Elasticsearch教程---Elasticsearch简介与基本概念(二)
第三章 ElasticSearch简介
3.1 ElasticSearch vs Lucene的关系
ElasticSearch vs Lucene的关系,简单一句话就是,成品与半成品的关系。
(1)Lucene专注于搜索底层的建设,而ElasticSearch专注于企业应用。
(2)Luncene是单节点的API,ElasticSearch是分布式的。
(3)Luncene需要二次开发,才能使用。不能像百度或谷歌一样,它只是提供一个接口需要被实现才能使用。
ElasticSearch直接拿来用。
3.2 Elasticsearch与Solr对比
Solr与elasticsearch是当前两大最流行的搜索应用服务器,他们的底层都是基于lucene。
- Elasticsearch是分布式的,不需要其他组件,Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- Elasticsearch设计用于云计算中,处理多租户不需要特殊配置,而Solr则需要更多的高级设置。
- 当单纯的对已有数据进行搜索时,Solr更快,实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势,随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化
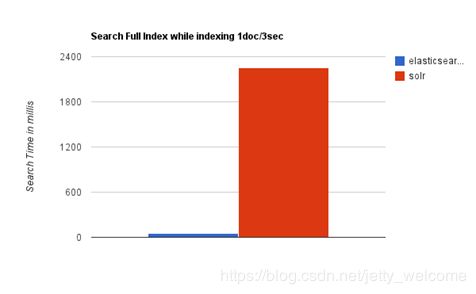
Elasticsearch与Solr的性能测试比较:
当单纯的对已有数据进行搜索时,Solr更快。

当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。

随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
3.3 Elasticsearch特性
3.3.1 安装管理方便
Elasticsearch没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群。
3.3.2 大规模分布式
Elasticsearch允许你开始小规模使用,但是随着你使用数据的增长,它可以建立在横向扩展的开箱即用。当你需要更多的容量,只需添加更多的节点,并让集群重组,只需要增加额外的硬件,让集群自动利用额外的硬件。
可以在数以百计的服务器上处理PB级别的数据。
节点对外表现对等(每个节点都可以用来做入口);加入节点自动均衡,可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
-
将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
-
将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
-
冗余每一个分片,防止硬件故障造成的数据丢失。
-
将集群中任意一个节点上的请求路由到相应数据所在的节点。
-
无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移
3.3.3 多租户的支持
ES处理多租户不需要特殊配置,可根据不同的用途分索引;可以同时操作多个索引。
ES 的多租户简单的说就是通过多索引机制同时提供给多种业务使用,每种业务使用一个索引。我们可以把索引理解为关系型数据库里的库,那多索引可以理解为一个数据库系统建立多个库给不同的业务使用。
在实际使用时,我们可以通过每个租户一个索引的方式将他们的数据进行隔离,并且每个索引是可以单独配置参数的(可对特定租户进行调优),这在典型的多租户场景下非常有用:例如我们的一个多租户应用需要提供搜索支持,这时可以通过 ES 根据租户建立索引,这样每个租户就可以在自己的索引下搜索相关内容了
3.3.4 高可用性
Elasticsearch集群是有弹性的 - 他们会自动检测到新的或失败的节点,以及重组和重新平衡数据,以确保数据安全。
3.3.5 操作持久化
Elasticsearch把数据安全第一。文档改变被记录在群集上的多个节点上的事务日志(transaction logs)中记录,以减少任何数据丢失的机会。
3.3.6 友好的RESTful API
Elasticsearch是API驱动。几乎任何动作都可以用一个简单的RESTful API使用JSON基于HTTP请求。ElasticSearch 提供多种语言的客户端 API。
Java
JavaScript
Groovy
.NET
PHP
Perl
Python
Ruby
3.4 典型使用案例
- 维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
- 英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
- StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
- GitHub使用Elasticsearch来检索超过1300亿行代码。
- 每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
第四章 Elasticsearch的基本概念

