基于树莓派的Spark集群搭建
本文只是为了想通过树莓派搭建Spark来练练手的同学们写的一个成功的案例和自己鼓捣出来的一些心得体会。
大神多多指教。
转载注明出处 http://blog.csdn.net/isinstance/article/details/51690133
参考文献有这么几个:
树莓派Spark集群(建议重点参考)
Linux系统安装配置JDK
重启hadoop各节点datanode的方法
————————————————-分割线————————————————–
1.前期准备:
【1】树莓派安装JDK的话安装第二个参考文献去安装就可以了,然后改/etc/profile 文件并使其source。
【2】下载Hadoop和spark,scala的安装包
很多网上的教程是要下载src文件在本地的机器上自己使用maven编译的,但是我没有编译,直接下载的bin安装包,解压
————————————————-分割线————————————————–
2.配置好JDK后:
注:
这里所指的参考文献二配置JDK是配置PC机的JDK
JDK的话还是建议从Oracle的网址下Oracle的包,不要用openJDK,openJDK没有Oracle的支持好
因为树莓派里面本身已经预装了JDK,在/usr/lib/jvm 里面有个arm版的JDK
如果这里找不到JDK的包的话,执行下面这个命令
update-alternatives --config java这时就会显示出来你的JAVA目录,这样都没有的话,老老实实装一个arm32的包吧。。。
在配置树莓派Java路径时候为了简单起见,可以将这个包整个复制到/usr/src 下
cp -r /usr/lib/jvm/jdk-8-oracle-arm32-vfp-hflt /usr/src/然后回到/usr/src/ 目录下
将这个包改名为jdk
mv jdk-8-oracle-arm32-vfp-hflt jdk下面是我的做法
我的所有包不管是压缩包还是解压后的包都是放在/usr/src目录下的
各位参考的时候可以改成自己喜欢的目录
配置完主机和树莓派的JDK后,现在让我们切换回PC机
PC机
首先切换到root模式,将下载好的hadoop包拷到/usr/src 目录下
cp hadoop-2.6.4.tar.gz spark-1.6.1-bin-hadoop2.4.tgz scala-2.11.8.tgz /usr/src然后就是解压到本地目录
tar zxvf hadoop-2.6.4.tar.gz spark-1.6.1-bin-hadoop2.4.tgz scala-2.11.8.tgz然后就可以了
下面我们安装一些必要的安装包,如果你看过那篇参考文献,这步你可以跳过了
然后这里我使用的是清华的源,先编辑一下/etc/apt/sources.list
vim /etc/apt/sources.list然后增加这两个源,关于树莓派怎么命令行下连WiFi请参考我的另一篇文章
deb http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ jessie main non-free contrib
deb-src http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ jessie main non-free contribapt-get install libtool zlib1g-dev pkg-config libssl-dev libfuse-dev libsnappy-dev libsnappy-java libbz2-dev vim以上的每一步是每个机器都必须做到
【切记】所有树莓派和主机PC的解压目录都应该是一样的
然后增加/etc/hosts文件中的主机名和ip
vim /etc/hosts将要搭建集群的树莓派的ip和名称写进去
192.168.1.40 master
192.168.1.41 s1
192.168.1.42 s2
192.168.1.43 s3这里的ip和名字只是举例,但是最好把作为master主机的名字设为Master或者带master字眼的
其他的简单起见可以使用s1,s2,s3等代称。
这一步每个树莓派也同样需要配置
做完后主机和每个树莓派可以测试一下
ping s1ping masterping s2等等,最好把每个树莓派的每个hosts都测试一遍,以防手抖打错了,不然待会集群时候对应不起来
配置树莓派的时候注意将127.0.1.1 raspberry 这一行注释掉
————————————————-分割线————————————————–
3.下面开始配置ssh
在主机生成公钥和私钥
ssh-keygen -t dsa -P ""
cp ~/.ssh/id_dsa.pub ~/.ssh/authorized_keys用dsa因为它比rsa速度快(这里是参考第一篇文章的做法,统一使用dsa,各位也可以使用rsa)
然后测试一下,ssh自己
ssh localhost如果没有出现输密码就说明成功了
现在就给各台树莓派传主机PC的密钥
ssh-copy-id -i ~/.ssh/id_dsa.pub s1
ssh-copy-id -i ~/.ssh/id_dsa.pub s2
ssh-copy-id -i ~/.ssh/id_dsa.pub s3这里我统一都使用了root模式,不管是树莓派还是本机,因为ssh登录时,登录名默认为本机的用户名,但是本机用户名千奇百怪,而树莓派的用户名是pi,会出现登不上的情况
这里要修改一下有个配置文件(这一步主机和树莓派都有做)
vim /etc/ssh/sshd_config一般是在28-33行之间
有个PermitRootLogin 后面改为yes
再下面的AutorizedKeysFile删掉注释
保存退出
重启服务
/etc/init.d/ssh restart各slaver到主机的密钥传不传都无所谓了
反正我是没传
然后直接回到你刚才解压hadoop的地方(也就是/usr/src/)
(这一步是在PC机上)
更改目录名字
mv hadoop-2.6.4 hadoopmv spark-1.6.1-bin-hadoop2.4 sparkmv scala-2.11.8 scala更改一下文件名,方便配置环境变量,不改也没关系,就是配置环境变量时候要手输很长的一段目录名,还怕打错!
