Mysql数据库读书笔记
(三)数据库
1.数据库的分类及常用的数据库:
数据库分为:关系型数据库和非关系型数据库
常用的关系型数据库有:MySQL、oracle、sqlserver等;
常用的非关系型数据库有:redis、memcache、mogodb、hadoop等。
2.简单介绍一下关系型数据库的三大范式:
什么是范式? (简单理解,就是关系型数据库在设计表的时候需要遵循的规范)
要想满足第二范式,必须先满足第一范式;要满足第三范式,必须先满足第二范式;
第一范式(1NF):[列数据的不可分割] 指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的每一个属性都不能有多个值、或者不能有重复的属性;
第二范式(2NF):[主键唯一] 要求数据库表中的每一行必须被唯一区分,为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识; 除主键以外的其他字段,都必须完全依赖与主键;
第三范式(3NF):[外键] 要求一个数据库表中不包含已经在其表中已包含的非主键信息,即要求除主键之外的其他字段不能存在依赖关系;
反三范式:有的时候,为了效率,可以设置重复或者可以推导出的字段;例如:一张表中已经有"订单项(单价)",但是,当订单项太多的时候,为了效率,会在表中添加"订单(总价)"【即使由单价和数量可以推导出总价】。
3.MySQL的SQL语句:
SQL:(Structure Query Language)结构化查询语言
DDL:数据库定义语言(定义数据库、数据表的结构)【create:创建; drop :删除;alter:修改】
DML:数据操纵语言(主要用来操作语言)【insert:插入; update:修改; delete:删除】
DCL:数据控制语言(定义访问权限、取消访问权限:条件管理、安全设置)【grant:分配权限】
DQL:数据查询语言【select:查询;from子句;where子句】
登录数据库服务器:mysql -u账户 -p密码
1)数据库的增删改查(CRUD)的操作:
-
创建数据库:
- (1)【create database+数据库名字】;
- (2)【create database +数据库名字+character set UTF-8】:创建数据库的时候,可以指定字符集;
- (3)【create database+数据库名字+character set UTF-8+collate+校对规则】:设置默认的校对规则,不区分大小;
-
查看数据库:
- 【show databases】:查看所有数据库;
- 【show create database+数据库名称】:查看数据库定义的语句;
-
修改数据库:(一个数据库创建出来,基本上就不会去动它了)
- 【alter database+数据库名称+character set+字符集名称】:修改数据库名称指定字符集;
-
删除数据库:
- 【drop database+数据库名称】;
2)数据表的增删改查操作:
-
创建表:
create table+表名(
列名1 列的类型(长度) 约束,
列名2 列的类型(长度) 约束);列的约束:
(1)primary key(主键约束):默认不能为空,内容必须唯一;一张表只能有一个主键;外键都是指向另一张表的主键;
(2)unique(唯一约束):列里面的内容必须唯一,不能出现重复,可以为空;一张表可以有多个唯一约束;唯一约束不可以作为其他表的外键;
(3)not null(非空约束);
(4)auto_increment(自动增长);列的类型:
int(整型类型);
char(固定长度的字符类型);
varchar(可变长度的字符类型);
double / float / boolean
blob(存放的是二进制);
text(主要用来存放文本)
data:YYYY-MM-DD;
time: hh:mm:ss;
datatime: YYYY-MM-DD hh:mm:ss(默认值为null);
timestamp: YYYY-MM-DD hh:mm:ss(默认使用当前时间); -
查看表:
- 查看所有表:【show tables】;
- 查看表的创建过程:【show create table+表名】;
- 查看表结构:【desc +表名】;
-
修改表:
- 添加列(add):【alter table+表名+add+列名+列的类型+列的约束】;
- 修改列(modify):【alter table+表名+modify+列名+列的类型+列的约束】;
- 修改列名(change):【alter table+表名+change+旧表名+新表名+列的类型】;
- 删除列(drop):【alter table+表名+drop+列名】;
- 修改表的字符集:【alter table+表名+character set+字符集名称】;
- 修改表名:【rename table+旧表名+to+新表名】;
-
删除表:
- 【drop table+表名】;
3)对表中数据的增删改查操作:
-
为表中增加数据:
方法1:
insert into +表名(列名1,列名2)+values+(值1,值2);(注:插入部分列,列名不能省略);方法2:
insert into +表名+values+(值1,值2,值3);方法3(批量插入):
insert into +表名+values+(值11,值12,值13)+(值21,值22,值23)+(值31,值32,值33);注:命令行中插入中文,会出现乱码问题:
(1)临时的解决方案是:set names GBK;
(2)永久的解决方案是:修改 my.ini 配置(在MySQL软件的安装路径里),具体步骤:step1:在任务管理器中,暂停MySQL的服务; step2:在MySQL安装路径中找到 my.ini 配置文件; step3:将文件中第57行的编码改为GBK,保存文件,退出; step4:启动MySQL服务。 -
为表中删除数据:
delete from +表名+ where 条件
(如果没有指定条件,会将表中的数据全部删除)
请说一下,delete删除数据和truncate删除数据有什么区别:
(1)delete:属于DML,一条一条的删除表中的数据;
(2)truncate:属于DDL,先删除表,再重建表;
如果数据比较少,delete比较高效;如果数据比较多,truncate比较高效;
- 为表中修改数据:
update +表名+set+ 列名1=列的值1,列名2=列的值2 where 条件;
例如:update student set sname="李四" where sid=3;
//表示将sid为5的名字改为李四;
如果没有写where条件,那么整个表的每一行都会被修改;
- 为表中查询数据:
新建商品分类表(包含属性:分类ID、分类名称、分类描述),如下:
create table category(
cid int primary key auto_increament,
cname varchar(10),
cdesc varchar(30)
);
为分类表中插入数据,如下:
insert into category values(null,‘手机数码’,‘电子产品’);
insert into category values(null,‘鞋靴箱包’,‘江南皮革厂制造’);
insert into category values(null,‘香烟酒水’,‘二锅头’);
insert into category values(null,‘酸奶饼干’,‘安慕希’);
新建商品表(包含属性:商品ID、商品名称、商品价格、商品生产日期),如下:
create table product(
pid int primary key auto_increament,
pname varchar(10),
price double,
pdate timestamp,
cno int
);
为商品表中插入数据,如下:
insert into product values(null,'小米mix4',1000,null,1),(null,'阿迪王',988,null,2),(null,'老村长',89,null,3),(null,'劲酒',100,null,3),(null,'小熊饼干',2.5,null,4),(null,'卫龙辣条',3.5,null,4);
1)简单查询(select…from):
select * from product;//查询所有商品
select pname,price from product;//查询商品名称和商品价格
2)别名查询(as):
select p.pname,p.price from product as p;//表别名
select pname as 商品名称, price as 商品价格 from product;//列别名
3)去掉重复的值(distinct):
select price from product;//查询商品表中所有的商品价格
select distinct price from product;//查询所有的未重复的商品价格
4)运算查询(在查询结果上做了加减乘除运算):
select *,price*1.5 as 折后价 from product;
//显示商品表,并多出来一列:折后价
5)条件查询(where):
select * from product where price>60;//查询商品价格大于60的所有商品信息
where后的条件写法:
(1)关系运算符: >, >=, <, <=, =, !=( 相当于<> )
select * from product where price <> 88;//查询商品价格不等于88的所有商品
(2)逻辑运算:and,or,not
select * from product where price>10 and price<100;
或者
select * from product where price between 10 and 100;
(3)模糊查询(like):
_:代表一个字符; %:代表多个字符;
例如:
select * from product where pname like '%饼%';//查询出名字中带有'饼'的所有商品
select * from product where pname like '_熊%';//查询第二个字为'熊'的所有商品
(4)在某个范围中获得值(in):
例如:
select * from product where cno in (1,3,4);
//查询出商品分类ID在1,3,4里面的商品
6)排序查询(order by):
注:asc:(ascend)升序;desc:(descend) 降序;
例如:
select * from product order by price;//查询所有商品,并按照商品价格排序
select * from product order by price desc;//查询所有商品,并按照商品价格降序排序
select * from product where pname like '%小%' order by price asc;//查询商品名称中带‘小’的商品,并按照价格升序排序
7)聚合函数:
sum():求和;
avg():求平均值;
count():统计数量;
max():求最大值;
min():求最小值;
注意:where条件后面不能接聚合函数
select sum(price) from product;//获取所有商品的价格总和
select avg(price) from product;//获取所有商品的平均价格
select count(*) from product;//获取所有商品的个数
8)分组(group by … having):
select cno,count(*) from product group by cno;
//根据cno字段分组,分组后统计商品的数量
select cno,avg(price) from product group by cno having avg(price)>70;
//根据cno字段分组,分组统计出平均价格大于70 的每组商品的平均价格
小结:
编写顺序:select ... from ... where ... group by ... having ... order by ;
执行顺序:from ... where ... group by ... having ... select ...order by ;
4.SQL的多表操作:
1)多表之间的关系如何维护?
