经典的卷积网络架构(二)——GoogLeNet [inception v1] 详解
GoogLeNet出自论文Going Deeper With Convolutions
如有错误,欢迎指正!
(未完待续)
目录
论文阅读
补充知识点:1*1卷积的作用
网络结构分析
参考博文
参考代码
附录
网络结构图
网络具体参数
引言:整理经典的卷积网络架构
论文阅读
GoogLeNet的最大特点是使用了Inception模块
目的:
设计一种具有局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算和池化操作
问题:
1、在对图像进行操作的时候,图像中包含目标信息的部分具有很大的差异性,可大可小。也即,目标在整个图像中所占的比例或者说区域是不一样的。由于信息位置差异大,难以确定合适的卷积核的大小
2、比较深的网络容易造成过拟合,很难将梯度更新传递给整个网络
3、网络的‘深’有两层含义:一是高水平的组织方式(本文的构建Inception模块);二是以直接的方式来增加网络的深度。
那么后一种简单地堆叠较大的卷积层很消耗计算资源
解决方案:
设计Inception模块。
主要的设计思路是在一个卷积网络中寻找一个局部最优的稀疏结构,该结构被可获得的密集组件覆盖或者近似表达。
在3*3和5*5的卷积以及最大池化层之前加1*1的卷积层,将所有的子层输出级联起来并送入下一个Inception模块。
这种网中网的结构增加了神经网络的表现力。
说明:网络越往后,特征就越抽象,每个特征涉及到的感受野也越大,所以随着网络层数的增加,3*3和5*5的卷积核比例会增加。采用不同大小的卷积核意味着有不同大小的感受野,大尺寸的卷积核意味着较大的感受野也意味着更多的参数,用连接的小网络来代替单个的大网络,在保持感受野的同时又减少了参数量。
补充知识点:1*1卷积的作用
1、控制特征图的深度
可以用来调节通道数,对不同通道数的像素进行线性组合,然后,进行非线性操作,完成升维和降维的功能
2、减少参数
降维其实也是减少参数,因为特征图少了,参数也就减少了。
相当于在特征图的通道数上进行卷积,压缩了特征图,二次提取特征,使得新特征的表达效果更好
3、实现了通道的信息组合,并增加了非线性特征
在保持feature map尺度不变(不损失分辨率)的前提下,大幅度增加了非线性特征(主要是利用后面接的非线性激活函数实现)。
网络结构分析
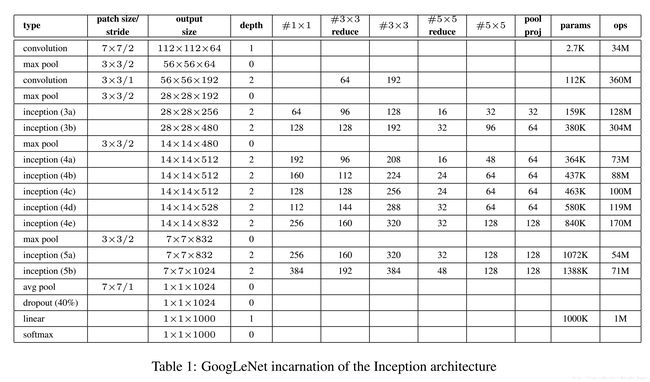
(如附录的网络结构图所示)有9个线性堆叠的Inception模块, 共22层(包括池化层有27层),在最后一个Inception处,使用全局平均池化来代替全连接层(为方便对输出灵活调整,实际仍然加了全连接层)
主要还是CNN的几个基本模块的组合:卷积层、池化层、全连接层,此外,添加了Inception模块
为了避免梯度消失的的问题,添加了2个辅助分类器(softmax),将中间某层的输出用作分类,以较小的权重(0.3)加到最终的分类结果中去(实际测试的过程不包含这两个辅助分类器)
0、INPUT——输入层
输出的图像尺寸大小为224*224*3
均进行零均值化的预处理操作
1、C1——卷积层
卷积核 7*7*64,padding=3,stride=2
卷积后 112*112*64 ((224-7+3*2)/2+1=112)
送入RuLU激活函数
max pooling 3*3,stride=2
池化后 56*56*64 ((112-3+1)/2+1=56)
2、C2——卷积层
卷积核 3*3*192,padding=1,stride=1
卷积后 56*56*192 ((56-3+1*2)/1+1=56)
送入RuLU激活函数
max pooling 3*3,stride=2
池化后 28*28*192 ((56-3+1)/2+1=28)
3a、Inception 3a层
![经典的卷积网络架构(二)——GoogLeNet [inception v1] 详解_第1张图片](http://img.e-com-net.com/image/info8/20a4ddecff67426788fbcec4e4514646.jpg)
![经典的卷积网络架构(二)——GoogLeNet [inception v1] 详解_第2张图片](http://img.e-com-net.com/image/info8/cb443127db334bb19b13faac78183ba3.jpg)
经过1*1*64的卷积,得28*28*64;送入ReLU激活函数。
经过1*1*96的卷积,得28*28*96;送入ReLU激活函数;经过3*3*128的卷积(padding=1),得28*28*128。
经过1*1*16的卷积,得28*28*16;送入ReLU激活函数;经过5*5*32的卷积(padding=2),得28*28*32。
经过3*3的max pooling (padding=1),得28*28*192;经过1*1*32的卷积,得28*28*32。
最后将四个分支合并:64+128+32+32=256
得到28*28*256
3b、Inception 3b层
4a、4b、4c、4d、4e、Inception 层
5a、5b、Inception 层
网络结构
基于tensorflow
# 模型架构文件 googlenet.py
'''
googlenet的网络结构
sstart at 2019.3.19
'''
import tensorflow as tf
import tensorflow.contrib.layers as layers
import tensorflow.contrib.framework as ops
# 定义Inception层
def get_inception_layer(inputs, conv11_size, conv33_11_size, conv33_size, conv55_11_size, conv55_size, pool_size):
with tf.variable_scope("conv_1*1"):
conv11 = layers.conv2d(inputs, conv11_size, [1, 1])
with tf.variable_scope("conv_3*3"):
conv33_11 = layers.conv2d(inputs, conv33_11_size, [1, 1])
conv33 = layers.conv2d(conv33_11, conv33_size, [3, 3])
with tf.variable_scope("conv_5*5"):
conv55_11 = layers.conv2d(inputs, conv55_11_size, [1, 1])
conv55 = layers.conv2d(conv55_11, conv55_size, [5, 5])
with tf.variable_scope("pool"):
pool = layers.max_pool2d(inputs, [3, 3], stride=1)
pool11 = layers.conv2d(pool, pool_size, [1, 1])
return tf.concat([conv11, conv33, conv55, pool11], 3)
# 定义网络中的辅助分类器(softmax)
def aux_logit_layer(inputs, n_classes, is_training):
with tf.variable_scope('ave_pool'):
ave_pool1 = layers.avg_pool2d(inputs, [5, 5], stride=3)
with tf.variable_scope("conv11"):
conv11 = layers.conv2d(ave_pool1, 128, [1, 1])
with tf.variable_scope("flatten"):
flat = tf.reshape(conv11, [-1, 2048])
with tf.variable_scope("fc1"): # activation_fn=None激活函数默认为relu函数
fc = layers.fully_connected(flat, 2048, activation_fn=None)
with tf.variable_scope("drop"):
drop = layers.dropout(fc, 0.3, is_training=is_training)
with tf.variable_scope("linear"):
linear = layers.fully_connected(drop, n_classes, activation_fn=None)
with tf.variable_scope("soft"):
soft = tf.nn.softmax(linear)
return soft
def googlenet(inputs, rate=0.4, n_classes=10):
with tf.name_scope('googlenet'):
conv1 = tf.nn.relu(layers.conv2d(inputs, 64, [7, 7], stride=2, scope='conv1'))
pool1 = layers.max_pool2d(conv1, [3, 3], scope='pool1')
conv2 = tf.nn.relu(layers.conv2d(pool1, 192, [3, 3], stride=1, scope='conv2'))
pool2 = layers.max_pool2d(conv2, [3, 3], stride='pool2')
with tf.variable_scope('Inception_3a'):
incpt3a = get_inception_layer(pool2, 64, 96, 128, 16, 32, 32)
with tf.variable_scope("Inception_3b"):
incpt3b = get_inception_layer(incpt3a, 128, 128, 192, 96, 64)
pool3 = layers.max_pool2d(incpt3b, [3, 3], scope='pool3')
with tf.variable_scope("Inception_4a"):
incpt4a = get_inception_layer(pool3, 192, 96, 208, 16, 48, 64)
with tf.variable_scope("aux_logit_layer1"):
aux1 = aux_logit_layer(incpt4a, n_classes, is_training=True)
with tf.variable_scope("Inception_4b"):
incpt4b = get_inception_layer(incpt4a, 160, 112, 224, 24, 64, 64)
with tf.variable_scope("Inception_4c"):
incpt4c = get_inception_layer(incpt4b, 128, 128, 256, 24, 64, 64)
with tf.variable_scope("Inception_4d"):
incpt4d = get_inception_layer(incpt4c, 112, 144, 288, 32, 64, 64)
with tf.variable_scope("aux_logit_layer2"):
aux2 = aux_logit_layer(incpt4d, n_classes, is_training=True)
pool4 = layers.max_pool2d(incpt4d, [3, 3], scope='pool4')
with tf.variable_scope("Inception_5a"):
incept5a = get_inception_layer(pool4, 256, 160, 320, 32, 128, 128)
with tf.variable_scope("Inception_5b"):
incept5b = get_inception_layer(incept5a, 384, 192, 384, 48, 128, 128)
pool5 = layers.avg_pool2d(incept5b, [7, 7], stride=1, scope='pool5')
reshape = tf.reshape(pool5, [-1, 2048])
drop = layers.dropout(reshape, rate, is_training=True)
linear = layers.fully_connected(drop, n_classes, activation_fn=None, scope='linear')
# soft = tf.nn.softmax(linear)
return linear, aux1, aux2
def losses(logits, labels):
with tf.variable_scope('loss') as scope:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels,
name='xentropy_per_example')
loss = tf.reduce_mean(cross_entropy, name='loss')
tf.summary.scalar(scope.name + '/loss', loss)
return loss
def trainning(loss, learning_rate):
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
def evaluation(logits, labels):
with tf.variable_scope('accuracy') as scope:
correct = tf.nn.in_top_k(logits, labels, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float16))
tf.summary.scalar(scope.name + '/accuracy', accuracy)
# 模型训练文件 train.py
# 数据预处理文件 prework.py
参考博文
1、大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
2、一文概览Inception家族的「奋斗史」
还有几篇参考文献忘记链接了,如有侵权,请与我联系!
参考代码
1、da-steve101/googlenet
2、PanJinquan/tensorflow_models_nets
附录
网络结构图
![经典的卷积网络架构(二)——GoogLeNet [inception v1] 详解_第3张图片](http://img.e-com-net.com/image/info8/bb491728900749f0944b4ff817b44f17.jpg)
网络具体参数