01-Flink安装部署及入门案例(仅供学习),音视频时代你还不会NDK开发
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
[root@node1 ~]# cd /export/software/
[root@node1 software]# rz
上传软件包:flink-1.13.1-bin-scala_2.11.tgz
[root@node1 software]# chmod u+x flink-1.13.1-bin-scala_2.11.tgz
[root@node1 software]# tar -zxf flink-1.13.1-bin-scala_2.11.tgz -C /export/server/
[root@node1 ~]# cd /export/server/
[root@node1 server]# chown -R root:root flink-1.13.1
[root@node1 server]# mv flink-1.13.1 flink-standalone
2)、修改flink-conf.yaml
vim /export/server/flink-standalone/conf/flink-conf.yaml
修改内容:33行内容
jobmanager.rpc.address: node1
3)、修改masters
vim /export/server/flink-standalone/conf/masters
修改内容:
node1:8081
4)、修改workers
vim /export/server/flink-standalone/conf/workers
修改内容:
node1
node2
node3
5)、添加HADOOP\_CONF\_DIR环境变量(集群所有机器)
vim /etc/profile
添加内容:
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
执行生效
source /etc/profile
6)、将Flink依赖Hadoop 框架JAR包上传至/export/server/flink-standalone/lib目录

[root@node1 ~]# cd /export/server/flink-standalone/lib/
[root@node1 lib]# rz
commons-cli-1.4.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.1.0-327-9.0.jar
7)、分发到集群其他机器
scp -r /export/server/flink-standalone root@node2:/export/server
scp -r /export/server/flink-standalone root@node3:/export/server
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
接下来,启动服务进程,运行批处理程序:词频统计WordCount。
1)、启动HDFS集群,在node1上执行如下命令
start-dfs.sh
2)、启动集群,执行如下命令
一键启动所有服务JobManager和TaskManagers
[root@node1 ~]# /export/server/flink-standalone/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node1.
Starting taskexecutor daemon on host node1.
Starting taskexecutor daemon on host node2.
Starting taskexecutor daemon on host node3.
3)、访问Flink UI界面:http://node1:8081/#/overview
4)、执行官方测试案例
准备测试数据
[root@node1 ~]# hdfs dfs -mkdir -p /wordcount/input/
[root@node1 ~]# hdfs dfs -put /root/words.txt /wordcount/input/

运行程序,使用–input指定处理数据文件路径
/export/server/flink-standalone/bin/flink run
/export/server/flink-standalone/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input/words.txt

使用–output指定处理结果数据存储目录
/export/server/flink-standalone/bin/flink run
/export/server/flink-standalone/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input/words.txt
–output hdfs://node1:8020/wordcount/output/result
[root@node1 ~]# hdfs dfs -text /wordcount/output/result

5)、关闭Standalone集群服务
一键停止所有服务JobManager和TaskManagers
[root@node1 ~]# /export/server/flink-standalone/bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 6600) on host node1.
Stopping taskexecutor daemon (pid: 3016) on host node2.
Stopping taskexecutor daemon (pid: 3034) on host node3.
Stopping standalonesession daemon (pid: 6295) on host node1.
**补充**:Flink Standalone集群启动与停止,也可以逐一服务启动
每个服务单独启动
在node1上启动
/export/server/flink-standalone/bin/jobmanager.sh start
在node1、node2、node3.
/export/server/flink-standalone/bin/taskmanager.sh start # 每台机器执行
===============================================================
每个服务单独停止
在node1上停止
/export/server/flink-standalone/bin/jobmanager.sh stop
在node1、node2、node3
/export/server/flink-standalone/bin/taskmanager.sh stop
#### 07-安装部署之Standalone HA
从Standalone架构图中,可发现JobManager存在`单点故障(SPOF`),一旦JobManager出现意外,整个集群无法工作。为了确保集群的高可用,需要搭建Flink的Standalone HA。
Flink Standalone HA集群,类似YARN HA 集群安装部署,可以启动多个主机点JobManager,使用Zookeeper集群监控JobManagers转态,进行选举leader,实现自动故障转移。
 在 Zookeeper 的协助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中\*\*只有一个处于Active工作状态,其他处于 Standby 状态。\*\*当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
1)、集群规划