添加外键约束:foreign key
例如:在商品表product中添加外键 cno ,指向商品分类表category的 cid;
方法1:
alter table product add foreign key (cno) references category (cid);
方法2:直接在新建商品表product时,增加外键,如下:
create table product(
pid int primary key auto_increament,
pname varchar(10),
price double,
pdate timestamp,
cno int,
foreign key (cno) references category (cid)
);
2)删除的时候,先删除外键关联的所有数据,再删除分类的数据;
例如:从商品分类表category中删除分类ID为4的信息,需要:
(1)首先,在商品表product中,删除 cno=4 的商品;
(2)然后,才能删除商品分类表category中 cid=4的信息;
3)多表之间的建表原则:
一对多:(如商品和分类)在多的一方(商品表)中添加一个外键指向一的一方(分类表)的主键;
多对多:(如老师和学生)多建一张中间表,把多对多的关系拆分为一对多的关系,中间表中至少要有两个外键,这两个外键指向原来的那两张表;
一对一:不常用,拆表操作
4)数据库客户端软件(SQLyog)
5)多表查询:
-
交叉连接查询:
- select * from product,category;
- select * from product,category where cno=cid;//过滤出有意义的数据
-
内连接查询:
-
隐式内连接:(交叉连接实际上就是隐式内连接)
select * from product p, category c where p.cno=c.cid; -
显式内连接(inner join … on ):
select * from product p inner join category c on p.cno=c.cid
-
隐式内连接和显式内连接的区别:
隐式内连接是,在查询出的结果的基础上 去做where条件的过程;
显式内连接是,带着条件去查询结果的过程,所以效率较高 -
-
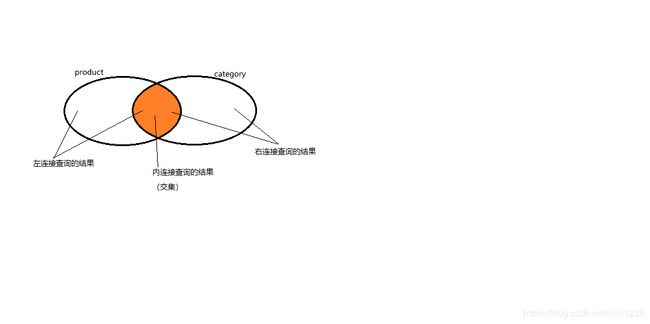
外连接查询:
- 左外连接:会将左表中的所有数据都查询出来,如果右表中没有对应的数据全是null;
select * from product p left outer join category c on p.cno=c.cid - 右外连接:会将右表中的所有数据都查询出来,如果左表中没有对应的数据全是null;
select * from product p right outer join category c on p.cno=c.cid
- 左外连接:会将左表中的所有数据都查询出来,如果右表中没有对应的数据全是null;
-
分页查询(limit):
-
假设每页数据的上限为3条,起始索引为 0:
select * from product limit 0,3;//第一个参数 0 表示起始索引;第二个参数 3 表示每页显示的个数 -
计算每一页的起始索引:
startindex = (index-1)*num其中,index表示当前显示为第几页;num表示每页的数据上限;页数从1开始,索引从0开始;
-
-
子查询(实际上就是SQL的嵌套):
例子1:查询出分类名称为’手机数码’的所有商品
step1:查询分类名称为'手机数码'的分类ID:
select cid from category where cname="手机数码";
step2:查询出响应分类ID等于1的所有商品:
select * from product where cno=1;
合并以上,有:
select * from product where cno=(select cid from category where cname='手机数码');
例子2:查询商品名称、商品分类名称的信息:
左连接:select p.pname,c.cname from product p left outer join category c on p.cno=c.cid;
子查询:select p.pname,(select c.cname from category c where c.cid=p.cno) as 商品分类名称 from product p;
5.JDBC(JAVA database connection):
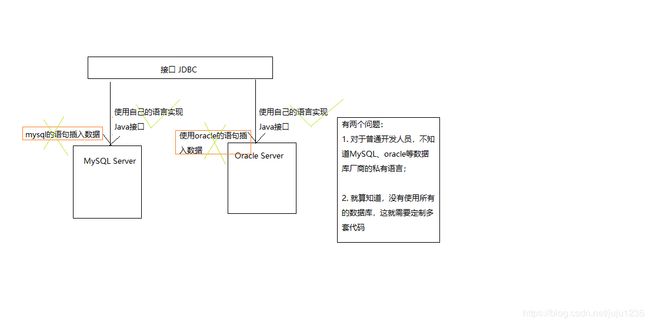
简单说一下你对JDBC的理解:
JAVA database connection,数据库连接。数据库管理系统(MySQL、oracle等)有很多,每个数据库管理系统支持的命令是不一样的。
Java只定义接口,让数据库厂商自己实现接口,对于我们开发者而言,只需要导入对应厂商开发的实现即可。然后以接口的方式进行调用(MySQL+MySQL驱动(实现)+jdbc)
我们的Java代码只要使用sun公司提供jdbc驱动即可。
写一个简单的JDBC的程序(或者写一个访问oracle数据的JDBC程序):
在Java Eclipse 中驱动JDBC,首先,需要导入jar包,具体操作如下:在项目下新建一个文件夹lib,右击Build Path/Configure build path/java build path/libraries/add external jars/选择文件"MySQL-connector-Java-5.1.46-bin.jar"
JDBC 的基本步骤:
(1)注册驱动;(com.mysql.jdbc.Driver; oracle.jdbc.driver.OracleDriver)
(2)建立连接;(DriverManager.getConnection(url,username,password))
(3)创建statement,设置参数;(PreparedStatement/Statement; ps.setXXX(index,value))
(4)执行sql语句;(executeQuery(); executeUpdate())
(5)释放连接;(是否连接要从小到大,必须放到finally)
具体如下:
1)首先,新建一个配置文件jdbc.properties,如下:
driverClass=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost/数据库名称
name=账户
password=密码
2)然后,JDBC 工具类整合:
public class JDBCUtil{
static String driverClass=null;
static String url=null;
static String name=null;
static String password=null;
static{
try{
//创建一个属性配置对象
Properties properties=new Properties();
//两种方式导入输入流
InpurStream is=new FileInputStream("jdbc.properties");
//或者 InputStream is = JDBCUtil.class.getClassLoader.getResourceAsStream("jdbc.properties");
properties.load(is);
