大数据基础(三):Java序列化与Hadoop序列化
1. Java 序列化简介
序列化是从一个对象(Object)转化为一个字节流(byte stream)的过程。而反序列化恰恰相反,是在内存中使用字节流构建一个确切的 Java 对象的过程。
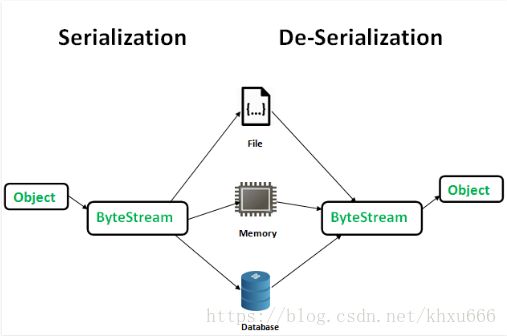
2. 序列化与反序列化
Java 序列化的过程是与平台无关的(platform-independent),也就是说一个 Java 对象可以在一个平台上序列化之后传输到另外一个平台上进行反序列化。需要进行序列化的 Java 类必须实现一个特殊的标记接口(maker interface)——Serializable。只有实现了 java.io.Serializable 接口的类可以进行序列化/反序列化,其中java.io.Serializable 接口是一个标记接口(maker interface),标记接口不含有任何成员和方法,标记接口的作用是标记一组类,这些类都具有相同的特定的功能,常见的标记接口还有 Cloneable。
对于常见的两个类:ObjectInputStream 和 ObjectOutputStream ,分别是 java.io.InputStream 和 java.io.OutputStream 这两个类的高级延伸。ObjectInputStream 类可以将更原始的类型以字节流的形式写入到 OutputStream 中。ObjectInputStream 中最重要的方法是:
public final void writeObject(Object o)
throws IOException;这个方法的作用是:接收一个可序列化的对象 o ,将 o 转换成一个连续的字节流。
同样的在 ObjectInputStream 类中最重要的方法是:
public final Object readObject()
throws IOException, ClassNotFoundException;这个方法的作用是:接收一端字节流,将字节流转化为一个 Java 对象,也就是转化回溯到最初的对象。
使用序列化带来的好处
- 保存一个对象的状态
- 可以通过网络传输对象
3. Java 序列化的几个特点
类的继承与组成
如果父类实现了 Serializable 接口,那么其子类不用显式的说明也自动的实现了此接口。但反过来不成立。并且这个类引用的对象(例如内部类、作为成员变量的类等)也必须实现 Serializable 接口。例如:
public class Person implements Serializable {
private int age;
private String name;
private Address country; // must be serializable too
People people = new People();
}由于上面的代码中的可序列化的类 Person 引用了 Address 类与 People 类,所以这两个类也必须在定义的时候实现 Serializable 接口,否则会抛出 NotSerializableException 异常。
序列化过程中的数据保存
在序列化的过程中只有非静态成员的数据会被保存,静态成员的数据和 transient 成员的数据在序列化过程中不会被保存。所以如果你不想保存费静态成员的数据,只需要将其使用 transient 修饰即可。
下面我们构造一个 Person 类来对序列化和反序列化过程有一个直观的认识。下面构造一个 Person 类,其中含有静态变量 country ,非静态变量 age 、name 以及 transient 变量 height。
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
static String country = "ITALY";
private int age;
private String name;
transient int height;
// getters and setters
}在下面的单元测试中我们对 Person 类进行初始化赋值,使用 ObjectOutputStream 保存对象的状态,使用 FileOutputStream 保存文件完成对象 person 的序列化。之后使用 FileInputStream 和 ObjectInputStream 从文件中反序列化构造对象 p2,在最后分别验证非静态数据 name 和 transient 数据 height 的值是否在经过序列化/反序列化之后仍然与原来一致。
@Test
public void whenSerializingAndDeserializing_ThenObjectIsTheSame()
throws IOException, ClassNotFoundException {
Person person = new Person();
person.setAge(20);
person.setName("Joe");
person.setHeight(10);
FileOutputStream fileOutputStream
= new FileOutputStream("yourfile.txt");
ObjectOutputStream objectOutputStream
= new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(person);
objectOutputStream.flush();
objectOutputStream.close();
FileInputStream fileInputStream
= new FileInputStream("yourfile.txt");
ObjectInputStream objectInputStream
= new ObjectInputStream(fileInputStream);
Person p2 = (Person) objectInputStream.readObject();
objectInputStream.close();
assertTrue(p2.getHeight() == person.getHeight());
assertTrue(p2.getName().equals(person.getName()));
}SerialVersionUID
在序列化的过程中,Java 虚拟机会为每一个序列化的类关联一个 long 类型的数字:SerialVersionUID。在反序列化的过程中,SerialVersionUID被用来确保发送端与接收端所序列化的对象的一致性。如果接收端与发送端的UID不一致,会抛出 InvalidClassException 异常。
如果在自定义类的时候没有显式的给出 SerialVersionUID 的值,JVM在序列化的时候回自动的为此对象分配一个默认的UID。但是最好在定义类的时候显式的给出SerialVersionUID的值。
自定义序列化方式
Java 支持自定义序列化方式。当我们想要序列化的类中含有不能序列化的成员时,通过自定义序列化的方式可以有效的解决异常抛出的问题。
想要自定义序列化方式需要重载两个方法:
private void writeObject(ObjectOutputStream out)
throws IOException;以及
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException;通过在自定义的类中重载以上两个方法,我们可以避免抛出 NotSerializableException 异常。下面给出示例代码:
// 定义不可序列化类
public class Address {
private int houseNumber;
// setters and getters
}// 重载两个方法实现自定义的序列化
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private transient Address address;
private Person person;
// setters and getters
private void writeObject(ObjectOutputStream oos)
throws IOException {
oos.defaultWriteObject();
oos.writeObject(address.getHouseNumber());
}
private void readObject(ObjectInputStream ois)
throws ClassNotFoundException, IOException {
ois.defaultReadObject();
Integer houseNumber = (Integer) ois.readObject();
Address a = new Address();
a.setHouseNumber(houseNumber);
this.setAddress(a);
}
}// 单元测试代码
@Test
public void whenCustomSerializingAndDeserializing_ThenObjectIsTheSame()
throws IOException, ClassNotFoundException {
Person p = new Person();
p.setAge(20);
p.setName("Joe");
Address a = new Address();
a.setHouseNumber(1);
Employee e = new Employee();
e.setPerson(p);
e.setAddress(a);
FileOutputStream fileOutputStream
= new FileOutputStream("yourfile2.txt");
ObjectOutputStream objectOutputStream
= new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(e);
objectOutputStream.flush();
objectOutputStream.close();
FileInputStream fileInputStream
= new FileInputStream("yourfile2.txt");
ObjectInputStream objectInputStream
= new ObjectInputStream(fileInputStream);
Employee e2 = (Employee) objectInputStream.readObject();
objectInputStream.close();
assertTrue(
e2.getPerson().getAge() == e.getPerson().getAge());
assertTrue(
e2.getAddress().getHouseNumber() == e.getAddress().getHouseNumber());
}4. Hadoop 序列化机制简介
Java 序列化过程中会不断的创建新的对象,并将每个序列化的对象的类名写入到输出流中,这种策略会占据更多的存储空间。为了解决这种问题,Hadoop 自定义了一套新的序列化机制—— writable。
Java 序列化简单来说就是在对象流 ObjectOutputStream 的基础上调用 writeObject() 方法,而 Hadoop 的序列化机制是通过直接调用对象的 write() 方法实现序列化,调用 readFields() 方法实现反序列化。在 Hadoop 中序列化过程广泛的应用在进程间通信和永久存储过程中,并且绝对的紧凑极大的减少空间占用,速度很快。
Hadoop定义了新的序列化接口——writable:
package org.apache.hadoop.io
import java.io.DataOutput
import java.io.DataInput
import java.io.IOException
public interface Writable{
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}通过实现 Writable 接口,完成序列化与反序列化。
但更多的时候,Hadoop要求同时实现序列化与可对比性,因此更常见的情况下需要实现的是 WritableComparable 接口。同时给出默认的构造函数供 MapReduce 进行实例化。下面给出一个自定义Hadoop可序列化类的示例:
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}博文引用自:
https://www.geeksforgeeks.org/serialization-in-java/
https://www.baeldung.com/java-serialization
《Hadoop权威指南(第四版)》