判断诗句出自李白还是杜甫?(python词频分析)
在第一篇博客里提到了使用python的jieba库中文分词功能可以用来分析诗句出自李白还是杜甫之手,
准确地来说,可以通过程序来分析输入的诗句更像李白写的还是杜甫写的。
今天我们就来完成它。
准备阶段
为了分析李白和杜甫的作诗风格,需要大量李白杜甫的诗句来进行分析。
所以先通过网络下载李白、杜甫的诗词合集,保存为txt格式,使用utf-8编码。
下文 libai.txt 、 dufu.txt即分别代表两位诗人诗词的合集,内含各几百首古诗词。
对两份txt的分析过程基本一致,下面以对李白诗词的分析为例。
对文件内容进行读取并分词
import jieba
txt = open("libai.txt", encoding="utf-8").read()
words = jieba.lcut(txt)考虑到古文多为单音节词,并且单个字对作诗风格也存在很大影响,所以分词时不使用停用词表。
排除垃圾数据的影响
counts = {}
cs = ["!",",","。","《","》","·"," ","\n","(",")","(","?"]
for word in words:
if word not in cs:
counts[word] = counts.get(word,0) + 1通过阅读下载的txt文件,截取部分如图所示

发现可能会对数据产生影响的有各类标点、换行符等,所以把他们放在一个列表中,在统计时对其进行排除。
格式转化、排序
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)打印排名前200个观察,全代码
import jieba
txt = open("libai.txt", encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
cs = ["!",",","。","《","》","·"," ","\n","(",")","(","?"]
for word in words:
if word not in cs:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(200):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))截取部分结果展示


赋权值、存入文档
鉴于分词比较耗费时间,为了以后更快地分析,避免每次判断都要分词一次,要把结果存入文件,注意以utf-8编码存储。
存储之前对每个词语赋权值,供判断时计算分数。
笔者使用前200进行判断,并给出现最多的词语赋200,往下递减,第200赋1分。使用字典一一对应。
dict={}
for i in range(200):
dict[items[i][0]] = 200 - i
with open("analibai.txt","w+",encoding='utf-8') as f:
f.write(str(dict)) 修改后全代码
import jieba
txt = open("libai.txt", encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
cs = ["!",",","。","《","》","·"," ","\n","(",")","(","?"]
for word in words:
if word not in cs:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
dict={}
for i in range(200):
dict[items[i][0]] = 200 - i
with open("analibai.txt","w+",encoding='utf-8') as f:
f.write(str(dict)) 至此文件夹生成文件analibai.txt,存储一个字典

对杜甫诗词的分析基本一致,仅因为下载的资源原因,对垃圾数据排出时存在一些差异,故不再赘述。
下面通过程序获取输入进行判断
首先将两个文档中的内容读入字典。为了尽可能地获取诗中出现的意象、词语,笔者考虑使用全模式进行分词,并排除可能出现的标点、空的影响。再用分词结果分别与两个字典进行比较、累加分值,最后计算平均。较简单,代码如下。
import jieba
txt_li=open("analibai.txt",encoding="utf-8-sig").read()
txt_du=open("anadufu.txt",encoding="utf-8-sig").read()
dict_li=eval(txt_li)
dict_du=eval(txt_du)
s = input()
words = jieba.lcut(s,cut_all = True)
puns = ",。?!"
for pun in puns:
while pun in words:
words.remove(pun)
while "" in words:
words.remove("")
sum_li = 0
sum_du = 0
for i in words:
if i in dict_li:
sum_li += dict_li[i]
if i in dict_du:
sum_du += dict_du[i]
print("李白相似分:%.1f"%(sum_li/len(words)))
print("杜甫相似分:%.1f"%(sum_du/len(words)))我们尝试进行判断
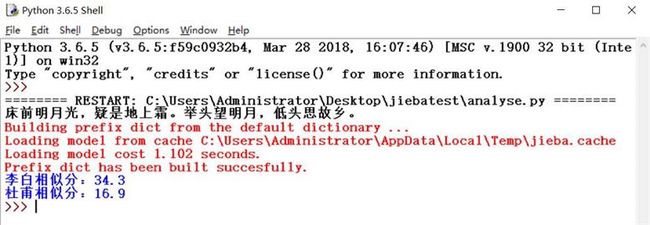


结果基本符合预期
最后,考虑到诗人不同的诗风格不同、人生各时期风格不同、以及样本有限、模型非最优等因素,会存在部分判断结果不准确,各位不必太过认真,求轻喷。
转载请告知作者。