修改故障转移群集心跳时间
Tuning Failover Cluster Network Thresholds
Windows Server Failover Clustering is a high availability platform that is constantly monitoring the network connections and health of the nodes in a cluster. If a node is not reachable over the network, then recovery action is taken to recover and bring applications and services online on another node in the cluster.
Failover Clustering by default is configured to deliver the highest levels of availability, with the smallest amount of downtime. The default settings out of the box are optimized for failures where there is a complete loss of a server, what we will refer to in this blog as a ‘hard’ failure. These would be unrecoverable failure scenarios such as the failure of non-redundant hardware or power. In these situations the server is lost and the goal is for Failover Clustering to very quickly detect the loss of the server and rapidly recover on another server in the cluster. To accomplish this fast recovery from hard failures, the default settings for cluster health monitoring are fairly aggressive. However, they are fully configurable to allow flexibility for a variety of scenarios.
These default settings deliver the best behavior for most customers, however as clusters are stretched from being inches to possibly miles apart the cluster may become exposed to additional and potentially unreliable networking components between the nodes. Another factor is that the quality of commodity servers is constantly increasing, coupled with augmented resiliency through redundant components (such as dual power supplies, NIC teaming, and multi-path I/O), the number of non-redundant hardware failures may potentially be fairly rare. Because hard failures may be less frequent some customers may wish to tune the cluster for transient failures, where the cluster is more resilient to brief network failures between the nodes. By increasing the default failure thresholds you can decrease the sensitivity to brief network issues that last a short period of time.
Trade-offs
It is important to understand that there is no right answer here, and the optimized setting may vary by your specific business requirements and service level agreements.
-
- Aggressive Monitoring – Provides the fastest failure detection and recovery of hard failures, which delivers the highest levels of availability. Clustering is less forgiving of transient failures, and may in some situations prematurely failover resources when there are transient network outages.
-
- Relaxed Monitoring – Provides more forgiving failure detection which provides greater tolerance of brief transient network issues. These longer time-outs will result in cluster recovery from hard failures taking more time and increasing downtime.
Think of it like your cell phone, when the other end goes silent how long are you willing to sit there going “Hello?... Hello?... Hello?” before you hang-up the phone and call the person back. When the other end goes silent, you don’t know when or even if they will come back.
The key question you need to ask yourself is: What is more important to you? To quickly recover when you pull out the power cord or to be tolerant to a network hiccup?
Settings
There are four primary settings that affect cluster heartbeating and health detection between nodes.
-
- Delay – This defines the frequency at which cluster heartbeats are sent between nodes. The delay is the number of seconds before the next heartbeat is sent. Within the same cluster there can be different delays between nodes on the same subnet, between nodes which are on different subnets, and in Windows Server 2016 between nodes in different fault domain sites.
-
- Threshold – This defines the number of heartbeats which are missed before the cluster takes recovery action. The threshold is a number of heartbeats. Within the same cluster there can be different thresholds between nodes on the same subnet, between nodes which are on different subnets, and in Windows Server 2016 between nodes in different fault domain sites.
It is important to understand that both the delay and threshold have a cumulative effect on the total health detection. For example setting CrossSubnetDelay to send a heartbeat every 2 seconds and setting the CrossSubnetThreshold to 10 heartbeats missed before taking recovery, means that the cluster can have a total network tolerance of 20 seconds before recovery action is taken. In general, continuing to send frequent heartbeats but having greater thresholds is the preferred method. The primary scenario for increasing the Delay, is if there are ingress / egress charges for data sent between nodes. The table below lists properties to tune cluster heartbeats along with default and maximum values.
| Parameter | Win2012 R2 | Win2016 | Maximum |
| SameSubnetDelay | 1 second | 1 second | 2 seconds |
| SameSubnetThreshold | 5 heartbeats | 10 heartbeats | 120 heartbeats |
| CrossSubnetDelay | 1 second | 1 seconds | 4 seconds |
| CrossSubnetThreshold | 5 heartbeats | 20 heartbeats | 120 heartbeats |
| CrossSiteDelay | NA | 1 second | 4 seconds |
| CrossSiteThreshold | NA | 20 heartbeats | 120 heartbeats |
To be more tolerant of transient failures it is recommended on Win2008 / Win2008 R2 / Win2012 / Win2012 R2 to increase the SameSubnetThreshold and CrossSubnetThreshold values to the higher Win2016 values. Note: If the Hyper-V role is installed on a Windows Server 2012 R2 Failover Cluster, the SameSubnetThreshold default will automatically be increased to 10 and the CrossSubnetThreshold default will automatically be increased to 20. After installing the following hotfix the default heartbeat values will be increased on Windows Server 2012 R2 to the Windows Server 2016 values.
https://support.microsoft.com/en-us/kb/3153887
Disclaimer: When increasing the cluster thresholds, it is recommended to increase in moderation. It is important to understand that increasing resiliency to network hiccups comes at the cost of increased downtime when a hard failure occurs. In most customers’ minds, the definition of a server being down on the network is when it is no longer accessible to clients. Traditionally for TCP based applications this means the resiliency of the TCP reconnect window. While the cluster thresholds can be configured for durations of minutes, to achieve reasonable recovery times for clients it is generally not recommended to exceed the TCP reconnect timeouts. Generally, this means not going above ~20 seconds.
It critical to recognize that cranking up the thresholds to high values does not fix nor resolve the transient network issue, it simply masks the problem by making health monitoring less sensitive. The #1 mistake made broadly by customers is the perception of not triggering cluster health detection means the issue is resolved (which is not true!). I like to think of it, that just because you choose not to go to the doctor it does not mean you are healthy. In other words, the lack of someone telling you that you have a problem does not mean the problem went away.
Configuration:
Cluster heartbeat configuration settings are considered advanced settings which are only exposed via PowerShell. These setting can be set while the cluster is up and running with no downtime and will take effect immediately with no need to reboot or restart the cluster.
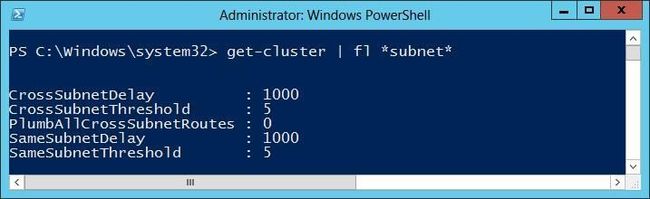
To view the current heartbeat configuration values:
PS C:\> get-cluster | fl *subnet*
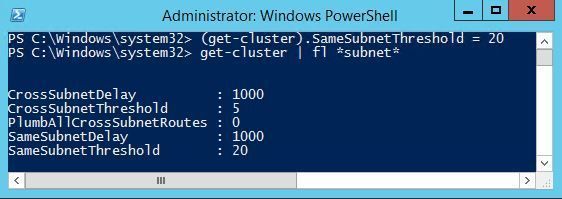
The setting can be modified with the following syntax:
PS C:\> (get-cluster).SameSubnetThreshold = 20
Additional Considerations for Logging:
In Windows Server 2012 there is additional logging to the Cluster.log for heartbeat traffic when heartbeats are dropped. By default the RouteHistoryLength setting is set 10, which is two times the number of default thresholds. If you increase the SameSubnetThreshold or CrossSubnetThrehold values, it is recommended to increase the RouteHistoryLength value to be twice the value to ensure that if the time arises that you need to troubleshoot heartbeat packets being dropped that there is sufficient logging. This can be done with the following syntax:
PS C:\> (get-cluster).RouteHistoryLength = 20
For more information on troubleshooting issues with nodes being removed from cluster membership due to network communication issues, please see the following blog:
http://blogs.technet.com/b/askcore/archive/2012/02/08/having-a-problem-with-nodes-being-removed-fro...
Additional Resources:
To learn more see this Failover Cluster Networking Essentials session I did at TechEd: