MongoDB 应用场景、避坑事项与最佳实践
1、如何学习MongoDB?
MongoDB日趋流行,作为一个开发/运维,如何快速上手MongoDB?或者有哪些推荐的学习MongoDB的方式?
写在最前:请使用mongodb 3.2或以上版本进行学习,或者直接从3.4开始。另外,百度出来的中文资料,请查看15年及以后的信息,可以少走很多弯路。另外,建议使用linux系统进行学习,方便排错。
英文比较好的小伙伴:
如果英语不好,建议先花时间学英语
1. 强烈推荐MongoDB官方的教程,MongoDB在线大学,无论开发还是DBA,都可以找到适合自己的视频教程。因为视频有英语字幕,听不懂的同学,多多暂停,看一下字幕都能理解。
每节课结束都有相应的作业,可以自己用来练手。而且作业都会有类似一键脚本的东西,帮你配置好需要的实验环境。完成作业后,会有不少成就感,让自己可以有学下去的动力。另外,每次作业和最后的考试都通过会有一张结业证书。
最后,MongoDB官方的新员工也是从这里开始学习的,而且课程更新频率也很高。
2. MongoDB的官方文档,文档地址,选择自己想要看到章节,文档的内容写的很详细,而且有的地方直接提供web shell的环境,让你实际操作。
3. MongoDB工程师网站,网站地址,这里可以深入看到一些MongoDB原理的内容。此外也推荐看percona公司关于MongoDB的一些博文
看到英语就头疼的小伙伴:
暂时没找到较好的基础视频教程,IT大咖说上面有MongoDB使用案例的视频,可以一看,不过不适合初学,需要有一定的基础。
1. 先从看书开始,强烈推荐《MongoDB实战 第二版》,因为这本书是3.x版本的,相对来说内容比较新。然后《MongoDB权威指南 第二版》,这本内容蛮多的,不过已经过时了。《MongoDB应用设计模式》关于MongoDB设计适用的书,非常短,值得一看。
2. MongoDB中文社区有部分官方文档的翻译。
3. MongoDB中文社区的公众号及博客,云栖社区MongoDB板块
2、Mongodb用在什么样的场景合适?
Mongodb是最近流行的NOsql数据库,但一直对其用在什么场景合适而不清楚。主要知道这个数据库是快速开发很合适。但一直归属到大数据板块,想要咨询下Mongodb适用的场景有哪些?在大数据板块充当什么角色哪?
常见应用场景:
1. 最近单的入手就是存log,因为mongodb本身存的就是json,可以很方便的接入各种存储日志的地方。然后可以做成相关监控报表,比如说APM,NPM等,比如说千寻位置
2. 其他的话要看题主所在的行业了,不同的行业有不同的用法,比如说信息的展示等等
3. 在网游界,MongoDB也非常流行,比如说最近大火的阴阳师,数据库用的就是MongoDB
大数据方面,MongoDB有以下三个优势:
1. 自带sharding,快速得水平扩展,为存储海量数据带来便捷
2. 官方提供驱动,可以直接对接hadoop或者spark
3、能提供几个mongodb的案例吗?
国外的例子太多,在mongodb的官网上就有,无论是金融、传统等行业,我这里说一下国内的案例
金融:
非核心业务的话几乎每家知名企业都在尝试使用,比如某国有银行用在了apm系统,平安科技用在了内部系统和日志系统。核心业务的话互联网金融企业考拉理财的大多数业务都在mongodb上
传统:
这一块了解不多,目前知道东方航空用在了下一代旅客服务系统
互联网:
互联网使用的企业非常多。妈妈帮的核心系统,小红书的核心系统,高德的app展示,千寻位置的日志收集分析,Teambition的核心系统,阴阳师的数据库,360的移动搜索等
4、Mongodb相对hbase、MySQL来说,有哪些优势?
