小冰聊天机制综述
心理学研究表明,快乐和有意义的谈话常常是相伴而生的。因此,在社交媒体时代,越来越多的人被数字化连接,社交聊天机器人已成为一种重要的互动方式,这并不令人意外。与早期的聊天机器人不同,小冰是一款社交聊天机器人,旨在满足用户的沟通、情感和社交归属感需求,并具有同理心、个性和技能,集情商和智商于一身,以预期的CPS为衡量标准,优化用户的长期参与度。
小冰的整体结构包括三部分:用户体验层、对话引擎层和数据层。
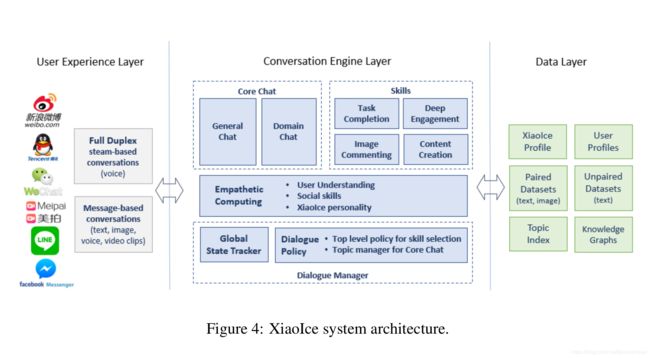
用户体验层的作用是将小冰和主流的平台做接入(微信、微博、QQ等),用户和小冰的对话可以使用两种方式:全双工,也就是用户和小冰通过语音电话交流,双方可以同时说话。另一种是基于信息的对话,小冰和用户交替的进行交流。这部分话还包括一些用于处理小冰和用户输入的组件,比如说语音识别和合成、图片解析和文本标准化。
对话引擎层包含了对话管理器、共情计算模块、核心聊天和对话技能四个子模块。对话管理模块持续的跟踪对话的状态,然后使用dialogue policy选择核心聊天或者对话技能模块来产生响应。共情计算模块不仅能理解用户输入的意图,还能理解对话过程中用户的情感倾向(情绪、意图、关于话题的看法、用户的背景和兴趣)。这体现了小冰的EQ,小冰的IQ体现在其核心谈话和对话技能上。
数据层的作用是存储核心聊天和对话技能的数据,(1)比如人类对话数据(文本对话对或者文本-图片对);(2)非对话数据和知识图谱;(3)小冰和所有注册用户的配置文件
聊天引擎
聊天引擎包含:会话管理、共情计算、核心聊天和聊天技能。
1.会话管理
会话管理作用是持续跟踪当前的对话内容(用户和小冰的文字对话记录)和对应的情感倾向,这些记录被编码成状态s,然后 D i a l o g u e P o l i c y Dialogue Policy DialoguePolicy会根据状态 s s s选择相应的动作,操作可以是由顶级策略激活的技能或核心聊天,以响应用户的特定请求。
顶层的策略根据当前的聊天状态选择激活Core Chat还是聊天技能模块。底层的策略作用于具体的聊天技能来管理对话的片段。假如用户输入文本,Core Chat会被激活。Topic Manager将会控制对话过程中话题的转换——开启新话题、在检测到用户兴趣后由General Chat转向Domain Chat。如果输入为图片或者视频片段,则加载Image Commenting技能。任务完成、深度参与和内容创建的技能由特定的用户输入和对话上下文触发。如果多个技能被同时触发,则根据置信度、优先级和会话上下文决定要激活的技能。为了保证对话的流畅性,系统会避免频繁的切换技能,只有在新技能激活的时候当前的技能才会被关闭。
会话管理还拥有一个话题管理的功能,用来决定是否转换话题的,以及新话题的推荐。一般来说,当发生下列情况的时候就需要转换话题:(1)Core Chat无法生成任何有效的响应候选,使用编辑响应的时候。(2)产生的内容仅仅是用户输入的简单重复,而不包含有效的信息的时候。(3)用户的反应是“好的”,“我知道了”,“继续说”的时候。
新话题的获取途径:高质量论坛,比如Instagram或者豆瓣流行的话题及其相关的评论和评论。根据当前对话的状态从数据集中检索新的话题,这些新话题使用机器学习到的决策树进行进一步的选择。标准有:(1)话题与上下文相关性、(2)话题的时效性、(3)与用户的兴趣相关、(4)话题的吸引力(5)话题被其他用户接受的比例。
2.共情计算
给定用户的查询Query、共情计算模块会结合上下文Context对Query进行重写得到 Q c Q_c Qc,共情向量征用户Query中的情感的共情向量 e R e_R eR,并且根据小冰的个性指定响应的共情向量 e R e_R eR,上面几个元素组合在一起就组成了共情计算单元的输出为 s = ( Q c , C , e Q , e R ) s=(Q_c, C, e_Q, e_R) s=(Qc,C,eQ,eR),表征的是聊天的状态。状态 s s s用于Dialogue Policy来选择对话技能。共情计算模块由上下文查询理解、用户理解和人际响应生成三部分组成。
上下文查询理解:作用是使用上下文信息重写用户的Query,具体步骤如下:
-
命名实体识别:标注query Q中的所有实体
-
将query Q中的所有代词用对应的实体代替
-
如果此时的Q不完整,则使用上下文信息做句子完型

用户理解
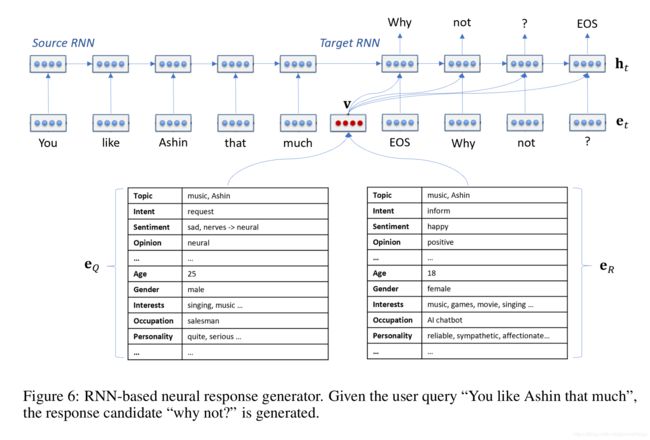
该组件基于 Q c Q_c Qc和 C C C生成查询共情向量 e Q e_Q eQ$由一系列表示用户意图、情感、主题、意见和用户角色的键值对组成,这些键值对使用一组机器学习分类器生成,如下所示。
- 主题检测标记用户是否遵循相同的主题,或者是否引入了新的主题。主题集是预设置的。
- 意图检测标签 Q c Q_c Qc使用的对话行为之一,如,问候,请求,通知等。
- 情绪分析检测用户的情绪,如高兴、悲伤、生气、神经,以及她的情绪在谈话过程中如何演变,如从高兴到悲伤。
- 意见检测检测用户对主题的反应,例如,积极的,消极的或神经的。
- 如果用户ID可用,将用户的个人资料(如性别、年龄、兴趣、职业、性格等)加入到在 e Q e_Q eQ的用户角色向量。
人际反应生成
该组件生成响应共情向量 e R e_R eR,它既指定要生成的响应的共情方面,又体现了小冰的角色。例如,图5 ©中的 e R e_R eR表示小冰通过遵循相同的主题(由主题管理器决定)来分享用户的感受,以一致和积极的方式作出回应,例如,用一套启发式方法,根据 e Q e_Q eQ中的意图、情绪和意见等值,计算出 e R e_R eR中的意图、情绪和意见等值。响应还必须符合小冰的角色,其键值对(例如年龄、性别和兴趣)是从预设的小冰配置文件中提取的。
3.Core Chat
核心聊天模块是小冰IQ和EQ的基础。配合同理心计算模块,核心聊条模块就能够接收文本输入并且产生符合人际交往的响应。核心聊天模块包含两个部分:
- 通用聊天:与用户进行开放式聊天,可以覆盖广泛的话题
- 领域聊天:负责深度话题响应的生成,比如音乐、电影和明星等话题。
通用聊天和领域聊天使用的是相同的模型,只有数据集的差别,下面以通用聊天模块为例做介绍
通用聊天模块的输入为对话状态 s = ( Q c , C , e Q , e R ) s=(Q_c, C, e_Q, e_R) s=(Qc,C,eQ,eR),Q_c表示使用上下文补全的Query,C表示上下文,e_Q表示Query的同理心向量、e_Q表示小冰的反应的同理心向量。通用聊天模块分为两个阶段:(1)生成候选响应,(2)对响应进行排序,接下来分别进行介绍。
基于Paired Data检索响应
Paired Data的来源有两个:(1)网络搜集的人类对话数据,比如社交网络、公共论坛、布告栏、新闻评论等。(2)小冰和用户的对话内容,目前,小冰70%的响应由以往的对话记录中检索获得。
为了保证这些Paired Data的质量,论文中对这些对话进行预处理,使用同理心计算模块计算得到 ( Q c , R , e Q , e R ) (Q_c, R, e_Q, e_R) (Qc,R,eQ,eR),然后过滤掉那些不符合小冰个性、乱码、包含不良内容或者拼写错误的对话对。然后使用Lucene对过滤后的成对数据集进行索引。在运行时,我们就可以使用具体的 Q c Q_c Qc从整理好的数据集中检索响应,论文使用关键字搜索和基于成对数据集的机器学习表示的语义搜索检索多达400个响应候选项备用。
这些检索到的响应质量不错,但是难以覆盖那些尚未广泛讨论的话题,为解决这个问题,论文还同时使用了另外两种响应生成方法。
神经网络生成响应
神经网络的优点是对于数据集未收纳的话题也能生成不错的响应。神经网络和检索两种方法是互补,基于神经网络的生成器能够提供对话的鲁棒性和高覆盖率,而基于检索的生成器则能对流行话题提供高质量的响应。
神经网络的输入是 ( Q c , e Q , e R ) (Q_c, e_Q, e_R) (Qc,eQ,eR),神经网络的任务是预测符合上下文、Query、用户和小冰情感的响应。论文首先将查询和响应的共情向量做线性组合,得到一个交互式表示 v v v,试图对小冰的响应进行建模。
v = σ ( W Q T e Q + W R T e R ) v = \sigma (W_Q^Te_Q+W_R^Te_R) v=σ(WQTeQ+WRTeR)
论文的使用seq2seq模型做文本生成,RNN单元使用GRU代替。编码器将Query编码成上下文变量,解码器每个时间步都使用 v , h i − 1 , y i − 1 v, h_{i-1}, y_{i-1} v,hi−1,yi−1,通过这个方式可以将共情信息注入到每个时间步的隐藏向量中,进而预设定的小冰性格能够约束整个响应生成过程,保证对话过程中响应的连贯性。
基于Unpaired Data检索生成方法
除了上述两种标准的对话式数据,网络上还存在一些高质量且庞大的非对话式数据,我们可以对其加以利用来提高响应的质量和话题覆盖率。
这些非对话式数据主要是一些从公开演讲和新闻报道中引用的句子,论文将这些句子作为候选的响应R。我们基于句子的讲述者的信息对句子进行共情向量的计算得到 ( R , e R ) (R, e_R) (R,eR),然后按照之前的方法进行过滤以匹配小冰的性格特点并且建立索引备用。
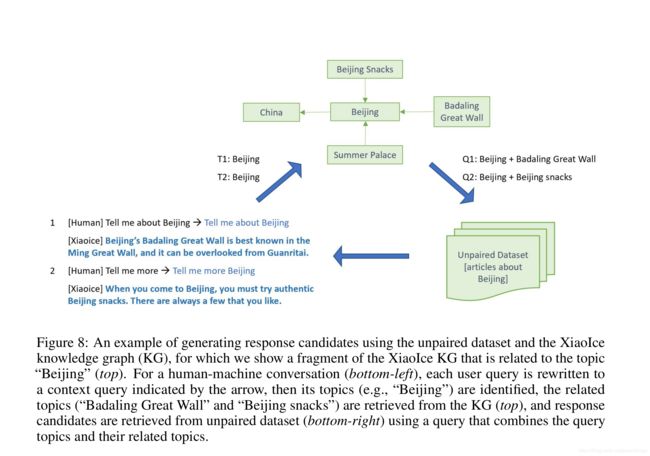
在运行时,为了防止检索到内容是用户输入的简单重复,我们需要为 Q c Q_c Qc扩展加入额外的话题。实现的方法是使用知识图谱的 ( h e a d , r e l a t i o n , t a i l ) (head,relation,tail) (head,relation,tail)三元组,Query中的实体对应head,使用对应的tail进行话题扩展,然后使用扩展的Query从Unpaired Data中检索响应。
以下图为例,这个过程包括三个步骤:
- 从用户的Query中确定其感兴趣的话题“Beijing”
- 对于每个话题,我们从知识图谱中检索出20个相关的话题,排序得到相关性最高的话题
- 结合 Q c Q_c Qc和KG中检索的相关话题,然后从Unpaired Data中检索相关的句子作为候选响应。
基于非对话数据的检索方法是上述两种方法的辅助方案,与神经网络生成方法一样,这种方法同样能够提高响应的话题覆盖率。相比于神经网络生成方法的相对简短的响应,这种方法的响应虽然质量稍差,但好在能够包含更多信息。
候选响应排序
为了从候选的响应中获得最恰当的选择,我们对所有的响应进行排序。如果有多个响应的得分超过阈值,则从中随机选择一个输出。
排序实际上是一个计算相关度得分的过程,给定对话状态 s = ( Q c , C , e Q , e R ) s=(Q_c, C, e_Q, e_R) s=(Qc,C,eQ,eR),对于一个候选响应 R ′ R' R′,主要基于以下四个特征计算排序得分
- 局部内聚特征:计算候选响应 R ′ R' R′和上下文Query Q c Q_c Qc的内聚得分,具体来说是使用DSSMs计算语义相似性。
- 全局内聚特征:使用DSSMs计算候选响应 R ′ R' R′和 ( Q c , C ) (Q_c, C) (Qc,C)的语义相似性,全局内聚在用户的的query没有关键信息的时候发挥作用,比如当用户的回答是“OK”、“why”,“I don’t know”。此时局部内聚没有太多作用。
- 共情匹配特征:一个好的响应应该能很好地符合小冰的个性,也就是候选响应 R ′ R' R′的共情向量 e R ′ e_{R'} eR′和小冰期待的共情向量 e R e_R eR应该满足一定程度的匹配。
- 检索匹配特征:这个特征只针对于那些从Paired Data集合中检索的响应,用户的上下文查询 Q c Q_c Qc必须和数据集中候选向量 R ′ R' R′对应的query一定程度上匹配。
DSSMs:Deep Semantic Similarity Model,计算一个paired-sentence的相似度
ranker的训练集包含许多 ( s t a t e , r e s p o n s e s ) (state, responses) (state,responses)对,每个对话对的标签是0-2的值。
- 0:响应没有做到共情或者与query无关,这样的响应可能会让谈话终止
- 1:响应是可被接受且与query相关的,这样的响应会对对话继续进行有帮助
- 2:响应能与用户共情,符合人际交往需求,让用户感到开心,这样的响应能有效促进谈话深入下去。
Editorial Response
如果响应生成器和ranker无法产生有效的响应,系统会挑选一个editorial response作为输出。选择editorial response的原则是满足共情的要求,这样才能保证让对话继续进行。当响应检索失败的时候,相比于“I don’t know”、“I am still learning to answer your question”,小冰更倾向于“Hmmm, difficult to say. What do you think"、”let us talk about something else“这样的回答。
4.对话技能
小冰拥有230项聊天技能,本节将这些技能分为四类:图像评论、内容创建、深度参与和任务完成分别介绍。
图像评论
聊天过程中的图像评论不仅仅要检测到其中的事物主体,还要关注事件、动作甚至情感倾向,这也是和普传统的图像标注/描述的最大的区别。对于人类来说,共情的图像评论对于推动有意义和有趣的对话更为重要。
图像评论的网络结构和Core Chat相似,对于给定的图片,分两阶段生成文本评论:候选评论的生成;排序。候选评论可以使用检索或者生成的方法获得。
基于检索的方法:收集(图像,评论)并且筛选出符合小冰个性的样本组成数据集,然后使用CNN网络将所有图片编码成表征着语义信息的向量。在运行的过程中,用户发出的图片通过相同的CNN网络获得的表征向量在数据库中进行检索,Cosine相似度最高的三张图片对应的comments作为候选评论。
基于生成的方法:这部分的模型是基于Microsoft Image Captioning system改进而来,增加了一些控制高阶情感和风格的模块。
ranking:给定对话状态 s = ( Q c , C , e Q , e R ) s=(Q_c, C, e_Q, e_R) s=(Qc,C,eQ,eR)以及两种方法获得的候选评论,使用一个提升树计算匹配得分的计算。与Core Chat相似,提升决策树有四个需要考虑的特征,不同之处在于图像评论需要计算图像和文字之间的相似性,论文中使用了DMSM(Deep Multimodal Similarity Model)来完成这个工作。 Q c Q_c Qc是从图像编码而来的表征向量。训练集的样本如下图所示:

内容生成
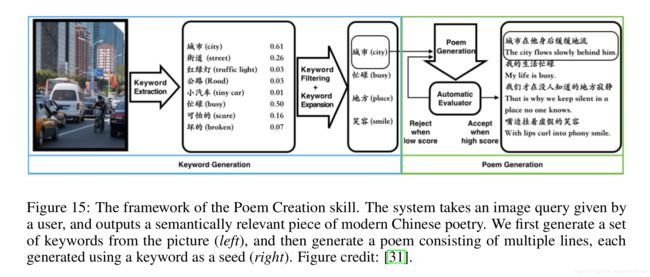
这类的技能包括:诗歌创造、唱歌、生成自定义儿童故事、小冰电台等等。下图是小冰创造现代诗的示意图。
深度参与
这类型技能旨在通过针对特定主题和设置,满足用户特定的情感和智力需求,从而提高用户的长期参与。这些技能可以在两个维度上分为不同的系列:从智商到情商,从一对一到小组讨论。
- 为了满足用户智力或者情感的需求,小冰能够在许多IQ的话题上分享自己的兴趣、经验和知识,涉及的范围从数学、历史到美食、旅游和明星。
- 一对一的对话让小冰和用户在私人空间分享话题和感受,与用户建立深厚的关系。另一方面,小冰能够帮助为有共同兴趣的用户形成一个用户群。

任务完成
这类技能包括:天气、硬件控制、日程安排、新闻推荐、必应知道等。 相比于Google Assistant、微软小娜这些私人助理,小冰能够更好的生成具有共情效果或者符合人际关系的回应,比如当用户询问中国的国土面积时,小冰会回答:“960万平方公里,和美国面积差不多”,而不是冷冰冰的数据。
5.将来的工作
- 更有效地人类对话过程中的内在激励进行建模,从而在模型中更好地集成强化学习
- 构建一个智能社交聊天机器人,能理解人类和周围的物质世界需要突破在许多领域的认知和有意识的人工智能,如移情计算、知识和记忆建模,可翻译的机器智能,常识推理,neural-symbolic推理、跨媒体和连续流AI和对话中反映人类情感或内在激励的有效建模。
6.论文中使用到的工具
- 检索索引建立:Lucene
- 建立知识图谱:Microsoft Satori
- 计算两句话的关系:DSSMs
- 图像描述:Microsoft Image Captioning system
- 文字、图像相似度比较
7.参考文献
[Arxiv 2018] The Design and Implementation of XiaoIce, an Empathetic Social Chatbot