分布式日志分析系统构建实战(三)——Kafka
介绍
生产者-消费者模型是系统架构中最常用的一种模型了,它在对于降低耦合度方面有着极大的作用。而一条消息从生产者出发到被消费者接受的过程中,是由消息队列来管理的。而消息队列就是用来对消息进行存储和分配,在多个生产者和消费者同时工作时,还要考虑读写冲突等线程安全问题。所以说,消息队列对于生产者-消费者模型的稳定性和可靠性方面起着至关重要的作用。对于这样一种经典的模型,消息队列的开源框架自然不在少数,例如经典的RabbitMQ和ActiveMQ,它们都在长期的实践运用中证明了自己的价值。
Kafka本质上也属于一个消息队列,但是设计初衷是作为轻量级,高吞吐的日志处理系统。因此与传统的消息队列存在一定的差异。
- 结构简单。Kafka只是按照传统意义上的MQ结构,定义了生产者(producer),消费者(consumer)和集群(broker)的概念,并没有像RabbitMQ等遵从AMQP协议。而且kafka的消息队列并不对生产者和消费者进行管理,全由两端各自进行各自的管理功能。Kafka提供的生产者和消费者以及其他第三方提供的生产者消费者,基本都是通过ZooKeeper来对自身信息进行记录管理的。
- 高吞吐量。Kafka的所有信息是按照接受到的时间进行顺序存储的。在消费者订阅接受信息的时候,也是按照指定的时间节点来顺序读取。因此,kafka通过这种数组式的存储方式,实现了O(1)的读写速度。
- 批量式订阅。许多MQ的消息在被订阅接受后就默认剔除了,这也是为什么大部分MQ需要做消息确认机制,不然无法应对消息传递失败的情形。而Kafka的消息则是持久性的存储起来,多个订阅者之间相互不干扰,都可以从任意时间点进行读取。因此,当消息传递失败时,订阅者可以自己返回上次时间点,再次接受消息。这样一来,又进一步提高了Kafka的吞吐量。同时,对于分布式系统来说,也提高了并行的效率。
Kafka
Kafka由生产者,消费者和集群构成。其中,在集群中,是通过Zookeeper来进行相互协作的。而其提供的生产者和消费者实现中,也是由ZooKeeper来交互并保存状态信息。结构如下图所示:
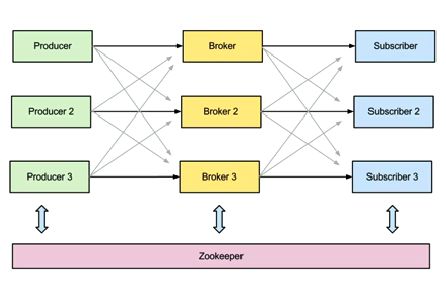
在Kafka中,消息是按照Topic这个概念来进行分类的。不论生产还是订阅消息的时候,都要定义好Topic,而读写的消息也只会针对这个Topic。
为了利用分布式系统,实现负载均衡,对于每个Topic又定义了partition的概念。顾名思义,partition就是将一组topic的消息分成多个组进行存储。这些partition会存放在不同的server上,从而避免某一个server存放了过多的消息。而对于消息分配到哪一个partition,则是由生产者来定义的。而生产者可以通过实现round-robin等方式来设定一个消息所对应的分区,当然,糟糕的生产者也可以破坏这一平衡。
在可靠性方面,kafka提供了replication选项来对消息进行备份,备份的对象是每一个partition。有意思的是,备份并不是强制的,备份的数量也是可控的,使用者可以根据业务需求和服务器的存储空间来决定这些参数。
可以看出,Kafka相对于其他成熟的MQ来说,有许多功能尚不具备。例如,kafka并没有提供JMS中的”事务性”“消息确认机制”“消息分组”等企业级特性。但是,Kafka的高吞吐量特性非常适合于类似日志处理等高速生产和消费的业务。同时,在并行化方面,kafka的批量式订阅也能提供很多方便的操作。总而言之,如果业务功能相对简单,且对少量的消息丢失可以容忍的情况下,kafka还是非常适合的。
配置
kafka本身不存在任何安装过程,下载好release版本并解压后,就可以直接通过bin文件夹下的脚本进行操作了。下载地址可以从这个网址获取:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
其中,config/server.properties给出了一个集群配置信息的示例,对于一些常用选项也进行了注释。其中,比较重要的属性有broker.id,listeners,zookeeper.connect,log.dirs等。其中,broker.id表示当前server的id;listener用来定义当前server绑定的端口;zookeeper.connect是用来定义zookeeper的信息,如果之前zookeeper的默认端口没改且安装在本机,zookeeper.connect也可以保持默认。
如果想要在一台机器上开启多个集群进程,实现本机分布式的效果,可以定义多个server.properties。只需要保持broker.id和listner端口唯一就可以了。一下命令就开启了三个kafka进程:
bin/kafka-server-start.sh config/server.properties > log/server0.log 2>&1 & # port 9092
bin/kafka-server-start.sh config/server-1.properties > log/server1.log 2>&1 & # port 9093
bin/kafka-server-start.sh config/server-2.properties > log/server2.log 2>&1 & # port 9094
kakfka常用操作包括:
- 新建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic my-topic - 查看某一topic的情况:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic - 列举所有topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181 - 发送消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic - 接收消息:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic my-topic --from-beginning
其他更多操作可以查看官网说明,或者bin下的脚本都有帮助功能。
可能遇到的问题
无法删除topic
Kafka是为了消息持久化设计的,可能也真因为如此,它并不提供消息删除机制。而在测试时,想要清空现有的消息,最好的办法就是创建一个测试的topic,然后在需要的时候删除这个topic,再重建就可以了。
但是在实际删除过程中,会发现kafka会给予提示:
Topic test-group is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
意思是topic并没有被真正意义上的删除,只是加了个标记而已。想要彻底删除一个topic,则必须在配置文件(config/server.properties,config/server-1.properties,config/server-2.properties)中添加delete.topic.enable=true这样一行,然后重启kafka进程就可以了。
无法远程的生产或消费消息
当尝试在另一台机器上向本机发送消息或者接受消息的时候,会发现连接超时。特别的,当使用消费者模式连接过来的时候,从日志中可以看出,消费者正在尝试连接localhost的kafka端口。而这时kafka是在另一台机器上运行的,自然就没有办法连接成功。
原来,在配置文件中有这样一个属性advertised.host.name,它的描述是这样写的:
Hostname to publish to ZooKeeper for clients to use. In IaaS environments, this may need to be different from the interface to which the broker binds. If this is not set, it will use the value for “host.name” if configured. Otherwise it will use the value returned from java.net.InetAddress.getCanonicalHostName()
原来,当生产者或消费者连接过来的时候,kafka会通过zookeeper发送一个目标ip,而这个ip就是发送和接受消息的地址。这样做的目的是,在IaaS体系下,收发消息的ip可能和当前的ip不同,所以client会根据这个advertised.host.name提供的ip来进行后续连接。
默认情况下,这个advertised.host.name会直接使用host.name的值,而host.name在默认情况下又是没有配置的,所以最终返回的信息为localhost。而对于client来说,localhost指向的是自己,不是kafka集群。
因此,在这里只需要设定advertised.host.name为kafka自身的ip即可。
PyKafka
Kafka自身提供了Java上实现的生产者和各个语言的消费者。就生产者而言,肯定是无法满足需求的。但是kafka本身也只是定义了一套协议,只要符合流程,任何语言都可以实现生产者和消费者的功能。当然,github上存在不少各个语言下,对kafka生产者和消费者的实现。
对于需要用python实现生产者的开发者来说,PyKafka是一个不错的选择。Python下还存在着另一个kafka工程,kafka-python,关于这两者的比较,可以参阅这个讨论。总得来说,pykafka在生产者的稳定性,消费者的平衡性方面都有优化处理,略胜一筹。
相关文章
- RabbitMQ和kafka从几个角度简单的对比
- Apache Kafka: Next Generation Distributed Messaging System