Python 文本解析器
一、实验介绍
1.1 实验内容
讲解一个使用 Python 来解析纯文本生成一个 HTML 页面的小程序。
将学习和实践以下知识点:
Python 基本语法
HTML 标记语言1.2 实验知识点
Python:一种面向对象、解释型计算机程序设计语言,用它可以做 Web 开发、图形处理、文本处理和数学处理等等。
HTML:超文本标记语言,主要用来实现网页。1.3 实验环境
Python 3.6.5
pychram1.4 实验结果
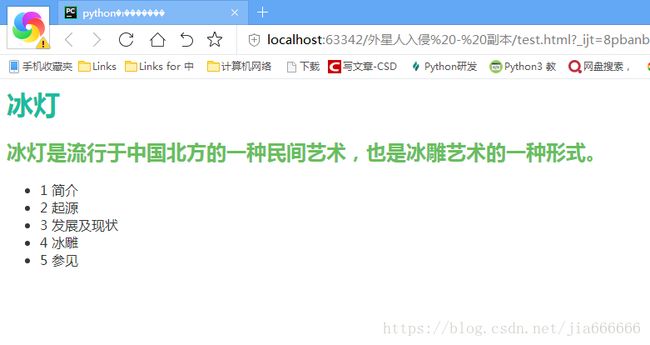
纯文本文件:
冰灯
冰灯是流行于中国北方的一种民间艺术,也是冰雕艺术的一种形式。
-1 简介
-2 起源
-3 发展及现状
-4 冰雕
-5 参见解析后生成的 HTML 页面如下图

二、项目文件结构
本项目中将创建以下的代码文件,每个文件的作用简介如下:
util.py:实现文本块生成器把纯文本分成一个一个的文本块,以便接下来对每一个文本块进行解析
handlers.py:为文本块打上合适的 HTML 标记
rules.py:设计一定的规则来判断每个文本块交给处理程序将要加什么标记
markup.py:对整个文本进行解析的程序
三、实验步骤
一共有文本块生成器、处理程序、规则、解析和运行与测试五个步骤。
3.1 文本块生成器
首先我们需要有一个文本块生成器把纯文本分成一个一个的文本块,以便接下来对每一个文本块进行解析,util.py 代码如下:
#!/usr/bin/python
# encoding: utf-8
def lines(file):
"""
生成器,在文本最后加一空行
"""
for line in file: yield line
yield '\n'
def blocks(file):
"""
生成器,生成单独的文本块
"""
block = []
for line in lines(file):
if line.strip():
block.append(line)
elif block:
yield ''.join(block).strip()
block = []strip() 函数可以去除一个字符串前后的空格以及换行符,如果在strip()函数添加不同的参数,如strip(“me”),则可以去除字符串前后的”me”字符。
s = ” This is me\n”
s = s.strip()
s
‘This is me’
s = s.strip(“me”)
s
‘This is ‘
yield()会返回一个生成器(generator)。如果对generator以及对 yiels 语句不太熟悉,建议先阅读yield解释(https://pyzh.readthedocs.io/en/latest/the-python-yield-keyword-explained.html)。
3.2 处理程序
假设我们已经知道一个文本块是 title/paragraph/heading/list,我们通过 handlers.py 给他们打上合适的 HTML 标记。代码如下:
'''对整个文本进行解析的程序'''
#!/usr/bin/python
# encoding: utf-8
import sys, re
from handlers import *
from util import *
from rules import *
class Parser:
"""
解析器父类
"""
def __init__(self, handler):
self.handler = handler
self.rules = []
self.filters = []
def addRule(self, rule):
"""
添加规则
"""
self.rules.append(rule)
def addFilter(self, pattern, name):
"""
添加过滤器
"""
def filter(block, handler):
return re.sub(pattern, handler.sub(name), block)
self.filters.append(filter)
def parse(self, file):
"""
解析
"""
self.handler.start('document')
for block in blocks(file):
for filter in self.filters:
block = filter(block, self.handler)
for rule in self.rules:
if rule.condition(block):
last = rule.action(block, self.handler)
if last: break
self.handler.end('document')
class BasicTextParser(Parser):
"""
纯文本解析器
"""
def __init__(self, handler):
Parser.__init__(self, handler)
self.addRule(ListRule())
self.addRule(ListItemRule())
self.addRule(TitleRule())
self.addRule(HeadingRule())
self.addRule(ParagraphRule())
self.addFilter(r'\*(.+?)\*', 'emphasis')
self.addFilter(r'(http://[\.a-zA-Z/]+)', 'url')
self.addFilter(r'([\.a-zA-Z]+@[\.a-zA-Z]+[a-zA-Z]+)', 'mail')
"""
运行程序
"""
handler = HTMLRenderer()
parser = BasicTextParser(handler)
parser.parse(sys.stdin)在上面的代码中 callable() 函数能够检查一个函数是否能够被调用。如果能够被调用返回True。
gerattr()函数则是返回一个对象的属性值。举例来说,getattr(x, ‘foo’, None) 就相当于是 x.foo,而如果没有这个属性值foobar,则返回我们设定的默认值None。
3.3 规则
有了处理程序和文本块生成器,接下来就需要一定的规则来判断每个文本块交给处理程序将要加什么标记,rules.py 代码如下:
'''设计一定的规则来判断每个文本块交给处理程序将要加什么标记'''
#!/usr/bin/python
# encoding: utf-8
class Rule:
"""
规则父类
"""
def action(self, block, handler):
"""
加标记
"""
handler.start(self.type)
handler.feed(block)
handler.end(self.type)
return True
class HeadingRule(Rule):
"""
一号标题规则
"""
type = 'heading'
def condition(self, block):
"""
判断文本块是否符合规则
"""
return not '\n' in block and len(block) <= 70 and not block[-1] == ':'
class TitleRule(HeadingRule):
"""
二号标题规则
"""
type = 'title'
first = True
def condition(self, block):
if not self.first: return False
self.first = False
return HeadingRule.condition(self, block)
class ListItemRule(Rule):
"""
列表项规则
"""
type = 'listitem'
def condition(self, block):
return block[0] == '-'
def action(self, block, handler):
handler.start(self.type)
handler.feed(block[1:].strip())
handler.end(self.type)
return True
class ListRule(ListItemRule):
"""
列表规则
"""
type = 'list'
inside = False
def condition(self, block):
return True
def action(self, block, handler):
if not self.inside and ListItemRule.condition(self, block):
handler.start(self.type)
self.inside = True
elif self.inside and not ListItemRule.condition(self, block):
handler.end(self.type)
self.inside = False
return False
class ParagraphRule(Rule):
"""
段落规则
"""
type = 'paragraph'
def condition(self, block):
return True3.4 解析
当我们知道每一个文本块进行怎么样的处理,交给谁去处理之后,我们就可以对整个文本进行解析了,markup.py 代码如下:
'''对整个文本进行解析的程序'''
#!/usr/bin/python
# encoding: utf-8
import sys, re
from handlers import *
from util import *
from rules import *
class Parser:
"""
解析器父类
"""
def __init__(self, handler):
self.handler = handler
self.rules = []
self.filters = []
def addRule(self, rule):
"""
添加规则
"""
self.rules.append(rule)
def addFilter(self, pattern, name):
"""
添加过滤器
"""
def filter(block, handler):
return re.sub(pattern, handler.sub(name), block)
self.filters.append(filter)
def parse(self, file):
"""
解析
"""
self.handler.start('document')
for block in blocks(file):
for filter in self.filters:
block = filter(block, self.handler)
for rule in self.rules:
if rule.condition(block):
last = rule.action(block, self.handler)
if last: break
self.handler.end('document')
class BasicTextParser(Parser):
"""
纯文本解析器
"""
def __init__(self, handler):
Parser.__init__(self, handler)
self.addRule(ListRule())
self.addRule(ListItemRule())
self.addRule(TitleRule())
self.addRule(HeadingRule())
self.addRule(ParagraphRule())
self.addFilter(r'\*(.+?)\*', 'emphasis')
self.addFilter(r'(http://[\.a-zA-Z/]+)', 'url')
self.addFilter(r'([\.a-zA-Z]+@[\.a-zA-Z]+[a-zA-Z]+)', 'mail')
"""
运行程序
"""
handler = HTMLRenderer()
parser = BasicTextParser(handler)
parser.parse(sys.stdin)3.5 运行与测试
运行程序(纯文本文件为 test.txt,生成 HTML 文件为 test.html):
python markup.py < test.txt > test.html获得 test.html 文件之后,我们想在浏览器中看一下我们的文本解释效果。