Mysql第四章:mysql语法练习
目录
1:mysql常用语法练习
2:查询语句(select)
3:排序语句(order by)
4:单一过滤语句(where)
5:组合条件过滤语句(where + 操作符)
6:通配符过滤语句(like)
7:字段拼接求和
8:数据处理函数
9:汇总函数(avg max min count)
10:数据分组(group by having)
11:子查询
12:连接查询
13:视图 (视图不包含数据,修改表数据,视图也会改变)
13.1:为什么使用视图
13.2:创建视图
14:存储过程
14.1:什么是存储过程
14.2:存储过程的优缺点
14.3:案例示范
15:触发器
15.1:什么是触发器
15.2:使用案例
16:事务
1:mysql常用语法练习
首先默认表数据如下:
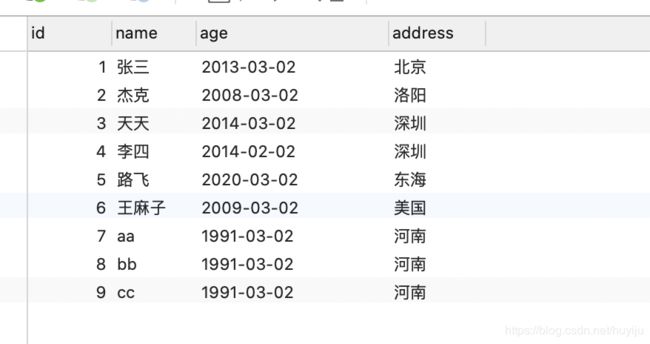
2:查询语句(select)
select * from user //查询所有数据
select name,age from user //查询指定字段
select distinct address from user// 由于地址信息有深圳,河南相同。查询结果为去重复
select * from user LIMIT 3,2 //从第3行开始查询2条数据。 查询结果是id是4,5的数据3:排序语句(order by)
select * from user ORDER BY age //默认asc是a-z 数字1-9 升序,此处显示结果是1991-2020
select * from user ORDER BY age desc//desc是z-a,9-1 降序 此处显示结果是2020-1991
select * from user ORDER BY age desc,name //首先age降序2020-1991,然后name升序a-z4:单一过滤语句(where)
//单一条件过滤语句
select * from user where name='bb' //等于
select * from user where age='2013-03-02'//等于
select * from user where name <> 'bb' // 不等于 查询名字不等于bb的数据
select * from user where name != 'bb' // 不等于 查询名字不等于bb的数据
select * from user where age >'2013-03-02' //大于 适用于日期和数值类型
select * from user where age >='2013-03-02' //大于等于 适用于日期和数值类型
select * from user where age <'2013-03-02' //小于 适用于日期和数值类型
select * from user where age <='2013-03-02' //小于等于 适用于日期和数值类型
select * from user where age BETWEEN '2013-03-02' AND '2020-03-02'//介于两者之间
select * from user where age is null //空值判断
select * from user where age is not null //非空判断5:组合条件过滤语句(where + 操作符)
//组合条件过滤
select * from user where name='bb' and address='河南' //and 两个条件都需套满足
select * from user where name='bb' OR address='深圳' //or 条件只需满足一个即可
select * from user where (address='河南' or address='深圳') and name='bb'//and运算优先级高和or混用的时候要加括号
select * from user where name in ('bb','cc','李四')//in操作符,与or操作符一致
select * from user where name not in ('bb','cc','李四') //not in操作符,与in相反6:通配符过滤语句(like)
//通配符过滤(通配符效率比较低 尽量不用在开始的位置)
select * from user where address LIKE '%南%' //包含有南的地址信息
select * from user where address like '河%1' //以河开始 1结束的地址信息7:字段拼接求和
//拼接字段
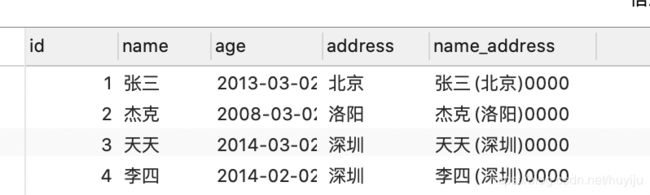
select *,CONCAT(name,'(',address,')','0000') as name_address from user //CONCAT函数用来拼接字段name(address)0000,并且将字段别名为name_address
//查询所有的字段和sid*score 并且命名为求和
select *,sid*score as 求和 from score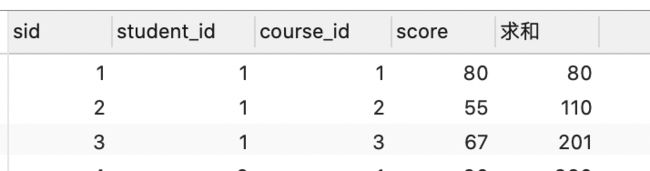
8:数据处理函数
//数据处理函数
select *,UPPER(name) as 大写 from user where address ='河南' //字段转大写
select *,LOWER(name) as 小写 from user where address ='河南' //字段转小写
select *,LEFT(name,3) from user //字段截取3位
//日期处理函数
select * from user where age='1991-03-02'
select * from user where DATE(age)='1991-03-02'//匹配年月日
select * from user where YEAR(age) BETWEEN '1991' and '2010' //匹配年
select * from user where MONTH(age)='03' //匹配月
select * from user where DAY(age)='02' //匹配日
9:汇总函数(avg max min count)
select * from score
select AVG(score) from score where student_id=1 //学号1的学生的平均分
select MAX(score) from score where student_id=1 //学好1的学生的最高分
select MIN(score) from score where student_id=1 //学好1的学生的最低分
select COUNT(*) from score //查询行数,所有行 跟count(1)差不多
select COUNT(1) from score //查询行数,所有行 使用到主键索引 比较快
select COUNT(score) from score //查询行数 忽略字段为null的行 该列没有索引会比较慢10:数据分组(group by having)
//group by数据分组 having过滤分组
select student_id,AVG(score),MAX(score),MIN(score) from score GROUP BY student_id HAVING AVG(score)>60
11:子查询
//子查询,查询结果是其他查询的条件,查询学生表的学生id,根据学生id查询分数
select * from score where student_id in (select sid from students)12:连接查询
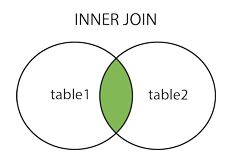
select * from a JOIN b on a.id=b.a_id //内链接(JOIN) 交集
select * from a INNER JOIN b on a.id=b.a_id //内链接(inner join) 交集
select * from a LEFT JOIN b on a.id=b.a_id //左链接 左边查询全部数据,关联右边
select * from a RIGHT JOIN b on a.id=b.a_id//右连接 右边查询全部数据,关联左边
select id from a
UNION
select address from b
//UNION求并集 除虫重复
select id from a
UNION all
select address from b
//UNION all求并集 不去重复
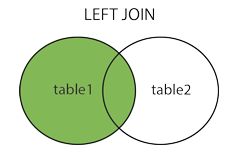
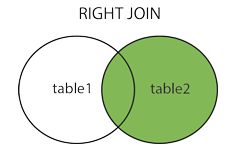
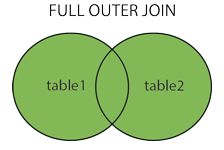
13:视图 (视图不包含数据,修改表数据,视图也会改变)
13.1:为什么使用视图
1:重用复杂的sql,便于运维
2:使用表的部分组成字段而不是全部的sql,使用表的一部分
3:保护数据,通过视图访问部分数据,而不是直接查询所有的表。
写了一个很复杂的sql查询出来了结果,这些结果是很多各表
13.2:创建视图
//创建视图,将表b中的address和a_id抽取出来构成视图。
select * from b
CREATE VIEW view1 as
select address,a_id from b
select * from view1//查询视图
UPDATE view1 SET address='update' where address='view'//修改视图
14:存储过程
14.1:什么是存储过程
存储过程是sql的封装,将复杂的sql封装成一个方法,可以有输入和输出参数,给外部调用。实现较为复杂的逻辑。
14.2:存储过程的优缺点
优点:
1:性能高:将不同的sql封装,比单条sql执行效率高,连接多次数据库。只需连接数据库一次,存储过程在创建的时候直接编译,而sql语句每次使用都要编译,提高执行效率
2:简单:复杂的sql封装,只管调用。外部简单,类似于java的方法封装一样
缺点:
1:对于专业技能姚要求高,简单的sql不必要封装成为存储过程,复杂的才需要,所以对于技术要求高
2:移植能力较差,维护麻烦
14.3:案例示范
--1:创建存储过程PROCEDURE1
CREATE PROCEDURE PROCEDURE1()
BEGIN
select * FROM students;
END;
--2:创建存储过程PROCEDURE2
--这里先解释一下delimiter //是什么意思
--mysql客户端中分隔符默认是分号(;),所以如果不指定一个特殊的分隔符,可能会编译失败
--上面语句将分隔符改为//,直到遇到下一个//才表示语句结束,这样可以保证创建语句完整。
delimiter //
CREATE PROCEDURE PROCEDURE2()
BEGIN
select * FROM students;
END//
delimiter ;
--3:调用存储过程procedure1
CALL procedure1
--4:调用存储过程procedure2
CALL procedure2
--5:创建含有参数和返回值的存储过程
CREATE PROCEDURE PROCEDURE2(
OUT a DECIMAL(8,2), #输出参数 (out 参数名字 参数类型)
OUT b DECIMAL(8,2), #输出参数 (out 参数名字 参数类型)
OUT c DECIMAL(8,2), #输出参数 (out 参数名字 参数类型)
in d INT #输入参数 (in 参数名字 参数类型)
)
BEGIN
select avg(score) INTO a #into 绑定输出参数
from score where student_id=d #直接饮用输入参数d
GROUP BY student_id;
select max(score) INTO b #into 绑定输出参数
from score where student_id=d #直接饮用输入参数d
GROUP BY student_id;
select min(score) INTO c #into 绑定输出参数
from score where student_id=d #直接饮用输入参数d
GROUP BY student_id;
END;
//调用含有输入输出参数的存储过程
call PROCEDURE2(@a,@b,@c,3);
//查询结果集
SELECT @a,@b,@c
--6:删除存储过程
drop PROCEDURE PROCEDURE2
15:触发器
15.1:什么是触发器
触发器主要是来监控表的,当表中的数据发生变化的时候,update,delete,insert的时候,自动触发触发器。
触发器的特点:
1:触发器名字唯一(每个表最多有6个触发器,在增删改*2=6)
2:触发器是监控指定的表,跟表关联(视图和临时表不支持触发器)
3:触发器监控update,delete,insert操作
4:触发器分为在操作之前和之后执行

15.2:使用案例
#触发器t2 监控a表,在a表删除数据之前,在b表添加两条数据
CREATE TRIGGER t2 AFTER DELETE on a
FOR EACH ROW
BEGIN
INSERT INTO b (address,a_id) VALUES ('删除数据触发器1',111);
INSERT INTO b (address,a_id) VALUES ('删除数据触发器2',111);
END16:事务
START TRANSACTION;#开启事务
select * from a;
DELETE from a where id=1;
select * from a;
ROLLBACK;#回滚事务
START TRANSACTION ;#开启事务
select * from a;
DELETE from a where id=1;
select * from a;
COMMIT; #提交事务