基于 Ceph RBD 实现 Docker 集群的分布式存储
以 Docker 为代表的容器技术在云计算领域正扮演着越来越重要的角色,甚至一度被认为是虚拟化技术的替代品。企业中对于有状态的容器,往往需要将数据保存在额外的存储空间。Docker 引入了 Volume 机制,能够将永久数据独立于容器之外。正式的生产环境,Docker 通常是以集群的方式使用的,因此容器会分散在不同的主机上,为了保证数据的一致性和可访问性,共享存储是不可避免的。相比于传统共享文件系统,分布式存储系统扩展能力更强,由于数据都是分散在多个数据存储服务器上,因此数据更加可靠、安全,也更适用于容器的存储。
Ceph 简介
Ceph 概述
Ceph 是一个分布式存储系统,独一无二地用统一的系统—Ceph 存储集群,提供了对象存储,块存储和文件存储三种功能。Ceph 的存储集群基于 RADOS,提供了极大伸缩性—供成千用户访问 PB 乃至 EB 级的数据。 Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、同时采用 CRUSH 算法动态地重分布数据。
Ceph 有很多术语,了解这些术语,对理解 Ceph 的体系结构是非常重要的。表 1 给出了 Ceph 的常见术语。
表 1. Ceph 术语
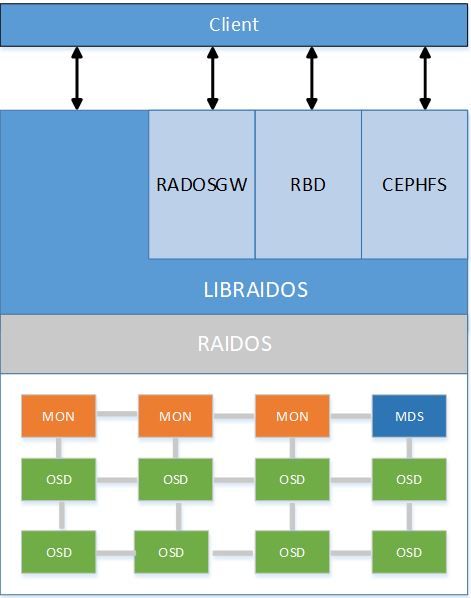
对 Ceph 的术语有了了解后,我们来看下 Ceph 的体系结构。Ceph 的体系结构与组成部分如下图 1 所示。Ceph 的体系结构由客户端(Client),对象存储网关(RADOSGW),块存储(RBD),文件存储(CEPHFS),和 RADOS 直接交互的库 LIBRADOS,存储集群(RADOS)组成。
Ceph 存储集群从 Ceph 客户端接收数据—不管是来自 Ceph 块设备、 Ceph 对象存储、 Ceph 文件系统、还是基于 librados 的自定义实现的—并存储为对象。每个对象是文件系统中的一个文件,它们存储在对象存储设备上。由 Ceph OSD 守护进程处理存储设备上的读/写操作。
图 1. Ceph 体系结构
Ceph 存储集群是 Ceph 很重要的部分,Ceph 文件系统、 Ceph 对象存储、和 Ceph 块设备从 Ceph 存储集群统一读出和写入数据。Ceph 存储集群的组件如下图 2 所示。Ceph 存储集群至少要有一个 Ceph Monitor 和两个 OSD 组成,如果要使用文件存储功能,还至少要有一个 MDS。
图 2. Ceph 存储集群

Ceph 常用命令
Ceph 客户端提供了非常丰富的命令用来操作块设备。在与容器对接过程中,我们需要创建块设备,删除块设备等功能,并且后续也需要针对这些功能提供相应的 REST API,方便通过 HTTP 请求的方式来操作块设备。所以这里对一些常用的命令进行说明,如表 2 所示。
表 2. Ceph 常用命令
Ceph 分布式存储集群的安装与配置
Ceph 集群搭建
本文通过安装 ceph-deploy 软件的管理节点来安装配置 ceph 集群,以 6 个节点—3 个 monitor 节点,3 个 osd 节点,以 ceph kraken(1.11.1)版本为例,说明 Ceph 存储集群的安装以及配置过程。集群的配置信息如表 3 所示。
表 3. Ceph 集群配置信息
Ceph 集群的安装配置过程如清单 1 所示。
清单 1. Ceph 集群的安装配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
# (1). 在所有节点安装依赖包
sudo yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/yum.repos.d/dl.fedoraproject.org*
yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# (2).在所有节点添加数据源
cat >>/etc/yum.repos.d/ceph.repo <<
EOF
[ceph-noarch]
name
=
Ceph
noarch packages
baseurl
=
https
://download.ceph.com/rpm-kraken/el7/noarch
enabled
=
1
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
[ceph]
name
=
Ceph
packages for $basearch
baseurl
=
http
://download.ceph.com/rpm-kraken/el7/$basearch
enabled
=
1
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
[ceph-source]
name
=
Ceph
source packages
baseurl
=
http
://download.ceph.com/rpm-kraken/el7/SRPMS
enabled
=
0
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
EOF
# (3). 所有节点更新数据源
sudo yum update
# (4). 在管理节点安装 ceph-deploy
sudo yum install ceph-deploy
# (5).所有节点安装 ssh【系统已经有了,就不用安装了】
yum install openssh-server
# (6). 所有节点创建用户,赋予 root 权限
useradd -d /home/{username} -m {username}
passwd {username}
echo "{username} ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/{username}
# (7). 所有节点设置刚刚创建的用户使用终端
sudo visudo -f /etc/sudoers
#Defaults requiretty
Defaults:ceph !requiretty
# (8) 所有节点添加集群信息
cat >> /etc/hosts <192.168.100 ceph-moni-0
192.168.1.101 ceph-moni-1
192.168.1.102 ceph-moni-2
192.168.1.103 ceph-osd-0
192.168.1.104 ceph-osd-1
192.168.1.105 ceph-osd-2
EOF
#(9) 设置 ssh 免密登录,在管理节点执行以下操作
su {username}
ssh-keygen
#根据提示输入三次换行符
#(10). 将管理节点产生的公钥拷贝到其他节点
ssh-copy-id -i /home/${username}/.ssh/id_rsa.pub ${username}@ceph-moni-1
ssh-copy-id -i /home/${username}/.ssh/id_rsa.pub ${username}@ceph-moni-2
ssh-copy-id -i /home/${username}/.ssh/id_rsa.pub ${username}@ceph-osd-0
ssh-copy-id -i /home/${username}/.ssh/id_rsa.pub ${username}@ceph-osd-1
ssh-copy-id -i /home/${username}/.ssh/id_rsa.pub ${username}@ceph-osd-2
#(11). 管理节点上更改~/.ssh/config
Host ceph-moni-1
Hostname ceph-moni-1
User ${username}
Host ceph-moni-1
Hostname ceph-moni-1
User ${username}
Host ceph-osd-0
Hostname cceph-osd-0
User ${username}
Host ceph-osd-1
Hostname cceph-osd-1
User ${username}
Host ceph-osd-2
Hostname cceph-osd-2
User ${username}
#更改权限
sudo chmod 600 ~/.ssh/config
#(12). 在管理节点,创建集群。
su ${username}
cd /home/${username}
mkdir ceph-cluster
cd ceph-cluster
ceph-deploy new {initial-monitor-node(s)}
例如:
ceph-deploy new ceph-moni-0 ceph-moni-1 ceph-moni-2
#(13) 在管理节点上,更改生成的 ceph 配置文件,添加以下内容
vim /home/${username}/ceph-cluster/ceph.conf
#更改 osd 个数
osd pool default size = 3
#允许 ceph 集群删除 pool
[mon]
mon_allow_pool_delete = true
#(14). 在管理节点上给集群所有节点安装 ceph
ceph-deploy install {ceph-node} [{ceph-node} ...]
