ZooKeeper源码学习笔记(2)--Standalone模式下的ZooKeeper
Server入口
Server的启动代码位于 zkServer.sh 文件中。

zkServer.sh脚本同 /etc/init.d/ 中的启动脚本比较类似,都是通过shell的case命令解析指令执行。具体指令如下:
1. start: 通过nohup后台启动org.apache.zookeeper.server.quorum.QuorumPeerMain
2. start-foreground: 前台运行org.apache.zookeeper.server.quorum.QuorumPeerMain
3. stop: 杀死通过start启动的进程
4. restart: 先后调用stop和start,起到重启的作用
5. status: 通过org.apache.zookeeper.client.FourLetterWordMain查看运行情况
6. upgrade: 通过org.apache.zookeeper.server.upgrade.UpgradeMain 进行线上更新
7. print-cmd: 输出启动start的命令
启动逻辑
从zkServer.sh中看到,ZooKeeper Server的入口类是QuorumPeerMain 。
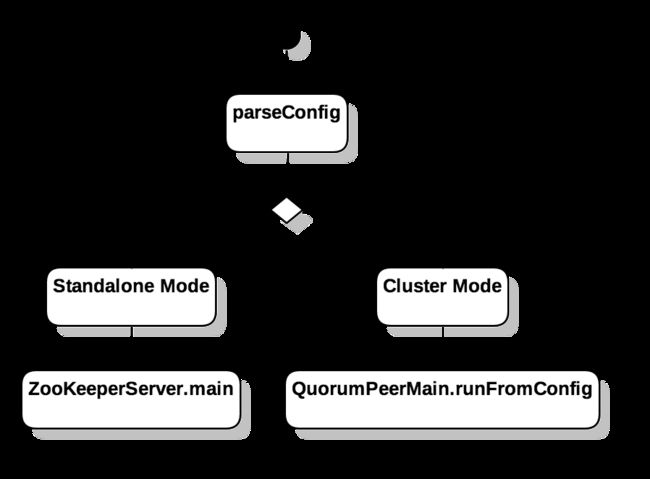
在入口函数中,根据在 zoo.cfg 文件中配置的server个数,决定启动Standalone(单机)模式或是Cluster(集群)模式
如果在 zoo.cfg 文件中没有配置 server 则默认作为 Standalone 模式启动,并将启动参数传递给 ZooKeeperServerMain::main ,否则作为 Cluster 模式进行启动。
在本节中,暂时不考虑Cluster模式,只关心 Standalone 模式下的 Server 运行逻辑。
Standalone 模式的启动流程
如上所言,在Standalone模式下,QuorumPeerMain会将启动参数传递给ZooKeeperServerMain::main。
ZooKeeperServerMain::main里,ZooKeeper在解析完成config文件后,调用runFromConfig初始化Server。
public void runFromConfig(ServerConfig config) throws IOException {
final ZooKeeperServer zkServer = new ZooKeeperServer();
// Registers shutdown handler which will be used to know the
// server error or shutdown state changes.
final CountDownLatch shutdownLatch = new CountDownLatch(1);
zkServer.registerServerShutdownHandler( new ZooKeeperServerShutdownHandler(shutdownLatch));
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
cnxnFactory.startup(zkServer);
shutdownLatch.await();
shutdown();
cnxnFactory.join();
if (zkServer.canShutdown()) {
zkServer.shutdown();
}
}
走读源码发现,cnxnFactory.startup方法中启动了三个线程,分别是NIOServerCnxnFactory(Runnable启动), PrepRequestProcessor , SyncRequestProcessor。
线程启动完毕后,进入shutdownLatch.await()的等待状态, 阻塞主线程,避免程序退出。
退出逻辑在ZooKeeperServerShutdownHandler::handle中可以看到:
if (state == State.ERROR || state == State.SHUTDOWN) {
shutdownLatch.countDown();
}当ZooKeeperServer处于异常或关闭状态,shutdownLatch.countDown();之后,shutdownLatch.await()指令完成,主线程进入关闭流程。
Server Sokect
在学习笔记(1)中,我们看到Client端在SendThread中同服务器保持一个socket长链接,与之对应的,在Server端也会有一个ServerSocket负责接收Client发送过来的请求。
String serverCnxnFactoryName = System.getProperty(ZOOKEEPER_SERVER_CNXN_FACTORY);
if (serverCnxnFactoryName == null) {
serverCnxnFactoryName = NIOServerCnxnFactory.class.getName();
}在runFromConfig中构造了一个ServerCnxnFactory对象,这个对象默认是一个NIOServerCnxnFactory,对应Client端中的ClientCnxnSocketNIO类。
@Override
public void configure(InetSocketAddress addr, int maxcc) throws IOException {
thread = new ZooKeeperThread(this, "NIOServerCxn.Factory:" + addr);
}
@Override
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
start();
setZooKeeperServer(zks);
zks.startdata();
zks.startup();
}NIOServerCnxnFactory类本身继承了Runnable接口,在 NIOServerCnxnFactory::startup 中启动一个Daemon线程响应来自Client的请求信息
响应socket请求
Client 端会中有一个SendThread 线程专门负责同 Server 的socket 链接。同样,在Server端的NIOServerCnxnFactory类中也有一个独立线程,专门负责读取Client发送来的数据。

