一文看懂图网络——实时语义分割网络搜索
快来投稿!我们在等你!
我们给你一个舞台,
Show出你的精彩!
欢迎扫描文末二维码进行投稿
本文出自商汤研究院石建萍团队(SenseTime Research)及浙大DCD实验室李玺团队。原论文发表于CVPR2020。
设计一个轻量级的语义分割分割网络往往需要研究者经过大量实验从而得到一个在精度和速度之间权衡得比较好的网络,该过程往往是费时、费力且要求研究者在分割领域有着较深的见解。本文作者从实时小网络的实际诉求 (精度和速度的极致权衡) 出发,构建了一个新的搜索空间,从而更高效的完成小网络的搜索,具体包括:
和常见的NAS方法相比,打破Cell共享的搜索方式,让每个Cell独立搜索,因而在搜索过程中能够更加灵活的进行精度和速度的权衡;
为方便优化,利用图卷积神经网络构建推理图,作为相邻Cell间的交流机制,从而引导整个搜索过程;
将网络的 Latency 纳入考虑,加入到搜索的优化过程中,配合分割损失,能够根据实际需求进行网络的定制化搜索;
一、背景
1.1 Cell共享的NAS方法
常见的NAS方法搜索两种类型的Cell (Normal Cell和Reduction Cell),然后将搜索到的Cell堆叠形成整个网络,这极大的减小了搜索空间和优化难度,且在理论上也验证对性能不会有太大的影响。然而,实时的小网络需要在精度和速度间进行权衡,我们在实验过程中发现,如果直接使用传统的NAS方法会产生两方面不足: a) 在不添加任何网络速度的约束时,容易搜索到复杂Cell结构 (精度Reward),堆叠形成的网络会有较高的Latency,无法满足速度需求;b) 当添加Latency约束时,很容易学习到简单的Cell(倾向于选择简单的operations),堆叠形成的网络虽然有较高的速度,但精度经常无法满足要求;
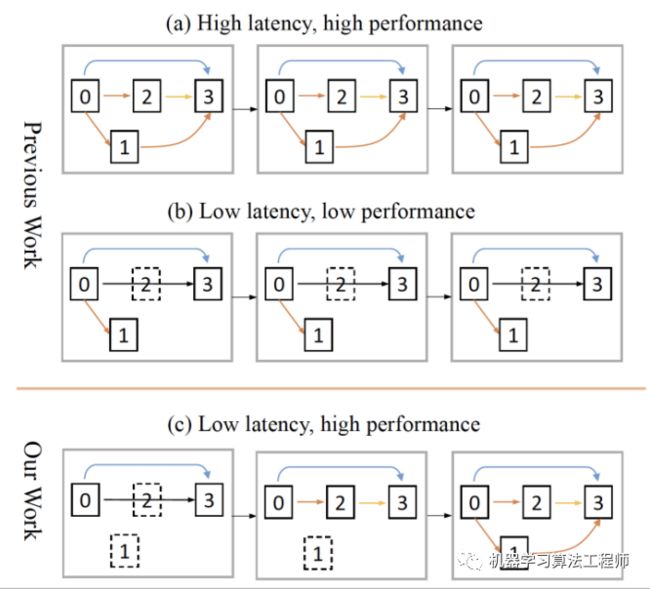
a) 复杂Cell堆叠形成的高Latency网络;b) 简单Cell堆叠形成的低性能网络;c) 在Latency约束下,每个Cell结构能够自适应,更好的权衡速度和精度;
因此,我们认为在搜索实时小网络时,应该打破这种共享的关系,让每个Cell可以自适应的决定自己的结构(如上图c)。这样,为了达到一个更好的权衡状态,网络可以在浅层处使用较为简单的Cell以加快速度,而在深层使用稍微复杂的Cell以提高精度,从而在搜索的过程中灵活地进行精度和速度的权衡。
1.2 自适应Cell的优化
依上节所述,为了能够更加灵活地进行精度和速度的权衡,Cell应该具备独立搜索的能力。但通过实验,我们发现两个现象:1) 如果只是简单的让每个Cell独立的进行搜索,搜索出来的网络精度会有较大的损失,原因在于Cell的独立扩大了搜索空间,从而增加了优化的难度 (论文中Fig 5)。2) 传统的NAS使用了共享的Cell,相当于网络中的每一个Cell都知道其他Cell的选择(identical),但独立的方式丢失了这部分信息。基于这两个发现,一个直观的想法是,在搜索过程中让Cell间能够彼此进行信息交流(or 共享信息)是有必要的。具体地,我们利用图卷积神经网络在每两个相邻Cell间构建了一个推理图,作为信息传播(information propagation)机制,从而能够将上一个Cell的状态信息(i.e. 操作选择信息)传播至当前Cell。这样,从第一个Cell开始,每一个Cell的状态信息都能够传播给下一个Cell,从而达到信息共享的目的。
1.3 Latency导向的实时网络搜索
为了得到一个实时的分割网络,在搜索过程中,我们将网络的Latency纳入考虑,使得搜索朝着高精度,低Latency方向进行。具体地,我们测量了每个候选operation的前向GPU耗时,并构建了离线的Latency查找表,将网络的Latency作为另一个优化目标。
二、方法
整体的方案如下图所示,主要包括网络结构搜索和图引导模块。具体的,网络由一系列相互独立的Cell堆叠而成,并在每两个相邻的Cell间用一个图引导模块 (GGM) 进行引导,达到信息传播的目的。
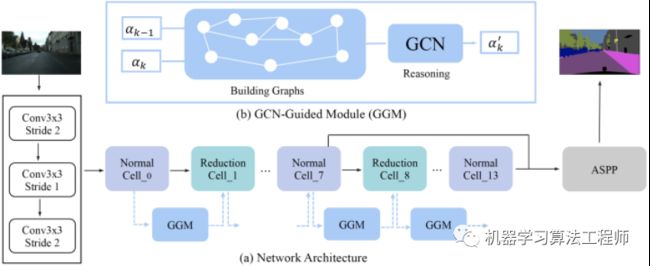
于此同时,在搜索的过程中,我们将 Latency 纳入考虑,整个搜索问题可以用公式(1)进行表示:
(1)
其中, 代表整个搜索空间, 和 分别是验证集的分割损失和Latency损失,搜索的目的是找到一个在精度和Latency间有最佳权衡的网络结构。
2.1 网络结构搜索
不同于SNAS,为了能够更灵活的在精度和速度之间做权衡,我们使用了更细粒度的Cell结构,即每个Cell只有两个中间节点(区别于SNAS每个Cell的四个中间节点)。这样,通过更细粒度的Cell,搜索方案能够根据实际的速度需求在多个Cell间进行更灵活、更微妙的适配。
具体的,Cell结构如下图所示,每个Cell是一个有向图(DAG),包含有两个输入节点 i1和i2,两个中间节点 x1 和 x2,输出中间节点的concat结果。在DAG中,节点代表潜在的表征,即Feature Map,边代表可选的operation,如Conv,Pooling等。每个中间节点都会接收它的所有前继的节点作为输入,这样 x1节点的输入为 ,而x2节点的输入则为 .
那么,中间节点的计算方式如公式(2)所示,其中 是边(h,i)搜索到的最终operation结果。
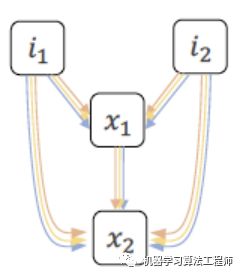 Cell结构
Cell结构
(2)
在搜索过程中,整个搜索空间由一个one-hot的向量集合进行表征,其采样自联合分布p(Z)1。具体的,边 (h, i) 会关联一个one-hot 向量 , 该向量会作为一个mask乘到该边上的所有候选的operations 上. 这样,中间节点在搜索过程中的计算方式如公式 (3).
