Logstash Grok详解
介绍
Logstash的Grok 可以使蹩脚的、无结构,杂乱无章的的日志内容结构化
需要注意的地方
grok 模式是正则表达式,因此这个插件的性能受到正则表达式引擎影响,效率并不高。如果通过给定的匹配格式匹配不上,那么Kibana查询的时候会自动打上tag 为 grok failed 的标签。
为什么通过正则表达式效率不高?
个人见解: 如果你的每一条日志都是无结构的,那么Grok 需要对每一条日志去正则匹配,这样子就相当于你用java或者php对每一个日志进行分析然后过滤出自己想要的字段一样,同时也和Linux上的Grep或者Awk 去过滤文本内容是一样,都会消耗内存和CPU资源。
然而假如你的日志是有结构化的比如JSON格式的日志,那么高级语言像Python等直接导入json的库就可以,(Logstash里面直接使用json的编码插件即可)不需要对每一条日志进行过多的分析,那样解析的效率就会很高
语法详解
grok模式的语法如下:
%{SYNTAX:SEMANTIC}
SYNTAX:代表匹配值的类型,例如3.44可以用NUMBER类型所匹配,127.0.0.1可以使用IP类型匹配。
SEMANTIC:代表存储该值的一个变量名称,例如 3.44 可能是一个事件的持续时间,10.0.0.2 可能是请求的client地址。
所以这两个值可以用 %{NUMBER:duration} %{IP:client} 来匹配。
你也可以选择将数据类型转换添加到Grok模式。默认情况下,所有语义都保存为字符串。如果您希望转换语义的数据类型。
例如将字符串更改为整数,则将其后缀为目标数据类型。
例如%{NUMBER:num:int}将num语义从一个字符串转换为一个整数。
测试匹配规则我们可以使用 Kiabna 的 Dev Tools 里的 Grok Debug 来实现,如下图:

匹配的典型格式举例
- %{NUMBER:duration} — 匹配浮点数
- %{IP:client} — 匹配IP
- (?([\S+]*)),自定义正则
- (?
([\S+]*)), 自定义正则匹配多个字符 - \s*或者\s+,代表多个空格
- \S+或者\S*,代表多个字符
- 大括号里面:xxx,相当于起别名
- %{UUID},匹配类似091ece39-5444-44a1-9f1e-019a17286b48
- %{WORD}, 匹配请求的方式
- %{GREEDYDATA},匹配所有剩余的数据
- %{LOGLEVEL:loglevel} ---- 匹配日志级别
- 自定义类型
(1) 命名捕获
(?[0-9A-F]{4}) # 这样可以匹配连续 长度为4的数字,并用xx来存储
(?[0-9A-F]{4}) # 这样可以匹配连续 长度为5的数字
(2) 创建自定义 patterns 文件进行匹配
- 2.1 创建一个名为patterns其中创建一个文件xx_postfix (名字任意定义),在该文件中,将需要的模式写为
模式名称,空格,然后是该模式的正则表达式
例如:
#contents of ./patterns/xx_postfix:
xx [0-9A-F]{10,11}
- 2.2 然后使用这个插件中的patterns_dir设置告诉logstash目录是你的自定义模式。
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:xx}: %{GREEDYDATA:syslog_message}" }
}
}
Grok过滤器配置选项
break_on_match
● 值类型是布尔值
● 默认是true
● 描述:match可以一次设定多组,预设会依照顺序设定处理,如果日志满足设定条件,则会终止向下处理。但有的时候我们会希望让Logstash跑完所有的设定,这时可以将break_on_match设为false
keep_empty_captures
● 值类型是布尔值
● 默认值是 false
● 描述:如果为true,捕获失败的字段将设置为空值
match
● 值类型是数组
● 默认值是 {}
● 描述:字段⇒值匹配
例如:
filter {
grok { match => { "message" => "Duration: %{NUMBER:duration}" } }
}
#如果你需要针对单个字段匹配多个模式,则该值可以是一组,例如:
filter {
grok { match => { "message" => [ "Duration: %{NUMBER:duration}", "Speed: %{NUMBER:speed}" ] } }
}
overwrite
● 值类型是 array
● 默认是[]
● 描述:覆盖字段内容
例如:
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite => [ "message" ]
}
}
实战举例
(1) 我们虚构的一个http请求日志:
114.114.114.114 GET /index.html 15824 0.043
可以使用如下grok pattern来匹配这种记录:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
(2)有一个这样的日志如下:
我们想要得到前面的时间 2020-03-18 以及 日志的级别 INFO ,如何编写Grok?
2020-03-18 14:04:23.944 [DubboServerHandler-10.50.245.25:63046-thread-168] INFO c.f.l.d.LogTraceDubboProviderFilter - c79b0905-03c7-4e54-a5a6-ff1b34058cdf CALLEE_IN dubbo:EstatePriceService.listCellPrice
解决如下:
\s*%{TIMESTAMP_ISO8601:timestamp} \s*\[%{DATA:current_thread}\]\s*%{LOGLEVEL:loglevel}\s*(?([\S+]*))
过滤结果显示如下:
{
"current_thread": "DubboServerHandler-10.50.245.25:63046-thread-168",
"loglevel": "INFO",
"class_info": "c.f.l.d.LogTraceDubboProviderFilter",
"timestamp": "2020-03-18 14:04:23.944"
}
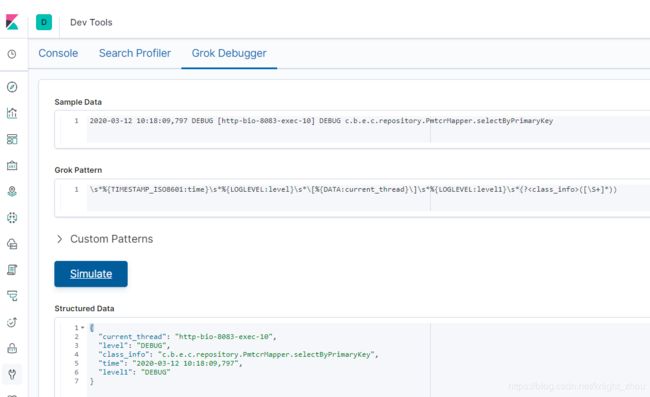
(3) 我们再来看另外一个Java日志内容:
2020-03-12 10:18:09,797 DEBUG [http-bio-8083-exec-10] DEBUG c.b.e.c.repository.PmtcrMapper.selectByPrimaryKey
如何将上面的进行grok 分割了?
\s*%{TIMESTAMP_ISO8601:time}\s*%{LOGLEVEL:level}\s*\[%{DATA:current_thread}\]\s*%{LOGLEVEL:level1}\s*(?([\S+]*))
运行结果如下: