Java对象在内存中的结构和锁状态升级过程
目录
- Mark Word
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
- Class Word
- Instance Data
- Padding
java对象在堆中主要分为四部分结构, 分别是对象头MarkWord, 对象指针ClassWord, 实例对象(如果对象是数组的话, 这里需要再分成两部分, 多了一个存储数组长度的数据位), 8字节对齐位. 下面以64位的JVM为例, 分析内存中对象的各个结构分别存储什么信息和作用.
| 结构 | 大小 | 作用 |
|---|---|---|
| Mark Word | 8bytes | 用来存储对象的各种状态, hash和锁标记等 |
| Class Word | 4 | 8bytes | 指向方法区Class信息的指针, 用来确定当前对象是哪个Class的实例和访问方法 |
| Instance Data | - | 存储对象中的实例数据, 和数组的长度 |
| Padding | 0 - 7bytes | 补齐填充, 如果整个对象在堆上不足8字节倍数的话, 按8字节倍数对齐 |
Mark Word
Mark Word用来存储对象的 identity hash code, Thread ID, GC年代, 偏向锁状态, 锁状态信息. 其中的很多状态和信息会随着当前对象的锁状态发生变化而变化. 所以接下来就根据锁的状态为主轴, 列出Mark Word的信息变化.
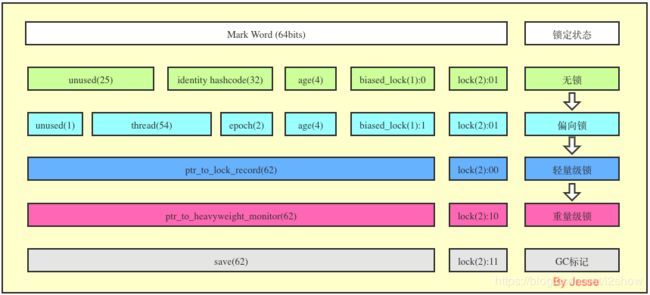
无锁状态
当new出对象后, 并且没有线程锁定当前对象时. 当前对象就处于无锁状态.
-
identity hashcode
占用32bits, identity hashcode会根据物理内存地址来生成hashcode, 保证每一个不同内存对象的hashcode都不一样. 对象加锁后, 没有足够的空间来存储hashcode了, 就将hashcode转移到管程Monitor中维护.
-
age
占用4bits, 代表当前对象此刻被GC的次数. 因为只有4个bit, 所以最大只能到15, 默认情况下就是age达到15这个阈值后GC就会将当前对象从年轻代转移到老年代. 这个age可以根据JVM参数-XX:MaxTenuringThreshold来设置. 绝大部分情况默认都是15次, GC的CMS默认是6次.
-
biased lock
占用1bit, 通过 0 | 1来判断当前是否为偏向锁状态. 无锁状态为0.
-
lock
占用2bits, 用来区分轻量级锁, 重量级锁, GC标记和其他状态. 无锁状态为01
偏向锁状态
当对象在无锁状态下, 有一个线程要锁定当前对象时, 锁状态升级到偏向锁. 偏向锁在无线程竞争时, 消除同步达到提高效率的目的.
- hashcode迁移到管程Monitor中管理
- 将biased lock标记位置为1
- 当前要锁定的线程信息存入到thread标记位中
- epoch是一个标记位, 初始值是类中epoch的值. 当一个类的对象发生偏向锁撤销(当前偏向线程A, A执行完后线程B申请锁, 就需要撤销偏向锁再重偏向线程B)的次数超过阈值(XX:BiasedLockingBulkRebiasThreshold)20后, 会对该类对象的锁状态进行批量重偏向, epoch会自增并同步更新所有类对象的Mark Word, 更新后对象中的epoch就和class中的epoch信息不一致了, 这时再有线程申请锁时, 直接进行重偏向CAS替换thread信息.
- 当偏向锁撤销超过阈值(XX:BiasedLockingBulkRevokeThreshold)40次后, 虚拟机认为这个类的对象撤销锁太频繁了直接升级所有类对象的偏向锁锁为轻量级锁.
偏向锁之所以会叫偏向锁就是因为它会保存申请锁的线程信息, 并且之后处理会偏向于存储这些信息的线程. 根据一个没有来源的统计描述绝大多数的锁大部分情况下都是被一个线程所持有, 并且我们日常中大部分使用的锁都是可重入锁. 当同一个线程多次申请当前对象的锁时(偏向锁状态下), cpu只需要判断一下偏向锁保存的线程id是否跟正在申请锁的线程一致, epoch是否和类的epoch保持一致, 如果一致的话就继续保持偏向锁的状态并且不需要做额外的检查切换工作(偏向锁加锁解锁的过程效率极高). 如果不一致, 就看上个线程是否还存活, 如果线程不在了就撤销老的偏向锁进行重偏向. 否则就撤销偏向锁升级到轻量级锁.
轻量级锁状态
当有超过一个存活线程向当前对象申请锁状态时, 升级为轻量级锁. 轻量级锁在少量线程竞争时, 使用CAS(CAS解析)和自旋等待在用户态消除同步, 通常比直接使用重量级锁效率要高.
- 将lock状态标记为00
- 拷贝Mark Word中的其他数据到持锁线程的锁记录中.
- 将lock record指针指向持锁线程的锁记录上.
锁的字节码级别是由两个指令组成, 分别是锁的入口monnitorenter和锁的结束monitorexit. 当线程进入monnitorenter后, 会在自己的线程的栈帧上建立一个锁记录, 并通过CAS机制尝试将锁对象的Mark Word中的信息拷贝到自己的栈帧中, 并将ptr_to_lock_record指针指向自己线程栈帧的锁记录上. 也标志了当前对象现在被该线程锁了. 线程退出同步块后将Mark Word再通过CAS还给对象头, 让其他线程知道现在锁空闲了.
轻量级锁也是自旋锁, 如果锁的对象头中没有Mark Word信息并有一个锁记录指针, 那么其他线程就一直不能获取到锁, 线程就会通过执行一个空循环等待. 自旋的过程中线程还是在用户态下活跃运行, 保证了线程的响应速度, 一有锁资源立刻就能继续运行线程. 但是自旋过程会消耗CPU资源. 如果很多线程都在自旋, 或者有线程一直在自旋那么资源的消耗还是很可观的. 所以当自旋超过默认10后, 或有更多的线程参与进来则膨胀为重量级锁.
重量级锁状态
在重量级锁状态下, 对象头中的ptr_to_heavyweight_monitor指针指向管程Monitor对象. 之后线程的锁分配操作就要从用户态移交给内核态去处理, 让cpu通过操作系统级别的互斥量Monitor对象来管理锁, 系统创建一个等待队列, 没获取到锁的线程被系统挂起并在队列中排队, 不再像自旋锁那样不停得消耗额外的资源. 就是因为有内核态操作, 操作系统级调度, 挂起线程这些很重的操作, 所以叫重量级锁.
Class Word
ClassWord中存储的是一个指针, 这里所占的空间会根据JVM参数的不同有不同的大小. 在默认没有开启指针压缩参数(-XX:-UseCompressedOops)时, ClassWord占8个字节, 开启指针压缩后占4个字节. 开启指针压缩是为了减少一些场景中指针的大小, 避免较大的指针在主存和缓存之间移动数据耗费更多的带宽, 也会在GC时带来更多的压力.
ClassWord指向的是方法区的Class信息, 对象可以通过这个指针访问自己的类信息和方法信息.
Instance Data
数据实例就是存储对象属性的空间, 如果当前对象是数组, 那么要再多出8个字节用来存储数组的长度.
基础类型直接按照自己的大小存储在Instance Data区域中. 对象引用的话存放一个8字节的指针, 指向当前对象所持有的对象. 对象引用的指针在开启指针压缩后体积也会改为占用4字节.
Padding
为什么需要按固定字节数对齐呢? 如果不对齐数据, 处理器从内存中拿到数据后还需要再调整一下才能正确得访问对象. 对齐后可以牺牲一小部分空间, 来提升对象的访问效率. 也可以提升内存GC时拷贝内存时的效率.
转载请注明出处:https://blog.csdn.net/l2show/article/details/103671211