例如:
ceph-deploy install ceph-moni-0 ceph-moni-1 ceph-moni-2 ceph-osd-0 ceph-osd-1 ceph-osd2
#(15). 配置初始 monitor(s)、并收集所有密钥:
ceph-deploy mon create-initial
#(16). 在管理节点上登录到每个 osd 节点,创建 osd 节点的数据存储目录
ssh ceph-osd-0
sudo mkdir /var/local/osd0
exit
ssh ceph-osd-1
sudo mkdir /var/local/osd1
exit
ssh ceph-osd-2
sudo mkdir /var/local/osd2
exit
#(17). 在每一个 osd 节点上更改 osd 数据存储目录的权限
#ceph-osd-0 节点上更改权限
chmode 777 -R /var/local/osd0
#ceph-osd-1 节点上更改权限
chmode 777 -R /var/local/osd1
#ceph-osd-2 节点上更改权限
chmode 777 -R /var/local/osd2
#(18). 在管理节点上执行命令,使每个 osd 就绪
ceph-deploy osd prepare ceph-osd0:/var/local/osd0 ceph-osd-1:/var/local/osd1 ceph-osd-2:/var/local/osd2
#(19). 在管理节点上激活每个 osd 节点
ceph-deploy osd activate ceph-osd0:/var/local/osd0 ceph-osd-1:/var/local/osd1 ceph-osd-2:/var/local/osd2
#(20). 在管理节点把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点
ceph-deploy admin {manage-node} {ceph-node}
例如:
ceph-deploy admin ceph-moni-0 ceph-moni-1 ceph-moni-2 ceph-osd-0 ceph-osd-1 ceph-osd2
#(21). 在每个节点上赋予 ceph.client.admin.keyring 有操作权限
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
#(22) 至此,部署完成。查看集群状态
ceph health
#会看到终端输出"HEALTH_OK",证明集群安装成功
|
Ceph 客户端配置
清单 2. Ceph 客户端配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# (1). 添加 ceph 源
cat >>/etc/yum.repos.d/ceph.repo <<
EOF
[ceph-noarch]
name
=
Ceph
noarch packages
baseurl
=
https
://download.ceph.com/rpm-kraken/el7/noarch
enabled
=
1
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
[ceph]
name
=
Ceph
packages for $basearch
baseurl
=
http
://download.ceph.com/rpm-kraken/el7/$basearch
enabled
=
1
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
[ceph-source]
name
=
Ceph
source packages
baseurl
=
http
://download.ceph.com/rpm-kraken/el7/SRPMS
enabled
=
0
gpgcheck
=
1
type
=
rpm
-md
gpgkey
=
https
://download.ceph.com/keys/release.asc
EOF
#(2). 安装 ceph client
yum update & yum install -y ceph
#(3) 添加集群信息
cat >> /etc/hosts <192.168.100 ceph-moni-0
192.168.1.101 ceph-moni-1
192.168.1.102 ceph-moni-2
192.168.1.103 ceph-osd-0
192.168.1.104 ceph-osd-1
192.168.1.105 ceph-osd-2
192.168.1.106 ceph-client
EOF
#(4). 拷贝集群配置信息和 admin 密钥
scp -r root@$ceph-moni-0:/etc/ceph/\{ceph.conf,ceph.client.admin.keyring\} /etc/ceph/
#(5) 创建 ceph rbd
sudo rbd create volume001 --size 1024 -m ceph-node1 -k
/etc/ceph/ceph.client.admin.keyring
#(6) 查看创建的 rbd 信息
rbd info volume001
|
Docker 集群使用 Ceph
我们以 Kubernetes 搭建的 Docker 集群为例,说明如何在 Docker 集群中使用 Ceph。关于 Kubernetes 的说明,可以参考Kubernetes 官方文档
Kubernetes 集群安装配置 Ceph
Kubernetes 集群中的每个节点要想使用 Ceph,需要按照 Ceph 客户端来安装配置 Ceph,具体步骤参考"清单 2 Ceph 客户端配置"。下面我们具体看下 Kubernetes 如何使用 Ceph RBD。
清单 3. Kubernetes 集群使用 Ceph RBD
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
# (1). 手动创建 ceph rbd
rbd create volume001 --size 1024 -m ceph-node1 -k /etc/ceph/ceph.client.admin.keyring
#(2) 禁用 rbd 的一些特性
rbd feature disable volume001 exclusive-lock, object-map, fast-diff, deep-flatten
#(3) 获取 ceph 集群 admin 的密钥的 base64
grep key /etc/ceph/ceph.client.admin.keyring |awk '{printf "%s", $NF}'|base64
#终端会输出 admin 密钥的 base64 形式${ceph-key-base64}
#(4) 创建 ceph 的 secret
# 在文件/home/ceph-secret.yaml 添加以下内容
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
type: "kubernetes.io/rbd"
data:
key: ${ceph-key-base64}
# 创建 ceph-secret
kubect create -f /home/ceph-secret.yaml
#(5) 创建使用 ceph rbd 的容器
#在/home/rbd.json 添加以下内容
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "rbd"
},
"spec": {
"containers": [
{
"name": "rbd-rw",
"image": "kubernetes/pause",
"volumeMounts": [
{
"mountPath": "/mnt/rbd",
"name": "rbdpd"
}]}],
"volumes": [
{
"name": "rbdpd",
"rbd": {
"monitors": [
#ceph 集群的所有监视器的 IP
${ceph-monitors}
],
"pool": "rbd",
"image": "volume001",
"user": "admin",
"keyring": "/etc/ceph/ceph.client.admin.keyring",
"fsType": "ext4",
"readOnly": false
}}]}}
#创建使用 ceph rbd 的 pod
kubectl create -f /home/rbd.json
|
Ceph REST API 服务搭建
上述步骤虽然实现了 Ceph RBD 作为 kubernetes 集群的存储方案,但 Ceph RBD 仍需要手动创建。为了自动化地管理 Ceph RBD,我们将 Ceph RBD 的相关操作封装成 REST API。 GitHub 上的 go-ceph 将 Ceph RBD 基础操作使用 go 封装成了 API,没有封装成 REST API,并且没有提供获取 RBD 使用情况的接口。我们在 go-ceph 添加获取 RBD 使用情况的接口,而后把 go-ceph 相关的 API 封装成 REST API。
go-ceph
清单 4. 安装 go-ceph
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#(1) 安装依赖包
sudo apt-get install librados-dev librbd-dev -y
#(2) 安装 golang 环境
wget https://storage.googleapis.com/golang/go1.7.5.linux-amd64.tar.gz"
tar -C /usr/local -xzf go1.7.5.linux-amd64.tar.gz
#(3)配置 go
export PATH=$PATH:/usr/local/go/bin
#(4) 设置 go 项目工作目录
mkdir -p /root/ceph
export GOPATH=/root/ceph
export PATH=$GOPATH/bin:$PATH
#(5)安装 git 和 gcc
apt-get install -y git
apt-get install -y gcc
#(6) 下载 go-ceph
cd /root/ceph
go get github.com/ceph/go-ceph
|
清单 5. go-ceph 添加获取 RBD 使用情况的接口
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# /root/ceph/src/github.com/ceph/go-ceph/rbd/rbd.go 中添加以下内容
#引入 ceph 获取 rbd 变化的函数 rbd_diff_iterate 同时实现该函数的回调函数 diff_callback
/*
int diff_callback(uint64_t offset,size_t len,int exists,void *arg) {
size_t *used_size = (size_t *)(arg);
if (exists){
(*used_size) +=len;
}
return 0;
}
int rbd_allocation(rbd_image_t image, const char *fromsnapname,uint64_t ofs, uint64_t len,
void *arg){
return rbd_diff_iterate(image,fromsnapname,ofs,len,diff_callback,arg);
}
*/
//...
#添加获取 rbd 使用情况的 go 函数
//int rbd_diff_iterate(rbd_image_t image,const char *fromsnapname,uint64_t ofs, uint64_t
len, int (*cb)(uint64_t, size_t, int, void *), void *arg);
func (image *Image)GetAllocation(imageName string,totalSize uint64)(allocation int64, err error){
if image.image == nil {
return 0, RbdErrorImageNotOpen
}
ret := int(C.rbd_allocation(
image.image,
nil,
(C.uint64_t)(image.offset),
(C.uint64_t)(totalSize),
(unsafe.Pointer)(&allocation)))
if ret < 0 {
return 0, RBDError(ret)
}
return allocation,nil
}
重新编译安装 go-ceph
go install github.com/ceph/go-ceph/rbd/
|
构建 Ceph REST API 项目
清单 6. 创建 rest api 项目
|
1
2
3
4
5
6
|
#安装 beego
cd /root/ceph
go get github.com/astaxie/beego
go get github.com/beego/bee
cd /root/ceph/src
bee api rest-ceph
|
清单 7. 创建操作 ceph 的 controller
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#编辑/root/ceph/src/rest-ceph/controllers/image.go
//Get Image Allocation
func getImageAllocation(poolName string, imageName string)(int64,string,error){
conn, err := newConn()
if err != nil {
return -1,"error",err
}
defer conn.Shutdown()
ioctx, err := conn.OpenIOContext(poolName)
if err != nil {
return -1,"error",err
}
defer ioctx.Destroy()
img := rbd.GetImage(ioctx, imageName)
img.Open()
totalSize,err:=img.GetSize()
if err!=nil {
fmt.Println("error when get size",err);
return -1,"error",err
}
allocation,err:=img.GetAllocation(imageName,totalSize);
if err!=nil {
fmt.Println("error when get allocation",err);
return -1,"error",err
}
img.Close()
return allocation,"success",nil
}
#其他操作 ceph 的接口...
|
清单 8 配置 namespace
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#编辑 /root/ceph/src/rest-ceph/routers/router.go
func init() {
ns := beego.NewNamespace("/v1",
beego.NSNamespace("/image",
beego.NSInclude(
&controllers.ImageController{},
),
),
//其他的命名空间
)
beego.AddNamespace(ns)
}
|
清单 9. 配置具体路由
|
1
2
3
4
5
6
7
8
9
10
|
#编辑 /root/ceph/src/rest-ceph/routers/commentsRouter_controllers.go
func init() {
beego.GlobalControllerRouter["rest-ceph/controllers:ImageController"] = append(beego.GlobalControllerRoute r["rest-ceph/controllers:ImageController"],
beego.ControllerComments{
Method: "GetImageAllocation",
Router: `/allocation`,
AllowHTTPMethods: []string{"get"},
Params: nil})
//类似的添加其他 rest api 的具体路由
}
|
清单 10. 启动服务
|
1
2
3
4
|
cd /root/ceph/src/rest-ceph
bee run rest-ceph
服务启动后,我们可以通过
http://<
node_ip
>:8080/v1/image/allocation?poolName=<
POOL_NAME
>&imageName=<
IMAGE_NAME
>
|
获取 rbd 使用情况。封装的 REST API 的主要方法如表 4 所示。
表 4. Ceph REST API
基于 Ceph RBD 实现 Docker 集群持久化存储案例
接下来,用 MYSQL 数据库容器来展示 Ceph RBD 如何实现数据持久化。
清单 11. 创建 mysql 数据库密码
|
1
2
3
|
#在 password.txt 中写入 mysql 数据库的密码
#创建 mysql 数据库密码 mysql-pass
kubectl create secret generic mysql-pass --from-file=password.txt
|
非持久化存储例子
清单 12. mysql 数据库 deployment 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#mysql-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: ${name}
spec:
replicas: 1
template:
metadata:
labels:
app: ${name}
spec:
containers:
- name: ${name}
image: ${mysql-repo}
imagePullPolicy: Always
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password.txt
ports:
- containerPort: 3306
name: mysql
imagePullSecrets:
- name: harbor.product.secret
|
清单 13. 创建非持久化 mysql 数据库 deployment
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
#把清单 12 的${name}赋值为:mysql-deployment
#创建 mysql-deployment
kubectl create -f mysql-deployment.yaml
#查看 pod
kubectl get po|grep mysql-deployment
mysql-deployment-311776555-0zz28 1/1 Running 0 1m
#登录 mysql pod
kubectl exec -it mysql-deployment-311776555-0zz28 /bin/bash
root@mysql-deployment-311776555-0zz28:/#
#登录 mysql
root@mysql-deployment-311776555-0zz28:/# mysql -uroot
#创建数据库
mysql> create database mydb;
Query OK, 1 row affected (0.00 sec)
#查看数据库列表
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mydb |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)
#删除 deployment:mysql-deployment
>kubectl delete deployment mysql-deployment
#把清单 12 的 mysql 数据库 deployment 的 yaml 文件的${name}赋值为 mysql-deployment-02
#得到 mysql-deployment-02.yaml 文件
#创建 mysql-deployment-02
kubectl create -f mysql-deployment-02.yaml
#获取 mysql-deployment-02 的 pod 的 name
kubectl get po|grep mysql-deployment
>mysql-deployment-02-423384506-d73q4 1/1 Running 0 52s
#登录 pod
kubectl exec -it mysql-deployment-02-423384506-d73q4 /bin/bash
#登录 mysql
root@mysql-deployment-02-423384506-d73q4:/# mysql -uroot
#列出所有的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)
|
这里我们可以看到新创建的 pod 并没有包含我们先前创建的 mydb 数据库,这是因为非执久化的 pod 所有数据都在内存中,数据会随着 pod 的删除一并删除。
持久化存储例子
下面我们再用 Ceph RBD 卷来实现数据持久化的效果。
清单 14. 连接 ceph 集群 secret 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
|
#获取 ceph 集群的秘钥
grep key /etc/ceph/ceph.client.admin.keyring |awk '{printf "%s", $NF}'|base64
QVFBTWdYaFZ3QkNlRGhBQTlubFBhRnlmVVNhdEdENGRyRldEdlE9PQ==
#ceph-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
type: "kubernetes.io/rbd"
data:
key: QVFDbzBadFkzbU9nQkJBQTNSZkZwT3IxQ2gvdWY1MVBtLzJreEE9PQ==
|
