BiLSTM+CRF(二)命名实体识别
前言
前一篇博客【https://blog.csdn.net/jmh1996/article/details/83476061 BiLSTM+CRF (一)双向RNN 浅谈 】里面,我们已经提到了如何构建一个双向的LSTM网络,并在原来单层的RNN的基础上,修改少数几行代码即可实现。
Bi-LSTM其实就是两个LSTM,只不过反向的LSTM是把输入的数据先reverse 首尾转置一下,然后跑一个正常的LSTM,然后再把输出结果reverse一次使得与正向的LSTM的输入对应起来。
这篇博客,我们就来看看如何通过BiLSTM+CRF来进行命名实体识别的任务。
先介绍一下命名实体识别任务。
命名实体识别
通俗来说,命名实体识别,就是给一句话或一段话,设计某种算法来把其中的命名实体给找出来。啥叫命名实体呢?说白了不值一提,命名实体,其实就是实际存在的具有专门名字的物体。命名实体识别,其实就是实体名字的识别。
例如:
我 们 的 藏 品 中 有 几 十 册 为 北 京 图 书 馆 等 国 家 级 藏 馆 所 未 藏 。
其中北京图书馆就是一个专有的实体名称。
一般命名实体有分:人名、地名、组织名、机构名等等之分,根据不同的任务有不同的划分。
命名实体识别的解法
目前命名实体识别领域比较流行的方法都是把命名实体识别问题转换为一个序列标注的问题,然后通过序列标注的方法来解决。
一般序列标注的解决方法有:隐马尔科夫模型HMM或 条件随机场 CRF 或BiLSTM+CRF 或BiLSTM+最大熵。其中前两种是统计学习方法,后面两种是神经网络的方法。
本文只介绍神经网络的方法。
当把命名实体识别转换为一个序列标注的问题后,问题就简化成了一个结构化分类的问题了。
什么意思呢?例如,对于人名识别的任务来说,我们把每个字分类为三类:O,B-PER,I-PER。O表示这个字不是人名,B-PER表示这个字是一个人名的开头,I-PER表示这个字是一个人名的中间,前面一定存在一个最近的B-PER使得从B-PER到I-PER形成的连续子串构成一个人名。
例如:
尤 以 收 录 王小二 小 子、 马六等人的 《 南 开 中 学 同 学 录 》
标注语料:
O O O O B-PER I-PER I-PER O O O B-PER I-PER O O O O
其中“王小二”是一个人名,于是这三个词被标注为B-PER I-PER I-PER。
同理“马六”也是一个人名。
做了这个处理以后,这个任务就简单的多了。
很明显,这是一个有监督的分类问题,训练语料一定要给出训练文本对应的标注。基于训练集,自然也就能学习到一个分类模型。
Bi-LSTM+最大熵 解法
Bi-LSTM+最大熵 解法是特别简单粗暴的一种解法,它的核心思想是通过一个Bi-LSTM计算得到某个词标注为各类标签的势能(其实就可以理解为概率)分布,然后取这些标签里面,势能最大的那个标签作为分类结果输出。
这种方法很简单,实现也方便。但是这种方法把各个词的标注结果独立开来,过度“相信”神经网络会自己学到词的标注结果之间的某种关系。
例如:
如果存在一个这样一个标注序列:B-PER,I-LOC,I-LOC,I-LOC
自然是不合理的。
经典模型:
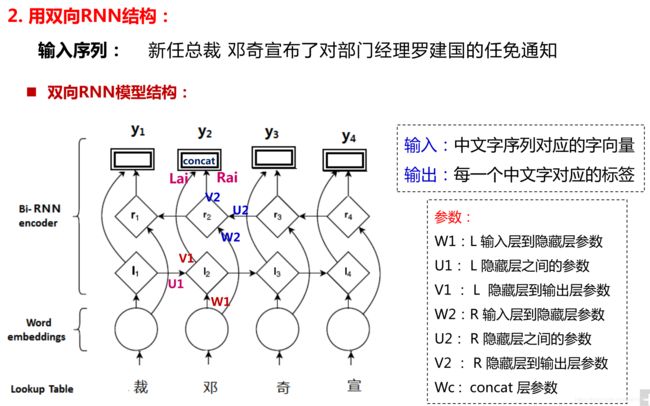
Bi-LSMT+CRF 解法
Bi-LSTM +CRF是在原来的Bi-LSTM+最大熵的基础上优化过来的,它最大的思想就是在Bi-LSTM的上面挂了一层条件随机场模型作为模型的解码层,在条件随机场模型里面考虑预测结果之间的合理性。
经典模型:

Bi-LSTM+CRF 模型的实现
模型:CRF的转移矩阵A由神经网络的CRF层近似得到,而P矩阵 也就是发射矩阵由Bi-LSTM近似得到。
词向量,即可以预先训练,也可以一并训练。
实现详解
数据处理逻辑
__author__ = 'jmh081701'
import json
import numpy as np
import random
class DATAPROCESS:
def __init__(self,train_data_path,train_label_path,test_data_path,test_label_path,word_embedings_path,vocb_path,seperate_rate=0.1,batch_size=100,