这里就简单说一下题主说的几个数据库中,mongodb优势的地方
vs hbase:
hbase是基于row key存储宽列的一款nosql,乍一看结构类似mongodb的_id主键和可变长的列数量。
具体的原理和区别这里不展开。
mongodb的优势在于轻量化部署非常简单,不用像hbase那样搭一整套hadoop集群,即开即用。hbase更适合离线的海量数据分析
vs mysqlpg:
这两款都是关系型数据库,所以放在一起比较。
MongoDB的优势主要有3个。
1、结构灵活,表结构更改比较自由,不用每次alter的时候付出代价,适合业务快速迭代,而且json原生和大多数的语言有天然的契合。还支持数组,嵌套文档等数据类型
2、自带高可用,自动主从切换(副本集)
3、自带水平分片(分片),内置了路由,配置管理。应用只要连接路由,对应用来说是透明的。
5、MongoDB是否支持事务?
MongoDB只支持行级的事务,或者说支持原子性,单行的操作要么全部成功,要么全部失败。
需要事务的话,得自己用代码实现二次提交作,模拟事务的功能,官方文档有相关的说明。
https://docs.mongodb.com/manual/tutorial/perform-two-phase-commits/
这里放一个小彩蛋,因为WiredTiger引擎本身支持事务,官方正考虑在MongoDB上实现事务。
6、MongoDB黑客勒索事件是怎么回事?
这次闹的沸沸扬扬的黑客事件主要是用户自己的MongoDB没有打开用户验证,而且把MongoDB保护在公网。打个比方就是你家住在闹市区,晚上没人的时候,门还没锁,然后就被小偷光顾了。
要解决问题很简单,首先,千,万,不,要把MongoDB暴露在公网,如果要外网访问,无论是还是ssh隧道都行。
此外,打开Mongodb的验证,这样所有操作都要用户名密码了但是短连接会因为验证造成资源损耗,这里就自己权衡了。阿里云和腾讯云针对这个问题都做了优化。
7、MONGODB数据库备份只能用mongodump吗?
常用而且通用的方法就是mongodump
备份还有这几种方法:
1. mongoexport(这个是逻辑备份,备份出json和csv)
2. 做磁盘快照
3. 停机后冷拷贝
8、Mongo大数据迁移方案,迁移过程中需要注意什么,集群的时候呢?
你的迁移是指怎么迁移?一般来说mongodump来迁移即可。
集群迁移的话,建议直接在目标服务器上面搭建从节点。全部搭建完之后,把新的从节点升级为主节点,再把老机器剔除出集群。
不过如果数据量太大,而且平时数据更改很频繁的话,初始化同步的过程可能Oplog不够用。
方案1
先升级到3.4版本,这个版本在初始化同步的时候会抓取oplog
方案2
停机一台从节点,物理复制到局域网中心机器,当从节点启动
这台从节点配置一个大oplog,然后迁移目标端的从节点从这台oplog从节点同步
9、MONGODB的水平扩展是什么原理?
MONGODB的水平扩展是依赖什么原理哪?如果由于前期规划不足,导致需要通过扩容的方式提高MOGODB的能力,在给他水平扩展的时候是否复杂哪?是否将原有数据重新同步?是否可以在线处理哪?
MongoDB的水平扩展主要依赖的原理相当有一个config组件负责管理元数据的位置,然后mongo的路由会从config取得数据所在或者应该在的数据节点位置,从而去对应的数据节点读写(路由本身也会有缓存)
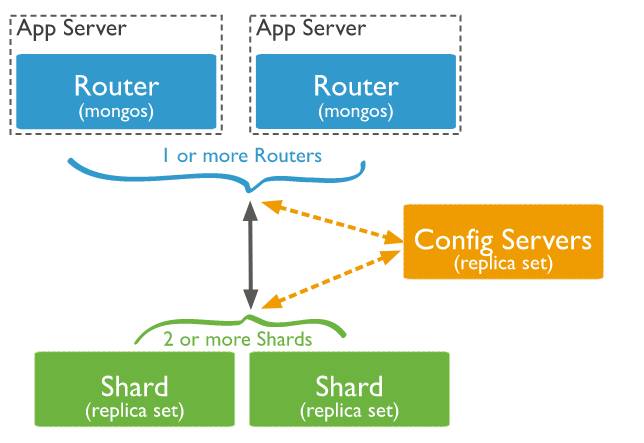
我这里只是简单的说明,具体可以看官方文档sharding一章节
水平扩展的步骤不算复杂,不用将数据重新同步(但是从单点到副本集还是要做同步的),整个过程可以在线处理(不过3.4开始,在设置为sharding模式的时候需要滚动重启一下mongod进程,加上shardsvr的配置)
具体看这一篇文档
https://docs.mongodb.com/manual/tutorial/convert-replica-set-to-replicated-shard-cluster/
10、mongodb集群实际应用中如何选择片键和索引?
