【Python3 爬虫学习笔记】用PySpider爬取虎嗅网并进行文章分析
–转自《1900-高级农民工》http://www.makcyun.top
安装并运行pyspider
安装pyspider
pip3 install pyspider
运行pyspider并创建爬虫项目huxiu
pyspider all
成功后,如下图所示:
在浏览器中输入:http://localhost:5000或者http://127.0.0.1:5000
点击Create,输入项目名称,此处不输入Start URLs
爬取数据
爬取代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-11-22 10:57:04
# Project: huxiu
from pyspider.libs.base_handler import *
import json
from pyquery import PyQuery as pq
import pandas as pd
import pymongo
import time
import numpy as np
client = pymongo.MongoClient('localhost', 27017)
db = client.Huxiu
mongo_collection = db.huxiu_news
class Handler(BaseHandler):
crawl_config = {
"headers":{
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
}
def get_taskid(self, task):
return md5string(task['url'] + json.dumps(task['fetch'].get('data', '')))
def on_start(self):
for page in range(2, 50):
print('正在爬取第 %s 页' % page)
self.crawl('https://www.huxiu.com/v2_action/article_list', method='POST', data={'page':page}, callback=self.index_page)
def index_page(self, response):
content = response.json['data']
doc = pq(content)
lis = doc('.mod-art').items()
data = [{
'title':item('.msubstr-row2').text(),
'url':'https://www.huxiu.com'+str(item('.msubstr-row2').attr('href')),
'name':item('.author-name').text(),
'write_time':item('.time').text(),
'comment':item('.icon-cmt+em').text(),
'favorites':item('.icon-fvr+em').text(),
'abstract':item('.mob-sub').text()
}for item in lis]
print(data)
return data
def on_result(self, result):
if result:
self.save_to_mongo(result)
def save_to_mongo(self, result):
df = pd.DataFrame(result)
content = json.loads(df.T.to_json()).values()
if mongo_collection.insert_many(content):
print('存储到mongodb成功')
sleep = np.random.randint(1,5)
time.sleep(sleep)
查看数据
由于只用于学习,此处只爬取50页数据。
打开Studio 3T,查看爬取到的数据。

爬取数据分析
# -*- encoding: utf-8 -*-
import pymongo
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import jieba
import os
from PIL import Image
from os import path
plt.style.use('ggplot')
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
fig = plt.figure(figsize=(8,5))
axl = fig.add_subplot(1,1,1)
colors = '#6D6D6D' # 设置标题颜色为灰色
color_line = '#CC2824'
fontsize_title = 20
fontsize_text = 10
# 数据清洗处理
def parse_huxiu():
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['Huxiu']
collection = db['huxiu_news']
# 将数据库数据转为dataFrame
data = pd.DataFrame(list(collection.find()))
# 删除无用的_id列
data.drop(['_id'], axis=1, inplace=True)