state={'O':0,'B-LOC':1,'I-LOC':2,'B-PER':3,'I-PER':4,'B-ORG':5,'I-ORG':6}):
self.train_data_path =train_data_path
self.train_label_path =train_label_path
self.test_data_path = test_data_path
self.test_label_path = test_label_path
self.word_embedding_path = word_embedings_path
self.vocb_path = vocb_path
self.state = state
self.seperate_rate =seperate_rate
self.batch_size = batch_size
self.sentence_length = 20
#data structure to build
self.train_data_raw=[]
self.train_label_raw =[]
self.valid_data_raw=[]
self.valid_label_raw = []
self.test_data_raw =[]
self.test_label_raw =[]
self.word_embeddings=None
self.id2word=None
self.word2id=None
self.embedding_length =0
self.__load_wordebedding()
self.__load_train_data()
#self.__load_test_data()
self.last_batch=0
def __load_wordebedding(self):
self.word_embeddings=np.load(self.word_embedding_path)
self.embedding_length = np.shape(self.word_embeddings)[-1]
with open(self.vocb_path,encoding="utf8") as fp:
self.id2word = json.load(fp)
self.word2id={}
for each in self.id2word:
self.word2id.setdefault(self.id2word[each],each)
def __load_train_data(self):
with open(self.train_data_path,encoding='utf8') as fp:
train_data_rawlines=fp.readlines()
with open(self.train_label_path,encoding='utf8') as fp:
train_label_rawlines=fp.readlines()
total_lines = len(train_data_rawlines)
assert len(train_data_rawlines)==len(train_label_rawlines)
for index in range(total_lines):
data_line = train_data_rawlines[index].split(" ")[:-1]
label_line = train_label_rawlines[index].split(" ")[:-1]
#assert len(data_line)==len(label_line)
#align
if len(data_line) < len(label_line):
label_line=label_line[:len(data_line)]
elif len(data_line)>len(label_line):
data_line=data_line[:len(label_line)]
assert len(data_line)==len(label_line)
#add and seperate valid ,train set.