//读取属性
driverClass=properties.getProperty("jdbc.properties");
url=properties.getProperty("url");
name=properties.getProperty("name");
password=properties.getProperty("password");
}catch(Exception e){
e.printStackTrace();
}
}
//获取连接对象
public static getConn(){
Connection conn=null;
try{
//驱动
class.forName(driverClass);
//建立连接
conn=DriverManage.getConnection(url,name,password);
}catch(Exception e){
e.printStackTrace();
}
return conn;
}
//释放资源
public static void release(Connection conn,Statement st, ResultSet rs) {
closeConn(conn);
closeSt(st);
closeRs(rs);
}
public static void release(Connection conn,Statement st) {
closeConn(conn);
closeSt(st);
}
private static void closeConn(Connection conn) {
try {
if(conn!=null) {
conn.close();
}
}catch(SQLException e) {
e.printStackTrace();
}finally {
conn=null;
}
}
private static void closeSt(Statement st) {
try {
if(st!=null) {
st.close();
}
}catch(SQLException e) {
e.printStackTrace();
}finally {
st=null;
}
}
private static void closeRs(ResultSet rs) {
try {
if(rs!=null) {
rs.close();
}
}catch(SQLException e) {
e.printStackTrace();
}finally {
rs=null;
}
}
}
3)利用JDBC Dao模式,去实现数据库的登录和查询操作:
首先,新建一个Dao接口,里面声明数据库的访问规则,如下:
//定义操作数据库的方法
public interface UserDao {
// 查询所有
void findAll();
/**登录
* @param username
* @param password
*/
void login(String username,String password);
}
然后,新建一个Dao的实现类,具体实现之前接口中定义的规则,如下:
public class UserDaoImpl implements UserDao {
@Override
public void findAll() {
Connection conn=null;
Statement st=null;
ResultSet rs =null;
try {
conn = JDBCUtil.getConn();
st = conn.createStatement();
String sql = "select * from t_user";
rs = st.executeQuery(sql);
while(rs.next()) {
String username=rs.getString("username");
int password=rs.getInt("password");
System.out.println("username="+username+
",password="+password);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
JDBCUtil.release(conn, st, rs);
}
}
public void login(String username, String password) {
Connection conn=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
conn = JDBCUtil.getConn();
//SELECT * FROM t_user WHERE username= 'zhangsan' AND PASSWORD=9876
String sql = "select * from t_user where username=?and password=?";
ps = conn.preparedStatement(sql);
ps.setString(1,username);
ps.setString(2,password);
rs = ps.executeQuery();
if(rs.next()) {
System.out.println("登录成功");
}else {
System.out.println("登录失败");
}
} catch (Exception e) {
e.printStackTrace();
}finally{
JDBCUtil.release(conn, st, rs);
}
}
}
最后,直接使用实现,如下:
public class testUserDaoImpl {
@Test
public void testFindAll() {
UserDao dao=new UserDaoImpl();
dao.findAll();
}
@Test
public void testLogin() {
UserDao dao=new UserDaoImpl();
dao.login("lisi", "9856");
}
}
JDBC中 PreparedStatemnt 相比 Statement 的好处:
大多数,我们使用PreparedStatement代替Statement,好处如下:
1)PreparedStatement是预编译的,比Statement速度快;
2)使用PreparedStatement,代码的可读性和可维护性更强;
3)安全性:PreparedStatement可以防止SQL注入攻击,而Statement却不能;例如:
String sql="select * from propuct where name="+name+"and password"+password;
如果我们把['or' 1 '=' 1]作为password传入进来,因为'1=1'肯定成立,所以任意用户都可以通过验证。
如果使用预处理编译语句,传入的任何内容就不会和原来的语句发生任何匹配的关系;
只要全使用预编译语句,就用不着对传入的数据做任何过滤;
而如果使用普通的Statement,有可能要对drop等做费尽心机的判断和过滤。
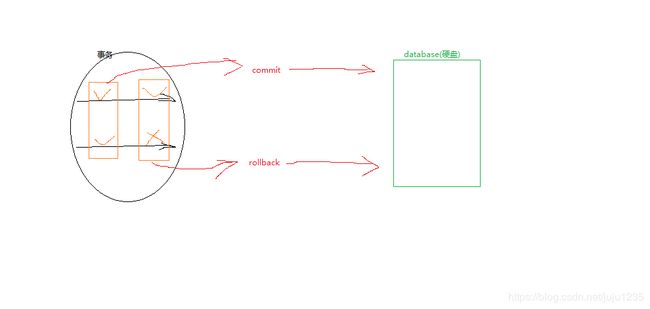
6. 事务
Transaction 其实指的是一组操作,里面包含许多个单一事务逻辑。只要有一个逻辑没有执行成功,那么都算失败,所有的数据都回归到最初的状态(回滚)。
- 为什么要有事务?