# 删除特殊符号©
data['name'].replace('©','',inplace=True,regex=True)
data_duplicated = data.duplicated().value_counts()
# 删除重复值
data = data.drop_duplicates(keep='first')
# 将数据列改为数值列
data = data.apply(pd.to_numeric, errors='ignore')
# 修改时间,并转换为datetime格式
data['write_time'] = data['write_time'].replace('.*前', '2018-10-31', regex=True)
data['write_time'] = pd.to_datetime(data['write_time'])
data = data.reset_index(drop=True)
# 增加标题长度列
data['title_length'] = data['title'].apply(len)
# 年份列
data['year'] = data['write_time'].dt.year
return data
# 数据分析部分
def analysis1(data):
data.set_index(data['write_time'], inplace=True)
data = data.resample('Q').count()['name'] # 以季度汇总
data = data.to_period('Q')
# 创建x,y轴标签
x = np.arange(0, len(data), 1)
axl.plot(x, data.values,
color = color_line,
marker = 'o', markersize = 4
)
axl.set_xticks(x) # 设置x轴标签为自然数序列
axl.set_xticklabels(data.index) # 更改x轴标签值为年份
plt.xticks(rotation=90) # 旋转90度,不至于太拥挤
for x,y in zip(x,data.values):
plt.text(x,y + 10, '%.0f' %y,ha = 'center', color = colors, fontsize=fontsize_text)
# 设置标题及横纵坐标轴标题
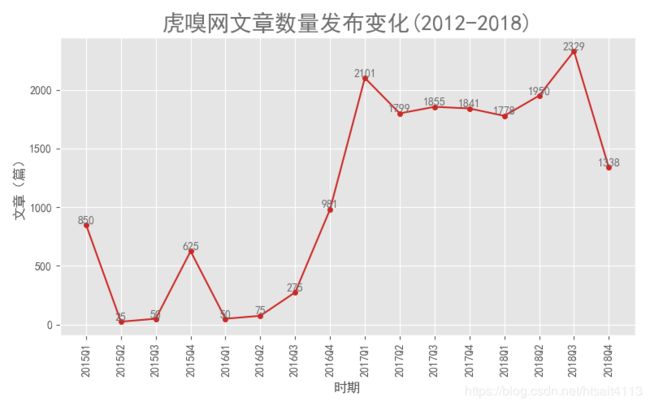
plt.title('虎嗅网文章数量发布变化(2012-2018)', color = colors, fontsize=fontsize_title)
plt.xlabel('时期')
plt.ylabel('文章(篇)')
plt.tight_layout() # 自动控制空白边缘
plt.savefig('虎嗅网文章数量发布变化.png', dip=200)
plt.show()
data = parse_huxiu()
# analysis1(data)
# 2 文章收藏量分析
def analysis2(data):
def topn(data):
top = data.sort_values('favorites', ascending=False)
return top[:3]
data = data.groupby(by=['year']).apply(topn)
print(data[['title', 'favorites']])
# 增加每年top123列,列依次值为1、2、3
data['add'] = 1 # 辅助
data['top'] = data.groupby(by='year')['add'].cumsum()
data_reshape = data.pivot_table(index='year', columns='top', values='favorites').reset_index()
print(data_reshape)
data_reshape.plot(
y = [1,2,3],
kind = 'bar',
width = 0.3,
color = ['#1362A3', '#3297EA', '#8EC6F5']
)
# 添加x轴标签
years = data['year'].unique()
plt.xticks(list(range(7)), years)
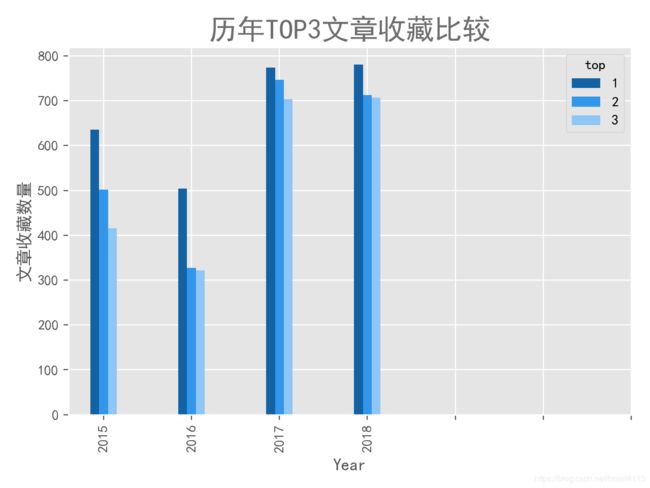
plt.xlabel('Year')
plt.ylabel('文章收藏数量')
plt.title('历年TOP3文章收藏比较', color = colors, fontsize = fontsize_title)
plt.tight_layout()
plt.savefig('历年TOP3文章收藏比较.png', dpi=200)
plt.show()
# analysis2(data)
# 3 发文最多的媒体 top20
def analysis3(data):
data = data.groupby(data['name'])['title'].count()
data = data.sort_values(ascending=False)
print(data)
# pandas 直接绘制,invert_yaxis()颠倒顺序
data[1:21].plot(kind='barh',color=color_line).invert_yaxis()
for y,x in enumerate(list(data[1:21].values)):
