【CCTC 2017】UCloud块存储研发部副总监彭晶鑫:重新定义云数据保护
【CSDN现场报道】2017年5月18-19日,CSDN主办的中国云计算技术大会(CCTC)在北京朝阳门悠唐皇冠假日酒店盛装启航。本次会议践行“云先行,智未来”的主题,在Keynote环节之外精心策划了微服务、人工智能、云核心三大论坛及Spark、Container、区块链、大数据四大技术峰会,众多技术社区骨干、典型行业案例代表齐聚京师,解读本年度国内外云计算技术发展最新趋势,深度剖析云计算与大数据核心技术和架构,聚焦云计算技术在金融、电商、制造、能源等垂直领域的深度实践和应用,全程高能不断档,干货满满精彩纷呈。
UCloud块存储研发部副总监彭晶鑫带来分享《重新定义云数据保护》,讲述在数据故障的状况下数据如何失而复得。首先列举了17年以来发生的重大数据事件,表明云数据保护的典型场景和方式。然后分享了块存储数据保护的最佳实践,并以提供连续数据保护服务的“数据方舟”为例详解RPO、RTO等数据回滚技术点,重新定义保护方式。最后以工程角度,在实现实时IO接入、成本降低、利用分布式存储和计算加快恢复速度等长远目标上,详细分析了UCloud数据方舟的实践和技术架构。以下为演讲实录。

现场演讲实录
主持人:数据安全日益成为了企业面临的重要问题,下面我们有请UCloud块存储研发资源部副总监彭晶鑫为我们讲解云数据保护的重新定义。
彭晶鑫:大家应该都知道比特币病毒的覆盖范围之广,中了毒就要交钱。今天我们的分享主题并不是如何把数据和别人隔离开,或者是防止病毒攻击,而是如果数据遭遇了这些故障怎么失而复得。现在我负责的是分布式云团的研发和存储保护的数据包装研发,后面会重讲数据包装研发的架构和技术点。
大家知道2017年以来发生了一些比较著名的事件:一个是工程师在现场运维,数据只剩下几个G的时候他才意识过来停止掉了;另一个是由于受到黑客攻击删减了数据。在座的各位大部分应该是研发工程师,相信大家都深有体会,可能由于操作不当把数据误杀掉了。还有一些硬件的故障导致数据损害,也导致业务无法正常启动。
发生问题的时候大家是很紧张的,不管是运维工程师还是研发工程师,背后也有一帮人在看着你,怎么把数据恢复过来。我们发现很久没有使用这一套备用的机制了,可能这个机制就运转不通,时间也消耗不长。可能要花八个小时,然后可以让业务正常恢复,七八个小时还算是比较正常的速度了,可能需要几天甚至几周。再就是回滚成功,大家的心已经放下来了,现在可能已经是凌晨七点了,或者是一天前或者几周前。
碰到这个问题的时候我们发现数据回滚没有一套非常好的机制保障数据失而复得,那么快数据保护的最佳实践应该是什么样的?业界承认的两个点一个是RPO,一个是RTO,要看可以回滚到哪一个点,比如几秒前、几个小时前还是几天前。还有一个复原时间问题,就是我想达到这个要求要耗时多久,几分钟、十几分钟、半个小时还是几天。我们认为除了这两个点之外还有另外两个点,一个是复原便捷的目标,再就是复原保障的目标,后面还会有一些详细的展开。我们推出了一个数据方案的产品,解决了刚才说的几个特点,主要是针对云硬盘和云主机两个产品给他们保驾护航。
今天我分享的主题是重新定义数据保护,那么应该怎么重新定义?很简单,我们首先要达到两个基本要求,一个是RPO,一个是RTO。说是基本的要求,其实现在云计算行业内基本上不能达到。理论上最好的方式是回归到故障之前的几秒或者几分,也可以是二十四小时之内的任意一个小时或者三十天之内的任何一个零点。除了这样精密的RTO目标之外我们也提供了业界通用的方式,就是可以制作一个快照进行个人回滚。RPO就是我们恢复的时间要多久,比如1T的硬盘如果全满的话基本上是二三十分钟,我认为这是非常大的弹性。除了RPO和RTO之外还有RCO和RAO,RCO其实没有什么太多说的,主要就是在云计算的平台之下你们可以通过API完成相关的操作,RAO就是回滚的时候希望怎么保障用户背后的数据,也希望数据是保留的,因为这个数据可能日后去分析问题,所以我们是需要把数据恢复到一个新的硬盘。我们后面其实是把一个新硬盘和一个旧硬盘交替,后端是帮助用户进行保护数据,分析原因到底是什么问题导致的。RAO就是这个机房出现问题的时候是不是可以在另外一个机房进行回滚,这也是我们方案的一个重要体系。