然后配置一下环境变量
各节点的树莓派和PC都要做
export SCALA_HOME=/usr/src/scala
export PATH=$SCALA_HOME/bin:$PATH
export HADOOP_HOME=/usr/src/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids (注意这里,建议不要将这个目录设置在root目录下,建议设置在你自己用户的主目录下)
(export HADOOP_PID_DIR=/home/jay/hadoop/pids jay是我的用户名)
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin先将scala 打包
tar zcvf scala.tar.gz scala然后传到各节点
scp -r scala.tar.gz s1:/usr/src后续的将s1改为s2,s3就行
然后在各个树莓派上解压scala.tar.gz就行
然后一路进入/usr/src/hadoop/ect/hadoop
cd /usr/src/hadoop/etc/hadoop修改这个目录下的core-site.xml
vim core-site.xml在两个尖括号configuration之间加入下面这些内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/jay/hadoop/storage/tmpvalue>
property>
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
<property>
<name>hadoop.native.libname>
<value>truevalue>
property>
configuration>然后配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/jay/hadoop/storage/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/jay/hadoop/storage/hdfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>然后配置hadoop-env.sh
最后加入这么一句话
export JAVA_HOME=/usr/src/jdk然后再配置slaves
注释掉localhost
加入
s1
s2
s3然后你可以将配置好的hadoop文件打包,然后发送给各个节点也就是各树莓派了
退出到hadoop主目录的上一级目录,打包,压缩
tar zcvf hadoop.tar.gz hadoop然后就会生成一个打包好的文件,通过ssh发送给各个节点
scp -r hadoop.tar.gz root@s1:/usr/src scp -r hadoop.tar.gz root@s2:/usr/src scp -r hadoop.tar.gz root@s3:/usr/src然后在各节点的/usr/src/ 目录下就有了一个hadoop.tar.gz 压缩包
在各节点分别解压
然后回到主机PC
尝试运行一下hadoop
hdfs namenode -format #初始化节点
start-dfs.sh #开启文件系统
start-yarn.sh #开启yarn
jps #显示进程如果最后在主节点也就是master上看到jps 的输出为
JPS
ResourceManager
NameNode
SecondaryNameNode说明成功了
在从节点也运行一下jps
输出如下
JPS
NodeManager
DataNode说明成功了
注: start-dfs.sh start-yarn.sh 只在master主机上运行
hdfs namenode -format 可以在各节点都初始化一下,不要频繁过多的初始化节点,会造成节点temp文件中文件名对应不上的问题, 初始化一次就行,以后就不用初始了
如果出现找不到hdfs namenode -format start-dfs.sh start-yarn.sh文件的报错, source /etc/profile 一下
4.安装spark
进入我们改名的spark主目录
如果你没有改名就进入相应的目录
修改spark-env.sh
vim /conf/spark-env.shexport JAVA_HOME=/usr/src/jdk
export SCALA_HOME=/usr/src/scala
export HADOOP_HOME=/usr/src/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKER_WEBUI_PORT=2023
export SPARK_MASTER_WEBUI_PORT=2022
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=(你现在配置的本机的IP或者别称如master或者s1等)
export LD_LIBRARY_PATH=/home/pi/lib/hadoop/hadoop-2.6.0/lib/native
export YARN_CONF_DIR=$HADOOP/etc/hadoop
export SPARK_JAR=/usr/src/spark/lib/spark-assembly-1.6.1-hadoop2.4.0.jar这一步你可以将SPARK_LOCAL_IP空着
然后退出到spark主目录的上一级目录,打包spark
tar zcvf spark.tar.gz spark然后传给个节点
scp -r spark.tar.gz root@s1:/usr/srcscp -r spark.tar.gz root@s2:/usr/srcscp -r spark.tar.gz root@s2:/usr/src最后在各个节点里修改每个节点的SPARK_LOCAL_IP
将在spark-env.sh 里面修改SPARK_LOCAL_IP为当前节点的IP地址
然后切回到spark的主目录
执行启动spark的命令
./sbin/start-all.sh然后使用jps 命令查看主节点也就是master 和各从节点的进程
如果主节点多了一个master
从节点多了一个worker 说明spark启动成功了
在浏览器中打开`http://master:2022地址
在这里你可以看到4节点,那就说明spark成功了
5.Spark的yarn模式运行
事实上有两种运行方式,一种是集群模式,集群模式是用来运行application的,还有一种是客户端模式,是在spark-shell中采用集群的方式
- 现在我们试着将文件推到hdfs中
hdfs dfs -mkdir /user/pi/sourceshdfs dfs -put README.md /user/pi/sources如果hdfs找不到命令的话,source一下/etc/profile
如果成功了话,恭喜你
如果没成功,也不怕,我一开始也没有成功,没有成功是一蹴而就的
如果没成功的话,多半是你的各节点的DataNode没有启动
注意:下面这些操作是属于DataNode没有启动的解决方法,在每个节点中都要做
我们切到hadoop的主目录,执行下面代码
./sbin/hadoop-daemon.sh start datanode然后jps一下看看,有没有多出来一个
datanode没有的话,再执行一遍,一般三遍以内就会出现datanode
确保每个节点都启动datanode之后
重启spark
我们先停止spark
记住,要先停止!
