PL/SQL
文章目录
- 一、plsql结构:
- 二、数据类型及变量
- 1.数字类型
- 2.字符串类型
- 3.日期类型
- 4.布尔类型
- 5.%type类型:
- 6.record类型:
- 7.%rowtype类型:
- 8.其他类型
- 9.命名规则:
- 三、变量及常量:
- 1.变量
- 2.常量:
- 四、流程控制语句
- 1.if语句:
- 2.if else语句:
- 3.elsif语句:
- 4.case when语句:
- 5.loop循环:
- 6.while循环:
- 7.for循环:
- 8.goto循环:
- 9.退出循环:
- 五、其他语句:
- 1.select into语句:
- 2.execute immediate语句:
- 3.bulk collect语句
- 4.forall批量绑定
- 六、游标
- 1.定义:
- 2.属性:
- 3.游标的声明:
- 4.游标的使用:
- 5.隐式游标:
- 6.游标传参:
- 7.游标类型:
- 七、集合
- 1.定义
- 2.属性及方法:
- 3.索引表
- 4.嵌套表
- 5.变长数组
- 6.bulk collect
- 7.批量绑定
- 八、异常
- 1.定义
- 2.分类
- 3.抛出异常
- 4.异常捕获
- 5.异常变量
- 6.异常绑定
- 异常预编译
- 异常映射
- 九、文件
- 1.打开方式
- 2.创建目录及文件变量
- 3.文件编辑
- 十、存储过程
- 1.介绍:
- 2.语法:
- 3.存储过程的调用
- 4.传参
- ①in参数
- ②out参数
- ③in out参数
- 5.应用
- 十一、函数
- 1.介绍
- 2.语法
- 3.应用
- 十二、触发器
- 1.介绍
- 2.表级触发器
- 3.行级触发器
- 4.替换触发器
- 十三、包
- 1.介绍
- 2.包的声明
- 3.定义包体
一、plsql结构:
DECLARE(声明部分):
主要包括常量、变量、游标变量、集合变量、异常变量、文件变量等的声明
begin
Plsql
Exception(异常处理)
End
二、数据类型及变量
1.数字类型
①number(p,s):
可存放各种数字类型数据
②pls_integer,binary_integer:
只能存放整数
2.字符串类型
①varchar2():变长
②Char():定长
3.日期类型
data:日期类型
timestamp:时间戳可以精确到纳秒
4.布尔类型
boolean:只有两个值true和false
5.%type类型:
%type:取数据库表中某一字段的类型作为变量类型
语法:表名.列名%type;例如:emp.ename%type
6.record类型:
记录类型可存放一组值,使用前需定义
语法:
1.先声明:变量名 记录类型
2.type 变量名 is record(
ename vachar2(10),
job emp.job%type,
sal emp.sal%type);
3.赋予值:变量名.属性名:=’值’;
7.%rowtype类型:
是%type类型和record类型的结合
语法:表名%rowtype
例如:dept%rowtype
v_dept dept%rowtype;
相当于:
type dept_type is record(
deptno dept.deptno%type,
dname dept.dname%type,
loc dept.loc%type);
v_dept dept_type;
8.其他类型
- 集合类型
- 索引表:
type 类型名 is table of 存储数据的数据类型 index by 下标的数据类型(varchar2,pls_integer,binary_integer) - 嵌套表:
type 类型名 is table of 存储数据的数据类型; - 变长数组:
type 类型名 is varray(初始长度) of 存储数据的数据类型;
- 索引表:
- 游标类型
type 类型名 is ref cursor;
9.命名规则:
①以字母开头,不能以数字开头可包含数字,#,$
②特殊字符用双引号括起来,不能超过30个英文字母长度
三、变量及常量:
1.变量
语法:变量名 数据类型[not null] [:=默认值]
:=在plsql中是赋值语句
V_N number (10):=1;
2.常量:
存储一个数据,一旦赋值不可改变
语法:常量名 constant 数据类型:=默认值;默认值必须存在
四、流程控制语句
1.if语句:
语法:
if 条件表达式 then plsql 语句;
end if;
2.if else语句:
语法:
if 条件表达式 then plsql语句;
else plsql语句;
end if;
3.elsif语句:
语法:
If 条件表达式1 then
plsql语句1;
elsif 条件表达式2 then
plsql 语句2;
else
plsql 语句n;
end if ;
4.case when语句:
语法:
case
when 条件表达式1 then
值1/plsql语句1;
when 条件表达式2 then
值2/plsql 语句2;
else(可以省略)
默认值/plsql语句;
end case;
5.loop循环:
语法:
Loop
Plsql语句;
Exit when 退出循环条件;
循环控制语句;
End loop;
6.while循环:
语法:
While 循环条件 loop
循环体语句;
循环控制语句;
End loop;
7.for循环:
语法:
For 循环变量 in [reverse] 集合|查询语句|游标变量 loop
循环体语句;
End loop;
注意:循环变量:不需要在declare中声名,变量类型,根据in后面的集合或者查询语句而定,普通数据类型,record类型
reverse:可选参数,表示循环的方向,不加表示从开始到结尾,加上表示从结尾到开头 。
8.goto循环:
语法:
<>
循环执行的plsql语句;
if 条件 then
goto lable;
end if;
其中
<<>>:标签定义符
lable:标签名,符合标识符命名规范
9.退出循环:
Exit when :当条件成立时退出循环
Continue:退出本次循环
Return:退出循环并结束程序
五、其他语句:
1.select into语句:
语法: select 列名 into 变量1|record变量|rowtype变量 from 表名 where 条件;
注意:select into语句查询出的结果只能是一条数据,超过一条数据会报错;
2.execute immediate语句:
execute immediate可以执行所有的数据库语句(sql语句,plsql代码,ddl语句)
execute immediate sql语句(字符串,可以是字符串变量) [into 变量,…] [using 变量或者值,…];
sql语句:sql语句可以使用占位符,占位符以冒号开头,如果sql语句使用了占位符,那么必须使用using子句给sql语句传值
应用1:
–执行update、insert、delete语句
declare
--声名一个变量保存sql语句
v_sql varchar2(255);
begin
--给dept表插入一条数据
v_sql:='insert into dept(deptno,dname,loc) values(:1,:2,:3)';
execute immediate v_sql using 11,'oracle','qd';
--修改dept表中的数据
v_sql:='update dept set loc=:1 where deptno=:2';
execute immediate v_sql using 'qingdao',11;
--删除dept表中的数据
v_sql:='delete from dept where deptno=:1';
execute immediate v_sql using 11;
end;
应用2:
–使用execute immediate创建一张表c
declare
--声名一个变量保存sql语句
v_sql varchar2(255);
begin
v_sql:='create table c(id number(11),name varchar2(30))';
execute immediate v_sql;
end;
plsql中直接写sql和使用execute immediate的区别:
①直接写sql时,表名不能使用变量的值
execute immediate:可以使用变量里保存的表名
②如果数据库中没有表,那么写sql语句在创建存储过程或者函数时,会直接报错
而execute immediate:中执行的sql语句中的涉及的表可以是数据库中没有的
3.bulk collect语句
可以加在所有有into的语句中,加上之后可以查出多条结果
select .. bulk collect into 集合变量;
execute immediate .. bulk collect into 集合变量;
fetch .. bulk collect into 集合变量;
4.forall批量绑定
forall 变量 in 集合
sql语句
注意:forall中没有loop
六、游标
1.定义:
游标是oracle在执行sql语句时,为这个sql语句分配一个缓冲区,里边存放了sql语句的执行结果,游标是指向这个缓冲区的地址,通过游标可以操作sql的处理结果
2.属性:
①%found:如果游标当前指向的数据不为空时,返回true,否则返回false
②%notfound:和%found相反
%isopen:判断当前游标是否打开,如果游标是打开的返回true,否则返回false
③%rowcount:返回游标指向的结果集的数据条数,当遍历游标时,可以表示当前处理数据的行号
另外:
游标属性的使用:游标%属性名
3.游标的声明:
cursor 游标名称 is select语句;
4.游标的使用:
1.打开游标
open 游标名称;
2.执行fetch into语句将游标指向的一条记录保存到变量中
fetch 游标名称 into 变量;
3.关闭游标
close 游标名称;
利用loop循环遍历游标:
declare
--声名一个游标
cursor cur is select ename from emp;
--声名一个变量,保存游标的一条记录
v_name varchar2(30);
begin
--打开游标
open cur;
--loop循环遍历游标
loop
--执行fetch into语句,将游标指向的记录保存到变量中
fetch cur into v_name;
--判断游标是否为空
exit when cur%notfound;
--打印变量
dbms_output.put_line(v_name);
end loop;
--关闭游标
close cur;
end;
5.隐式游标:
游标分为显式游标和隐式游标,前者想要自己声明,后者是oracle在执行update、delete、insert语句时,oracle自动给分配的一个游标,游标的名称:sql其属性:sql%found、sql%rowcount
declare
begin
--删除除10号部门的所有员工
delete from emp where deptno=10;
--打印删除的数据条数
dbms_output.put_line(sql%rowcount);
end;
6.游标传参:
1.传值
2.传变量(会将变量值传给游标形参)
3.按位传值 形参名=>值
根据传入的部门编号,查询该部门下的所有员工
declare
--声名一个带参数的游标
cursor cur(dno number default 10) is select * from emp where deptno=dno;
