使用云服务器+Docker部署Ceph存储系统
使用云服务器+Docker部署Ceph存储系统
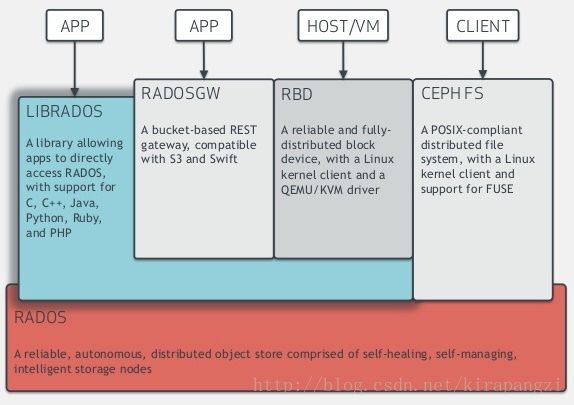
Ceph简介
一图流:底层rados storage cluster + lib + rgw + rbd + cephfs
准备工作
云服务器
到公有云服务商上购买一个云服务器,配置至少2个硬盘(system 40G+resource 20G),选择一个Linux 发行版安装,笔者日常工作用CentOS,所以直接7.2 online(kernel 已经被ali升级到了7.3);
[root@cluster ~]# uname -a; cat /etc/redhat-release
Linux cluster 3.10.0-514.6.2.el7.x86_64 #1 SMP Thu Feb 23 03:04:39 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
CentOS Linux release 7.2.1511 (Core)
安装Docker
yum list| grep docker; yum install docker; systemctl enable docker; systemctl start dockerCeph部署
Ceph镜像选择
Docker hub上有很多Ceph社区开发者维护的Ceph镜像,本文选用了ceph/demo镜像,该镜像部署简单,可以在单机实现所有Ceph组件;
[root@cluster ~]# docker pull ceph/demo; docker images ceph/demo
Using default tag: latest
Trying to pull repository docker.io/ceph/demo ...
latest: Pulling from docker.io/ceph/demo
Digest: sha256:23cbed2848c0347058fc1efb0f7692ec685c15712dc50e899a60261157d81b05
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/ceph/demo latest ed38ba053588 11 weeks ago 877.2 MB
跑起来
目录准备:mkdir /etc/ceph; mkdir /var/lib/ceph;
将MON_IP 和 CEPH_PUBLIC_NETWORK 替换,遇到问题不要急,请查看排障记录;
[root@cluster ~]# sudo docker run -d --net=host --name=ceph \
-v /etc/ceph:/etc/ceph \
-v /var/lib/ceph/:/var/lib/ceph \
-e MON_IP=172.18.18.95 \
-e CEPH_PUBLIC_NETWORK=172.18.18.0/24 \
ceph/demo
看一看
各个组件都有一个daemon常驻来实现功能,里外都看一看:ps aux |grep ceph; docker exec -it ceph ps aux
进入容器 docker exec -it ceph /bin/bash
查看Ceph cluster状态:
什么版本?运行正常吗?有pg stuck吗?创建了多少pool?:
[root@cluster ~]# ceph version; ceph -s; ceph health detail; ceph df
ceph version 11.2.0 (f223e27eeb35991352ebc1f67423d4ebc252adb7)
cluster 0449eede-d41e-4c46-a54d-2f014cc76043
health HEALTH_OK
monmap e2: 1 mons at {cluster=172.18.18.95:6789/0}
election epoch 4, quorum 0 cluster
fsmap e5: 1/1/1 up {0=0=up:active}
mgr active: cluster
osdmap e18: 1 osds: 1 up, 1 in
flags sortbitwise,require_jewel_osds,require_kraken_osds
pgmap v25: 136 pgs, 10 pools, 3829 bytes data, 223 objects
135 MB used, 20332 MB / 20468 MB avail
136 active+clean
HEALTH_OK
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
20468M 20332M 135M 0.66
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 20332M 0
cephfs_data 1 0 0 20332M 0
cephfs_metadata 2 2148 0 20332M 20
.rgw.root 3 1681 0 20332M 4
default.rgw.control 4 0 0 20332M 8
default.rgw.data.root 5 0 0 20332M 0
default.rgw.gc 6 0 0 20332M 32
default.rgw.lc 7 0 0 20332M 32
default.rgw.log 8 0 0 20332M 127
default.rgw.users.uid 9 0 0 20332M 0
一切正常,就是这么简单,rbd + rgw + cephfs 一应俱全!这比笔者之前用ceph-deploy和源码安装方便快捷了很多很多,对于需要使用ceph系统作为backend 并进行上层应用开发的开发者来说,非常有用。
reference:
ceph in docker
ceph in docker_2
一切重来
哪一步做错了?不用急,一键清除在这里:删除ceph 容器,清除ceph 数据和配置,重新格式化vdb;
docker stop ceph; docker rm ceph; rm -rf /etc/ceph/*; rm -rf /var/lib/ceph/*; umount /dev/vdb1; mkfs.xfs /dev/vdb1 -f; mount /dev/vdb1 /var/lib/ceph/排障记录
docker 跑起来后,好像有什么不对劲?
[root@cluster ~]# docker exec -it ceph ceph -s
Error response from daemon: Container dbcc2e6808d2bc5645c0f30ec40a80792fc81c529109752503ee9ddafa790b5d is not running
[root@cluster ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dbcc2e6808d2 ceph/demo "/entrypoint.sh" 54 seconds ago Exited (1) 33 seconds ago ceph原来ceph的实例已经退出了,看log;仔细看看log其实对理解ceph系统启动流程和各个组件功能很有用;
[root@cluster ~]# docker logs -f ceph
creating /etc/ceph/ceph.client.admin.keyring
creating /etc/ceph/ceph.mon.keyring
monmaptool: monmap file /etc/ceph/monmap-ceph
monmaptool: set fsid to 2c72bea5-2b0f-4aef-9b15-4a08cd56797f
monmaptool: writing epoch 0 to /etc/ceph/monmap-ceph (1 monitors)
creating /tmp/ceph.mon.keyring
importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring
importing contents of /etc/ceph/ceph.mon.keyring into /tmp/ceph.mon.keyring
ceph-mon: set fsid to 2c72bea5-2b0f-4aef-9b15-4a08cd56797f
ceph-mon: created monfs at /var/lib/ceph/mon/ceph-cluster for mon.cluster
set pool 0 size to 1
0
2017-06-25 15:12:35.835954 7fb98ce0fa40 -1 filestore(/var/lib/ceph/osd/ceph-0) WARNING: max attr value size (1024) is smaller than osd_max_object_name_len (2048). Your backend filesystem appears to not support attrs large enough to handle the configured max rados name size. You may get unexpected ENAMETOOLONG errors on rados operations or buggy behavior
2017-06-25 15:12:35.846022 7fb98ce0fa40 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2017-06-25 15:12:35.846053 7fb98ce0fa40 -1 journal FileJournal::_open_file : unable to preallocation journal to 104857600 bytes: (22) Invalid argument
2017-06-25 15:12:35.846062 7fb98ce0fa40 -1 filestore(/var/lib/ceph/osd/ceph-0) mkjournal error creating journal on /var/lib/ceph/osd/ceph-0/journal: (22) Invalid argument
2017-06-25 15:12:35.846081 7fb98ce0fa40 -1 OSD::mkfs: ObjectStore::mkfs failed with error -22
2017-06-25 15:12:35.846138 7fb98ce0fa40 -1 ** ERROR: error creating empty object store in /var/lib/ceph/osd/ceph-0: (22) Invalid argument原来是backend filesystem不对劲,来看vda 格式化的什么fs;
[root@cluster ~]# mount |grep vda
/dev/vda1 on / type ext3 (rw,relatime,data=ordered)
云服务商ali在server上线的时候,并没有让我选fs,就这么任性的用了古老的ext3;Fix it;
[root@cluster ~]# parted -s /dev/vdb mkpart primary xfs 0% 100%; mkfs.xfs -f /dev/vdb1; mount /dev/vdb1 /var/lib/ceph/