在node1上复制一份standalone
[root@node1 ~]# cd /export/server/
[root@node1 server]# cp -r flink-standalone flink-ha
删除日志文件
[root@node1 ~]# rm -rf /export/server/flink-ha/log/*
2)、启动ZooKeeper,在node1上启动
start-zk.sh
3)、启动HDFS,在node1上启动,如果没有关闭,不用重启
start-dfs.sh
4)、停止集群,在node1操作,进行HA高可用配置
/export/server/flink-standalone/bin/stop-cluster.sh
5)、修改flink-conf.yaml,在node1操作
vim /export/server/flink-ha/conf/flink-conf.yaml
修改内容:
jobmanager.rpc.address: node1
high-availability: zookeeper
high-availability.storageDir: hdfs://node1:8020/flink/ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_standalone
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://node1:8020/flink/checkpoints
state.savepoints.dir: hdfs://node1:8020/flink/savepoints
6)、修改masters,在node1操作
vim /export/server/flink-ha/conf/masters
修改内容:
node1:8081
node2:8081
7)、分发到集群其他机器,在node1操作
scp -r /export/server/flink-ha root@node2:/export/server/
scp -r /export/server/flink-ha root@node3:/export/server/
8)、修改node2上的flink-conf.yaml
[root@node2 ~]# vim /export/server/flink-ha/conf/flink-conf.yaml
修改内容:33 行
jobmanager.rpc.address: node2
9)、重新启动Flink集群
node1和node2上执行
/export/server/flink-ha/bin/jobmanager.sh start
node1和node2、node3执行
/export/server/flink-ha/bin/taskmanager.sh start # 每台机器执行

#### 08-Flink on YARN之运行流程
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的Workload,因此 Flink 也支持在 Yarn 集群运行。
>
> 为什么使用`Flink on Yarn或Spark on Yarn?`
>
>
>
* 1)、Yarn的资源可以按需使用,提高集群的资源利用率
* 2)、Yarn的任务有优先级,根据优先级运行作业
* 3)、基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
`当应用程序(MR、Spark、Flink)运行在YARN集群上时,可以实现容灾恢复。`
#### 09-Flink on YARN之安装部署
Flink on YARN安装配置,此处考虑高可用HA配置,集群机器安装软件框架示意图:
1)、关闭YARN的内存检查(`node1`操作)
yarn-site.xml中添加配置
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
添加如下内容:
2)、 配置Application最大的尝试次数(`node1`操作)
yarn-site.xml中添加配置
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
添加如下内容:
3)、同步yarn-site.xml配置文件(`node1`操作)
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml root@node2: P W D s c p − r y a r n − s i t e . x m l r o o t @ n o d e 3 : PWD scp -r yarn-site.xml root@node3: PWDscp−ryarn−site.xmlroot@node3:PWD
4)、启动HDFS集群和YARN集群(`node1`操作)
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh
5)、添加`HADOOP_CONF_DIR`环境变量(**集群所有机器**)
添加环境变量
vim /etc/profile
添加内容:
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
环境变量生效
source /etc/profile
6)、上传软件及解压(`node1`操作)
[root@node1 ~]# cd /export/software/
[root@node1 software]# rz
上传软件包:flink-1.13.1-bin-scala_2.11.tgz
[root@node1 software]# chmod u+x flink-1.13.1-bin-scala_2.11.tgz
[root@node1 software]# tar -zxf flink-1.13.1-bin-scala_2.11.tgz -C /export/server/
[root@node1 ~]# cd /export/server/
[root@node1 server]# chown -R root:root flink-1.13.1
[root@node1 server]# mv flink-1.13.1 flink-yarn
7)、将Flink依赖Hadoop 框架JAR包上传至`/export/server/flink-yarn/lib`目录

[root@node1 ~]# cd /export/server/flink-yarn/lib/
[root@node1 lib]# rz
commons-cli-1.4.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.1.0-327-9.0.jar
8)、配置HA高可用,依赖Zookeeper及重试次数(`node1`操作)
修改配置文件
vim /export/server/flink-yarn/conf/flink-conf.yaml
添加如下内容:
high-availability: zookeeper
high-availability.storageDir: hdfs://node1:8020/flink/yarn-ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
high-availability.zookeeper.path.root: /flink-yarn-ha
high-availability.cluster-id: /cluster_yarn
yarn.application-attempts: 10
9)、集群所有机器,同步分发Flink 安装包,便于任意机器提交运行Flink Job。
scp -r /export/server/flink-yarn root@node2:/export/server/
scp -r /export/server/flink-yarn root@node3:/export/server/
10)、启动Zookeeper集群(`node1`操作)
start-zk.sh
在Flink中执行应用有如下三种部署模式(Deployment Mode):

* 无论JobManager还是TaskManager,都是运行NodeManager Contanier容器中,以JVM 进程方式运行;
* 提交每个Flink Job执行时,找的就是JobManager(**AppMaster**),找运行在YARN上应用ID;
Session 会话模式:arn-session.sh(开辟资源) + flink run(提交任务)
* 第一、Hadoop YARN 运行Flink 集群,开辟资源,使用:yarn-session.sh
+ 在NodeManager上,启动容器Container运行JobManager和TaskManagers
* 第二、提交Flink Job执行,使用:flink run
准备测试数据,测试运行批处理词频统计WordCount程序
[root@node1 ~]# vim /root/words.txt
添加数据
spark python spark hive spark hive
python spark hive spark python
mapreduce spark hadoop hdfs hadoop spark
hive mapreduce
数据文件上传
[root@node1 ~]# hdfs dfs -mkdir -p /wordcount/input/
[root@node1 ~]# hdfs dfs -put /root/words.txt /wordcount/input/

* 第一步、在yarn上启动一个Flink会话,node1上执行以下命令
export HADOOP_CLASSPATH=hadoop classpath
/export/server/flink-yarn/bin/yarn-session.sh -d -jm 1024 -tm 1024 -s 2
参数说明
-d:后台执行
-s: 每个TaskManager的slot数量
-jm:JobManager的内存(单位MB)
-tm:每个TaskManager容器的内存(默认值:MB)
提交flink 集群运行yarn后,提示信息
JobManager Web Interface: http://node1:44263
…
$ echo “stop” | ./bin/yarn-session.sh -id application_1633441564219_0001
If this should not be possible, then you can also kill Flink via YARN’s web interface or via:
$ yarn application -kill application_1633441564219_0001
* 第二步、查看UI界面,http://node1:8088/cluster/apps
 JobManager提供WEB UI:http://node1:8088/proxy/application\_1614756061094\_0002/#/overview

此时,没有任何TaskManager运行在容器Container中,需要等待有Flink Job提交执行时,才运行TaskManager。
* 第三步、使用flink run提交任务
/export/server/flink-yarn/bin/flink run
-t yarn-session
-Dyarn.application.id=application_1652168669227_0001
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input/words.txt

* 第四步、通过上方的ApplicationMaster可以进入Flink的管理界面

* 第五步、关闭yarn-session
优雅 停止应用,如果设置重启次数,即使停止应用,也会重启,一直到超过次数以后,才能真正停止应用
echo “stop” | /export/server/flink-yarn/bin/yarn-session.sh -id application_1633441564219_0001
kill 命令,直接将运行在yarn应用杀死,毫不留情
yarn application -kill application_1633441564219_0001
#### 11-Flink on YARN之PerJob模式运行
每个Flink Job提交运行到Hadoop YARN集群时,根据自身的情况,单独向YARN申请资源,直到作业执行完成

在Hadoop YARN中,每次提交job都会创建一个新的Flink集群,任务之间相互独立,互不影响并且方便管理。任务执行完成之后创建的集群也会消失。
采用Job分离模式,**每个Flink Job运行,都会申请资源,运行属于自己的Flink 集群**。
* 第一步、直接提交job
export HADOOP_CLASSPATH=hadoop classpath
/export/server/flink-yarn/bin/flink run
-t yarn-per-job -m yarn-cluster
-yjm 1024 -ytm 1024 -ys 1
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input
参数说明
-m:指定需要连接的jobmanager(主节点)地址,指定为 yarn-cluster,启动一个新的yarn-session
-yjm:JobManager可用内存,单位兆
-ytm:每个TM所在的Container可申请多少内存,单位兆
-ys:每个TM会有多少个Slot
-yd:分离模式(后台运行,不指定-yd, 终端会卡在提交的页面上)

* 第二步、查看UI界面:http://node1:8088/cluster

提交Flink Job在Hadoop YARN执行时,最后给出如下错误警告:

解决办法: 在 flink 配置文件里 flink-conf.yaml设置
classloader.check-leaked-classloader: false
#### 12-Flink on YARN之Application模式运行
**Flink 1.11** 引入了一种新的部署模式,即 **Application** 模式,目前可以支持基于 Hadoop YARN 和 Kubernetes 的 Application 模式。
1、Session 模式:
所有作业Job共享1个集群资源,隔离性差,JM 负载瓶颈,每个Job中main 方法在客户端执行。
2、Per-Job 模式:
每个作业单独启动1个集群,隔离性好,JM 负载均衡,Job作业main 方法在客户端执行。
 以上两种模式,main方法都是在客户端执行,需要**获取 flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行**,那么将会给服务器造成很大的压力。此外,提交任务的时候会**把本地flink的所有jar包先上传到hdfs上相应的临时目录**,带来大量的网络的开销,所以如果任务特别多的情况下,平台的吞吐量将会直线下降。
>
> Application 模式下,用户程序的 main 方法将在集群中运行,用户**将程序逻辑和依赖打包进一个可执行的 jar 包里**,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。
> 
>
>
>
**Application 模式为每个提交的应用程序创建一个集群,并在应用程序完成时终止**。Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 m**ain** 可以[节省所需的 CPU 周期],还可以[节省本地下载依赖项所需的带宽]。
Application 模式==使用 bin/flink run-application提交作业,本质上是Session和Per-Job模式的折衷。
* 通过 **-t** 指定部署环境,目前支持部署在 yarn 上(-t yarn-application) 和 k8s 上(-t kubernetes-application);
* 通过 **-D** 参数指定通用的运行配置,比如 jobmanager/taskmanager 内存、checkpoint 时间间隔等。
export HADOOP_CLASSPATH=hadoop classpath
/export/server/flink-yarn/bin/flink run-application
-t yarn-application
-Djobmanager.memory.process.size=1024m
-Dtaskmanager.memory.process.size=1024m
-Dtaskmanager.numberOfTaskSlots=1
/export/server/flink-yarn/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/input
由于MAIN方法在JobManager(也就是NodeManager的容器Container)中执行,当Flink Job执行完成以后,启动`MRJobHistoryServer`历史服务器,查看AppMaster日志信息。
node1 上启动历史服务
[root@node1 ~]# mr-jobhistory-daemon.sh start historyserver
第二步、查看UI界面:http://node1:8088/cluster

测试Flink Job不同运行模式时,注意事项如下

### 第三部分:Flink入门案例
#### 13-Flink入门案例之编程模型
基于Flink计算引擎,分别实现批处理(Batch)和流计算(Streaming )中:词频统计WordCount。
第一点:Flink API== ,提供四个层次API,越在下面API,越复杂和灵活;越在上面API,使用越简单和抽象

第二点:编程模型==,无论编写批处理还是流计算程序,分为三个部分:Data Source、Transformations和Data Sink
第一步、从数据源DataSource获取数据
流计算:DataStream
批处理:DataSet
第二步、对数据进行转换处理
第三步、结果数据输出DataSink
无论批处理Batch,还是流计算Stream,首先需要创建`执行环境ExecutionEnvironment对象`,类似Spark中`SparkSession`或者`SparkContext`。

创建整个Flink基础课程Maven Project,设置MAVEN Repository仓库目录及Maven安装目录

约定:每天创建一个Maven Module](),创建第1天Maven Module,模块结构:

POM文件添加如下内容:
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
central_maven
central maven
https://repo1.maven.org/maven2
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
apache.snapshots
Apache Development Snapshot Repository
https://repository.apache.org/content/repositories/snapshots/
false
true
org.apache.flink
flink-java
1.13.1
org.apache.flink
flink-streaming-java_2.11
1.13.1
org.apache.flink
flink-clients_2.11
1.13.1
org.apache.flink
flink-runtime-web_2.11
1.13.1
org.slf4j
slf4j-api
1.7.7
runtime
org.slf4j
slf4j-log4j12
1.7.7
runtime
log4j
log4j
1.2.17
runtime
src/main/java
src/test/java
org.apache.maven.plugins
maven-compiler-plugin
3.5.1
1.8
1.8
org.apache.maven.plugins
maven-surefire-plugin
2.18.1
false
true
**/*Test.*
**/*Suite.*
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
*:*
META-INF/.SF
META-INF/.DSA
META-INF/*.RSA
日志配置文件:`log4j.properties`
This affects logging for both user code and Flink
log4j.rootLogger=INFO, console
Uncomment this if you want to only change Flink’s logging
#log4j.logger.org.apache.flink=INFO
The following lines keep the log level of common libraries/connectors on
log level INFO. The root logger does not override this. You have to manually
change the log levels here.
log4j.logger.akka=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.hadoop=INFO
log4j.logger.org.apache.zookeeper=INFO
Log all infos to the console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
Suppress the irrelevant (wrong) warnings from the Netty channel handler
log4j.logger.org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, console
#### 14-Flink入门案例之WordCount【批处理】
首先,基于Flink计算引擎,[实现离线批处理Batch:从文本文件读取数据,词频统计]。