如图,在Client端成功和Server端建立链接之后,Client端的用户请求会被 ClientCnxnSocketNIO 写入socket中,当NIOServerCnxnFactory 读取并处理完毕后,再通过socket进行写回,得到response。
对于大部分数据请求,会在doIO中逐步解析成一个Packet对象,再获取Request请求,发送给ZooKeeperServer::submitRequest进行消费,具体的消费路径会在后面进行讲解,这里只简单介绍 socket 的通信逻辑。
Watcher的实现
ServerCnxn实现了Watcher接口,如果判断request中包含了watcher,则会将ServerCnxn加入监听列表中,当指定节点发生变化时,回调ServerCnxn的对应方法,通过sendResponse通知Client节点信息发生改变
ZooKeeper的数据结构
ZooKeeper是一个基于节点模型的分布式协调框架,使用类似文件路径的节点进行数据存储。
在运行过程中,节点信息都会被全部加载到内存中,每个节点都会被构造成一个DataNode 对象,被称为znode。
三层数据缓存层
znode节点会由于用户的读写操作频繁发生变化,为了提升数据的访问效率,ZooKeeper中有一个三层的数据缓冲层用于存放节点数据。

outstandingChanges
outstandingChanges 位于ZooKeeperServer 中,用于存放刚进行更改还没有同步到ZKDatabase中的节点信息
ZKDatabase
ZKDatabase 用于管理ZooKeeper的中的节点数据。
ZKDatabase中有一个DataTree对象,在DataTree中维护一个叫做nodes的ConcurrentHashMap,用于在内存中持有完整的节点信息。
在cnxnFactory.startup的时候,系统会通过zkDb.loadDatabase()将序列化存放的节点信息还原到内存中
Disk files
Disk file 由两部分组成,一个是 FileSnap, 一个是FileTxnLog。顾名思义,FileSnap 用于存放基于某个时间点状态的 ZooKeeper 节点信息快照,FileTxnLog 用于存放数据对节点信息的具体更改操作。
ZKDatabase 的数据持久化
ZooKeeper 通过维护节点信息的一致性来完成分布式应用的协调工作。
关于 Snapshot 和 Transaction
同 Hadoop 类似,在ZooKeeper中同样存在Snapshot和Transaction的概念。

Snapshot 对应某个时间点数据的完整状态,Transaction 代表某条对数据的修正指令。
当Snapshot A 执行完指令后,他的数据状态得到更新,成为 Snapshot B。
当服务端异常退出或重启时,还原数据节点到指定状态有两种方案,一种是再次执行每一条Transaction,另一种是先将数据节点还原到一个正确的Snapshot,再执行从这个Snapshot之后的每一条Transaction。第一种方案需要保存从首次启动开始的每一条指令,同时运行时间随指令条数线性增长,影响还原效率。因此我们通常都采用第二种方案snapshot+transaction进行数据还原。
数据加载流程
如果当前并非首次启动ZooKeeper,则我们需要将关闭前的ZooKeeper数据进行还原。
根据前一小节,我们知道了Snapshot和Transaction的关系,在返回源码,我们看到在ZooKeeperServer::loadData()会调用以下代码
public long loadDataBase() throws IOException {
PlayBackListener listener=new PlayBackListener(){
public void onTxnLoaded(TxnHeader hdr,Record txn){
Request r = new Request(null, 0, hdr.getCxid(),hdr.getType(), null, null);
addCommittedProposal(r);
}
};
long zxid = snapLog.restore(dataTree,sessionsWithTimeouts,listener);
return zxid;
}
public long restore(DataTree dt, Map sessions,
PlayBackListener listener) throws IOException {
snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
TxnIterator itr = txnLog.read(dt.lastProcessedZxid+1);
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
while (true) {
hdr = itr.getHeader();
if (hdr == null) {
return dt.lastProcessedZxid;
}
processTransaction(hdr,dt,sessions, itr.getTxn());
listener.onTxnLoaded(hdr, itr.getTxn());
if (!itr.next())
break;
}
} finally {
if (itr != null) {
itr.close();
}
}
return highestZxid;
} snapLog是一个FileTxnSnapLog类,他由一个FileSnap和一个FileTxnLog组成。
FileSnap 是快照文件的工具类,拥有serialize,deserialize方法,可以将DataTree对象进行序列化和反序列化。
FileTxnLog是Transaction 日志的工具类,通过txnLog.read,我们拿到Snapshot文件发生后的Transaction 日志,通过processTransaction将事务应用到DataTree上,还原初态。
通过loadDatabase()我们成功的将磁盘文件保存的节点信息重新加载到了内存中,从这个时候开始我们可以对到来的socket进行消费。
处理 session 请求
在响应socket请求的小节中,我们看到在NIOServerCnxnFactory中启动了一个Daemon线程,并在while循环中获取socket请求信息,然后分发到doIO中执行。

ZooKeeper将每一个 socket 的链接,都认为是一个session, 并拥有一个超时时间。请求会被包装成一个NIOServerCnxn对象,当判断session是首次connect到ZooKeeperServer的时候,先读取connect信息,在SessionTrackerImpl中维护当前存活的session队列。
SessionTrackerImpl 是一个独立线程,专门用于检测 session 的存活状态。
其他非首次连接的socket信息会通过readRequest进行消费。
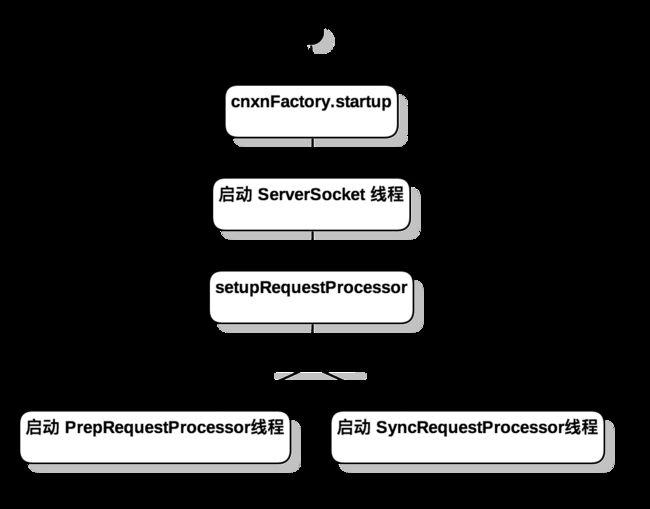
RequestProcessor 任务链
![]()
在ZooKeeperServer::setupRequestProcessors中创建了三个RequestProcessor对象,分别是 FinalRequestProcessor , SyncRequestProcessor 和 PrepRequestProcessor ,其中PrepRequestProcessor 和 SyncRequestProcessor 类分别继承自 Thread 类,作为独立线程运行。
readRequest通过反序列化Packet类,提取出Request信息,然后调用ZooKeeperServer::submitRequest进行数据处理。
public void submitRequest(Request si) {
firstProcessor.processRequest(si);
}对于Standalone 模式的ZooKeeperServer,他的firstPrcessor就是PrepRequestProcessor类
PrepRequestProcessor
PrepRequestProcessor是整个任务链的起点。
PrepRequestProcessor::submitRequest不会立即处理request请求,而是将request加入运行队列submittedRequests中,等待执行。

PrepRequestProcessor自身的独立线程不断从队列中拉去Request对象,调用pRequest(request)。在pRequest中,根据Request的不同种类,将Request转变为不同的Record对象,通过addChangeRecord将ChangeRecord加入ZooKeeperServer.outstandingChanges 中,此时节点数据并没有同步到DataTree中。
根据节点的三层缓存模型,在获取节点信息时,会首先从outstandingChangesForPath中获取信息,当没有找到对应的节点信息时,再通过zkDb::getNode获取。
SyncRequestProcessor
SyncRequestProcessor 作为 PrepRequestProcessor 的下游消费者,负责将Transaction写入TxnLog中,并定时构建快照文件。

zkDatabase.append中会将Request写入Transaction Log File,如果发现当前的Txn条数超过阈值,则启动一个快照线程,将DataTree作为快照实例到磁盘中。
在takeSnapshot中,通过序列化当前的DataTree结构,将snapShot保存到磁盘上
当SyncRequestProcessor的处理条数超过阈值1000条时,调用flush()命令,将任务逐个传递给下游的RequestProcessor进行处理。
FinalRequestProcessor
FinalRequestProcessor作为Standalone模式下的任务链终点,主要完成以下工作。
while (!zks.outstandingChanges.isEmpty() && zks.outstandingChanges.get(0).zxid <= request.zxid) {
ChangeRecord cr = zks.outstandingChanges.remove(0);
if (cr.zxid < request.zxid) {
LOG.warn("Zxid outstanding " + cr.zxid + " is less than current " + request.zxid);
}
if (zks.outstandingChangesForPath.get(cr.path) == cr) {
zks.outstandingChangesForPath.remove(cr.path);
}
}
if (request.hdr != null) {
TxnHeader hdr = request.hdr;
Record txn = request.txn;
rc = zks.processTxn(hdr, txn);
}- 调用
zks.processTxn(),将请求信息合并到DataTree中 - 清理掉
zks.outstandingChanges中的冗余数据,防止outstandingChanges无限增长。
任务链总结
ZooKeeper Server中通过三层的任务链实现对请求的处理过程。
第一层负责在outstandingChanges中构建一个临时的节点对象,便于后续请求能够快速获取对应节点最新状态
第二层负责将请求数据转为Transaction日志,并记录到磁盘中,便于重启后的节点数据还原。同时还会根据日志操作定时保存快照。
第三层负责批量将请求数据合并到DataTree中,同时清除第一层临时构建的节点对象。
总结
ZooKeeper Server使用DataTree在内存中持有所有节点信息, 在磁盘中通过Snapshot 和 TxnFile 保存历史节点数据。
响应请求时,Server 将请求数据分发给一个RequestProcessor任务链进行消费。
在任务链中,通过一个单线程保证数据的线程安全和一致性。
同样由于在 ZooKeeper 中是通过单线程保证数据线程安全,在大访问量级下的运行效率值得思考,之后可以看看Cluster下的ZooKeeper有没有对这一块做出优化。