4.1 索引(index)
索引是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。对于我们的程序而言,文档存储在索引(index)中。剩下的细节由Elasticsearch关心既可。(索引的名字必须是全部小写,不能以下划线开头,不能包含逗号)
4.2 类型(type)
类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表。在Elasticsearch中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
es 6.0 开始不推荐一个index下多个type的模式,并且会在 7.0 中完全移除。在 6.0 的index下是无法创建多个type
4.3 文档(documents)
文档是ElasticSearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。 在Elasticsearch中,文档(document)这个术语有着特殊含义。它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasticsearch中)。
4.4 字段(fields)
文档由字段组成,相当于关系数据库中列的属性,不同的是ES的不同文档可以具有不同的字段集合。
4.5 节点与集群
一个集群是由一个或多个节点组成的集合,集群上的节点将会存储数据,并提供跨节点的索引和搜索功能。
集群通过一个唯一的名称作为标识,节点通过设置集群名称就可以加入相应的集群,当然这需要节点所在的网络能够发现集群。所以要注意在同一个网络中,不同环境、服务的集群的名称不能重复。
一个节点就是一个 Elasticsearch 服务(实例),可以实现存储数据,索引并且搜索的功能。和集群一样,每个节点都有一个唯一的名称作为身份标识,如果没有设置名称,默认使用 UUID 作为名称。如果想更好的管理集群,最好给每个节点都定义上有意义的名称,在集群中区分出各个节点。
节点通过设置集群名称,在同一网络中发现具有相同集群名称的节点,组成集群。默认的集群名称为 elasticsearch 。如果在同一网络中只有一个节点,则这个节点成为一个单节点集群,换句话说就是每个节点都是功能齐全的服务。
4.6 分片与副本
如果一个索引具有很大的数据量,它的数据量可能会超出单个节点的容量限制(硬盘容量),而且单个节点数据量过大,执行性能也会随之下降,每个搜索请求的执行效率都会降低。
为了解决上述问题, Elasticsearch 提出了分片的概念,索引将划分成多份,称为分片。当创建索引时,可以很简单的指定想要的分片数量。每个分片都是功能齐全的,独立的“索引”,驻留在集群的各个节点中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tTRvkmKG-1584341454077)(mdpic/Elasticsearch集群结构.png)]
Elasticsearch 中的分片其实就是 Lucene 索引。
分片的作用
分片有两个主要的用处:
- 水平划分数据
- 多个分片分发工作,并行执行,从而提高性能,吞吐量
分片分为主分片和副本分片。副本分片主要功能如下:
- 高可用性:副本分片作为数据备份,当某个主分片发生故障时,副本分片能够成为新的主分片,保证服务的可用性。
- **提高性能:**副本分片本身也是一个功能齐全的独立的分片(所以才能够随时取代故障的主分片),当有查询请求时,既可以在主分片中完成查询,也可以在副本分片中完成查询,当然数据添加、更新的操作只能在主分片中完成。
副本分片与主分片需要分配在不同的节点上,一是为了更好的均衡负载,不同节点上二是节点发生故障时,主分片和副本分片一起故障,没法保证高可用性。所以 Elasticsearch 集群最好要有 2 个节点或以上。
一个索引默认有 5 个主分片,每个主分片默认有 1 个副本分片,即创建一个索引默认会有 10 个分片。

4.7 实际应用
场景1:数据量大小约为10GB, 用于输入时自动提示场景,数据每天定时更新部分字段。ES集群有5台机器。
方案一:主分片数=1,副分片数=4,每个节点持有一个分片。
- 优点:每个节点持有一个分片,读请求可以在一个分片获取结果,不需要合并结果等操作。
- 缺点:索引写入的时候,全部请求到主分片的机器,再由主分片同步到副分片,由于副分片较多,写入过程变慢。
方案二:主分片数=2,副分片数=4,每个节点持有一个主分片和一个副分片。
- 优点:副分片变少,对写入操作友好。
- 缺点:多个分片分散在不同节点上,请求会发布到各个分片号上取topN汇总。由于评分是在各个分片内进行,在本场景中存在TF/IDF评分差异,导致返回结果排序问题。
考虑业务场景,最终选择方案一。
**场景2:**在ELK(ELK是Elasticsearch、Logstash、Kibana的简称)中,想一下, 大部分的 Logstash 用户并不会频繁的进行搜索, 甚至每分钟都不会有一次查询. 所以这种场景, 推荐更为经济使用的设置. 在这种场景下, 搜索性能并不是第一要素, 所以并不需要很多副本。
4.8 总结
-
读远大于写的场景,可以减少主分片个数,增加副本数,提升读吞吐率,前提是写的优先级不高。极端情况下单分片多副本可以最大程度提升总的读吞吐。
-
写远大于读的场景,最大程度分配主分片个数,一个机器一个,并最大程度减少副本数(极端情况下集群规模不大且可用性优先级较低时可以不要副本)。
4.9 分片的大小和数量怎么设定?
注1:小的分片会造成小的分段,从而会增加开销。我们的目的是将平均分片大小控制在几 GB 到几十 GB 之间。对于基于时间的数据的使用场景来说,通常将分片大小控制在 20GB 到 40GB 之间。
注2:由于每个分片的开销取决于分段的数量和大小,因此通过 forcemerge 操作强制将较小的分段合并为较大的分段,这样可以减少开销并提高查询性能。 理想情况下,一旦不再向索引写入数据,就应该这样做。 请注意,这是一项比较耗费性能和开销的操作,因此应该在非高峰时段执行。
注3:我们可以在节点上保留的分片数量与可用的堆内存成正比,但 Elasticsearch 没有强制的固定限制。 一个好的经验法则是确保每个节点的分片数量低于每GB堆内存配置20到25个分片。 因此,具有30GB堆内存的节点应该具有最多600-750个分片,但是低于该限制可以使其保持更好。 这通常有助于集群保持健康。
注4:如果担心数据的快速增长, 建议根据这条限制: ElasticSearch推荐的最大JVM堆空间是 30~32G, 把分片最大容量限制为 30GB, 然后再对分片数量做合理估算。例如, 如果的数据能达到 200GB, 则最多分配7到8个分片。
完整代码:https://github.com/chutianmen/elasticsearch-examples