data=[int(self.word2id.get(each,0)) for each in data_line]
label=[int(self.state.get(each,self.state['O'])) for each in label_line]
if random.uniform(0,1) <self.seperate_rate:
# 按照一定的比例划分
self.valid_data_raw.append(data)
self.valid_label_raw.append(label)
else:
self.train_data_raw.append(data)
self.train_label_raw.append(label)
self.train_batches= [i for i in range(int(len(self.train_data_raw)/self.batch_size) -1)]
self.train_batch_index =0
self.valid_batches=[i for i in range(int(len(self.valid_data_raw)/self.batch_size) -1) ]
self.valid_batch_index = 0
def __load_test_data(self):
pass
def pad_sequence(self,sequence,object_length,pad_value=None):
'''
:param sequence: 待填充的序列
:param object_length: 填充的目标长度
:return:
'''
if pad_value is None:
sequence = sequence*(1+int((0.5+object_length)/(len(sequence))))
sequence = sequence[:object_length]
else:
sequence = sequence+[pad_value]*(object_length- len(sequence))
return sequence
def next_train_batch(self):
#padding
output_x=[]
output_label=[]
index =self.train_batches[self.train_batch_index]
self.train_batch_index =(self.train_batch_index +1 ) % len(self.train_batches)
datas = self.train_data_raw[index*self.batch_size:(index+1)*self.batch_size]
labels = self.train_label_raw[index*self.batch_size:(index+1)*self.batch_size]
for index in range(self.batch_size):
#复制填充
data= self.pad_sequence(datas[index],self.sentence_length)
label = self.pad_sequence(labels[index],self.sentence_length)
output_x.append(data)
output_label.append(label)
return output_x,output_label
#返回的都是下标
def next_test_batch(self):
pass
def next_valid_batch(self):
output_x=[]
output_label=[]
index =self.valid_batches[self.valid_batch_index]
self.valid_batch_index =(self.valid_batch_index +1 ) % len(self.valid_batches)
datas = self.valid_data_raw[index*self.batch_size:(index+1)*self.batch_size]
labels = self.valid_label_raw[index*self.batch_size:(index+1)*self.batch_size]
for index in range(self.batch_size):
#复制填充
data= self.pad_sequence(datas[index],self.sentence_length)
label = self.pad_sequence(labels[index],self.sentence_length)
output_x.append(data)
output_label.append(label)
return output_x,output_label
if __name__ == '__main__':
pass
数据处理模块主要是为了实现两个函数:next_train_batch和next_valid_batch,用于从训练集和预测集获取一个batch的数据,注意这里的batch不是随机的,而是序惯的。
注意这里面的pad 填充函数,它会把序列填充到给定的sentence_length的长度,填充方法是倍增填充。
神经网络模型
__author__ = 'jmh081701'
import tensorflow as tf
from tensorflow.contrib import crf
import random
from utils import *
#超参数
batch_size=300
dataGen = DATAPROCESS(train_data_path="data/source_data.txt",
train_label_path="data/source_label.txt",
test_data_path="data/test_data.txt",
test_label_path="data/test_label.txt",
word_embedings_path="data/source_data.txt.ebd.npy",
vocb_path="data/source_data.txt.vab",
batch_size=batch_size
)
#模型超参数
tag_nums =len(dataGen.state) #标签数目
hidden_nums = 30 #bi-lstm的隐藏层单元数目
learning_rate = 0.0005 #学习速率
sentence_len = dataGen.sentence_length #句子长度,输入到网络的序列长度
frame_size = dataGen.embedding_length #句子里面每个词的词向量长度
#网络的变量
word_embeddings = tf.Variable(initial_value=dataGen.word_embeddings,trainable=True) #参与训练
#输入占位符
input_x = tf.placeholder(dtype=tf.int32,shape=[None,None],name='input_word_id')#输入词的id
input_y = tf.placeholder(dtype=tf.int32,shape=[None,sentence_len],name='input_labels')
sequence_lengths=tf.placeholder(dtype=tf.int32,shape=[None],name='sequence_lengths_vector')
#
with tf.name_scope('projection'):
#投影层,先将输入的词投影成相应的词向量
word_id = input_x
word_vectors = tf.nn.embedding_lookup(word_embeddings,ids=word_id,name='word_vectors')
