JVM详解
先看一下JVM的整体结构:
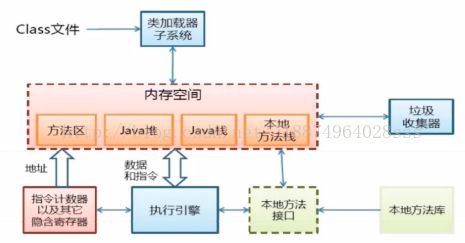
接下来我会分以下几个模块进行讲解:
第一个模块class文件:通过JVM IDE将.java文件生成.class文件。
大家可以看一下我的另外一个技术博客 有对.class详细介绍:点击打开链接
具体的编译流程:核心就是对源文件的词法和语法进行一个分析。
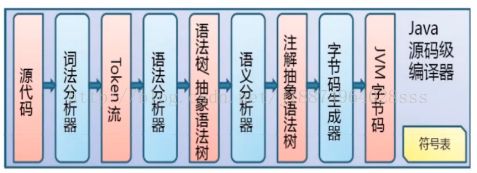
第二个模块类加载器:类加载器的子系统,将class文件的字节码加载到jvm对应的虚拟机内存中。类加载器的核心是classLoader,classLoader又是动态跟新的核心。
JVM提供了所有classLoader,既以下四种:
BootStrap ClassLoader,ExtensionClassLoader用来加载jdk中特定的jar包的。
APP classLoader:用来加载应用程序的classLoader,它是应用程序真正要用到的加载器。
Custom ClasssLoader:可以自定义classLoader。它是作用是重写一个classLoader,用这个classLoader来加载指定目录下的class文件。
如果是Android的同学可以对比学习以下dalvikVM类加载机制:点击打开链接
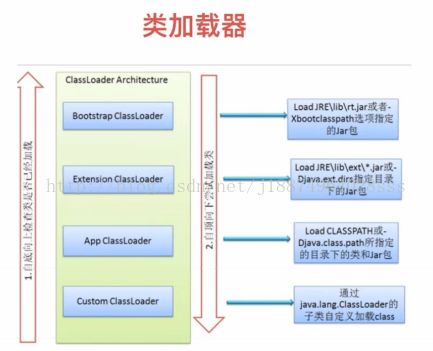
类的加载流程:
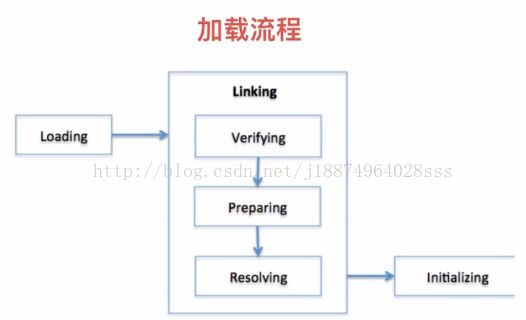
类加载器是如何将class字节码加载到我们的JVM对应的内存中呢
分为三个步骤去完成,首先就是loading,然后再是linking,然后再会是initializing,去完成我们对应变量的初始化。
Loading:类信息从文件中获取并且载入到JVM的内存中。
Verifying:检查读入的结构是否符合JVM规范的描述。如果符合我们才会对它进行下一步。
Preparing:验证完正确以后,分配一个结构用来存储类信息。
Resolving:存储完以后,把这个类的常量池中的所有的符号引用改变成直接引用。
Initializing:在我们的存储化完了以后,最后才是我们的初始化。执行静态初始化程序,把静态变量初始化成指定的值。
第三个模块(内存空间):当我们的class字节码被我们的classLoader加载到JVM对应的内存空间以后,我们的JVM又会把我们的内存区域分成:方法区、java堆区、java栈区、本地方法栈。这四个部分用来存储class字节码的不同部分。
Java栈区:
作用:它存放的是java方法执行时的所有的数据。
栈区组成:由栈帧组成,一个栈帧代表一个方法的执行。
具体讲解栈帧:
一个栈帧的作用:每个方法从调用到执行完成就对应一个栈帧在虚拟机栈中入栈到出栈。比如我们的A方法中调用到B方法,方法B开始执行的时候,java虚拟机就会为其创建一个保存B方法的栈帧,然后把这个栈帧压入到java的栈区中。
栈帧包含内容:局部变量表、栈操作数、动态链接、方法出口。stackOverFlow这个异常:就是当栈的深度大于jvm所允许最大的深度,就会报出这个异常。模拟:没有退出条件的递归函数,这个函数一运行就会不停的去调用它自己,直到发生这个异常。
本地方法栈:
作用:本地方法栈专门为native方法服务的。
跟java方法栈类似,也是通过栈帧来记录每个方法的调用。
方法区:存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的数据。是永远占据内存的。
堆区:所有通过new创建的对象的内存都在堆中分配。
特点:是虚拟机中最大的一块内存,是GC经常要回收的部分。
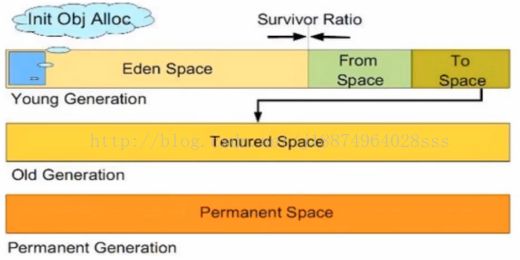
刚刚创建的对象放到我们的新生代中,当新生内存空间不足时,java虚拟机会通过一定的算法规则将新生代对象挪到对我们的老生代中,这样我们的新生代又有了新的内存空间,此时新生代就可以继续的分配一些内存。当内存空间不足时会触发垃圾回收器,而当新生代和老生代都没有足够的内存的时候,这个时候JVM就会抛出OOM异常。
当然我们的新生代对象是什么时机移入我们的老生代,这一部分每一个版本的虚拟机都是不同的。那么我们的jvm为什么要将堆区这一块内存分为新生代和年老代呢?它最大的好处就是可以让开发人员去动态的调整它们的大小。比如说在做一些即时通信的java服务器的时候,可能创建一些临时对象message比较多,那么就可以把新生代的内存区域调整的大一些,这样便于我们的内存的分配,加快我们对象的创建。如果去开发一些大型服务类的项目时,我们可能并不需要频繁的创建对象,这个时候就将新生代调整的小一些,从而扩大老生代内存区域,达到一个对象常驻的效果,保证服务的稳定性。
第四个模块:垃圾回收器。
垃圾收集算法:
1、引用计数算法:这个算法是java虚拟机最早使用的算法,来标记这个对象是不是垃圾对象。对象创建和被引用都是+1,引用被销毁时就-1。如果引用计算器的值为0的时候就标明这个对象可回收了;如果这个对象的计算器值大于0时,那么标记为可用对象不回收。
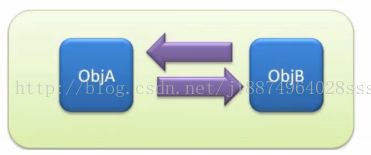
但这存在一个问题,如:A引用B,而B也引用了 A ,那么两个引用计算器的值都为1,但是A B都是不可达的,也就是说没有路劲指向这两个对象了,也就是他们已经是垃圾了,但是在引用计算的这种场景下无法被垃圾回收。
2、可达性算法:
从JDK1.2以后一直就是用的可达性算法,也叫做根搜索算法。可达性算法是从我们的离散数学的图论中引入的,把整个程序的引用关系看做一张图,从一个叫做gc root节点开始,寻找所有对应它的引用节点,找到引用节点以后继续找到这个节点的引用,在所有的节点引用寻找完毕以后,剩余的节点则被认为是没有被引用的节点,没有被引用的节点即不可达的节点,即可以被认为是垃圾对象。
这里所说的引用分为四种:强引用、弱引用、软引用、虚引用。最常用是的是强引用、弱引用。
垃圾回收算法:
标记清除算法:从根节点来遍历所有对象的引用。第一步:遍历,第二步:标记,第三步:清除。
优点:不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活对象比较多的情况下极为高效。
缺点:由于我们的标记清楚算法会直接回收不存活的对象,因此会造成内存碎片。
复制算法:将内存区域分为两块。然后垃圾回收时 从根节点开始遍历每个对象,如果发现某个对象是可达的,就将该对象复制到另一块的空闲区域,等所有的复制都处理完以后,就将原来的内存空间都清理掉。
优势:但存活对象比较少时,极为高效。
缺点:需要一块内存作为交换空间,造成内存浪费。
标记-整理算法:第一阶段遍历 也是从根节点开始遍历,第二个阶段标记 将可回收对象,第三个阶段直接扫描整个空间,并且清除未标记的对象。在标记清除算法的基础上进行了一个改进,它会将所有的存活对象往左端空闲处移动,并更新对应的指针。但它进行对象的移动,因此成本更高,但是解决了内存碎片的问题。
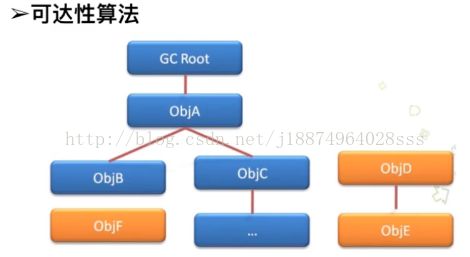
总结:存活对象比较少的时候采用复制算法处理,当存活对象比较多的时候就采用标记整理或者标记清除算法。
GC的触发条件:
1)JVM无法再为新对象分配内存空间的时候。
2)手动调用system.gc()时。
3)低优先级的GC线程被执行时。
其他的模块:像指令计算器、执行引擎、本地方法接口等等都是JVM比较底层的,与CPU打交道的一些接口了,不需要我们程序员过多的了解,所以不做跟多介绍。