1.
import tensorflow as tf
import numpy as np
# create data
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3
# create tensorflow structure start
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases # 模型
loss = tf.reduce_mean(tf.square(y-y_data)) # 损失函数
optimizer = tf.train.GradientDescentOptimizer(0.5) # 优化器,学习效率为0.5
train = optimizer.minimize(loss) # 最小化损失函数
init = tf.initialize_all_variables() # 初始化变量
# create tensorflow structure end
sess = tf.Session()
sess.run(init) # 激活
for step in range(201): # 训练201次
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
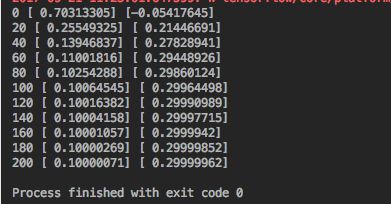
Snip20170921_4.png
Weights接近于0.1,biases接近于0.3
2.Session会话
import tensorflow as tf
matrix1 = tf.constant([[3, 3]])
matrix2 = tf.constant([[2], [2]])
product = tf.matmul(matrix1, matrix2) # 矩阵乘法
# method 1
#sess = tf.Session()
#result = sess.run(product)
#print(result)
#sess.close()
# method 2
with tf.Session() as sess:
result2 = sess.run(product)
print(result2)

Snip20170921_5.png
3.变量
# 变量
import tensorflow as tf
state = tf.Variable(0, name='counter') # 定义一个变量
# print(state.name)
one = tf.constant(1) # 常量
new_value = tf.add(state, one) # state + one
update = tf.assign(state, new_value) # 赋值
init = tf.initialize_all_variables() # 如果定义了变量,必须有这句话,初始化变量
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(update)
print(sess.run(state))
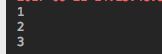
Snip20170921_6.png
4.传入值
# 传入值
import tensorflow as tf
input1 = tf.placeholder(tf.float32) #
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run(output, feed_dict={input1: [7.], input2: [2.]})) # 用字典形式传入值
Snip20170921_7.png
5.建造神经网络与结果可视化
# 建造神经网络
# 可视化
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 添加层
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
predition = add_layer(l1, 10, 1, activation_function=None)
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - predition), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# 可视化
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x_data, y_data)
plt.ion()
plt.show()
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
try:
ax.lines.remove(lines[0])
except Exception:
pass
predition_value = sess.run(predition, feed_dict={xs: x_data})
lines = ax.plot(x_data, predition_value, 'r-', lw=5)
plt.pause(0.1)

Snip20170921_8.png
6.优化器
# 优化器
# class tf.train.GradientDescentOptimizer
# class tf.train.AdagradOptimizer
# class tf.train.MomentumOptimizer
# class tf.train.AdamOptimizer
# class tf.train.FtrlOptimizer
# class tf.train.RMSPropOptimizer
7.1神经网络结构可视化
# 框架可视化
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
writer = tf.summary.FileWriter("logs/", sess.graph)
# important step
sess.run(tf.initialize_all_variables())

Snip20170922_15.png
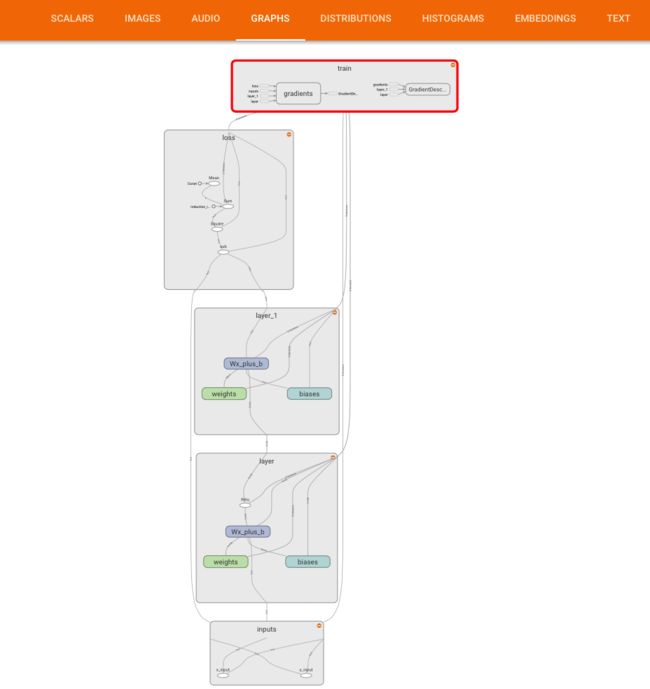
Snip20170922_14.png
7.2可视化
import tensorflow as tf
import numpy as np
def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):
# add one more layer and return the output of this layer
layer_name = 'layer%s' % n_layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
tf.summary.histogram(layer_name + '/weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(layer_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs
# Make up some real data
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs/", sess.graph)
# important step
sess.run(tf.initialize_all_variables())
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
result = sess.run(merged,
feed_dict={xs: x_data, ys: y_data})
writer.add_summary(result, i)
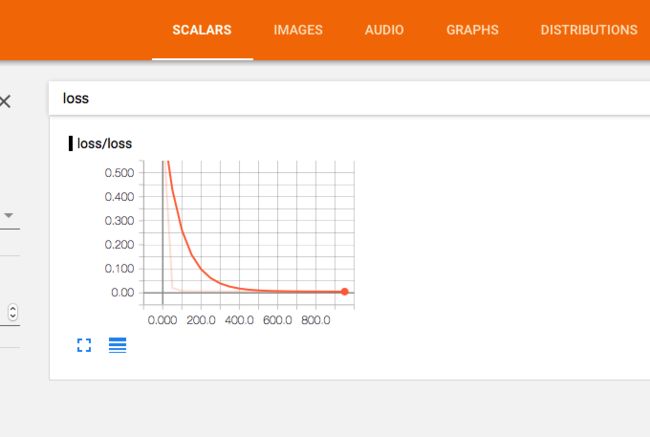
Snip20170922_16.png
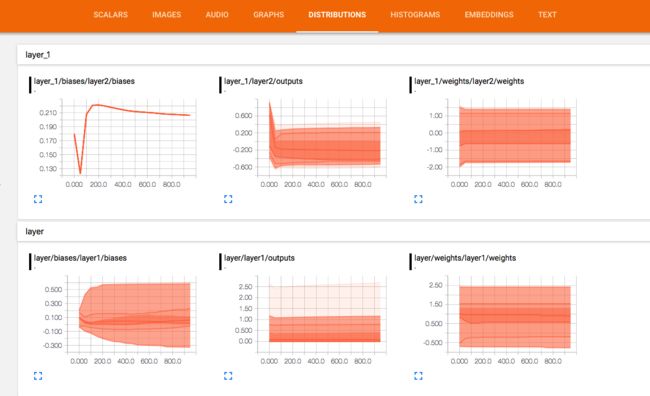
Snip20170922_17.png
8. 分类实例---手写数字识别
# 分类
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
# add output layer
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
sess.run(tf.initialize_all_variables())
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys:batch_ys})
if i % 50 == 0:
print(compute_accuracy(mnist.test.images, mnist.test.labels))
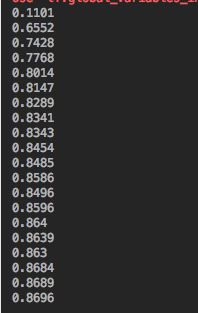
Snip20170922_12.png
8.