——FSAF,CVPR 2019

摘要
本文提出feature selective anchor-free (FSAF) module,单阶段检测器的组成block,可以插入具有特征金字塔结构的单阶段检测器。解决了基于anchor的检测方法的两个主要问题:1、启发式的特征选择(依赖于人为指定),2、基于IOU的特征采样。FSAF模块进行在线特征选择,并且应用于多级anchor-free分支的训练,每一分支来源于特征金字塔的每一层,允许检测框在任意层上进行anchor-free的编码和解码。在训练过程中,动态地将每个物体标注分配至最合适的层,在前向时,FSAF可以通过并行或者联合输出预测与anchor-based分支一起完成检测,通过简单实现anchor-free分支和在线特征选择策略来实现。在COCO上的实验结果表明,FSAF模块相比anchor-based的对应模型表现更好,同时更快。当与anchor-based分支一起用时,FSAF在不同设置下大幅度提升了RetinaNet的性能,而基本没引入前向负担。(最优模型44.6% mAP)
介绍
基于anchor的方法anchor-box的尺寸比例依赖于手工方法,但是特征与实例之间的匹配关系却取决于实例的尺寸,这样会带来物体大小与特征层次不匹配的问题。待检测目标通常存在尺度差异性,使用anchor boxes将所有的目标离散化成不同尺寸、长宽比的有限个boxes,因此将小的anchor boxes对应到浅层特征,大的anchor对应到深层特征,ground truth boxes基于IoU匹配到不同的anchor boxes。但是这样做的缺陷在于可能gt匹配到的不是最接近的anchor boxes。
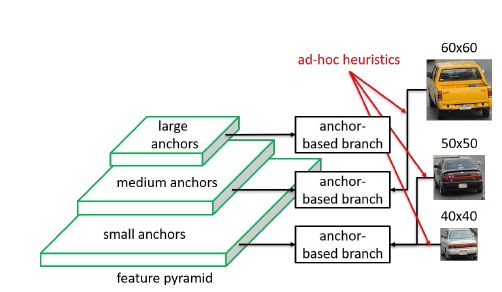
FSAF令每个物体自行选择最合适的特征层次,因此就不应该采用anchor-based的方式来限制特征选取,以anchor-free的方式对实例进行编码,以学习分类和回归的参数。FSAF模块嵌入anchoer-based的网络示意图如下:
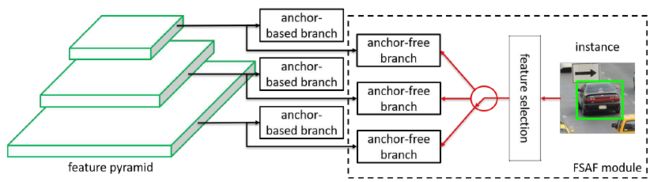
anchor-free分支与anchor-based分支并行,且同样包含分类和回归子网,一个物体可以被分配到任一层特征的anchor-free分支,训练时,为每个目标动态选择最合适的特征层次,被选择的特征层次则学习检测对应的物体。FASF是back-bone无关的,能嵌入到任何一种包含特征金字塔的单阶段检测器中,同时带来较小的计算负担。
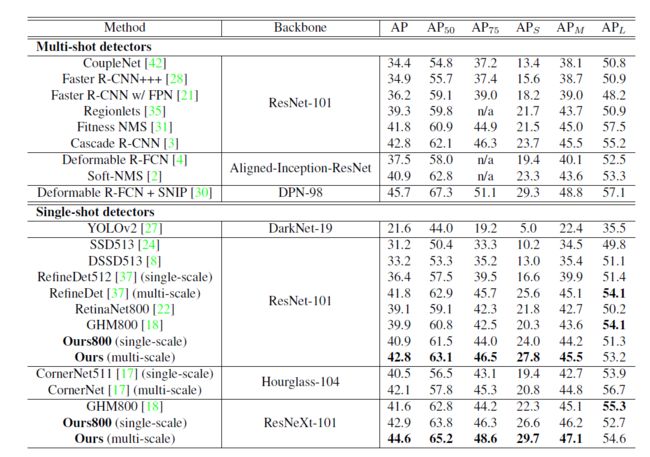
与ResNeXt-101 based RetinaNet相比,精度提高1.8%,延迟只增加6ms。最好的模型44.6mAP。
以往的多层特征检测的模型都采用了人为定义的anchor,如SSD,DSSD,FPN,RetinaNet,DeNet等。
anchor-free的方法有:Dense-Box(全卷积直接预测检测框);UnitBox(IoU loss)
An anchor-free region proposal network for faster r-cnn based text detection approaches
基于关键点的检测:CornerNet,CenterNet,Object as Points
Feature Selective Anchor-Free Module
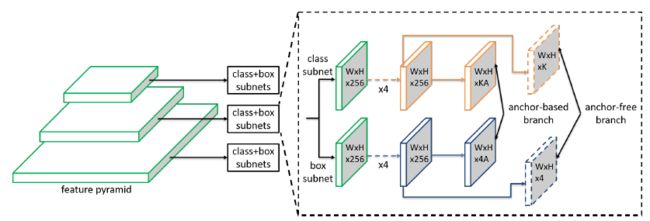