这里我着重列了三个场景,还有它们的最佳实践是什么样子,下面我们谈一谈它的工程的实践。任何的工程实践肯定要有一个目标,我们认为主要是三个点的目标,就是在云计算行业之下有大量的用户磁盘,每秒产生的是大量的IOPS,还有IO带宽。我们需要扛住IOPS和IO带宽,成本上也要有一个衡量,不能一直在那里不停地记录数据,没有采取什么策略,即便我们把这个产品做出来了客户也不一定能够接受这个成本。我们要怎么更加快速地把数据回滚到一个新的磁盘?我们要利用一个后端分布式的存储以及计算的能力调度节点把这个事情做到,然后加快回滚的速度,如果客户出现业务中断之后能够很快把业务回滚。
我们刚开始就引入了份额存储的架构:第一层是采用高速的SSD设备,可以用它的软件能力扛住比较大的IOPS,就是大量磁盘的写操作。第二层是采用传统的SD设备存储不是实时的数据,可以尽量发挥SDD盘数据读写的能力。通过这种分层的份额存储,我们既达到了部门的要求又可以在成本上进行一定的衡量。
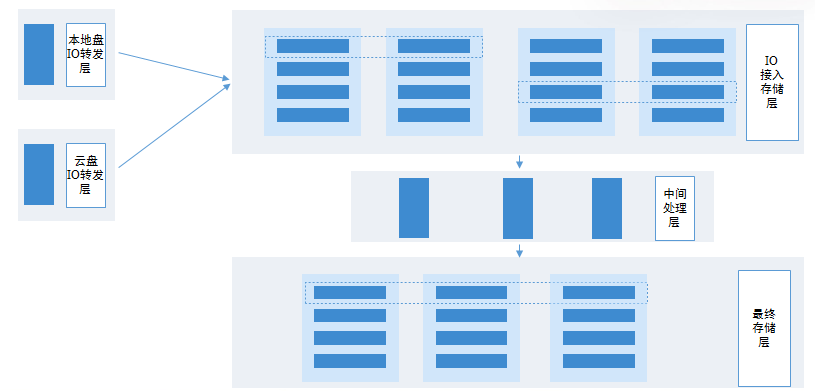
这是数据方舟重要的软件架构:第一层就是本地硬盘的IO转化率以及名义盘的转层,希望农村网络传输到数据方式的的后端集群,我们的设计理念也是换一张优质网卡来做这个事情,要从一个磁盘的角度出发,每时每刻都要把它控制住,同时我们可能要做一些设计保证数据的准确性。刚才我们所说的IO结构层采用的就是高速的设备,总体的容量肯定不能一直深入每时每刻的IO存量的东西,中间是把IO层拉下来进行一定的预处理,然后按照磁盘的垂直范围进行分配,也会按照一定格式进行存储。这个地方的中间程序层可能按照一定的程序,比如二十分钟或者十分钟,通过HDD的设备来做存储。刚才所说的IO接入层一个是IOPS一个是IO带宽,对应起来就是CPO和磁盘容量是不是扛得住。机器负载达到一定程度的时候我们就要迁移到另外一台机器上面,因为数据方舟的目标是回滚到任意一秒,决定了每时每刻数据都不能丢失,最终存储层是希望通过一个调度模块,能够利用最终存储层的多个节点去做分布式的存储和分布式的计算,用户回滚的时候可以平行地做操作做计算,然后可以把数据恢复出来。
每个数据的存储也是比较关键的地方,为了成本没有变化,我们需要对数据进行一些处理。

这张卡片讲的是一段时间的数据组成,比如十分钟之内数据的组成是什么样子。现在我们会根据磁盘的垂直范围,比如0-1G,也有可能是0-64M,这是一个非同大小的规格。另外我们要考究它的成本,所以会采取存储行业比较通用的方式,就是每个存储文件是多种模块储存,可以在Cloud级别去做一些压缩的操作,更好地节省它的成本。
前面已经大致把我们每个层次的目标以及数据的存储格式讲清楚了,接下来就讲一讲回滚的时候应该是什么样子。刚才所说的最终存储层已经形成了备份的数据,但是还需要被中间的调度模块生成,比如小时的数据和天的数据,最后合成一个Base数据。这个是增量处理方式,比如存储管理就是被存储的数据,加上天级别的增量数据以及小时级别的增量数据,还有中等的增量数据,里面关系到任意一秒系统的存储。我们可以生成一个新的Base数据,然后生成一个新的磁盘,比如到云磁盘、本地盘和数据的留存。
数据方舟过去一年的实践当中我们开拓了很多功能,经验积累当中也发现了一些回滚的案例。回滚的原因可能分布在误删数据,这个方面还是比较多的,误写数据也是比较多的,数据损害存在着一定的部分,我认为可能是其中之一,也有可能遭遇了一些问题。刚才我们说到数据方舟重新定义数据保护,6月份就会发布2.0的版本更好地服务客户。
更多精彩内容,请关注图文直播专题:CCTC 2017中国云计算技术大会,Keynote视频直播,微博:@CSDN云计算,订阅 CSDN 官方微信公众号(ID:CSDNnews),即时获取大会动态。