HashMap和线程安全
HashMap是Java当中很常用的数据结构。
那么HashMap是线程安全的吗?高并发情况下HashMap会出现什么问题?为什么HashMap在高并发情况下会出现死锁?
Java8中,HashMap的结构有什么样的优化呢?
下面我们一起来看一下高并发情况下,HashMap可能出现的致命问题。
在分析高并发场景之前,我们需要先搞清楚[rehash]这个概念。
Rehash是HashMap在扩容时候的一个步骤。
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。
这时候,HashMap需要扩展它的长度,也就是进行Resize。

影响发生Resize的因素有两个:
1.Capacity
HashMap的当前长度。HashMap的默认初始长度是16 ,每次自动扩展或手动初始化时,长度必须是2的幂。
2.LoadFactor
HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:HashMap.Size >= Capacity * LoadFactor。
就是当HashMap中已经使用的长度大于HashMap的总长度乘以负载因子时就需要扩容了。
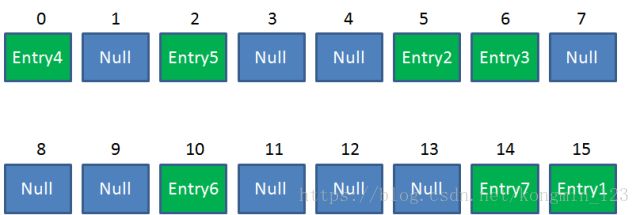
如上图,HashMap.Capacity = 8,HashMap.Size = 6,Capacity * LoadFactor = 8*0.75 = 6,
满足HashMap.Size >= Capacity * LoadFactor的条件,这个时候就需要扩容了,扩容需要调用HashMap的Resize( )方法。
HashMap的Resize( )方法,具体做了什么事情呢?
HashMap的Resize( )方法不是简单的把长度扩大,而是经过下面两个步骤。
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
让我们回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
Resize前的HashMap:

Resize后的HashMap:
ReHash的Java代码如下(基于JDK1.7的代码):
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
//扩容前的容量已经达到最大容量,将阈值设置为整型的最大值
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE;////修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
//初始化一个新的Entry数组
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
//计算是否需要对键重新进行哈希码的计算
useAltHashing |= sun.misc.VM.isBooted() && (newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);//将数据转移到新的Entry数组里
table = newTable;//HashMap的table属性引用新的Entry数组
//修改HashMap的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}可以看到上面的代码只是完成了Resize操作的第一步,扩容。 rezise( )方法调用了transfer( )方法,Resize操作的第二步Rehash在transfer( )方法中完成,下面我们来重点关注一下transfer( )方法。
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {//table是旧的Entry数组,遍历旧的Entry数组,取得旧Entry数组的每个元素
while(null != e) {//遍历数组中每一个Index下的链表
Entry next = e.next;
if (rehash) {//如果需要,重新计算元素的hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//!!重新计算每个元素在数组中的位置
e.next = newTable[i];//标记
newTable[i] = e;//将元素放在数组上
e = next;////访问下一个Entry链上的元素
}
}
} transfer( )方法中调用了IndexFor( )方法,该方法是根据元素的HashCode重新计算元素在数组中的index的。方法如下:
static int indexFor(int h, int length) {
return h & (length - 1);
}刚才的流程在单线程下执行并没有问题,可惜HashMap并非线程安全的。
那么在多线程环境下,HashMap的Rehash操作可能带来什么问题呢?
假设一个HashMap已经到了Resize的临界点。此时有两个线程A和B,在同一时刻对HashMap进行Put操作:
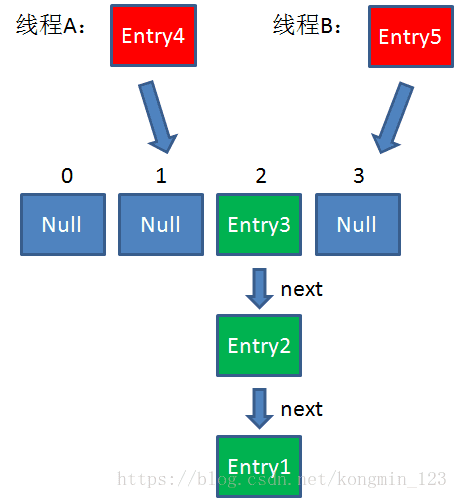
此时达到Resize条件,两个线程各自进行Rezie的第一步,也就是扩容:
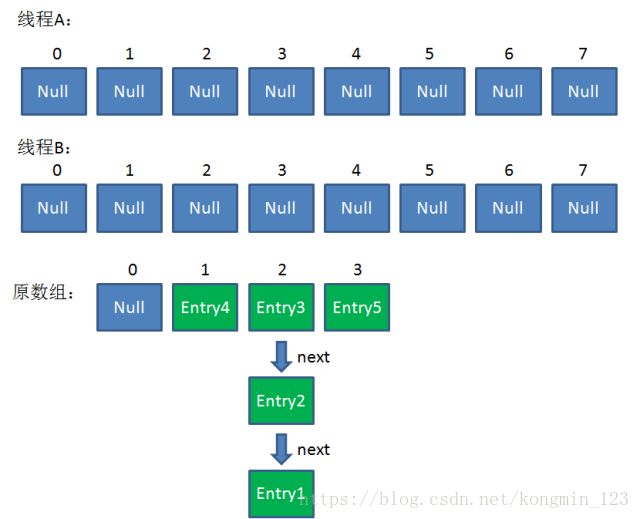
这时候,两个线程都走到了ReHash的步骤。让我们回顾一下ReHash的代码:

假如此时线程B遍历到Entry3对象,刚执行完红框里的这行代码,线程就被挂起。对于线程B来说:
e = Entry3
next = Entry2
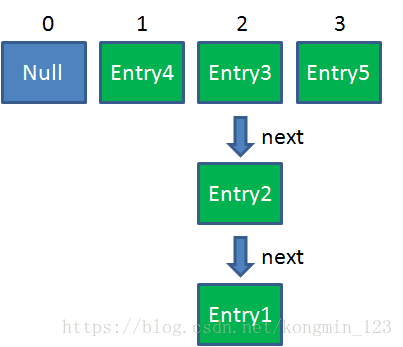
这时候线程A畅通无阻地进行着Rehash,当ReHash完成后,结果如下(图中的e和next,代表线程B的两个引用):
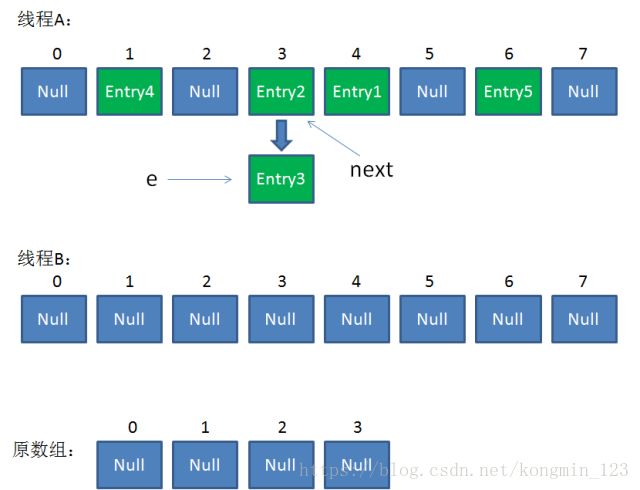
直到这一步,看起来没什么毛病。接下来线程B恢复,继续执行属于它自己的ReHash。线程B刚才的状态是:
e = Entry3
next = Entry2

当执行到上面这一行时,显然 i = 3,因为刚才线程A对于Entry3的hash结果也是3。

我们继续执行到这两行,Entry3放入了线程B的数组下标为3的位置,并且e指向了Entry2。此时e和next的指向如下:
e = Entry2
next = Entry2
整体情况如图所示:
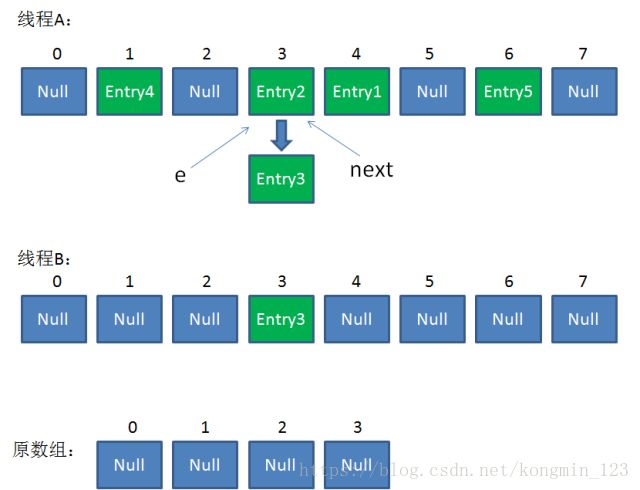
接着是新一轮循环,又执行到红框内的代码行:

e = Entry2
next = Entry3
整体情况如图所示:
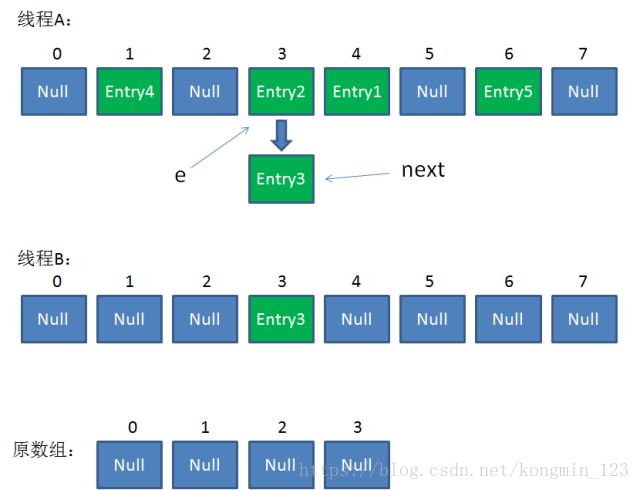
接下来执行下面的三行,用头插法把Entry2插入到了线程B的数组的头结点:

整体情况如图所示:
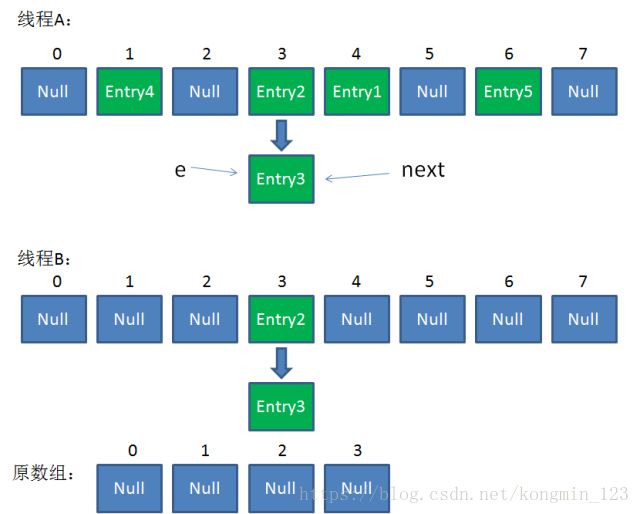
第三次循环开始,又执行到红框的代码:

e = Entry3
next = Entry3.next = null
最后一步,当我们执行下面这一行的时候,见证奇迹的时刻来临了:

newTable[i] = Entry2
e = Entry3
Entry2.next = Entry3
Entry3.next = Entry2
链表出现了环形!
整体情况如图所示:
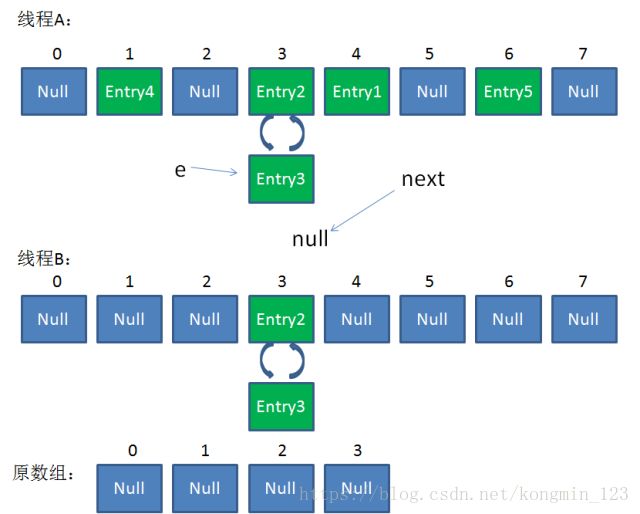
此时,问题还没有直接产生。当调用Get查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!
那么。如何杜绝这种情况的产生呢?
有许多种方法。既然HashMap在多线程环境下不是线程安全的,那么我们就可以使用一个线程安全的类替换它。
可以选择的类主要有两种:HashTable和ConcurrentHashMap。
Hashtable几乎可以等价于HashMap,但是他们两者也有区别。
HashMap和Hashtable的区别:
1.HashMap是非线程安全的,HashTable是线程安全的。
2.HashMap可以存储null(可以接受值为null的键(key)和值(value)),而Hashtable的键和值都不能为null。
3.由于Hashtable是线程安全的,它在使用的时候要做一些安全方面的控制,所以在单线程环境下它比HashMap要慢,HashMap执行速度相对较快。
4.由于他们两个的特点,HashMap适用于单线程环境,而HashTable适用于多线程环境。
HashTable中的方法都是同步的,被synchronized关键字修饰,从而保证了对元素访问和操作过程中的线程安全。
Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
所以在多并发场景下,我们通常采用另一种集合类ConcurrentHashMap,这个集合类兼顾了线程安全和性能。
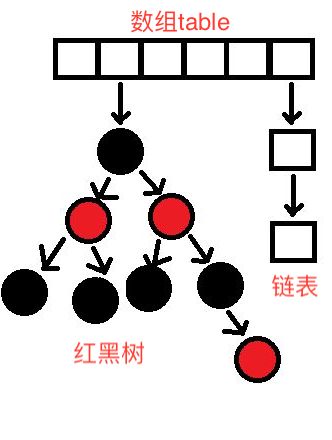
另外,Java8中,HashMap的结构做了一些优化。从结构上讲,JDK1.8对HashMap增加了红黑树的结构,当index的链表长度大于8时,会把链表转换为红黑树。原因就是对红黑树的操作除了插入之外,查找的性能要优于链表的顺序查找,提高查找效率。
JDK1.8的HashMap的结构如下:
最后再来总结一下:
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是:HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
关于高并发场景下的HashMap就讲到这里啦。
参考:程序员小灰—《高并发下的HashMap》