分片方式有两种:
1. 范围分片:这个类似分区表,合适的分片条件可以增加查询性能,更优的设计可以优化写入性能。
比如说数据1、2在节点a,数据3、4、5在节点b,数据6、7在节点c
2. hash分片:使数据均匀落在不同的分片节点上,优化写入性能,但是读的话需要扫所有节点
好的片键需要以下的考量:
1. 片键中文档尽可能的少,避免单chunk过大,这个会导致无法balance
2. 片键离散分布,这样可以在不同的节点写入(避免自增主键或者时间戳单独的做片键,这样会存在写入热点问题)
3. 大多数的查询的条件要包含你的分片条件
举一个例子:
一个日志记录系统,有hostname,timestamp,message等信息,经常会有查询需求,这里用范围分片
很多人可能会直接拿timestamp做范围片键,这样可以覆盖到常见的时间查询需求,但是所有写的请求都落到同一台,造成热点问题。而且查hostname的时候会扫描所有节点。
好的方案就是选择hostname和timestamp做一个联合的分片条件,一来数据分布更均匀,二来基于主机和时间的查询也可以优化到。
推荐两个网址:
https://yq.aliyun.com/articles/60096?spm=5176.8091938.0.0.Kxyh2C
http://www.mongoing.com/blog/post/on-selecting-a-shard-key-for-mongodb
11、MongoDB如何进行升级?
这里升级以副本集为例
小版本升级:
非常简单,直接停机,替换二进制文件,启动即可。先升级从节点,再升级主节点,避免业务中断。
大版本升级(不更换存储引擎):
也是直接替换即可,有的版本(如升级到3.4),想启动新版本功能,需要执行
db.adminCommand( { setFeatureCompatibilityVersion: "3.4" } )
大版本升级(换存储引擎):
数据文件需要重做,新建从节点,升级那个从节点的二进制文件,配置使用新的引擎,将数据完整的同步,然后该从节点升级为主节点,其他节点正常升级。
不建议跨大版本升级,否则会有不确定的问题。
最后,官方文档非常详细,一步一步的操作都有
https://docs.mongodb.com/manual/release-notes/3.4-upgrade-replica-set/
12、Mongodb升级报错?
mongodb副本集从2.6升级到3.0,密码验证升级了 报如下错误
Failed to authenticate xxx@xxxx with mechanism MONGODB-CR: AuthenticationFailed MONGODB-CR credentials missing in the user document
应该如何解决呢? 是把原来的用户删了,用3.0的在创建一个一样的用户吗? 有没有更好的办法呢?
原因是因为3.0开始mongodb的认证加密模式从Mongodb-cr改到了sha1
治标方法:
先关闭验证,然后把
admin库中system.version表的
{ "_id" : "authSchema", "currentVersion" : 3 }
那个currentVersion改成3(默认是5),就可以了
治本方法:
1. 升级客户端的驱动(迟早要升级了,不然不支持新功能)
2. 上面那个currentVersion别动
参考:https://jira.mongodb.org/browse/SERVER-17459
13、MongoDB在出现负载过高的情况下如何处理?
原来遇到过一次mongodb负载过高的情况,主库和从库的负载突然就上来了,CPU占有率都到了100%,这种情况下,如何处理?mongodb是做的副本集,但是主库和从库这个时候是负载同时来的。
简单点看db.currentop,看mongotop和mongostat,currentop相当于当前所有在执行的任务,看一下是在执行什么,有多少数量。也可以去slowlog里面看是否有记录,然后mongotop和mongostat是用来查看和平时比有什么异常信息。
可能的情况有连接数突然变高,查询突然变多,有一种查询没有索引,建立大表的索引等等。