word_vectors = tf.nn.dropout(word_vectors,0.8)
with tf.name_scope('bi-lstm'):
labels = tf.reshape(input_y,shape=[-1,sentence_len],name='labels')
fw_lstm_cell =tf.nn.rnn_cell.LSTMCell(hidden_nums)
bw_lstm_cell = tf.nn.rnn_cell.LSTMCell(hidden_nums)
#双向传播
output,_state = tf.nn.bidirectional_dynamic_rnn(fw_lstm_cell,bw_lstm_cell,inputs=word_vectors,sequence_length=sequence_lengths,dtype=tf.float32)
fw_output = output[0]#[batch_size,sentence_len,hidden_nums]
bw_output =output[1]#[batch_size,sentence_len,hidden_nums]
contact = tf.concat([fw_output,bw_output],-1,name='bi_lstm_concat')#[batch_size,sentence_len,2*hidden_nums]
contact = tf.nn.dropout(contact,0.9)
s=tf.shape(contact)
contact_reshape=tf.reshape(contact,shape=[-1,2*hidden_nums],name='contact')
W=tf.get_variable('W',dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer(),shape=[2*hidden_nums,tag_nums],trainable=True)
b=tf.get_variable('b',initializer=tf.zeros(shape=[tag_nums]))
p=tf.matmul(contact_reshape,W)+b
logit= tf.reshape(p,shape=[-1,s[1],tag_nums],name='omit_matrix')
with tf.name_scope("crf") :
log_likelihood,transition_matrix=crf.crf_log_likelihood(logit,labels,sequence_lengths=sequence_lengths)
cost = -tf.reduce_mean(log_likelihood)
with tf.name_scope("train-op"):
global_step = tf.Variable(0,name='global_step',trainable=False)
optim = tf.train.AdamOptimizer(learning_rate)
train_op=optim.minimize(cost)
#grads_and_vars = optim.compute_gradients(cost)
#grads_and_vars = [[tf.clip_by_value(g,-5,5),v] for g,v in grads_and_vars]
#train_op = optim.apply_gradients(grads_and_vars,global_step)
#
display_step = len(dataGen.train_batches)*10
max_batch = 10000
step=1
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while step<max_batch:
batch_x,batch_y = dataGen.next_train_batch()
_,loss,score=sess.run([train_op,cost,logit],{input_x:batch_x,input_y:batch_y,sequence_lengths:[sentence_len]*batch_size})
print({'loss':loss,'step':step})
if(step % display_step ==0):
valid_x,valid_y=dataGen.next_valid_batch()
scores,transition_matrix_out=sess.run([logit,transition_matrix],{input_x:valid_x,input_y:valid_y,sequence_lengths:[sentence_len]*batch_size})
for i in range(batch_size):
label,_=crf.viterbi_decode(scores[i],transition_params=transition_matrix_out)
print(label)
step+=1
本人没有写 准确率函数。
命名实体识别的准确率是判断标准答案里面的命名实体集 S s u p e r v i s e S_{supervise} Ssupervise,与预测的实体集 S p r e d i c t S_{predict} Spredict之间交集占各自的比例。
一个巨大的坑
这个模型不难,但是却让我调试了1个月,原来的模型实现中模型始终预测出"O",调试中看了各个词的发射概率scores ,发现"O"标签的概率最大,让人如何也想不出问题所在。
后来,在一个偶然的机会中,本人意识到一个问题:那就是dynamic_rnn函数的有一个参数sequence_length 是需要正确设置的。
tf.nn.bidirectional_dynamic_rnn(fw_lstm_cell,bw_lstm_cell,inputs=word_vectors,sequence_length=sequence_lengths,dtype=tf.float32)
之前对sequence_length理解不深,后面翻阅文档知道这个参数的含义是:
sequence_length: (optional) An int32/int64 vector, size `[batch_size]`,
containing the actual lengths for each of the sequences in the batch.
If not provided, all batch entries are assumed to be full sequences; and
time reversal is applied from time `0` to `max_time` for each sequence.
也就是说,这个sequence_length反映的是序列真实的有效的长度,如果不指定就按照完整序列来迭代rnn。大家想之前为了矩阵表示的方便,最起码在每个batch里面我们需要让各个序列的长度相同,不够长度的我们采用一些填充的办法。
我一开始的实现是让每个句子的长度都填充或者截断为100,于是rnn需要对每一个长度为100的序列进行迭代,大家都知道LSTM/GRU 在序列长度大于30的时候效果会急剧下降,因此我一开始把所有序列长度设置为100后,又不在dynamic_rnn函数中指定实际的序列长度,那么模型始终输出“O” 也就是可以解释了。后面我把句子的长度都截断为25后,效果里面就好了很多,模型也能够收敛了。
对于长度都为100的序列,LSTM的确无能为力啊!
当然这样截断的方式也不好,最好的方式是在dynamic_rnn函数中指定各个序列的实际有效长度。
本例,最大的启发是,dynamic_rnn中sequence_length参数的作用,以及序列填充后需要考虑序列长度是否是lstm可有效接受的。
需要养成一个习惯:认真对待sequence_length参数,尤其是当填充后的序列特别特别长的时候。