《麻省理工学院公开课:人工智能》笔记三
《04 搜索: 深度优先,爬山,束搜索》视频链接
【内容简介】
由地图的例子讲述了关于搜索的几个算法的原理,包括:大英博物馆算法(British Museum Algorithm),深度优先搜索(Depth first search),广度优先搜索(Breadth first search),爬山算法(Hill climbing),束搜索算法(Beam)
【笔记】
因为实际的地图非常复杂,所以我们就假设一个简单的地图来解释上述搜索算法。假设我们有这么一张地图,如下图,我们打算从S点移动到G点,请你规划出一条最近的路线。
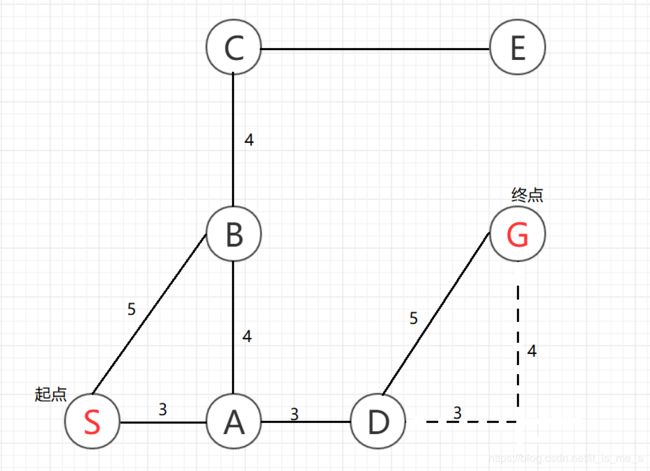
如果让我们来规划的话,我们肯定选择 S>A>D>G 这条路线,因为我们人脑运行的是基于视觉的算法,但是机器没有视觉,如果让机器来选择,它会如何选择呢?
大英博物馆算法(British Museum Algorithm)
大英博物馆算法的思路就是:找出所有可能的路径。让我们用 树 来表示就是下图:
当处理这种问题时我们有两个 惯例 需要了解:
- 要求你画出来的搜索树使用词典顺序。(意思是S下的这些节点都需要按照字母顺序来)
- 搜索树不能在原地打转。(意思是:从S去了A,就不能再从A回到S,不允许有路径绕回到原来到过的地方,否则我们会无止境的原地打转)
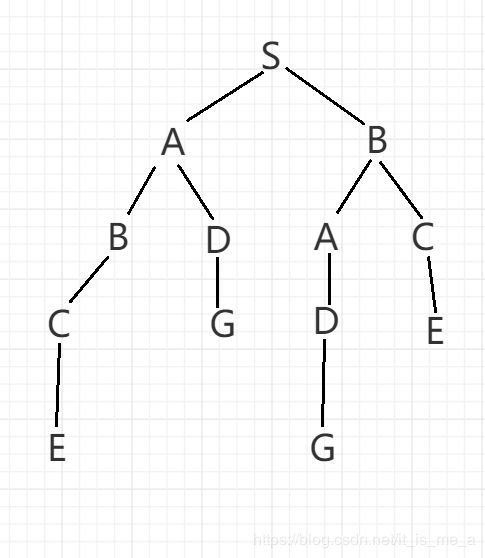
如图所示,大英博物馆算法就是在树上列出了所有的路径。当地图很复杂的时候,这个算法就显得非常愚蠢了。
有一点要强调,虽然我们用地图来解释搜索算法,但实际上 搜索是关于选择的,这节课的内容也就是在讲探索地图时所面临的选择。
深度优先搜索(Depth First Search)
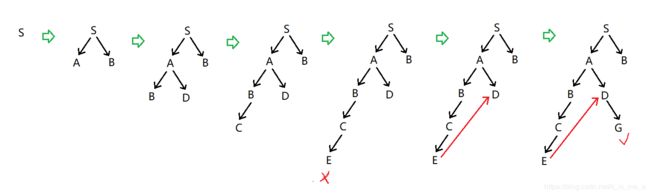
按照深度优先和从左开始的原则,我们将会拓展出 S>A>B>C>E 这条道路,这时就会进入死胡同。
Tip 1:
处理办法就是回到上次做出选择的地方,选择另一个分支进行深度拓展,这个过程称为回溯(Backup/Backtracking)*
所以搜索树的演变就如下图:
搜索算法的深度优先大致流程图如下:
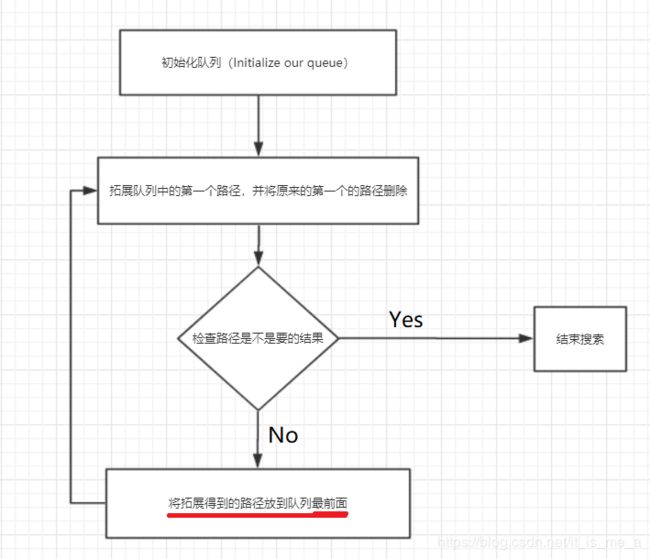
解释:
假设我们有一个队列来存储所有的路径。
刚开始队列里面存储的是(S),因为并不是想要的结果,所以我们拓展队列中的第一个。
这时队列里面存储就是( S>A,S>B ),这也不是想要的结果,所以我们拓展队列中的第一个路径,并删除原来第一个的路径。
这时队列里面存储就是( S>A>B,S>A>D,S>B ),这也不是想要的结果,所以我们拓展队列中的第一个路径,并删除原来第一个路径。
…
所以队列的变化就为:
(S)
(S>A, S>B)
(S>A>B, S>A>D, S>B)
(S>A>B>C, S>A>D, S>B)
(S>A>B>C>E, S>A>D, S>B)
(S>A>D, S>B)
(S>A>D>G, S>B)
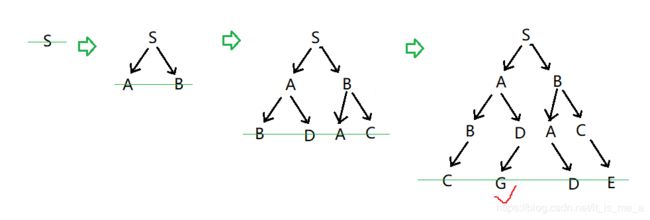
广度优先搜索
工作方式:你一层一层的建立这棵树,在某一层横向扫描时发现自己得到了目标的路径。
搜索树的变化为:
广度优先的算法与深度优先的算法流程图区别在于:将拓展结果方放到队列末端,这样的话队列就会同时拓展所有的路径。
但是广度优先也是比较蠢的?
- 路径重复考虑了(比如说A到D,B到C被重复考虑了,如果路径够复杂,会影响效率)
Tip 2:
为了解决路径重复考虑的问题,我打算修改算法流程图中的规则:不拓展队列中的第一个路径,除非末端节点之前从未被扩展过。因此我们需要一个列表来存储之前已经拓展过的所有路径。
在广度优先的基础上加入 拓展位置列表 就对搜索算法进行了优化。
爬山算法(hill climb)
与深度优先搜素算法相似,只是不再使用字典顺序进行选择。
当我们起点放到地图中间(如下图所示),此时不管我们用上面讲述过的任何一种算法,它都会往左寻找路径,但我们人眼可以看到往右才离目标更近。所以我们在搜索算法中加入哪些节点离得目标近的思路来优化它。
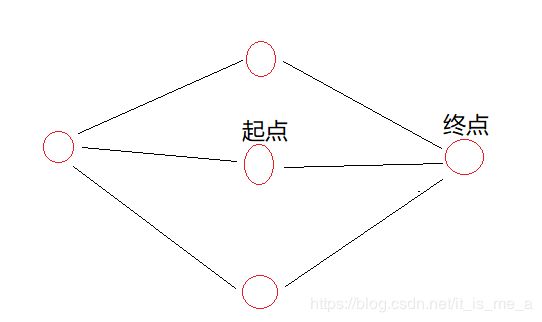
Tip 3:
怎么才能让机器知道哪些节点离目标更近?
用一些启发式的方法。就比如我们最初的地图上(下图)就标注了距离长度,这是一般地图上都会有的。
启发式方法有就用,没有就算了。
所以用爬山算法解决这个地图,它的搜索树就如下图所示: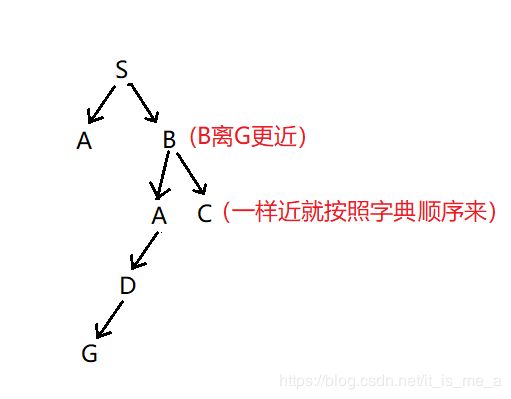
爬山法对搜素算法流程图的改动在于:在深度优先的基础上,将路径按照知情启发式信息,及远近信息进行排序后,放到队列前面。
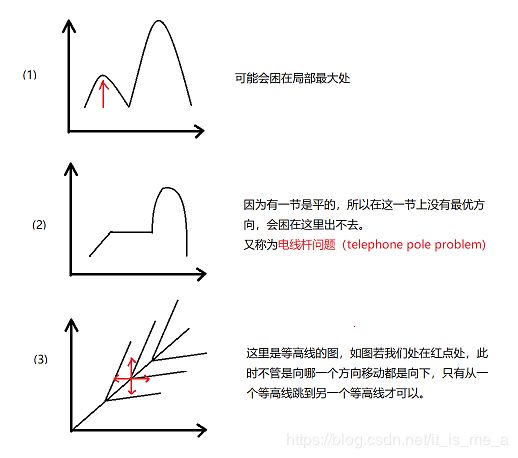
但是爬山法会有一些问题:
束搜索(Beam search)
是广度优先的改良,将知情启发式信息加到了广度优先搜素中。
我们将每一层中考虑拓展的路径数字进行限制,取一个较小固定数字(比如说我们这里假设束搜素的束宽 (Beam Width) w 为 2),再加上知情启发式信息,我们的搜素树就如下图:
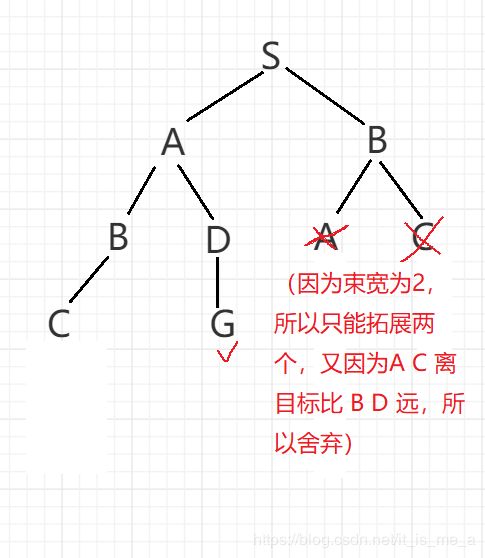
束搜索对搜素算法流程图的改动在于:在广度优先的基础上,将路径放到队列之前,要 keep w best。
最后有一个表格整理这节内容:
| Backup | use extended list | informed search | |
|---|---|---|---|
| British Museum | NO | NO | NO |
| Depth First | Yes | Yes | NO |
| Breadth First | NO | Yes | NO |
| Hill climb | Yes | Yes | Yes |
| Beam | NO | Yes | Yes |