plt.text(x+12,y+0.2,'%s' %round(x,1),ha='center',color=colors)
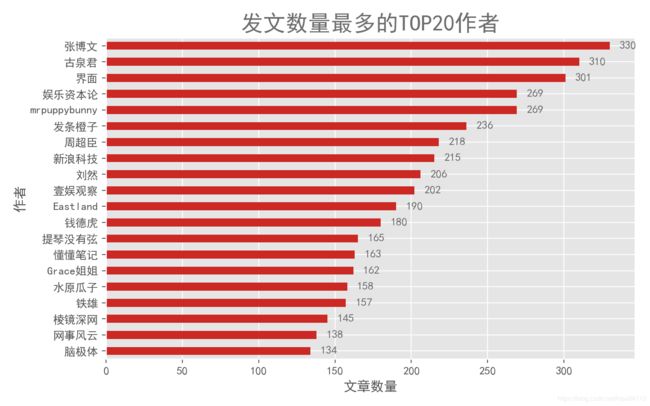
plt.xlabel('文章数量')
plt.ylabel('作者')
plt.title('发文数量最多的TOP20作者', color = colors, fontsize=fontsize_title)
plt.tight_layout()
plt.savefig('发文数量最多的TOP20作者.png',dpi=200)
plt.show()
# analysis3(data)
# 发文超过至少5篇以上的作者的文章平均收藏数排名
def analysis4(data):
data = pd.pivot_table(data,values=['favorites'],index='name',aggfunc=[np.sum,np.size])
data['avg'] = data[('sum','favorites')]/data[('size','favorites')]
# 平均收藏数取整
# data['avg'] = data['avg'].round(decimals=1)
data['avg'] = data['avg'].astype('int')
# flatten 平铺列
data.columns = data.columns.get_level_values(0)
data.columns = ['total_favorites','ariticls_num','avg_favorites']
# 筛选出文章数至少5篇的
data=data.query('ariticls_num > 4')
data = data.sort_values(by=['avg_favorites'],ascending=False)
print(data[:10])
print(data[-10:])
# analysis4(data)
# print(data.dtypes)
# 5 收藏和评论的分布直方图
def analysis5(data):
sns.distplot(data['favorites'])
plt.tight_layout()
# plt.title('收藏和评论的分布直方图', color = colors, fontsize=fontsize_title)
# plt.savefig('收藏和评论的分布直方图.png',dpi=200)
plt.show()
# analysis5(data)
# 6 散点图查看收藏和评论数的关系,发现个别异常
def analysis6(data):
plt.scatter(data['favorites'], data['comment'], s=8, color='#1362A3')
plt.xlabel('文章收藏量')
plt.ylabel('文章评论数')
plt.title('文章评论数与收藏量关系', color = colors, fontsize=fontsize_title)
plt.tight_layout()
plt.savefig('文章评论数与收藏量关系.png', dpi=200)
plt.show()
# analysis6(data)
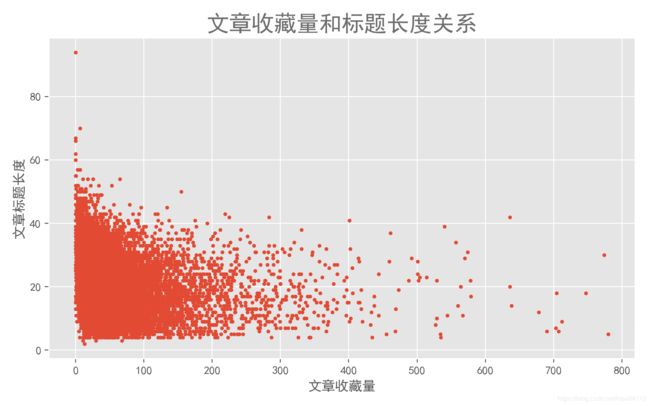
# 7 查看标题长度与收藏量的关系
def analysis7(data):
plt.scatter(
x=data['favorites'],
y=data['title_length'],
s=8,
)
plt.xlabel('文章收藏量')
plt.ylabel('文章标题长度')
plt.title('文章收藏量和标题长度关系', color = colors, fontsize=fontsize_title)
plt.tight_layout()
plt.savefig('文章收藏量和标题长度关系.png', dpi=200)
plt.show()
# analysis7(data)
# 8 查看标题长度与收藏量和评论数之间的关系
def analysis8(data):
plt.scatter(
x=data['favorites'],
y=data['comment'],
s=data['title_length']/2,
)
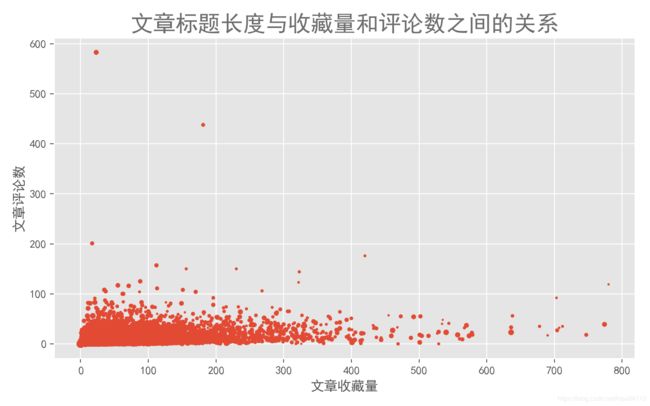
plt.xlabel('文章收藏量')
plt.ylabel('文章评论数')
plt.title('文章标题长度与收藏量和评论数之间的关系', color = colors, fontsize=fontsize_title)
plt.tight_layout()
plt.savefig('文章标题长度与收藏量和评论数之间的关系.png', dpi=200)
plt.show()
# analysis8(data)
# 9 词云
def analysis9(data):
jieba.load_userdict("userdict.txt")
jieba.add_word('区块链')
text=''
for i in data['title'].values:
# for i in data[data.year == 2018]['title'].values:
# 替换无用字符
symbol_to_replace = '[!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~]+'
# data['name'].str.replace(symbol_to_replace,'',inplace=True,regex=True)
i = re.sub(symbol_to_replace,'',i)
# print(i)
text+=' '.join(jieba.cut(i,cut_all=False))
# text = jieba.del_word('如何')
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
background_Image = np.array(Image.open(path.join(d, "tiger.jpg")))
# background_Image = plt.imread('./tiger.jpg')
font_path = 'C:\Windows\Fonts\simhei.ttf' # 思源黑,黑体simhei.ttf
# 添加stopswords
stopwords = set()
# 先运行对text进行词频统计再排序,再选择要增加的停用词
stopwords.update(['如何','怎么','一个','什么','为什么','还是','我们','为何','可能','不是','没有','哪些','成为','可以','背后','到底','就是','这么','不要','怎样','为了','能否','你们','还有','这样','这个','真的','那些'])
wc = WordCloud(
# background_color = '#3F3F3F',
# background_color = 'white',
background_color = 'black',
font_path = font_path,
mask = background_Image,
stopwords = stopwords,
max_words = 200,
# width = 1000,height=600,
margin =2,
max_font_size = 100,
random_state = 42,
scale = 2,
# colormap = 'viridis'
)
wc.generate_from_text(text)
process_word = WordCloud.process_text(wc, text)
# 下面是字典排序
sort = sorted(process_word.items(),key=lambda e:e[1],reverse=True) # sort为list
print(sort[:50]) # 输出前词频最高的前50个,然后筛选出不需要的stopwords,添加到前面的stopwords.update()方法中
img_colors = ImageColorGenerator(background_Image)
wc.recolor(color_func=img_colors) # 颜色跟随图片颜色
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.tight_layout() # 自动控制空白边缘,以全部显示x轴名称
plt.savefig('huxiu5.png',dpi=200)
plt.show()
analysis9(data)
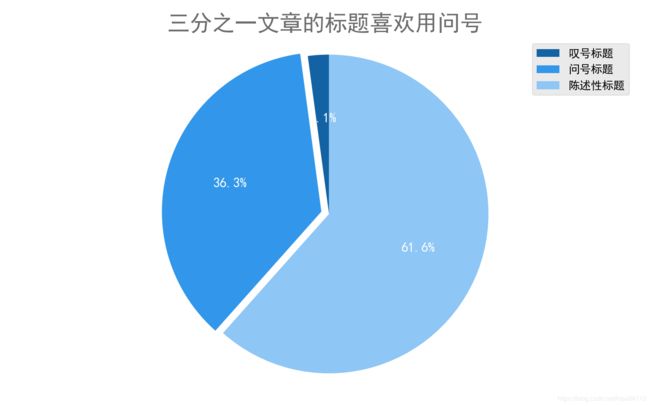
# 10 绘制标题形式饼图
def analysis10(data):
data1 = data[data['title'].str.contains("(.*\?.*)|(.*\?.*)")]
data2 = data[data['title'].str.contains("(.*\!.*)|(.*\!.*)")]
# 带有问号的标题数量
quantity1 = data1.shape[0]
# 带有叹号的标题数量
quantity2 = data2.shape[0]
# 剩余数量
quantity = data.shape[0] - data1.shape[0] - data2.shape[0]
sizes = [quantity2,quantity1,quantity]
labels = [u'叹号标题',u'问号标题',u'陈述性标题']
colors_pie = ['#1362A3','#3297EA','#8EC6F5'] #每块颜色定义
explode = [0,0.05,0]
plt.pie(
sizes,
autopct='%.1f%%',
labels= labels,
colors =colors_pie,
shadow = False, #无阴影设置
startangle =90, #逆时针起始角度设置
explode = explode,
# textprops={'fontsize': 14, 'color': 'w'} # 设置文字颜色
textprops={'fontsize': 12, 'color': 'w'} # 设置文字颜色
)
plt.title('三分之一文章的标题喜欢用问号',color=colors,fontsize=fontsize_title)
plt.axis('equal')
plt.axis('off')
plt.legend(loc = 'upper right')
plt.tight_layout() # 自动控制空白边缘,以全部显示x轴名称
plt.savefig('title问号.png',dpi=200)
plt.show()
# analysis10(data)