为了确保逻辑的成功。例子:银行的转账
使用命令行方式演示事务
-
开启事务
start transaction;
-
提交或者回滚
commit; 提交事务,数据将会写到磁盘上的数据库;
rollback;数据回滚,回到最初的状态;
1). 关闭自动提交功能。
cmd ---> MySQL -u root -p **********
use bank;
select * from count;
+----+---------+-------+
| id | name | money |
+----+---------+-------+
| 1 | aobama | 1000 |
| 2 | xierdun | 1000 |
+----+---------+-------+
update count set money = money -100 where id = 1;
+----+---------+-------+
| id | name | money |
+----+---------+-------+
| 1 | aobama | 900 |
| 2 | xierdun | 1000 |
+----+---------+-------+
show variables like'%commit%';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| autocommit | ON |
| innodb_commit_concurrency | 0 |
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
set autocommit = off;
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| autocommit | OFF |
| innodb_commit_concurrency | 0 |
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
2). 演示事务
update count set money = money -100 where id = 1;
select * from count;
+----+---------+-------+
| id | name | money |
+----+---------+-------+
| 1 | aobama | 800 |
| 2 | xierdun | 1000 |
+----+---------+-------+
但是,磁盘上的money没有变化;
commit;(commit之后,磁盘上的money就变化了)
start transaction;
update count set money = money -100 where id =1;
select * from acount;
+----+---------+-------+
| id | name | money |
+----+---------+-------+
| 1 | aobama | 700 |
| 2 | xierdun | 1000 |
+----+---------+-------+
但是,磁盘上的money没有变化;
rollback;(rollback之后,磁盘上的money就变化了)
select * from count;
+----+---------+-------+
| id | name | money |
+----+---------+-------+
| 1 | aobama | 800 |
| 2 | xierdun | 1000 |
+----+---------+-------+
使用代码行方式演示事务
-
新建一个Java project;然后在Java project下面新建一个folder(命名为lib);然后将connection的jar包导入lib,并右击build path --> add…;
-
将之前的jdbc工具包和jdbc.properties复制到src下面,并且在src下面新建一个test包,并在包里新建一个测试类;
-
右击项目名,点击build path --> add library --> JUnit —> JUnit4(导入org.junit.Test);可以在方法上面加@Test(并导入import org.junit.Test;)
注意: 代码里面的事务,主要是针对于连接的,
1.通过 conn.setAutoCommit(false) 来关闭自动提交的设置;
2.提交事务 conn.commit();
3.回滚事务 conn.rollback();
下面的代码中,可以发现:因为异常,第二次加钱没有成功
@Test
public void test2(){
Connection conn=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
conn = JDBCUtil.getConn();
String sql = "update count set money = money -? where id =?";
ps = conn.prepareStatement(sql);
//扣钱,扣id为1 的100 块
ps.setInt(1, 100);
ps.setInt(2, 1);
ps.executeUpdate();
int a=10/0;
//加钱,加id为2 的100 块
ps.setInt(1, -100);
ps.setInt(2, 2);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally{
JDBCUtil.release(conn, ps);
}
}
改进上面的代码,演示事务
@Test
public void testTransaction(){
Connection conn=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
conn = JDBCUtil.getConn();
//连接:事务默认的是自动提交
conn.setAutoCommit(false);
String sql = "update count set money = money -? where id =?";
ps = conn.prepareStatement(sql);
//扣钱,扣id为1 的100 块
ps.setInt(1, 100);
ps.setInt(2, 1);
ps.executeUpdate();
int a=10/0;//这里加入一个异常
//加钱,加id为2 的100 块
ps.setInt(1, -100);
ps.setInt(2, 2);
ps.executeUpdate();
//成功,则提交事务;
conn.commit();
} catch (SQLException e) {
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally{
JDBCUtil.release(conn, ps);
}
}
事务的特性(ACID)
- 原子性
指的是:事务中包含的逻辑,不可分割;
- 一致性
指的是:事务执行前后,数据完整性;
- 隔离性
指的是:事务在执行期间不应该受到其他事物的影响;
- 持久性
指的是:事务执行成功,那么事务应该持久保存到磁盘上;
不考虑事务的隔离级别设置,那么会出现下面的安全隐患:
-
读问题:
- 脏读
一个事务读到另外一个事务还未提交的数据;
- 不可重复读
一个事务读到了另外一个事务提交的数据,造成了前后两次查询结果不一致;
- 幻读
一个事务读到另外一个事务已提交的插入的数据,导致多次查询结果不一致;
-
写问题:
- 丢失更新
理解(见图)

事务的隔离级别
MySQL默认的隔离级别是 可重复读 ;Oracle默认的隔离级别是 读已提交;
- read uncommitted[读未提交]
指的是:一个事务可以读到另一个事务还未提交的数据。
这会引发"脏读":(读取到的是数据库内存中的数据,而并非真正磁盘上的数据)
- read committed[读已提交]
指的是:只能读取到其他事务已经提交的数据,那些没有提交的数据是读不出来的。
这解决了"脏读"问题,但是会引发另一个问题"不可重复读":(前后读到的结果不一样)
- repeatable read[重复读]----MySQL默认的隔离级别
该隔离级别,可以让事务在自己的会话中重复读取数据,并且不会出现结果不一样的状况,即使其他事务已经提交了,也依然还是显示以前的数据(不会因为其他事务已经提交了,而改变)
- serializable[可串行化]
如果有一个连接的隔离级别设置为可串行化,那么谁先打开了事务,谁就有了先执行的权利;谁后打开事务,谁就只能等着,等前面的那个事务提交或者回滚后,才能执行。
但是这种隔离级别一般比较少用,因为容易造成性能上的问题,效率比较低;
该事务隔离级别是最高级别的事务级别了。比前面几个都要强大一些,也就是前面的几种问题【脏读、不可重复读、幻读】都能解决,但是效率上有一些缺陷。
按效率划分,从高到低:
read uncommitted > read committed > repeatable read > serializable
按拦截程度划分,从高到低
realizable > repeatable read > read committed > read uncommitted
读未提交 演示
1). cmd打开两个MySQL连接;设置A窗口的隔离级别为 读未提交;
//查看当前连接的隔离级别
select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
//设置事务A的隔离级别为read committed
set session transaction isolation level read committed;
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
2). 两个事务(A、B)都分别开启事务;
start transaction;
读已提交 演示
- 设置A窗口的隔离级别为 读已提交;
- A B两个窗口都开启事务,在B窗口执行更新操作;
- 在A窗口执行的查询结果不一致,一次是在B窗口提交事务之前,一次是在B窗口提交事务之后;
这个隔离级别 能够屏蔽"脏读"的现象,但引发了另一个问题:“不可重复读”;
解决丢失更新
-
悲观锁(for update)
可以在查询的时候,加入 for update 加锁:
select * from count for update;
但是,实际开发中,加锁的操作是很浪费资源的,因此,出现了乐观锁。
分析(见图):

-
乐观锁
要求程序员自己控制;
应用场景:买家不是特别多,冲突的机会不多的情况下,可以使用乐观锁;(在冲突机会多的情况下,如:网上抢票,用乐观锁是不可以的)
分析(见图):

7. 数据库连接池
主要用于管理数据库连接(详情见图)

1.数据库的连接对象创建工作,比较消耗性能;
2.一开始先在内存中开辟一块空间(集合),往池子里面放置多个连接对象;后面需要连接的话,直接从池子里取,不需要再自己去创建连接了;使用完毕,要记得归还连接,确保连接对象能循环利用。
简单搭建
DataSource 是数据库连接池接口
1). 新建一个Java project(ConnectionPool),并导入connection的jar包,并且add build path;
2). 复制jdbc的工具包和jdbc.properties到src下;
3). 然后新建一个类,负责搭建一个数据库连接池, 如下:
新建一个数据库连接池的代码(MyDataSource.java):
/**
* 这是一个数据库连接池
* 1.开始先往池子里放10个连接(构造函数)
* 2.来的程序通过getConnection()方法获取连接
* 3.用完之后,使用addBack()归还连接
* 4.扩容
*/
public class MyDataSource implements DataSource {
List list=new ArrayList();
public MyDataSource() {
for (int i = 0; i < 10; i++) {
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
//该连接池对外公布的获取连接的方法
public Connection getConnection() throws SQLException {
//来拿连接的时候,先看看池子里面还有没有连接;
if(list.size()==0){
for (int i = 0; i < 5; i++) {
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
//remove(0)---->移除第一个(移除的是集合中的第一个)
Connection conn = list.remove(0);
return conn;
}
/**
* 用完连接后,记得归还
* @param conn
*/
public void addBack(Connection conn){
list.add(conn);
}
public Connection getConnection(String arg0, String arg1)throws SQLException {
return null;
}
public PrintWriter getLogWriter() throws SQLException {
// TODO Auto-generated method stub
return null;
}
public int getLoginTimeout() throws SQLException {
// TODO Auto-generated method stub
return 0;
}
public void setLogWriter(PrintWriter arg0) throws SQLException {
// TODO Auto-generated method stub
}
public void setLoginTimeout(int arg0) throws SQLException {
// TODO Auto-generated method stub
}
}
简单使用
4). 建立一个测试类:来从连接池取一个连接使用;
public class TestPool {
@Test
public void testPool(){
Connection conn =null;
PreparedStatement ps =null;
MyDataSource dataSource=new MyDataSource();
try {
conn = dataSource.getConnection();
String sql="insert into count values (null, ?, ?)";
ps = conn.prepareStatement(sql);
ps.setString(1, "lisi");
ps.setInt(2, 100);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally{
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
//归还连接
dataSource.addBack(conn);
}
}
}
自定义数据库连接池
-
代码实现(如上)
-
出现的问题:
/* 问题:
sun公司针对数据库连接池定义的一套规范(DataSource接口)
1.需要额外记住 addBack()方法;
2.单例;
3.无法面向接口编程:
UserDao dao=new UserDaoImp1();//编译看左边,运行看右边
dao.insert();
MyDataSource dataSource=new MyDataSource();
//如果把前面的 MyDataSource 换成 DataSource,
//那么后面的dataSource.addBack(conn);编译就不能通过;
//因为接口里面没有定义addBack()方法。
4.怎么解决? 以addBack()为切入点
* /
自定义数据库连接池出现的问题
1)由于多了一个addBack()方法,所以使用这个连接池的地方,需要额外记住这个方法,并且还不能面向接口编程;
2)我们打算修改接口中的close()方法。原来的Connection对象的close()方法,是真的关闭连接;
3)打算修改close()方法,以后再调用close(),并不是真的关闭,而是归还连接对象;
如何扩展某一个方法?
( 原有的方法逻辑,不是我们想要的,想修改自己的逻辑 );
方法1:直接改源码 ----> 无法实现
方法2:继承(重写方法): 必须得知道这个接口(Connection)的具体实现类是谁,但是我们不知道
方法3:使用装饰者模式
方法4:动态代理
装饰者模式(例子)
1). 新建一个Java project(WraperDemo),在src下面新建一个接口(Waiter),并新建两个实现类(第二个实现类是第一个实现类的包装类)
接口Waiter.java代码如下:
public interface Waiter {
void service();
}
实现类Waitress.java代码如下:
public class Waitress implements Waiter {
public void service() {
System.out.println("在服务-------");
}
}
包装类WaitressWrap.java代码如下:
public class WaitressWrap implements Waiter{
Waiter waiter=null;
public WaitressWrap(Waiter waiter) {
this.waiter=waiter;
}
public void service() {
System.out.println("。。。微笑。。。");
waiter.service();
}
}
2). 新建一个测试类
public class MainTest {
public static void main(String[] args) {
/*Waiter waiter=new Waitress();
waiter.service();*/
WaitressWrap waitressWrap=new WaitressWrap(new Waitress());
waitressWrap.service();
}
}
- 题外话—面向接口编程(好处)
接口:[领导]规定需要的一些方法,具体方法的实现可以由[下属]来写实现类;
接口名 dao = new 实现类名();
UserDao dao = new UserDaoImp();
dao.insert();
- 装饰者模式(解决自定义数据库连接池出现的问题)
修改上面的新建数据库连接池的MyDataSource.java代码:
public class MyDataSource implements DataSource {
List list=new ArrayList();
public MyDataSource() {
for (int i = 0; i < 10; i++) {
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
//该连接池对外公布的获取连接的方法
public Connection getConnection() throws SQLException {
//来拿连接的时候,先看看池子里面还有没有连接;
if(list.size()==0){
for (int i = 0; i < 5; i++) {
Connection conn = JDBCUtil.getConn();
list.add(conn);
}
}
//remove(0)---->移除第一个(移除的是集合中的第一个)
Connection conn = list.remove(0);
//把这个连接对象抛出去的时候,对这个对象进行包装
Connection connection = new ConnectionWrap(conn, list);
return connection;
}
/**
* 用完连接后,记得归还
* @param conn
*/
/*public void addBack(Connection conn){
list.add(conn);
}*/
Connection的包装类(ConectionWrap.java)代码修改如下:
public class ConnectionWrap implements Connection {
Connection connection=null;
List list;
public ConnectionWrap(Connection connectionon,List list) {
super();
this.connection = connectionon;
this.list = list;
}
public void close() throws SQLException {
//connection.close();
System.out.println("有人来归还连接对象了,归还前,数据库连接池中的连接数量是"+list.size());
list.add(connection);
System.out.println("有人来归还连接对象了,归还后。。。,数据库连接池中的连接数量是"+list.size());
}
public PreparedStatement prepareStatement(String sql) throws SQLException {
return connection.prepareStatement(sql);
}
测试类的代码(TestPool.java)修改如下:
public class TestPool {
@Test
public void testPool(){
Connection conn =null;
PreparedStatement ps =null;
MyDataSource dataSource=new MyDataSource();
try {
conn = dataSource.getConnection();
String sql="insert into count values (null, ?, ?)";
ps = conn.prepareStatement(sql);
ps.setString(1, "lisi");
ps.setInt(2, 100);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally{
//归还连接
//dataSource.addBack(conn);
JDBCUtil.release(conn, ps);
}
}
}
开源数据库连接池:DBCP & C3P0
用来处理:连接、管理、创建、回收
DBCP(DataBase Connection Pool)
DBCP是数据库连接池,是Java数据库连接池中的一种,由Apache开发,通过数据库连接池,也可以让程序自动管理数据库连接的释放和断开;
1). 导入jar包 commons-dbcp.jar和commons-pool.jar;
2). 代码连接(不使用配置文件方式)
DataSource是数据库连接池的开源接口;BasicDataSource实现了接口DataSource;
@Test
public void testDBCP(){
Connection conn =null;
PreparedStatement ps =null;
try {
//1.构建数据源对象
BasicDataSource dataSource=new BasicDataSource();
//2.连的是什么类型的数据库,访问的是哪个数据库,用户名,密码
//jdbc:mysql://localhost/bank 主协议:子协议://本地/数据库名
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/bank");
dataSource.setUsername("root");
dataSource.setPassword("hxzgnpy123");
//3.得到连接对象
conn = dataSource.getConnection();
String sql ="insert into count values (null, ?, ?)";
ps = conn.prepareStatement(sql);
ps.setString(1, "zhangsan");
ps.setInt(2, 500);