RetinaNet中FPN包含5层特征:,的stride为,即相对原图分辨率降低,每层上都接一个分类和回归子网,均为全卷积网络,预测anchor-box的类别和4个类别无关的位置偏移。
在RetinaNet的顶部,FSAF模块在每个分支引入两个额外的卷积层,负责anchor-free分支的分类和回归。具体而言,K(类别)个3*3卷积+Sigmoid激活添加到分类分支,4个3*3卷积+ReLU添加到回归分支。由此,anchor free和anchor-based方法就能并行工作,同时共享特征。
Ground-truth and Loss
ground truth box (中心坐标加宽高),class ,这个物体将被分配至第l层特征
predicted box ,有
定义:
effective box ,缩放比例系数为
ignoring box ,缩放比例系数为
分别作为predicted box的一部分,使得:
一个目标的标注产生如下图:
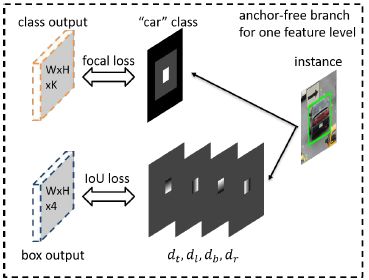
Classification Output:
分类输出的标注是K个图,每个图对应一个类。每个物体以三种方式影响第k个ground-truth map:
1、effective box 表示是在某类标注图中显示为白框的正样本,表示实例的存在。
2、ignoring box 减去effective box ()表示上图中灰色的区域,表示这部分区域的梯度不回传;
3、相邻标注图中的ignoring boxes同样表示ignoring boxes,如果其存在的话。
如果两个目标的effective box在某一层特征图上重叠,则较小的目标具有较高的优先级。剩下的区域为负样本(黑色的,以0填充),表明没有物体。Focal loss用于分类网络,一张图片的总分类损失来源于anchor-free分支的所有非ignoring box,并由所有effective boxes中的像素个数进行正则化。
Box Regression Output:
回归输出的标注是4个偏移图(offset maps,与类别无关),物体仅仅影响偏移图中的effective box区域,对于effective box中的每个像素位置,将predicted box 表示为四维向量,其中,表示当前像素位置与predicted box 的左、上、底、右边的距离。然后,将4个偏移图上的位置处的4维向量设置为,其中每个图对应于一个维度,是归一化常数,设为4.0。IoU loss应用于回归分支,总的回归损失是所有effective box 的IoU loss的平均值。
在前向时,直接由分类和回归输出编码得到预测框,在每个像素位置,假设预测的偏移为
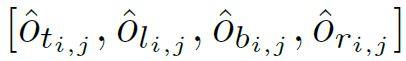
预测的距离为
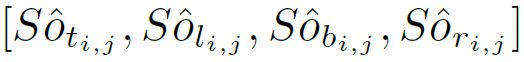
预测框的左上角和右下角为:
最后以缩放预测框来得到原图上的检测框。可以通过分类输出图上的位置处的最大分数和K维向量的对应类来确定框的置信度得分和类别。
Online Feature Selection:
anchor free分支允许使用任意层的特征进行学习,FSAF根据目标的语义来选择最合适的特征,而不仅仅是根据目标的尺寸(anchor-based)。
给定一个目标,定义在某层特征图上的分类损失和回归损失为,计算方法为:
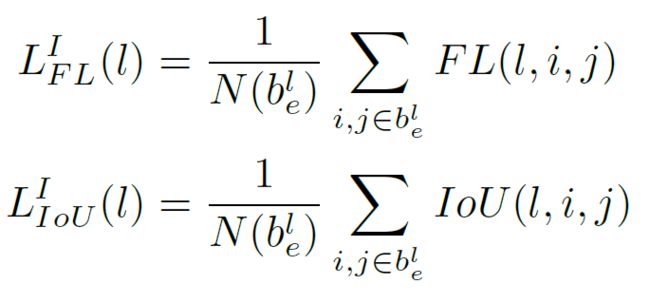
表示effective box中的像素个数。表示在特征图上位置处的focal loss和IoU loss。
在线特征选择如图:

一个目标将经过所有层上的anchor free分支,计算每层上的分类损失和回归损失,并得到他们的和,然后,选择使得损失和最小的特征层作为特征选取层:

训练中,对于一个batch,将更新其相应分配的目标的的特征,因此所选特征目前是建模实例的最佳特征,它的损失形成了特征空间的下界,训练过程中,将不断降低这个下界。
在infer时,我们不需要选择特征,因为最合适的特征金字塔层级将自然地输出高置信度分数。
为了验证这个在线特征选择的重要性,同样构建一个启发式的选择方式(FPN,仅仅根据尺度来选择),一个目标被分配的层级为:
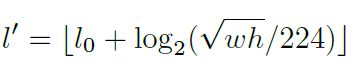
是w×h = 的目标应该映射到的特征层级。
此处,,表示ResNet使用第五组卷积特征进行分类。
Joint Inference and Training
将FSAF嵌入到RetinaNet,能与anchor based的分支并行,保持anchor based分支的参数不变(训练和前向都不变)
Inference:
FSAF仅仅增加了几个卷积层,前向依然很简单。对于anchor free分支,在对置信度得分(confidence score)进行阈值处理(阈值0.05)后,只解码每个金字塔特征层级中最多1k个得分位置的边框预测。来自所有层级的这些较好的预测与来自anchor based的分支的边框预测合并,随后是具有阈值0.5的非极大值抑制,从而产生最终检测。
Initialization:
ResNet在ImageNet 1k上预训练,遵循RetinaNet对其进行初始化,对于FSAF的几个卷积,以高斯分布进行权重初始化(方差0.01),偏移为,表明在训练的初始阶段,每个位置产生objectness score在0.01周围。回归分支的权重初始化为方差为0.01的高斯分布,偏移为0.1,保证网络初始训练阶段稳定,损失不会太大。
Optimization:
网络的整体损失为anchor free损失和anchor based损失,令表示RetinaNet的anchor based的总损失,分别为anchor free分支的总分类和总回归损失,网络的总损失为:

网络训练细节:
stochastic gradientdescent (SGD) on 8 GPUs with 2 images per GPU.
如非说明,all models are trained for 90k iterationswith an initial learning rate of 0.01, which is divided by 10 at 60k and again at 80k iterations.
Horizontal image flipping is the only applied data augmentation unless otherwise specified.
Weight decay is 0.0001 and momentum is 0.9.
Experiments
为了验证anchor free 分支的作用,消融实验如下:
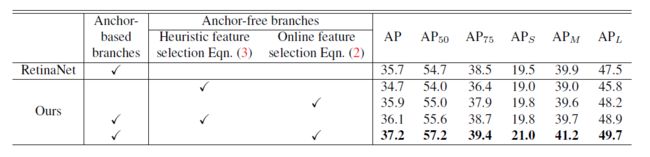
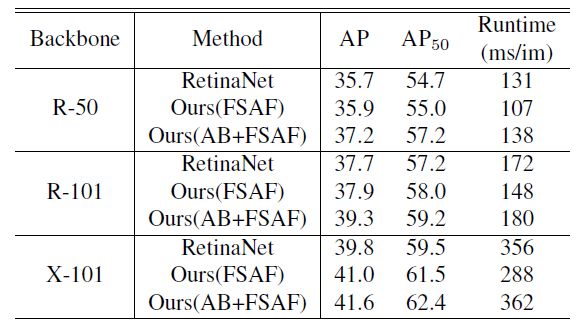
AB:Anchor-based branches. R: ResNet. X: ResNeXt.
可视化:

数字表示选取的特征层级。
与其他方法对比: