Python scrapy 爬取拉勾网招聘信息
周末折腾了好久,终于成功把拉钩网的招聘信息爬取下来了。现在总结一下!
环境: windows 8.1 + python 3.5.0
首先使用 scrapy 创建一个项目:
E:\mypy> scrapy startproject lgjobE:\mypy\lgjob
----scrapy.cfg
----lgjob
|-------__pycache__
|-------spiders
|-------__pycache__
|-------__init__.py
|-------__init__.py
|-------items.py
|-------middlewares.py
|-------pipelines.py
|-------settings.py
网络上有一中方法是读取 json 格式的,如下图:

这种方法是比较完整的,每个公司的招聘信息都很完整。拉钩网默认每页显示15个公司,最大30页。json格式比较规范,但是测试过程中一直读取不到网页记录,提示 “ 操作频繁 ” 。所以打算用传统的方法,即找出每页的规律,确认页码的位置。而内容则是直接读取 html 格式的节点取记录。
我们从拉钩首页点击某一个分类,比如我点击了 “java” ,接下来就跳转到各个公司的招聘信息列表,拉钩每页显示15个公司。看看网址为 : https://www.lagou.com/zhaopin/Java/?labelWords=label,网址中看到关键字 “java” 了吗?替换成 “DBA” 回车查询也是可以的。再点击分页,也发现分页页码显示规律了!
如下为搜索 DBA 的第二页 和第五页:
https://www.lagou.com/zhaopin/DBA/2/?filterOption=3
https://www.lagou.com/zhaopin/DBA/5/?filterOption=3
按 F12 再右键某个职位名称:

每页15个公司的招聘信息都显示出来了,这里不需要要查看职位的详细信息,所以在查找职位页面就可以把基础的信息爬取下来。职位在列表标签 “li” 显示是有规律和固定格式的,所以等下爬取也是每页去爬取,每页循环读取网页标签 “
主要的项目文件,默认都已经创建了:(E:\mypy\lgjob\lgjob\)
items.py : 爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy提供 Item 类来满足这样的需求。
pipelines.py : 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理(如保持到数据库)。
settings.py : 设定为代码提供了提取以key-value映射的配置值的的全局命名空间(namespace)。 设定可以通过下面介绍的多种机制进行设置。
还有一个主要的解析主文件,需要手动创建,放到项目的 spiders (E:\mypy\lgjob\lgjob\spiders)目录中,本次测试创建的文件名为 : main.py
现在数据库创建一个表,本次测试使用的是 sql server 数据库保存爬取数据:
CREATE TABLE [dbo].[lgjob](
[companyfullname] [varchar](50) NULL,
[positionname] [varchar](30) NULL,
[salary] [varchar](20) NULL,
[workyear] [varchar](20) NULL,
[education] [varchar](20) NULL,
[city] [varchar](20) NULL,
[district] [varchar](20) NULL,
[financestage] [varchar](50) NULL,
[industryfield] [varchar](100) NULL,
[firsttype] [varchar](50) NULL,
[positionlables] [varchar](100) NULL
) ON [PRIMARY]
GO【items.py】
# -*- coding: utf-8 -*-
# python 3.5
import scrapy
class LgjobItem(scrapy.Item):
companyfullname = scrapy.Field()
positionname = scrapy.Field()
salary = scrapy.Field()
workyear = scrapy.Field()
education = scrapy.Field()
city = scrapy.Field()
district = scrapy.Field()
financestage = scrapy.Field()
industryfield = scrapy.Field()
firsttype = scrapy.Field()
positionlables = scrapy.Field()【pipelines.py】结果保持到数据库
# -*- coding: utf-8 -*-
# python 3.5
import pymssql
from scrapy.conf import settings
class LgjobPipeline(object):
def __init__(self):
self.conn = pymssql.connect(
host = settings['MSSQL_HOST'],
user = settings['MSSQL_USER'],
password = settings['MSSQL_PASSWD'],
database = settings['MSSQL_DBNAME']
)
self.cursor = self.conn.cursor()
self.cursor.execute('truncate table lgjob;')
self.conn.commit()
def process_item(self, item, spider):
try:
self.cursor.execute(
"""INSERT INTO lgjob( companyfullname , positionname, salary, workyear, education
, city,district, financestage, industryfield, firsttype, positionlables)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""",
(
item['companyfullname'],
item['positionname'],
item['salary'],
item['workyear'],
item['education'],
item['city'],
item['district'],
item['financestage'],
item['industryfield'],
item['firsttype'],
item['positionlables']
)
)
self.conn.commit()
except pymssql.Error as e:
print(e)
return item【settings.py】配置参数(如数据库连接信息)
# -*- coding: utf-8 -*-
# Scrapy settings for lgjob project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lgjob'
SPIDER_MODULES = ['lgjob.spiders']
NEWSPIDER_MODULE = 'lgjob.spiders'
MSSQL_HOST = 'HZC'
MSSQL_USER = 'kk'
MSSQL_PASSWD = 'kk'
MSSQL_DBNAME = 'Myspider'
ITEM_PIPELINES = {
'lgjob.pipelines.LgjobPipeline': 300,
}
【main.py】 (自建的)
# -*- coding: utf-8 -*-
# python 3.5
# file path ../lgjob/lgjob/spiders/main.py
# perform: scrapy crawl lgjob
import json
import scrapy
from lgjob.items import LgjobItem
from bs4 import BeautifulSoup
class MainLgjob(scrapy.Spider):
name = 'lgjob'
domain = ['lagou.com']
start_url = ['https://www.lagou.com/zhaopin/']
curpage = 1
totalPageCount = 6
keyword = "DBA"
cururl = "https://www.lagou.com/zhaopin/%s/%s/?filterOption=3"%(keyword,curpage)
def start_requests(self):
return [scrapy.http.FormRequest(self.cururl,callback=self.parse)]
def parse(self, response):
soup = BeautifulSoup(response.body,'html.parser',from_encoding='utf-8')
body_ul = soup.find_all("li" ,class_="con_list_item default_list")
for li in body_ul:
item = LgjobItem()
arg1 = li.find("div",class_="position").find("div",class_="p_top").find("em").get_text(strip=True)
arg2 = li.find("div",class_="position").find("div",class_="li_b_l").get_text(" / ",strip=True)
arg3 = li.find("div",class_="company").find("div",class_="industry").get_text(strip=True)
arg4 = li.find("div",class_="list_item_bot").find("div",class_="li_b_r").get_text(strip=True)
item['companyfullname'] = li.find("div",class_="company").find("div",class_="company_name").find("a").get_text(strip=True)
item['positionname'] = li.find("div",class_="position").find("div",class_="p_top").find("h3").get_text(strip=True)
item['salary'] = ((arg2 + "/").split('/')[0]).strip()
item['workyear'] = ((arg2 + "/").split('/')[1]).strip()
item['education'] = ((arg2 + "/").split('/')[2]).strip()
item['city'] = (arg1+'·'+arg1).split('·')[0]
item['district'] = (arg1+'·'+arg1).split('·')[1]
item['industryfield'] = ((arg3 + "/").split('/')[0]).strip()
item['financestage'] = ((arg3 + "/").split('/')[1]).strip()
item['positionlables'] = arg4.strip('“').strip('”')
item['firsttype'] = li.find("div",class_="list_item_bot").find("div",class_="li_b_l").get_text(",",strip=True)
yield item
if self.curpage < self.totalPageCount:
self.curpage += 1
self.cururl = "https://www.lagou.com/zhaopin/%s/%s/?filterOption=3"%(self.keyword,self.curpage)
yield scrapy.http.FormRequest(self.cururl,callback=self.parse)
main.py 这个脚本有几个缺点,还没完善:
1. 总的页码需要手动定义(可以参考第一张图中的总记录计算总页码)
2. 其他筛选条件没有(只有搜索的岗位名称,城市则是在拉钩上设置的默认地方)
3. 访问到第6页时,则出现 302 重定向,爬虫终止结束了!
现在解决 1和3 的问题。
1. 总页数可以从web显示的页码那里获取(或者底部),如下图


定位到标签中,获取总页码:
page_num= soup.find("div" ,class_="page-number").find("span" ,class_="span totalNum").get_text(strip=True)
self.totalPageCount = int(page_num)
302 的问题,请求时添加 cookie,使其可以访问更多页。
登录之后找到cookie,cookie内有很多 “属性=值,属性=值…”,稍后都改为“键: 值,键: 值…” 。同样也可以看到其他 headers 信息。
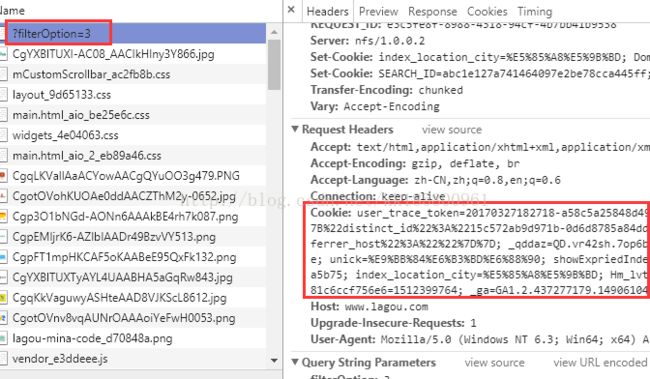
【settings.py】此时的配置文件内容改为如下(cookie都改为“key-value”格式,顺便也添加了header)
# -*- coding: utf-8 -*-
# Scrapy settings for lgjob project
BOT_NAME = 'lgjob'
SPIDER_MODULES = ['lgjob.spiders']
NEWSPIDER_MODULE = 'lgjob.spiders'
MSSQL_HOST = 'HZC'
MSSQL_USER = 'kk'
MSSQL_PASSWD = 'kk'
MSSQL_DBNAME = 'Myspider'
ITEM_PIPELINES = {
'lgjob.pipelines.LgjobPipeline': 300,
}
USER_AGENT = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36"
#以下为使用 cookie 时添加. 不使用的话在文件 MainLgjob 注释
ROBOTSTXT_OBEY = False #不遵守Robot协议
DOWNLOAD_DELAY = 3 #延迟
COOKIES_ENABLED = True #启用 cookie
HEADERS = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'
}
META = {
'dont_redirect': True,
'handle_httpstatus_list': [301, 302]
}
COOKIES = {
'user_trace_token': 'xxxxxxxxxxxxxxxxxxxxxxxxxx',
'LGUID': 'xxxxxxxxxxxxxxxxxxxxxxxxxx',
'sensorsdata2015jssdkcross': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'_qddaz': 'QD.vr42sh.xxxxxxxxxxxxx.xxxxxxxxxxxxx',
'JSESSIONID': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'_putrc': 'xxxxxxxxxxxxxxxxxxxxxxxxxx',
'login': 'true',
'unick': 'xxxxxxxxxxxxxxxxxxxxxxxxxx',
'showExpriedIndex': '1',
'showExpriedCompanyHome': '1',
'showExpriedMyPublish': '1',
'hasDeliver': '49',
'SEARCH_ID': 'xxxxxxxxxxxxxxxxxxxxxxxxxx',
'index_location_city': 'xxxxxxxxxxxxx',
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': 'xxxxxxxxxxxxx',
'Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': 'xxxxxxxxxxxxx',
'_ga': 'GA1.2.437277179',
'LGRID': 'xxxxxxxxxxxxx'
}
# -*- coding: utf-8 -*-
# python 3.5
# file path ../lgjob/lgjob/spiders/main.py
# perform: scrapy crawl lgjob
import json
import scrapy
from lgjob.items import LgjobItem
from bs4 import BeautifulSoup
from scrapy.conf import settings
class MainLgjob(scrapy.Spider):
name = 'lgjob'
domain = ['.lagou.com']
start_url = ['https://www.lagou.com/zhaopin/']
#不使用cookie,注释 Request的 ,headers=self.headers, cookies=self.cookies, meta=self.meta
meta = settings['META']
cookies = settings['COOKIES']
headers = settings['HEADERS']
curpage = 1
totalPageCount = 1
keyword = u"DBA"
cururl = "https://www.lagou.com/zhaopin/%s/%s/?filterOption=3"%(keyword,curpage)
def start_requests(self):
return [scrapy.http.FormRequest(self.cururl,callback=self.parse,headers=self.headers, cookies=self.cookies, meta=self.meta)]
def parse(self, response):
soup = BeautifulSoup(response.body,'html.parser',from_encoding='utf-8')
body_ul = soup.find_all("li" ,class_="con_list_item default_list")
#每次获取总页码
page_num= soup.find("div" ,class_="page-number").find("span" ,class_="span totalNum").get_text(strip=True)
self.totalPageCount = int(page_num)
for li in body_ul:
item = LgjobItem()
arg1 = li.find("div",class_="position").find("div",class_="p_top").find("em").get_text(strip=True)
arg2 = li.find("div",class_="position").find("div",class_="li_b_l").get_text(" / ",strip=True)
arg3 = li.find("div",class_="company").find("div",class_="industry").get_text(strip=True)
arg4 = li.find("div",class_="list_item_bot").find("div",class_="li_b_r").get_text(strip=True)
item['companyfullname'] = li.find("div",class_="company").find("div",class_="company_name").find("a").get_text(strip=True)
item['positionname'] = li.find("div",class_="position").find("div",class_="p_top").find("h3").get_text(strip=True)
item['salary'] = ((arg2 + "/").split('/')[0]).strip()
item['workyear'] = ((arg2 + "/").split('/')[1]).strip()
item['education'] = ((arg2 + "/").split('/')[2]).strip()
item['city'] = (arg1+'·'+arg1).split('·')[0]
item['district'] = (arg1+'·'+arg1).split('·')[1]
item['industryfield'] = ((arg3 + "/").split('/')[0]).strip()
item['financestage'] = ((arg3 + "/").split('/')[1]).strip()
item['positionlables'] = arg4.strip('“').strip('”')
item['firsttype'] = li.find("div",class_="list_item_bot").find("div",class_="li_b_l").get_text(",",strip=True)
yield item
if self.curpage < self.totalPageCount:
self.curpage += 1
self.cururl = "https://www.lagou.com/zhaopin/%s/%s/?filterOption=3"%(self.keyword,self.curpage)
yield scrapy.http.FormRequest(self.cururl,callback=self.parse,headers=self.headers, cookies=self.cookies, meta=self.meta)
执行爬取命令: scrapy startproject lgjob
爬取过程中命令行页面会显示每个属性值,本人电脑执行大约每5秒完成拉钩一页15个公司的数据处理。
最终结果如下:

参考:
Beautiful Soup 4.2.0 文档
Scrapy 0.24 文档
【python爬虫02】使用Scrapy框架爬取拉勾网招聘信息
【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(1)
Python爬虫系列之----Scrapy(八)爬取豆瓣读书某个tag下的所有书籍并保存到Mysql数据库中去
Scrapy中使用cookie免于验证登录和模拟登录