消息队列——RabbitMQ的基本使用及高级特性
文章目录
- 一、引言
- 二、基本使用
- 1. 简单示例
- 2. work queue和公平消费消息
- 3. 交换机
- 三、高级特性
- 1. 消息过期
- 2. 死信队列
- 3. 延迟队列
- 4. 优先级队列
- 5. 流量控制
- a. 服务端限流
- b. 客户端限流
- 6. 消息可靠性
- a. 如何确保消息发送到交换机
- b. 如何确保消息正确路由到队列
- c. 消息持久化存储
- d. 如何确保消息正确投递到消费者
- e. 如何保证消息幂等性
- f. 如何保证消息的顺序
- 四、总结
一、引言
Rabbit是基于AMQP协议并使用Erlang开发的开源消息队列中间件,它支持多种语言的客户端,也是目前市面上使用比较广泛的一种消息队列,因此学习并掌握它是非常有必要的。本文主要基于Java客户端进行讲解,不涉及环境搭建部分。
二、基本使用
1. 简单示例
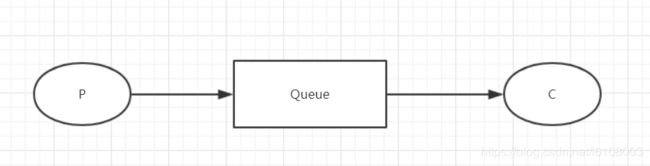
上图就是Rabbit最简单的一种使用,生产者产生消息发送到队列,消费者订阅队列消费消息,典型的点对点模型,代码也很简单。首先我们需要一个获取连接的工具类(在后面的示例中都会使用到它):
public static Connection getConnection(String host, Integer port, String username, String password) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(host); // 服务端ip
factory.setPort(port); // 端口号
factory.setVirtualHost("/");
factory.setUsername(username); // 用户名
factory.setPassword(password); // 密码
return factory.newConnection();
}
上面代码不难理解,就是通过连接工厂设置连接参数,并新建一个连接。VirtualHost可能会比较疑惑,可以类比虚拟机的概念,RabbitMQ支持虚拟消息服务器,每个虚拟服务器之间是相互独立,互不影响的,基于此我们也可以做相应的权限管理。
try (Connection connection = ConnectionUtils.getConnection("192.168.0.106", 5672, "lwj", "lwj");
Channel channel = connection.createChannel()) {
// 声明队列,参数含义:1. 队列名称 2. 是否持久化 3. 该队列是否仅对首次声明它的连接可见 4. 是否自动删除 5. 队列参数
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 发送消息,参数含义:1. 交换机名称,未声明使用默认交换机 2. routingKey 3. 消息属性 4. 消息
channel.basicPublish("", QUEUE_NAME, null, "Hello, world!".getBytes());
} catch (TimeoutException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
上面的是生产者的代码,因为连接实现了AutoCloseable接口,所以可以使用try-with-resource语法(不过再消费者方就不要使用了)简化开发。代码注释都很清楚了,其中交换机和routingKey的先忽略,稍后会详细讲解,下面就来看看消费者的代码:
// 这里最好不要使用try-with语法,在异步接收消息情况下会导致连接关闭
Connection connection = ConnectionUtils.getConnection("192.168.0.106", 5672, "lwj", "lwj");
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println("waitting msg......");
// 使用DefaultConsumer处理消息
// DefaultConsumer consumer = new DefaultConsumer(channel) {
// @Override
// public void handleDelivery(String consumerTag, Envelope envelope,
// AMQP.BasicProperties properties, byte[] body) throws IOException {
// String msg = new String(body, "utf8");
// System.out.println("receive msg: " + msg);
// }
// };
// 消费消息后的回调函数
DeliverCallback callback = (consumerTag, delivery) -> {
String msg = new String(delivery.getBody(), "utf8");
System.out.println("receive msg: " + msg);
};
// 接收消息
channel.basicConsume(QUEUE_NAME, true, callback, consumerTag -> {});
前三步和生产者是一样的,也是获取连接创建Channel,并通过Channel创建队列,需要注意生产者和消费者声明创建的队列属性必须要是一样的,否则会抛出异常。接着通过basicConsume方法接收消息,但该方法只是从队列中获取消息,对于消息的处理有两种方式:一种是使用上面注释代码中的DefaultConsumer,并重写handleDelivery方法,在该方法中实现我们的业务逻辑消费消息;另外一种就是使用回调函数DeliverCallback,该方式是新版本中新增的,也是官方Demo中使用的方式。至于两种方式有何优缺点,笔者还未研究。
2. work queue和公平消费消息
以上就是RabbitMQ最简单的使用,要是觉得一个消费者不够,我们还可以定义多个消费者同时消费同一个队列,也就是work queue,像下面这样:
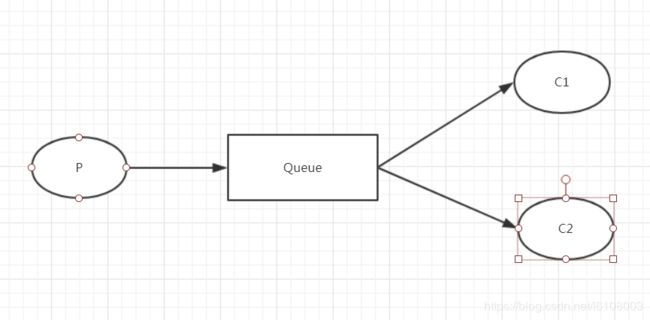
当多个消费者订阅同一个队列时,消息采取轮询的方式将消息分发到各个消费者上去(详细代码)。但轮询的方式并不公平,如偶数或奇数都是耗时的操作时,就会导致其中一个消费者消息积压,而另一个空闲等待的情况,所以可以通过指定prefetchCount参数来是实现公平的消息消费策略。熟悉ActiveMQ的对这个参数应该不陌生,我之前文章也有讲过,不过RabbitMQ的这个参数和ActiveMQ的有些不一样。ActiveMQ这个参数表示消费者一次性从服务器取走的消息数量,而在RabbitMQ中则是表示消费者消息最大积压数量,可以通过以下方式设置:
channel.basicQos(10);
即当该参数指定为10且当前消费者积压消息达到10时,就不会接收新的消息,新的消息会被分发到其它空闲的消费者那去(该参数也可以用来做客户端限流,这个会在后面详细讲解。)。
3. 交换机
上述为了方便,所以只描述了生产者-队列-消费者,但在RabbitMQ服务器中实际上还存在一个交换机的概念:

生产者首先都是将消息发送到交换机上,然后交换机再将消息分发到与之绑定的队列上去,和队列一样,我们可以使用自己创建的交换机,若没有创建,则使用默认的交换机,RabbitMQ默认提供了一些交换机,在Web管理页面可以看到(这个是RabbitMQ提供的一个插件,搭建服务器的时候可以开启使用,默认访问地址是:ip:port/15672,需要账号密码登录):
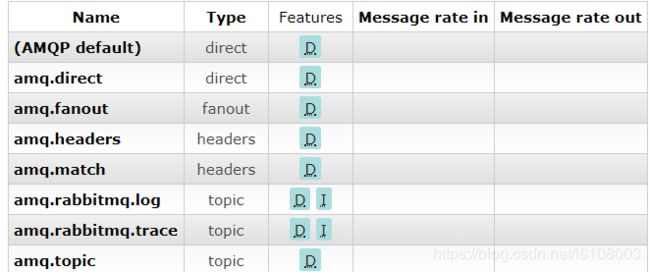
上图就是RabbitMQ默认会创建的交换机,当我们未创建交换机发送消息时,默认都是发送到AMQP default上。另外通过上图我们还可以看到交换机是有不同类型的,RabbitMQ支持direct、topic、fanout和headers四种类型的交换机,其中headers类型笔者还未深入研究,这里不过多讲解,下面主要来看看前三种类型的交换机:
- direct:直连交换机,队列通过routingKey绑定到该类型的交换机上,只有消息的routingKey和队列的routingKey完全匹配时,该队列才能接收到该消息。
// 声明直连类型的交换机
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
// 参数含义:1. 队列名称 2. 是否持久化 3. 该队列是否仅对首次声明它的连接可见 4. 是否自动删除 5. 队列参数
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 绑定交换机和队列,并指定routingKey
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "direct");
// 发送消息,只有routingKey为direct的队列才能接收到这条消息
channel.basicPublish(EXCHANGE_NAME, "direct", null, "Hello, world!".getBytes());
上述代码演示了生产者如何将消息发送到指定routingKey的直连类型交换机上,我们可以发现当使用默认交换机时,默认是使用队列名字作为routingKey(详细代码)。另外需要注意的是,声明队列和交换机可以在生产者或消费者任一方声明(根据实际情况选择,一般都是在消费者方声明,因为每个消费者的属性一般都不会相同),也可以同时声明(需要保证两边声明的交换机和队列的属性和参数都一样)。
- topic:主题交换机,顾名思义,每个队列可以指明自己关心的主题,即只接受到与自己routingKey匹配的消息,这里的匹配是指routingKey必须以“X.X.X”格式声明,同时提供“*”和“#”两个范围匹配符,前者代表任一一个单词,后者代表任意多个单词,单词以“.”分隔。

如上图:“*.black.*”就可以接收到“small.black.dog”和“small.black.pig”的消息,而“big.fat.black.pig”类型的消息就无法接收;“*.*.pig”可以接收到“small.black.pig”消息,接收不到“small.black.dog”和“big.fat.black.pig”;“big.#”只能接收到“big.fat.black.pig”。而当一个队列绑定了多个routingKey且消息的routingKey都能与之匹配时,会发生什么呢?当然消息也只会发送一次,不然就消息重复了(详细代码)。 - fanout:广播交换机,该类型的交换机不处理routingKey,只要与之绑定的队列就能接收到所有的消息(详细代码)。
掌握以上所讲,我们就能熟练使用MQ发送接收消息,但仅靠这些肯定无法应付复杂的业务场景,因此RabbitMQ也提供了丰富的特性供我们选择。
三、高级特性
1. 消息过期
消息如果长时间没有被消费,就会一直占用服务器资源,因此给消息设置过期时间是一个很常见的需求,在RabbitMQ中有两种方式设置过期时间:
- 声明队列时给队列设置过期属性x-message-ttl,这样该队列中所有消息默认过期时间就是队列的过期属性指定的时间:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-message-ttl", 20000);
channel.queueDeclare(QUEUE_NAME, false, false, false, arguments);
- 给单条消息添加过期属性:
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 持久化
.contentType("utf8")
.expiration("5000") // 过期时间 5s
.build();
// 发送到直连类型的amqp default exchange,只要有队列名字和routing key相同就能收到消息
channel.basicPublish("", QUEUE_NAME, properties, "Hello, world!".getBytes());
当上述两种方式同时存在时,以最小过期时间为准(详细代码)。
2. 死信队列
当消息过期后,消息会去到哪里呢?一种是直接删掉,另外一种则是可以绑定一个死信队列,消息过期后会直接进入死信队列。
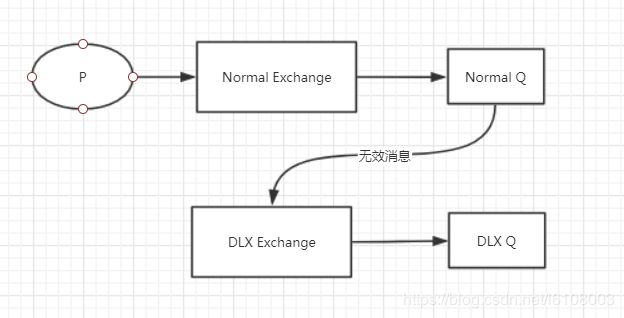
注意上图中我写的是无效消息,说明不仅仅是过期消息会进入死信队列,还有以下情况:
- 拒收且未设置重新入队的消息
- 队列达到最大长度时,先入队的会被淘汰进入死信队列
下面是代码演示,首先需要三个消费者来演示不同的情况,每个消费者创建一个单独的队列且绑定同一个死信队列:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME); // 将队列和死信队列进行绑定
channel.exchangeDeclare(TEST_EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
channel.queueDeclare(TEST_QUEUE_NAME, false, false, false, arguments);
channel.queueBind(TEST_QUEUE_NAME, TEST_EXCHANGE_NAME, "reject");
// 创建死信队列及交换机
channel.exchangeDeclare(DLX_EXCHANGE_NAME, BuiltinExchangeType.DIRECT, false, false, false, null);
channel.queueDeclare(DLX_QUEUE_NAME, false, false, false, null);
// 需要注意如果与该死信队列绑定的队列指定了routingKey,死信队列也需要指定所有需要接收的routingKey,否则会收不到消息
channel.queueBind(DLX_QUEUE_NAME, DLX_EXCHANGE_NAME, "reject");
DeliverCallback callback = (consumerTag, delivery) -> {
String msg = new String(delivery.getBody(), "utf8");
System.out.println("receive msg: " + msg);
// (reject || nack) && requeue == false会进入死信队列
if ("ack".equals(msg)) {
// 手动应答
// multiple: 是否批量应答,true表示会批量确认当前tag及小于当前tag且未被确认的消息
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} else if ("reject".equals(msg)) {
// 单条拒收消息
// requeue:拒收后是否重新入队,true会重新入队导致重复消费消息,false则是直接删除
channel.basicReject(delivery.getEnvelope().getDeliveryTag(), false);
} else if ("nack".equals(msg)) {
// 批量拒收消息
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), true, false);
}
};
// 接收消息
channel.basicConsume(TEST_QUEUE_NAME, false, callback, consumerTag -> {});
上面是演示拒收的消费者,接着是演示过期消息的消费者:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-message-ttl", 10000); // 过期的消息会直接进入私信队列
arguments.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME); // 将队列和死信队列进行绑定
channel.exchangeDeclare(TEST_EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
channel.queueDeclare(TEST_QUEUE_NAME, false, false, false, arguments);
channel.queueBind(TEST_QUEUE_NAME, TEST_EXCHANGE_NAME, "ttl");
// 创建死信队列及交换机
channel.exchangeDeclare(DLX_EXCHANGE_NAME, BuiltinExchangeType.DIRECT, false, false, false, null);
channel.queueDeclare(DLX_QUEUE_NAME, false, false, false, null);
// 需要注意如果与该死信队列绑定的队列指定了routingKey,死信队列也需要指定所有需要接收的routingKey,否则会收不到消息
channel.queueBind(DLX_QUEUE_NAME, DLX_EXCHANGE_NAME, "ttl");
// 不消费等待消息过期进入死信队列
// channel.basicConsume(TEST_QUEUE_NAME, false, callback, consumerTag -> {});
将接收消息的代码注释掉即可等到消息超时,然后是演示超出队列最大长度的代码:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-max-length", 2); // 允许最大积压消息数,会淘汰掉老的
arguments.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME); // 将队列和死信队列进行绑定
channel.exchangeDeclare(TEST_EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
channel.queueDeclare(TEST_QUEUE_NAME, false, false, false, arguments);
channel.queueBind(TEST_QUEUE_NAME, TEST_EXCHANGE_NAME, "maxLen");
// 创建死信队列及交换机
channel.exchangeDeclare(DLX_EXCHANGE_NAME, BuiltinExchangeType.DIRECT, false, false, false, null);
channel.queueDeclare(DLX_QUEUE_NAME, false, false, false, null);
// 需要注意如果与该死信队列绑定的队列指定了routingKey,死信队列也需要指定所有需要接收的routingKey,否则会收不到消息
channel.queueBind(DLX_QUEUE_NAME, DLX_EXCHANGE_NAME, "maxLen");
// 积压消息测试超出两条会将先进入队列的放入死信队列
// channel.basicConsume(TEST_QUEUE_NAME, true, callback, consumerTag -> {});
同样将接收消息代码注释掉来实现消息积压,最后看看消费者生产消息的代码:
String[] msg = {"ack", "reject", "nack", "ttl", "max1", "max2", "max3"};
String routingKey = "reject";
for (int i = 0; i < msg.length; i++) {
if ("ttl".equals(msg[i])) {
routingKey = "ttl";
test_exchange_name = "test dlx exchange with ttl";
}
if (i > 3) {
routingKey = "maxLen";
test_exchange_name = "test dlx exchange with max length";
}
channel.basicPublish(test_exchange_name, routingKey, null, msg[i].getBytes());
}
因为每个消费者我都设定了routingKey,所以不同的消息会发送到对应的消费者上去(需要注意与之绑定的死信队列也需要指定相同的routingKey才能接收到死亡的消息)。再指定一个消费者消费死信队列消息并打印结果:
// 消费死信队列
DeliverCallback dlxCallback = (consumerTag, delivery) -> {
String msg = new String(delivery.getBody(), "utf8");
System.out.println("dlx msg: " + msg);
};
channel.basicConsume(DLX_QUEUE_NAME, true, dlxCallback, consumerTag -> {});
// 输出结果
waitting msg......