(3)
利用重参数方法2可以让离散的结构参数变连续,从而让p(Z)可导,具体如公式(4)所示:
(4)
是边 (h,i) 的架构参数, 是随机的Gumbel变量,Uh,i是一个均匀分布变量, 则控制softmax的Temperature。
在operation的搜索过程中,整个搜索空间由一个one-hot的向量集合进行表征,其采样自联合分布$p(Z)$[1]。利用重参数方法[2]可以让离散的结构参数变连续。
我们使用了如下8种类型的operation进行搜索:
3x3 max pooling, 3x3 conv, 3x3 separable conv
3x3 dilated separable conv (dilation=2)
3x3 dilated separable conv (dilation=4)
3x3 dilated separable conv (dilation=8)
skip connection, zero operation
2.2 图引导模块
如前所述,每两个相邻的Cell中会有一个图卷积网络作为交流机制,而后通过图卷积操作进行图例,从而将上一个Cell的信息传播到当前的Cell。在实验中,我们利用相邻Cell中边的相似性来构建推理图,这样,上一个Cell状态的改变就能通过图推理将信息传播至当前的Cell。用 表征第k个Cell的架构参数,其是一个 pxq的矩阵,p是Cell中边个数,q等于候选operations的数目,以此类推, 也是一个pxq的矩阵,我们采用式(5)对当前Cell状态的进行更新: (5)
其中, G代表改推理图,Adj代表该推理图的邻接矩阵, 和 则代表两个1D Convolution转换。 我们利用边的相似性关系来构建推理图 G的邻接矩阵,给定第 k-1个 Cell 和 第 k个 Cell,通过公式(6)计算推理图的邻接矩阵,结果是一个 pxp矩阵:
(6)
其中, , 代表两个类似的映射,参数 和 都是qxq大小,并且可以通过反向传播进行学习更新。基于上述的邻接矩阵,推理图的信息传播按照式(7)进行,其中, 代表推理图的参数, 实验中该参数维度设置为64, 则代表残差连接。 (7)
三、实验
3.1 图引导模块消融实验
为验证图引导模型的作用,我们Cityscape数据集上进行实验,具体的配置为: a) 传统的Cell 共享方式;b) Cell 独立的方式;c) Cell 独立,但采用Fully Connected 作为信息交流机制;d) Cell独立,但采用图卷积网络作为交流机制。实验结果汇总在下图中,可以发现,直接让Cell独立,不加入任何的交流机制,精度从 68.5% 降低 66.9% 。为了消除这个影响,我们探索了Fully Connected (在相邻Cell间加入FC)和图引导两种方式,实验发现,相比于FC,利用图引导模块能够极大的提升模型的精度,同时搜索到的网络也具有更小的Param Size,仅2.18M。 图引导模块,紫色线表示多次实验的方差,坐标轴之下的数字表示模型的Param Size
图引导模块,紫色线表示多次实验的方差,坐标轴之下的数字表示模型的Param Size
我们也对比了GAS和随机采样方法,实验对随机采样设置两种配置,a) 完全随机采样,b) 在随机采样的过程中选出速度符合108FPS左右的网络,对比结果如表(1)所示,可见,我们的方法在速度和精度上达到了一个很好的权衡,进一步体现了我们方法的优势。 表1 GAS和随机采样对比
表1 GAS和随机采样对比
3.2 GAS性能
为了验证所提出的GAS方法的优越性,作者在Cityscapes分割数据集进行了实验,并在该数据集上获得了新的SOTA结果。作者和现有最优秀的几种小型网络结构作对比,包括BiSeNet、DFANet、CAS等,结果汇总在表2中,这些模型都包含了mIoU和FPS,其中,FPS是在Titan XP GPU上的测试结果。从结果中我们可以看到,和之前的SOTA方法相比,GAS能够在维持相同速度下,精度有1.3 - 3个点的提升。
 表2 各方法在Cityscapes数据集上的比较结果
表2 各方法在Cityscapes数据集上的比较结果
3.3 图引导模块作用分析
如前所述,图引导模块在搜索过程中扮演了重要的角色,我们猜想其主要来源于如下几个方面:
为了搜索实时的语义分割网络,我们打破了Cell共享方式,而这种方式加大了优化的难度从而无法保证精度,这种情况下,加入的图引导模块可以被认为是一个正则化项,引导整个搜索的过程;
正如2.1节所示, 是一个fully factorizable joint distribution。对于公式(4),如果当前Cell的架构参数依赖于上一个Cell的架构参数, 将会变成一个条件分布,在这种情况下,图引导模型建模了该条件;
图引导模块其实产生了Attention的效果,如公式(8)所示为Non-local Network的转换方式 (f表示相似关系),其和式(5)的转换是一致的,因此,在图引导模块的作用下,当前Cell相当于能够更有效的提取上一个Cell的有用信息。(8) 因此,图引导模块在搜索的过程中其实扮演着很重要的角色。
参考文献:
1 Sirui Xie, Hehui Zheng, Chunxiao Liu, and Liang Lin.SNAS: stochastic neural architecture search. In ICLR, 2019.
2 Chris J Maddison, Andriy Mnih, and Yee Whye Teh. Theconcrete distribution: A continuous relaxation of discreterandom variables.arXiv:1611.00712, 2016.
3 Peiwen Lin, Peng Sun, Guangliang Cheng, Sirui Xie, Xi Li, Jianping Shi.Graph-guided Architecture Search for Real-time Semantic Segmentation.arXiv:1909.06793, 2019
作者:林培文*,孙鹏*,程光亮,谢思锐,李玺,石建萍
(* means equal contribution)
论文地址:https://arxiv.org/abs/1909.06793
之后代码将会开源:
https://github.com/L-Lighter/LightNet
编辑:Lujohn3li
机器学习算法工程师
????投稿请扫描下方二维码