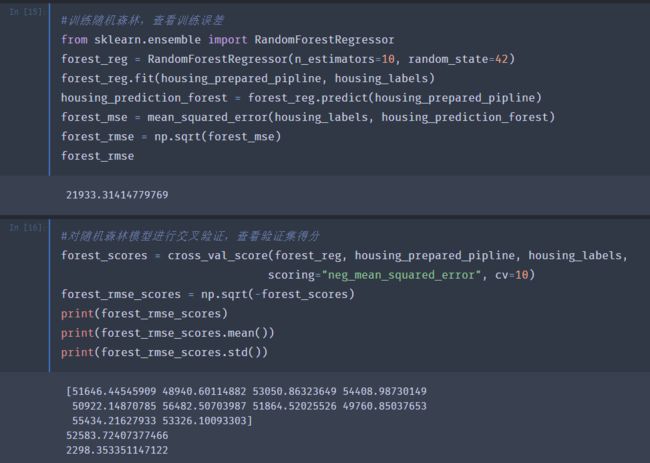
随机森林
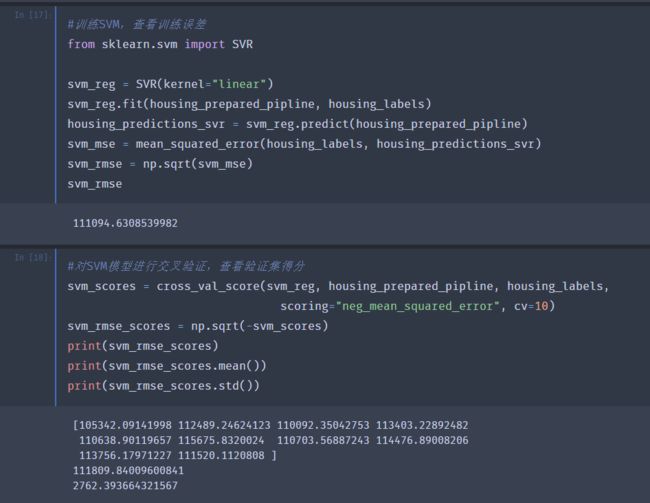
SVM
几个模型的结果总结如下面表格:

目前来看随机森林的表现最好:训练集和交叉验证的误差得分都小。但训练集的分数仍然远低于验证集,说明存在一定的过度拟合。
使用网格搜索调整超参数
sklearn中提供了GridSearchCV帮我们进行参数的网格搜索,需要事先指定超参数组合。例如下面以随机森林为例说明:

param_grid中有两个dict,它的含义是,首先评估第一个dict中n_estimator和max_features的所有组合,共3X4=12种。然后尝试第二个dict中的参数组合,共2X3=6种,并且次数的booststrap参数应该设置为False(默认值为True)。超参数的组合一共是18种,我们还使用了5折交叉验证,因此一共要进行90次训练。
查看gridsearch为我们找到的最优参数:

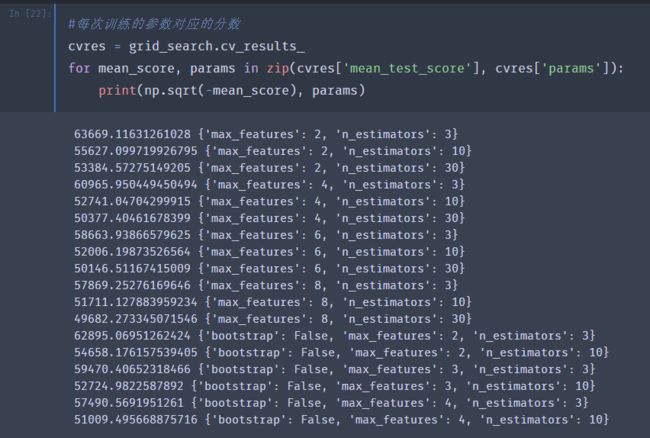
可以看到,最优的参数组合为max_features为8,n_estimators为30,对应的验证集分数为49682,比之前默认的模型要好一些。
可以通过将搜索结果转为dataframe查看更多细节:
使用随机搜索调整超参数
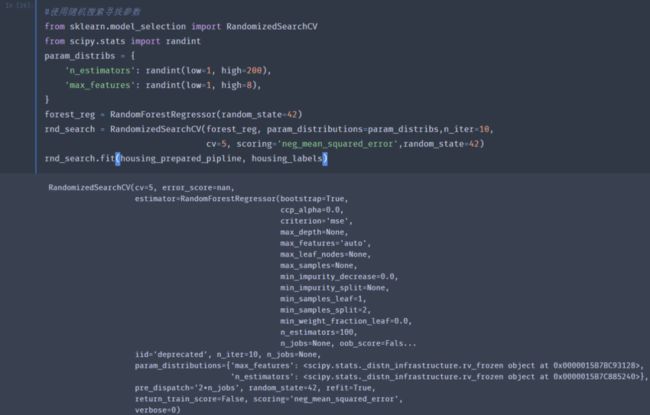
随机搜索是使用了sklearn中的RandomizedSearchCV。与GridSearchCV相比,它不会尝试所有可能的组合,而是在每次迭代时为每个超参数选择一个随机值,然后对一定数量的随机组合进行评估。运行10次迭代的结果如下:

可以看到,max_feature为7,n_estimators为180时,得到的误差最小,是最好的组合。比刚才网格搜索的结果还略好一些。
将最优模型应用于测试集
通过前面的分析,我们认为随机森林模型效果是最好的,并且使用两种方式取得了最佳的超参数。接下来要在测试集上使用最佳模型。见下面的代码:
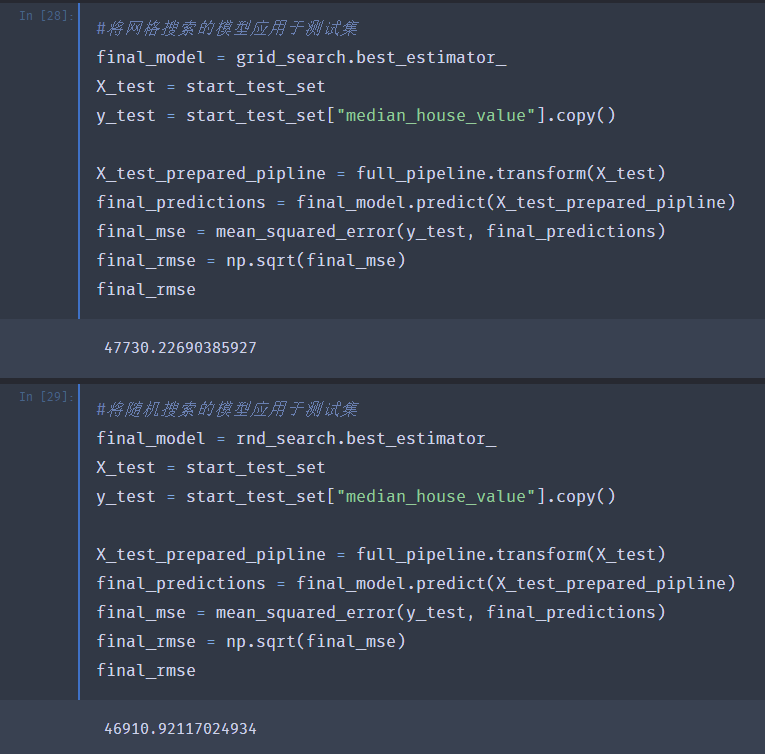
我们在之前构造了处理对数据集进行预处理的流水线,在测试集上也只需要调用transform方法就可以很方便地转换数据,并最终将模型预测的结果与实际结果进行比较得到测试集上的RMSE。随机搜索的结果要略好于网格搜索的结果。
小结
至此我们从数据探索开始,最终实现了一个机器学习项目完整的流程。本文我们采用的是在特征不变的情况下寻找最优的模型。想提升模型的表现还可以通过深入做一些特征工程的方式,从而能用更好的特征表达数据的分布。实际中更多的会采用两种方式结合。另外需要指出:预测器同样也可以结合在pipeline中,这样能进一步简化对于数据的处理和测试工作。
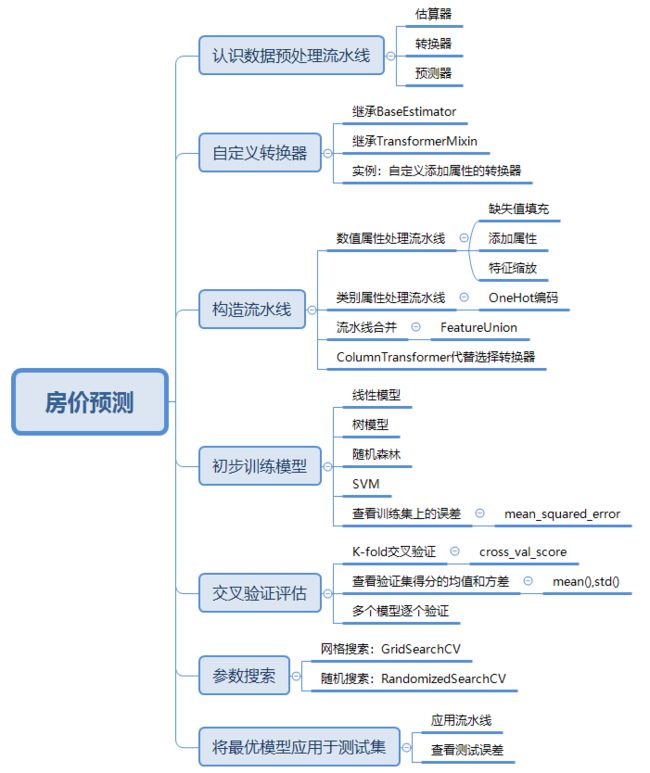
本文的小结如下面脑图所示,可以在公众号后台回复“房价”获取两篇文章的数据,代码,PDF文件和思维导图。
reference:
《机器学习实战:基于Scikit-Learn和Tensorflow》第二章

以清净心看世界;
用欢喜心过生活。
超哥的杂货铺,你值得拥有~
长按二维码关注我们
推荐阅读:
1.手把手带你开启机器学习之路——房价预测(一)
2.在一个机器学习项目中,你需要做哪些工作?
3.简单几步,教你使用scikit-learn做分类和回归预测
4.RFM模型是什么,我用python带你实战!
5.一场pandas与SQL的巅峰大战