receive msg: ack // 手动确认的消息
receive msg: reject // 单条拒收的消息
receive msg: nack // 批量拒收的消息
dlx msg: max1 // 超出最大长度的队列将先进入队列的消息送到了死信队列
dlx msg: reject // 拒收的消息
dlx msg: nack // 批量拒收的消息
dlx msg: ttl // 过期的消息
详细代码
3. 延迟队列
什么是延迟队列,就是我们有时会希望消息不要立即被消费者消费,而是等到一定时间后再被消费。RabbitMQ本身没有提供这种功能,而是可以通过rabbitmq-delayed-message-exchange插件实现,或者使用过期时间加死信队列也可以实现。这里主要说说后者,很简单,也就是给队列设定一个过期时间,消费者只消费死信队列,这样过期时间也就起到了延迟的作用。
4. 优先级队列
RabbitMQ还提供了优先级队列的功能,可以通过如下方式设定队列的优先级等级:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-max-priority", 10); // 设置优先级
channel.queueDeclare(QUEUE_NAME, false, false, false, arguments);
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
在发送消息时指定消息的优先级:
for (int i = 0; i < 10; i++) {
// 设置消息的优先级,优先级越高越先被消费,当且仅当消息积压时有效
AMQP.BasicProperties basicProperties = new AMQP.BasicProperties().builder()
.priority(i+1)
.build();
channel.basicPublish(EXCHANGE_NAME, "", basicProperties, (i + "").getBytes());
}
优先级越大的消息越先被消费,但是只在消息积压的情况下有用,另外,当消息的优先级比队列的优先级还大时,统一按照队列的最高优先级处理(详细代码)。
5. 流量控制
RabbitMQ流量控制可以通过两种方式实现:服务端限流和客户端限流。
a. 服务端限流
RabbitMQ 会在启动时检测机器的物理内存数值。默认当 MQ 占用 40% 以上内存时,MQ 会主动抛出一个内存警告并阻塞所有连接(Connections)。可以通过修改 rabbitmq.config 文件来调整内存阈值,默认值是0.4。另外,如果剩余磁盘空间在 1GB 以下,RabbitMQ 会主动阻塞所有的生产者,这个阈值也是可调的。
注意队列长度限制只在消息堆积的情况下有意义,而且会删除先入队的消息,不能实现服务端限流。
b. 客户端限流
客户端限流在上文提到过了,就是通过设置prefetchCount值来实现,当消息积压到prefetchCount指定的值时,服务端就不会再往该队列分发消息,也就起到了一个限流的作用。下面通过两个消费者消费同一队列来演示:
- 消费者1
// 设置最大处理消息数
channel.basicQos(2);
channel.basicConsume(QUEUE_NAME, true, callback, consumerTag -> {});
- 消费者2
channel.basicQos(3);
// 关闭自动确认
channel.basicConsume(QUEUE_NAME, false, callback, consumerTag -> {});
上面代码的意思是,消费者1最大积压2条消息,消费者2最大积压3条消息,关闭掉消费者2的自动确认来实现消息积压,现在往队列中发送消息:
for (int i = 0; i < 10; i++) {
channel.basicPublish(EXCHANGE_NAME, "", null, ("hello, " + i).getBytes());
}
结果如下:
// 消费者1的结果
receive msg: hello, 0
receive msg: hello, 2
receive msg: hello, 4
receive msg: hello, 6
receive msg: hello, 7
receive msg: hello, 8
receive msg: hello, 9
// 消费者2的结果
receive msg: hello, 1
receive msg: hello, 3
receive msg: hello, 5
可以看到消费者2只接收了3条消息,由于一直未确认,所以不会接收新的消息。
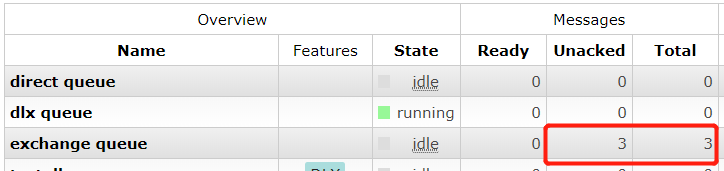
当消费者2停掉后,这3条消息又会变为ready状态等待消费(详细代码)。
6. 消息可靠性

使用消息队列时,我们首先要考虑的一个问题就是如何保证消息的可靠性,即消息不丢失,准确投递等问题。从上图我们可以发现在消息从生产到消费的任何一个步骤中都存在问题,即:
- 如何保证消息准确发送到了交换机上
- 如何保证消息能够发送到正确的队列
- 队列中如何持久化存储消息
- 如何确保消息正确投递到了消费者且被消费
- 如何保证消息幂等性
- 如何保证消息的顺序
下面就一一来讨论各个问题的解决方案。
a. 如何确保消息发送到交换机
这个和ActiveMQ也一样,RabbitMQ提供了事务模式和确认模式。
- 事务模式:生产者可以通过channel.txSelect开启事务模式,通过channel.txCommit提交消息,通过channel.txRollback回滚消息(详细代码)。
- 确认模式:生产者同样可以通过channel.confirmSelect开启确认模式,而在确认消息时又有三种方式,分别是单条确认、批量确认和异步确认。
b. 如何确保消息正确路由到队列
当消息从交换机发送到队列时,也存在不可靠问题,比如routingKey错误,这时消息可靠性如何保证呢?RabbitMQ也提供了两种方式:
- mandatory参数和ReturnListener监听器:首先可以给Channel添加一个监听器,并在发送消息时设置mandatory参数为true,这样当消息无法正确路由时,就会返回给生产者并被监听器捕获(详细代码)。
- 使用备份交换机:在声明交换机时,可以指定alternate-exchange参数,即备份交换机的名称,需要注意该方式存在以下问题(详细代码):
- 如果备份交换机不存在,消息丢失,没有异常
- 如果备份交换机未绑定队列,消息丢失,没有异常
- 如果备份交换机没有匹配到任何队列,消息丢失,没有异常
c. 消息持久化存储
消息分发到队列但还未被消费,这是队列存在挂掉的风险,如果不设定持久化存储就会导致消息丢失。另外还可以考虑搭建集群来避免单机风险(集群搭建不在本文讨论范围内)。
d. 如何确保消息正确投递到消费者
RabbitMQ也是采用了消息确认模式,分为自动确认和手动确认,手动确认时可以表明是否拒收以及拒收后是否重新入队,通过消息确认即可保证消息正确投递到消费者。但这里也会引出一个问题,当消息被拒收且设置重新入队时,就可能会导致消息被重复消费,如果不设置重新入队,那么消息就会直接被删除掉,导致消息丢失,因此需要根据业务来考虑。
e. 如何保证消息幂等性
导致消息重复可能会有两种原因,一个是生产中开启确认模式但未收到确认就会重复发送,二个是消费者未确认消息导致消息重复投递。如何避免这两种情况呢?单从RabbitMQ上是无法完全解决这个问题的,我们可以考虑给每个消息生成唯一的id标识,消费者记录已经消费的消息id,如果有重复的直接丢弃或者对比差异。
f. 如何保证消息的顺序
当一个队列有多个消费者时,消息的顺序是无法保证的,因为每个消费者消费速率都是不一样的,这时我们也可以考虑通过全局编号等方式来解决避免。
四、总结
本文从基础使用和常用高级特性方面对RabbitMQ做了一个梳理和总结,由于笔者也是初学,文中错误欢迎指出,深入研究还需参考官方文档。