一个类ring buff的ping pong buff实现
代码参考于:https://github.com/dennis-musk/pingpong_buffer.git
我的代码:https://github.com/Mr-jinfa/ping-pong-buff--like-ring-buff
貌似好久没更新博客,因为这段时间浸淫于Android、音视频。虽然两个都学得不咋地,不过还是有点点收获。至少遇到某函数时再也不会叫函数,而是尊称为“方法”。。
本文本着分享模块间数据交互的性能优化手段及其基础知识,展示一个可用案例供读者试验/移植/优化。本文代码移植于这里,我改进后的代码在这里。
先看下大众化的串行编程模型示例图
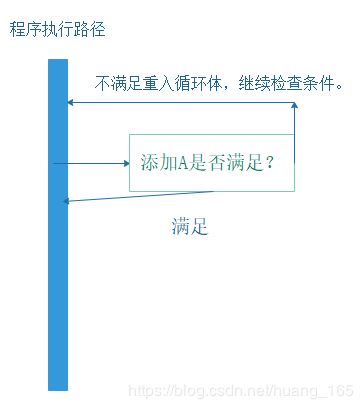
可以看到,由于串行编程只有一条执行路径(线程),所以遇到添加不满足时只能不断地轮询条件可得。这样编码模式适用于条件分支判断,不适用于当程序依赖某个关键条件的情况。
再看下用于提高性能的并行的编程模型示例图
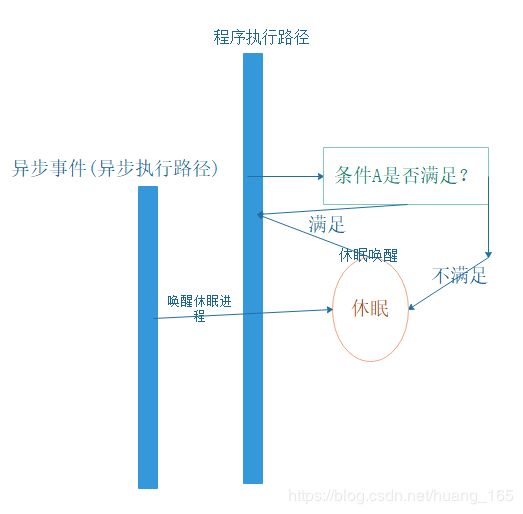
和串行编程区别在于多了休眠、异步执行路径机制。这样做的好处是主执行路径可以主动休眠(主动释放调度权--降低cpu消耗),等待资源可用等异步事件唤醒。
从不深入技术细节来看,上面的模式很好。有事情就干活,没事情就休眠。但是如果考虑到两执行路径(线程)的速度匹配问题后,这个问题就没那么简单了。
我们假设一个情景:A线程生产者,B线程消费者。
如果从A-->B只有一块缓冲区来传递数据的话,那么A、B都需要对该缓冲区做互斥访问,因为一旦一方占用这块缓冲区,另一方的直接操作会导致前面那个人拿出来或丢进去的数据的一致性失效。所以最坏的情况是:一方需要等待另一方“操作缓冲区的最大时间”。
不过,如果A、B两者操作缓冲区的速度是匹配的(固定不变的)这样的话可以使用但缓冲区模型。如果A、B两个有一段时间一个快,一个慢的话会出现丢帧情况。那么,需要使用下面描述的模型。
从A-->B传递数据需要多个缓冲区支持(动态增删),这样做的好处是每块缓冲区都有可读/可写属性配置,一旦A速度出现尖峰效应“多缓冲区”机制可以及时将A的瞬时数据缓冲起来并对应到相应的缓冲区且更新缓冲区属性值,同样B可以连续地读取拥有可读属性的缓冲区并设置为可写属性。
在分析具体代码之前,先看下ping pong buff逻辑结构
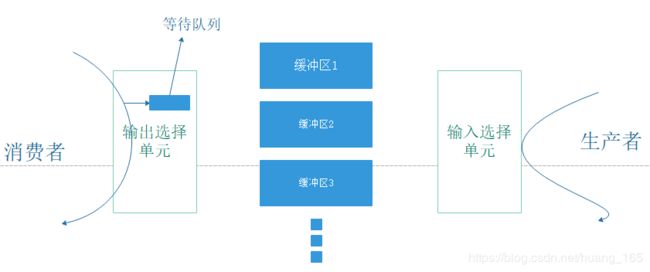
图示可以得知,构造ping pong buff逻辑结构需要三部分:输入选择单元、缓冲区、输出选择单元。
A生产者先要从输出选择单元枚举一个可写缓冲区,然后才可以将buff写进去并更新该缓冲区属性、唤醒阻塞在输出选择单元里的消费者线程。
B消费者从输出选择单元唤醒并获得一个可读缓冲区,然后才可以将缓冲区内容读出并更新该缓冲区属性、合适时候再进入输出选择单元模块。
好了,框架化地了解ping pong buff,下面请看关键代码,完整代码请从前面贴出github 链接下载。
B消费者逻辑:分为输出选择单元、用于阻塞的等待队列、更新缓冲区属性。
/* return valule: bytes have read, or goto pthread_cond_wait if not read enable */
uint32_t read_from_pingpong_buf(struct pingpong_buffer *pp_buf, const uint32_t count)
{
uint32_t ret = 0;
uint32_t len;
struct buff_str *buf;
if (pp_buf->read_switch) {
pp_buf->current_read = pp_buf->current_read->next_buf_addr;