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
try {
ps.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
3). 代码连接(配置文件方式)
BasicDataSourceFactory类实现了ObjectFactory接口,方法有creatDataSource(Properties properties)
@Test
public void testDBCP02(){
Connection conn =null;
PreparedStatement ps =null;
try {
BasicDataSourceFactory factory=new BasicDataSourceFactory();
Properties properties=new Properties();
InputStream is=new FileInputStream("src//jdbc.properties");
properties.load(is);
BasicDataSource dataSource = factory.createDataSource(properties);
//2.得到连接对象
conn = dataSource.getConnection();
String sql ="insert into count values (null, ?, ?)";
ps = conn.preparedStatement(sql);
ps.setString(1, "zhangsan");
ps.setInt(2, 500);
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
try {
ps.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
C3P0(***)
C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。
目前使用它的开源项目有Hibernate,Spring等。
1). 导入jar包— c3p0-0.9.5.2.jar
2). 代码连接(不使用配置文件方式)
@Test
public void test01(){
Connection conn =null;
PreparedStatement ps =null;
try {
ComboPooledDataSource dataSource=new ComboPooledDataSource();
dataSource.setDriverClass("com.mysql.jdbc.Driver");
dataSource.setJdbcUrl("jdbc:mysql://localhost/bank");
dataSource.setUser("root");
dataSource.setPassword("*****");
conn = dataSource.getConnection();
String sql="insert into count values (null, ?, ?)";
ps = conn.prepareStatement(sql);
ps.setString(1, "KAIKAI");
ps.setInt(2, 300);
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
try {
ps.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 代码连接(配置文件方式)
配置文件是支持两种方式:c3p0.properities 和 c3p0-config.xml(后一种比较常用,注意,文件名一定要是c3p0-config.xml,comboPooledDataSource类的源码中由类加载器自动加载这个文件,所以不能改名)
1). 创建在src 下面创建 c3p0-config.xml:
com.mysql.jdbc.Driver
jdbc:mysql://localhost/bank
root
*****
10
30
100
10
200
2)C3P0Demo.java的代码:
public class C3P0Demo02 {
@Test
public void test02(){
Connection conn =null;
PreparedStatement ps =null;
try {
//就只是new了一个对象,默认会找xml中的
ComboPooledDataSource dataSource=new ComboPooledDataSource();
//也可以是别的,比如之后连接oracle数据库时;可以通过设置
//但是,一般一个应用只用一个数据库
//ComboPooledDataSource dataSource2=new ComboPooledDataSource("oracle");
conn = dataSource.getConnection();
String sql="insert into count values (null, ?, ?)";
ps = conn.prepareStatement(sql);
ps.setString(1, "KAIKAI");
ps.setInt(2, 300);
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
try {
ps.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
注:(修改JDBCUtil.java为C3P0的形式,如下:
之后,JDBCUtil.java 可以向之前一样使用
public class JDBCUtil {
static ComboPooledDataSource dataSource =null;
static{
dataSource =new ComboPooledDataSource();
}
/**
* 获取连接对象
*/
public static Connection getConn() throws SQLException{
return dataSource.getConnection();
}
/**
* 释放资源
*/
public static void release(Connection conn, java.sql.PreparedStatement ps,
ResultSet rs) {
closeRs(rs);
closePs(ps);
closeConn(conn);
}
public static void release(Connection conn, java.sql.PreparedStatement ps) {
closePs(ps);
closeConn(conn);
}
private static void closeConn(Connection conn) {
try {
if (conn != null) {
conn.close();
}
} catch (Exception e) {
e.printStackTrace();
}finally{
conn=null;
}
}
private static void closePs(java.sql.PreparedStatement ps) {
try {
if (ps != null) {
ps.close();
}
} catch (Exception e) {
e.printStackTrace();
}finally{
ps=null;
}
}
private static void closeRs(ResultSet rs) {
try {
if (rs != null) {
rs.close();
}
} catch (Exception e) {
e.printStackTrace();
}finally{
rs=null;
}
}
}
8. mysql 数据库的默认的最大连接数是:
为什么需要最大连接数?
特定服务器上面的数据库只能支持一定数目同时连接,这时候我们设置最大连接数(即最多同时服务多少连接),在数据库安装时都会有一个默认的最大连接数。
可以在MySQL安装的默认路径中,可以找到配置文件 my.ini,打开后,查找max,就能知道MySQL的默认最大连接数。
max_connections=100
实际工作中,一般都会设置更大的最大连接数。
9. 简单说一下MySQL的分页、oracle的分页:
为什么需要分页?(在很多数据中,不可能完全显示数据,需要进行分段显示)
1)MySQL是使用关键字limit来进行分页的:limit offset,size表示从多少索引去多少位;
String sql="select * from product order by pid limit"+pageSize*(pageNumber-1)+","+pageSize;
2)oracle的分页,思路是:要使用三层嵌套查询;具体记不住,如果在工作中使用,可以到原来的项目中拷贝、或者上网查询;
String sql="select * from"+(select *,rownum rid from (select * from students order by postime desc) where rid <="+pageSize*pageNumber+") as t"+"where t>" + pageSize*(pageNumber-1);
10. 触发器的使用场景:
触发器,需要有触发条件,当条件满足以后做什么操作;
触发器的使用场景有很多,比如:校内网、开心网、Facebook,具体地:你发一个日志,自动通知好友,其实就是在增加日志时做一个后触发,再向通知表中写入条目,因为触发器效率高。(而UCH没有触发器,效率和数据处理能力都很低)。
例如:每插入一个帖子,都希望将版面表中的最后发帖时间、帖子总数字段进行同步更新,用触发器做效率就很高。
create table board1 (
id int primary key auto_increment,
name varchar(50),
articleCount int
);
creat table article1(
id int primary key auto_increment,
title varchar(50),
bid int references board1(id)
);
delimiter| //把分隔符;改为|
create tigger insertArticle_Trigger after insert on article1 for each row
begin
update board1 set articleCount=articleCount+1 where id=NEW.bid;
end;
|
delimiter;
insert into board1 value(null,'test',0);
insert into article1 value(null,'test',1);
11. 数据库的存储过程的优点:
1)存储过程只在创建时进行编译,以后每次执行存储过程都不需要再重新编译,而一般SQL语句每执行一次就编译一次,因此,使用存储过程可以大大提高数据库执行速度;
2)通常,复杂的业务逻辑需要多条SQL语句,这些语句要分别地从客户机发送到服务器,当客户机和服务器之间的操作很多时,将产生大量的网络传输,如果将这些操作放在一个存储过程中,那么客户机和服务器之间的网络传输就会大大减少,降低了网络负载;
3)存储过程创建一次便可以重复使用,从而可以减少数据库开发人员的工作量;
4)安全性高,存储过程可以屏蔽对底层数据库对象的直接访问,使用execute权限调用存储过程,无需拥有访问底层数据库对象的显示权限。
目前常用的数据库都支持存储过程,例如:SQLServer、Oracle、Access等,开源数据库系统MySQL在5.0的时候实现了对存储过程的支持
定义存储过程:
create procedure insert_Student(
_name varchar(50),
_age int,
out_id int
);
begin
insert into student value(null,_name,_age);
select max(stuId) into _id from student;
end;
call insert_Student('wfz',23,@id);
select @id;
12.用JDBC怎么调用存储过程?
(贾琏欲执事)
加载驱动
获取连接
设置参数
执行
释放连接
Class.forName("com.mysql.jdbc.Driver");
conn=DriverManager.getConnection("jdbc:mysql:///test","root","root");
cstmt = conn.prepareCall("{call insert_Student (?,?,?)}");
catmt.registerOutParameter(3,Types.INTEGER);
catmt.setString(1,"wangwu");
catmt.setInt(2,25);
catmt.execute();
13. 数据库连接池的作用:
1)限定数据库连接的个数,不会导致由于数据库连接过多导致系统运行缓慢或崩溃;
2)数据库连接不需要每次都去创建或者销毁,节约了资源;
3)数据库连接不需要每次都去创建,响应时间更快。
14. MySQL数据库优化方面的事情:
定位:查询、定位慢查询,并优化;
优化手段:(其他数据库类似)
a. 创建索引:(创建合适的索引,我们就可以利用索引查询,查询到以后,直接找对应的记录)
b. 分表:(当一张表的数据比较多、或者一张表的某些字段的值比较多并且很少使用时,采用水平分表和垂直分表来优化)
c. 读写分离:(当一台服务器不能满足需求时,采用读写分离的方式进行集群)
d. 缓存:(使用redis来进行缓存)
e. 一些常用的优化技巧
如何查找慢查询、并定位慢查询?
在项目自验项目转测试之前,在启动MySQL数据库时开启慢查询,并且把执行慢的语句写到日志中,在运行一定时间后,通过查看日志找到慢查询语句。
要找出项目中的慢sql时:
1)关闭数据库服务器(关闭服务);
2)把慢查询记录到日志中;
3)设置慢查询时间:set global long_query_time=1;
4)找出日志中的慢查询SQL.
使用explain 慢查询语句,来详细分析语句的问题
mysql> explain select * from 数据库名称 where 列名='aaa'\G
注: 数据库优化,数据库表设计时需要遵循:
三范式(列不可分割、主键唯一,外键)、反三范式(特殊情况,允许依赖)
选择合适的数据库存储引擎:
在开发过程中,我们经常使用的存储引擎有:myisam、innodb、memory
1)myisam存储引擎:
如果表对事务的要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎;比如:bbs中的发帖表、回复表。
2)innodb存储引擎:
如果表对事务的要求高,保存的数据都是重要数据;我们建议使用innodb存储引擎;比如:订单表、账号表。
3)memory存储引擎:
如果数据变化频繁、不需要入库,同时又需要频繁的查询和修改;我们考虑使用memory存储引擎,速度极快。
mysql数据库中使用的是myisam、innodb存储引擎,它们的主要区别是:
(1)事务安全(myisam不支持事务,innodb支持);
(2)查询和添加速度(myisam不支持事务,就不需要考虑同步锁,所以查找和添加数据的速度快);
(3)支持全文索引(myisam支持全文索引,但是innodb不支持);
(4)锁机制(myisam只支持表锁,而innodb支持行锁);
(5)外键(myisam不支持外键,innodb支持外键)
选择合适的索引:
索引(index)是帮助DBMS高效获取数据的数据结构;
索引的分类:普通索引、唯一索引、主键索引、全文索引,具体如下:
普通索引:允许重复的值出现;
唯一索引:处理不允许重复值的记录外,其他和普通索引一样(例如:用户名、用户身份证等);
主键索引:唯一且没有null值;主键索引随着设定主键而创建,也就是把某个列设为主键的时候,数据库就会给该列创建索引;
全文索引:用来对表中的文本域(char、varchar、text)进行索引,全文索引针对myisam存储引擎;
explain select * from 数据库名称 where match (title,body) against(‘database’);//会使用全文索引
索引使用的小技巧:
索引的弊端:
a. 占用磁盘空间
b. 对dml(插入、修改、删除)操作有影响,变慢
索引的使用场景:
a. 肯定在where条件中经常使用,如果不做查询就没有意义
b. 该字段的内容不是唯一的几个值
c. 字段内容不会频繁变化
索引使用的具体技巧:
a. 对于创建的多列索引(复合索引),不是使用的第一部分就不会使用索引;
alter table 表名 add index 索引名 (左边的列名,右边的列名);
explain select * from 表名 where 左边的列名=‘aaa’\G;\会使用到索引
explain select * from 表名 where 右边的列名=‘aaa’\G; \就不会使用到索引
b. 对于使用like的查询,查询如果是’%aaa’,就不会使用到索引;而’aaa%‘会使用到索引;
explain select * from 表名 where 列名=’%aaa’\G;\不会使用到索引
explain select * from 表名 where 列名=‘aaa%’\G; \会使用到索引
因此,在like查询的时候,'关键字’的最前面不能使用 % 或 _ 这样的字符,如果一定要前面有变化的值,则考虑使用全文索引 sphinx。
c. 如果条件中有or,有条件没有使用索引,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须单独使用时能使用索引;
d. 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引;
e. 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。例如:表里面只有一条记录。
分表:
分表分为:水平分表(按行)、垂直分表(按列)
水平分表:就是按行分表,一般情况下,**表数据达到百万级(行很多)**时,查询效率会很低,容易造成表锁,甚至堆积很多链接,直接挂掉。这种情况下,水平分表能够很大程度上减少这些压力;
垂直分表:就是按列分表,如果一张表中的某个字段值非常长(如长文本、二进制等),并且只在很少情况下会查询;这是就可以把这个字段单独放到一个表中,可以通过外键关联起来。比如:考试详情,字段很长,并且一般我们只会关注开始成绩,此时可以采用垂直分表。
水平分表的策略:(常用按区间范围分表、hash分表)
a. 按时间分表: 这种分表方式有一定的局限性,数据具有较强的时效性,例如:微博发送记录、微信消息记录等,这种数据很少有用户会查询几个月以前的数据,这种数据就可以按月分表;b. 按区间范围分表: 一般在有严格的自增id需求上,例如:按照user_id水平分表,如下:
table_1 user_id从1~100w
table_2 user_id从101~200w
table_3 user_id从201~300wc. hash分表:通过一个原始目标的ID或者名称、通过一定的hash算法,算出数据存储表的表名,然后访问相应的表。
读写分离:
- 什么情况下数据库优化需要读写分离?
由于一台数据库支持的最大并发连接数是有限的,如果用户并发访问太多,并且一台服务器满足不了要求时,就可以集群处理。mysql的集群处理技术最常用的就是读写分离。
-
读写分离的具体操作:
(1)主从分离:数据库最终会把数据持久化到磁盘上,如果集群处理必须确保每个数据库服务器的数据都是一致的,因此,将能改变数据库数据的操作都往主数据库去写,而其他的数据库从主数据库上同步数据。
(2)读写分离:使用负载均衡来实现写的操作都往主数据库服务器去,而读的操作都往从数据库服务器去。
缓存:(最经典的优化技术)
在持久层(dao)和数据库(db)之间添加一个缓存层,如果用户访问的数据已经缓存起来时,在用户访问时直接从缓存中获取,不用再访问数据库,而缓存是在操作内存,访问速度快。
缓存的作用:减少数据库服务器压力,减少访问时间。
Java中常用的缓存有:
a. hibernate的二级缓存,该缓存不能完成分布式缓存;
b. 可以使用redis、memcahe作为中央缓存;对缓存的数据进行集中处理
sql语句优化小技巧:(DDL/DML优化比较常用)
DDL优化:
a. 通过禁用索引来提供导入数据性能,这个操作主要针对有数据库的表,追加数据;
//去除键
alter table 表名 DISABLE keys;
//批量插入数据
insert into 表名1 select * from 表名2;
//恢复键
alter table 表名 ENABLE keys;
b. 关闭唯一校验:
set unique_checks=0 //关闭
set unique_checks=1 //开启
c. 修改事务提交方式(导入):(变多次提交为一次)
set autocommit=0 //关闭
//批量插入
set autocommit=1 //开启
DML优化:(变多次提交为一次)
insert into 表名 values(1,2);
insert into 表名 values(1,3);
insert into 表名 values(1,4);
//合并多条为一条
insert into 表名 values(1,2),(1,3),(1,4);
DQL优化:
order by 优化:
a. 多用索引排序
b. 普通结果排序(非索引排序)Filesort
group by 优化:
是使用order by null,取消默认排序;
子查询优化:
//在'客户列表'找到不在'支付列表'的客户,查询没买过东西的客户
explain
select * from customer where customer_id not in (select DISTINCT customer_id from payment);//这种是基于func外链
explain
select * from customer c left join payment p on (c.customer_id=p.customer_id) where p.customer_id is null;//这种是基于'索引'外链
or 优化:
在两个独立索引上使用 or 的性能优于:
a. or 两边都是用索引字段做判断,性能好!
b. or两边,有一边不用,性能差;
c. 如果employee表的name和email这两列是一个复合索引,但是如果是:name='A' or email='B' 这种方式,不会用到索引
limit 优化:
select film_id,description from film order by title limit 50,5;
select a.film_id,a.description from file a inner join (select film_id from film order by title limit 50,5) b on a.film_id = b.film_id;
JDBC批量插入几百万条数据怎么实现?(***)
原理:变多次提交为一次,使用批量操作
conn=DriverManager.getConnection(url,user,password);
conn.setAutoCommit(false);//(1)
String sql="insert into product (id,name) values (?,?)";
ps=conn.preparedStatement(sql);
for(int i=1;i省出的时间可观。
像这样的批量插入操作能不使用代码操作就不使用,可以使用存储过程来实现。
15. Redis
简单介绍Redis:
Redis是一个key-value的nosql数据库;
(好处):先存到内存中,会根据一定的策略持久化到磁盘,即使断电也不会丢失数据,支持的数据类型比较多。
(作用):redis主要用来缓存数据库的数据;web集群时,redis可以当做中央缓存存放session;
mysql、redis、memcache的比较:
| mysql | redis | memcache | |
|---|---|---|---|
| 类型 | 关系型 | 非关系型 | 非关系型 |
| 存储位置 | 磁盘 | 磁盘和内存 | 内存 |
| 存储过期 | 不支持 | 支持 | 支持 |
| 读写性能 | 低 | 非常高 | 非常高 |
1)redis和memcache都是把数据存放在内存中,不过memcache还可以用于缓存其他东西,例如:图片、视频等;
2)redis不仅支持简单的key-value类型的数据,同时还提供list、set、hash等数据结构的存储;
3)虚拟存储—redis当物理内存用完时,可以将一些很久没用的value交换到磁盘。
Redis的使用场景:
1)作为缓存:把经常需要查询、很少修改的数据;(redis是内存级别的,因此访问时间很快)
2)作为计数器:redis中提供了一种计数器是原子性的内存操作;(最简单的例子:可以解决库存溢出问题)
3)session缓存服务器(中央缓存):web集群时,redis可以作为session缓存服务器;
具体地:当一台web服务器不能满足需求时,需要提供多台web服务器;作为集群,需要在前面增加一个负载均衡,负责将请求均衡的分配到多台web服务器上面;每台web服务器都有自己独立的session,并有一个专门管理session的区域;导致存在一个web服务器上的数据,另一个服务器不知道;因此,在服务器和数据库之间增加一个中央缓存(redis)。
redis存储对象的方式:(经常使用的是json字符串)
1)json字符串:需要把对象转换为json字符串,当做字符串处理,直接使用set、get来设置或者获取;
优点:设置和获取比较简单
缺点:没有提供专门的方法,需要把对象转换为json字符串(直接使用jsonlib,就可以实现);
2)字节流:需要做序列化,就是把对象序列化为字节保存。
如果是存储百万级的大数据对象,建议采用存储序列化对象方式;如果是少量的数据对象、或者是数据对象字段不多,还是建议采用json转换成字符串方式
redis数据淘汰机制:
由于内存大小有限,需要保存有效的数据,就需要淘汰一些暂时不用的数据;
redis提供了6种数据淘汰机制:
volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰;
volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰;
volatile-random:从已设置过期时间的数据集中任意选择数据淘汰;
allkeys-lru:从数据集中挑选最近最少使用的数据淘汰;
allkeys-random:从数据集中任意选择数据淘汰;
no-enviction:禁止驱逐数据
Java访问redis的方式:
1)使用jedis Java客户端来访问redis服务器(类似于通过jdbc访问mysql);
2)如果是spring进行集成时,可以使用spring data来访问redis;spring data只是对jedis的二次封装(类似于jdbcTemplate和jdbc的关系);
redis集群:
当一台数据库无法满足要求时,可以使用redis集群来处理,类似于mysql的读写分离。