清单 15. 持久化 pv 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#ceph-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: ceph-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
rbd:
monitors: [
"192.168.1.100:6789",
"192.168.1.101:6789",
"192.168.1.102:6789"
],
pool: rbd
image: ceph-rbd
user: admin
secretRef:
name: ceph-secret
fsType: ext4
readOnly: false
persistentVolumeReclaimPolicy: Recycle
|
清单 16. 持久化 pvc 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
|
#ceph-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ${name}
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
|
清单 17. 持久化 mysql 的 service 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: v1
kind: Service
metadata:
name: mysql-service
labels:
app: mysql-statefulset
spec:
ports:
- port: 3306
selector:
app: mysql-statefulset
type: NodePort
|
清单 18. 持久化 mysql 的 statefulset 的 yaml 文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: ${name}
spec:
serviceName: mysql-service
replicas: 1
template:
metadata:
labels:
app: mysql-statefulset
spec:
terminationGracePeriodSeconds: 10
containers:
- name: ${name}
image: ${image-repo}
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: pvc
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: pvc
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
|
清单 19. 创建持久化 mysql 的 statefulset
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
#创建 ceph-secret
kubectl create -f ceph-secret.yaml
#创建 ceph rbd
curl -X POST http://root:[email protected]/v1/image?
-d "poolName=rbd&imageName=ceph-rbd&size=1073741824"
#创建 pv
kubectl create -f ceph-pv.yaml
#把清单 16 的${name}赋值为 pvc-mysql-statefulset-0
#创建 pvc
Kubectl create -f ceph-pvc.yaml
#创建 service
Kubectl create -f mysql-statefulset-service.yaml
#把清单 18 的${name}赋值为 mysql-statefulset
#创建 mysql-statefulset
kubectl create -f mysql-statefulset.yaml
#获取 pod
kubectl get po|grep mysql-state
mysql-statefulset-0 1/1 Running 0 4m
#进入 pod
kubectl exec -it mysql-statefulset-0 /bin/bash
#登录 mysql
mysql -uroot
#创建 database
mysql> create database mydb;
Query OK, 1 row affected (0.00 sec)
#显示数据库列表
mysql>show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mydb |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)
#退出 mysql 以及 pod
mysql> exit
Bye
root@mysql-statefulset-0:/# exit
exit
#删除 pv,pvc,statefulset
kubectl delete statefulset mysql-statefulse
#把清单 18 的${name}更改为"mysql-statefulset-02",得到 mysql-statefulset-02.yaml 文件
#把清单 16 的 name 更改为"pvc-mysql-statefulset-02-0"得到 pvc-mysql-statefulset-02.yaml 文件
#创建 pv,pvc 和 mysql-statefulset-02
kubectl creat -f ceph-pv.yaml
kubectl create -f ceph-pvc-02.yaml
kubectl create -f mysql-statefulset-02.yaml
#获取 pod name
kubectl get po|grep mysql-statefulset
mysql-statefulset-02-0 1/1 Running 0 10s
#登录 pod
kubectl exec -it mysql-statefulset-02-0 /bin/bash
#登录 mysql
mysql -uroot
#查看数据库列表
# (10). 列出 database
Mysql > show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mydb |
| mysql |
| performance_schema |
| test |
+--------------------+
>5 rows in set (0.02 sec)
|
这里我们可以看到新创建的容器包含了之前创建的数据库 mydb,也就实现了我们说的数据持久化效果。
小结
本文介绍了 CEPH 集群的安装,以及 kubernetes 基于 CEPH RBD 的 REST API 和 CEPH Client 实现了 Docker 集群持久化存储的功能。Docker 本身提供了本地存储的方案,但无法跨越主机,因此容器一旦被销毁后,如果不是落在先前的宿主机上运行也就意味着数据丢失。本文实现的 CEPH RBD 存储方案,数据不会随 Docker 宿主机的变更而发生变化。因此能够方便实现 Docker 集群的横向扩展。
参考资料
学习
参考架构介绍了解 CEPH 架构
参考 CEPH 官网关于体系结构的介绍,了解 CEPH 架构
参考 RADOS 介绍文档,了解 RADOS
参考 CEPH 官网快速安装部分,了解 CEPH 安装
参考 kubernetes 例子,了解 kubernetes 的使用
参考 beego 官网,了解 beego 安装使用
参考 golang 官网,了解 golang 安装使用