pp_buf->read_switch = 0;
}
buf = pp_buf->current_read;
pthread_mutex_lock(&read_mutex_lock);
while(!buf->read_enable) {
printf("read wait by %d......\n", buf->index);
pthread_cond_wait(&read_condition, &read_mutex_lock);
}
pthread_mutex_unlock(&read_mutex_lock);
len = min(count, buf->length - buf->offset);
printf("\n******************** read from :%d************************", buf->index);
/* instead read() for test */
print_mem(buf->addr, len, 1);
ret = len;
buf->offset += ret;
pthread_mutex_lock(&read_mutex_lock);
/* get to the buffer end, switch to next buffer */
if(buf->offset == buf->length) { //当offset到达length处时该可读buff已经读完
buf->read_enable = 0;
buf->offset = 0;
pp_buf->read_switch = 1;
}
pthread_mutex_unlock(&read_mutex_lock);
return ret;
}A生产者逻辑:分为输入选择单元、更新缓冲区属性。
uint32_t write_to_pingpong_buf(struct pingpong_buffer *pp_buf, const uint32_t count)
{
struct buff_str *buf;
if (pp_buf->write_switch) {
pp_buf->current_write = pp_buf->current_write->next_buf_addr;
pp_buf->write_switch = 0;
}
buf = pp_buf->current_write;
printf("\n******************** write to :%d************************\n", buf->index);
/* use memset instead write operations for test */
memset(buf->addr, fill_data, BUF_LEN);
fill_data++;
/* when write finished, enable write */
pthread_mutex_lock(&read_mutex_lock);
buf->read_enable = 1;
pp_buf->write_switch = 1;
pthread_mutex_unlock(&read_mutex_lock);
pthread_cond_broadcast(&read_condition); //唤醒阻塞在读等待队列的读线程,要用广播不然部分读线程不能出来
return BUF_LEN;
}需要注意的是,由于缓冲区固定只有三个,生产者消费者线程都是可以回卷的,当消费者很慢时,生产者会主动回卷且一圈下来消费者还没来得及消费的话,之前生产者的数据会丢掉。所以,可以实现一个缓冲区动态增删机制,当生产者很快时系统主动申请若干缓冲区来支撑,当生产者速度下来时,主动将部分冗余缓冲区删除掉。有兴趣的小伙伴可以下载我的源码进行适配。