我们切回spark的主目录,执行
./sbin/stop-all.sh然后再启动spark
./sbin/start-all.sh这时候再put就可以传上去了
- 下一步就是启动yarn
./bin/spark-shell --num-executors 3 --master yarn --executor-memory 200m不过我比较喜欢Standalone模式
我们也可以这样测试
./bin/pyspark spark://master:7070然后打开浏览器的
http://master:7070这时候就会出现spark Standalone模式下的web UI
我这里有几张树莓派集群的图
大家参考一下
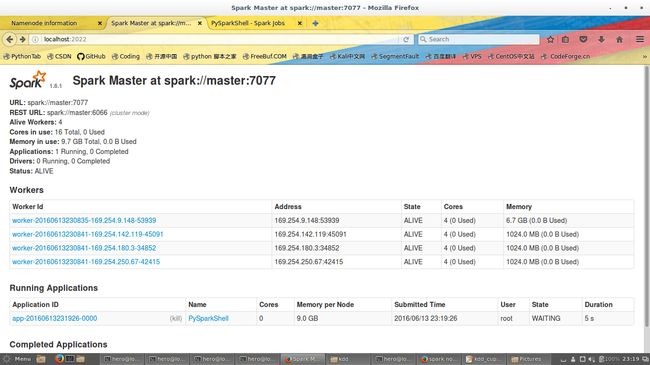
我这时测试了了一个PySparkShell
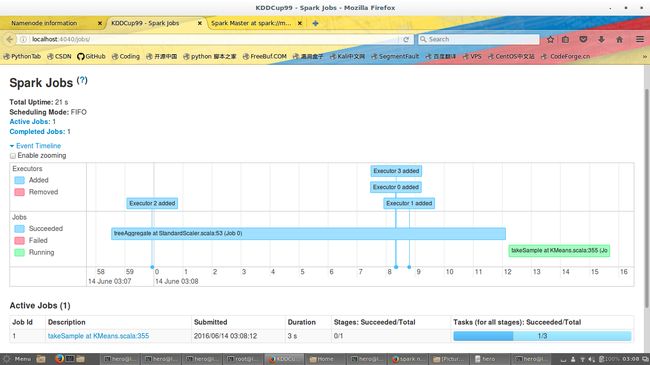
然后这张图我用spark的Mllib算了一下Kmeans
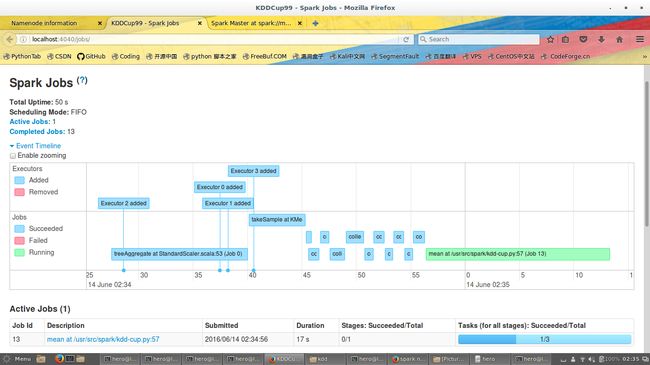
最后这张图显示的是真正运行一个application时候的样子
好了,授课到此,欢迎大家留意问问题。我会尽力给大家解答的。
- 2018-1-12 我把我的毕业设计论文上传github了,里面有具体的实现细节,大家可以参考参考,因为已经过去两年了,所以就把论文释出了