批处理时词频统计思路如下伪代码所示:
spark flink flink flink spark
|
| flatMap
|
3-1. 分割单词 spark, flink, flink, flink, spark
|
| map
|
3-2. 转换二元组 (spark, 1) (flink, 1) (flink, 1) (flink, 1) (spark, 1)
|
| groupBy(0)
|
3-3. 按照单词分组
spark -> [(spark, 1) (spark, 1)]
flink -> [(flink, 1) (flink, 1) (flink, 1) ]
|
|sum(1)
|
3-4. 组内数据求和,第二元素值累加
spark -> 1 + 1 = 2
flink -> 1 + 1 + 1 =3
基于Flink编写批处理或流计算程序步骤如下:(5个步骤)
1.执行环境-env
2.数据源-source
3.数据转换-transformation
4.数据接收器-sink
5.触发执行-execute
编写批处理词频统计:`BatchWordCount`,创建Java类
package cn.itqzd.flink.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 使用Flink计算引擎实现离线批处理:词频统计WordCount
* 1.执行环境-env
* 2.数据源-source
* 3.数据转换-transformation
* 4.数据接收器-sink
* 5.触发执行-execute
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1.执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment() ;
// 2.数据源-source
DataSource inputDataSet = env.readTextFile("datas/words.txt");
// 3.数据转换-transformation
/\*
spark flink spark hbase spark
|flatMap
分割单词: spark, flink, spark
|map
转换二元组:(spark, 1) (flink, 1) (spark, 1), TODO:Flink Java API中提供元组类Tuple
|groupBy(0)
分组:spark -> [(spark, 1), (spark, 1)] flink -> [(flink, 1)]
|sum(1)
求和:spark -> 1 + 1 = 2, flink = 1
*/
// 3-1. 分割单词
FlatMapOperator
@Override
public void flatMap(String line, Collector out) throws Exception {
String[] words = line.trim().split(“\s+”);
for (String word : words) {
out.collect(word);
}
}
});
// 3-2. 转换二元组
MapOperator> tupleDataSet = wordDataSet.map(new MapFunction>() {
@Override
public Tuple2 map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 3-3. 分组及求和, TODO: 当数据类型为元组时,可以使用下标指定元素,从0开始
AggregateOperator> resultDataSet = tupleDataSet.groupBy(0).sum(1);
// 4.数据接收器-sink
resultDataSet.print();
// 5.触发执行-execute, TODO:批处理时,无需触发,流计算必须触发执行
//env.execute("BatchWordCount") ;
}
}
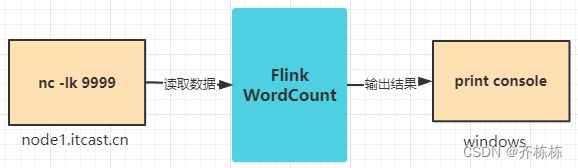
#### 15-Flink入门案例之WordCount【流计算】
编写Flink程序,**接收TCP Socket的单词数据,并以空格进行单词拆分,分组统计单词个数**。

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
for (String word : words) {
out.collect(word);
}
}
});
// 3-2. 转换二元组
MapOperator> tupleDataSet = wordDataSet.map(new MapFunction>() {
@Override
public Tuple2 map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 3-3. 分组及求和, TODO: 当数据类型为元组时,可以使用下标指定元素,从0开始
AggregateOperator> resultDataSet = tupleDataSet.groupBy(0).sum(1);
// 4.数据接收器-sink
resultDataSet.print();
// 5.触发执行-execute, TODO:批处理时,无需触发,流计算必须触发执行
//env.execute("BatchWordCount") ;
}
}
15-Flink入门案例之WordCount【流计算】
编写Flink程序,接收TCP Socket的单词数据,并以空格进行单词拆分,分组统计单词个数。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-ZhXIfxxu-1713686082819)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!