--声名一个变量保存游标中的一条记录
v emp%rowtype;
begin
--打开游标
--1.按值传参
open cur(20);
--遍历
loop
--将游标的值放入变量v中
fetch cur into v;
--判断游标是否为空
exit when cur%notfound;
--打印员工信息
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end loop;
--关闭游标
close cur;
end;
declare
--声名一个带参数的游标
cursor cur(dno number default 10) is select * from emp where deptno=dno;
--声名一个变量保存游标中的一条记录
v emp%rowtype;
--声名一个number类型变量,接收从键盘输入的一个部门编号
deptno number(10):=&deptno;
begin
--打开游标
--2传变量
open cur(deptno);
--遍历
loop
--将游标的值放入变量v中
fetch cur into v;
--判断游标是否为空
exit when cur%notfound;
--打印员工信息
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end loop;
--关闭游标
close cur;
end;
declare
--声名一个带参数的游标
cursor cur(dno number default 10) is select * from emp where deptno=dno;
--声名一个变量保存游标中的一条记录
v emp%rowtype;
begin
--打开游标
--3.按位传参
open cur(dno=>20);
--遍历
loop
--将游标的值放入变量v中
fetch cur into v;
--判断游标是否为空
exit when cur%notfound;
--打印员工信息
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end loop;
--关闭游标
close cur;
end;
7.游标类型:
游标类型的定义:
type 类型名称 is ref cursor;
游标变量的声名:
变量名 类型名;
游标变量的使用:
1.打开游标
open 游标变量 for select语句;
2.遍历游标
fetch 游标变量名 into 变量
3.关闭游标
close 游标变量
注意:
游标变量不能使用for循环遍历
declare
--声名一个游标类型
type ctype is ref cursor;
--声名一个游标变量
cur ctype;
--声名一个变量保存dept表中的一条记录
v_dept dept%rowtype;
--声名一个变量保存emp表中的一条记录
v emp%rowtype;
begin
--让游标指向dept,打印所有部门信息
--打开游标
open cur for select * from dept;
--遍历游标
loop
--将游标当前值保存到变量中
fetch cur into v_dept;
--判断游标是否为空
exit when cur%notfound;
--打印部门信息
dbms_output.put_line(v_dept.deptno||','||v_dept.dname||','||v_dept.loc);
end loop;
--关闭
close cur;
dbms_output.put_line('==========================================================');
--让游标变量指向emp表
open cur for select * from emp;
loop
fetch cur into v;
exit when cur%notfound;
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end loop;
--关闭游标
close cur;
end;
通过游标类型声名的游标变量,可以在程序中动态地指定游标变量指向的结果集;
查询打印部门信息,并打印它下面的员工信息
declare
--声名一个游标
cursor c1 is select * from dept;
--声名一个游标
cursor c2(dno number) is select * from emp where deptno=dno;
--声名两个变量分别用来保存c1和c2的一条记录
--声名一个变量保存dept表中的一条记录
v_dept dept%rowtype;
--声名一个变量保存emp表中的一条记录
v emp%rowtype;
begin
--打开游标c1
open c1;
--遍历c1
loop
--将c1的一条记录保存到变量v_dept中
fetch c1 into v_dept;
--判断游标是否为空
exit when c1%notfound;
--打印v_dept
dbms_output.put_line(v_dept.deptno||','||v_dept.dname||','||v_dept.loc||':');
--打开游标c2
open c2(v_dept.deptno);
loop
fetch c2 into v;
exit when c2%notfound;
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end loop;
--关闭游标c2
close c2;
dbms_output.put_line('=============================');
end loop;
--关闭游标c1
close c1;
end;
七、集合
1.定义
集合:是oracle中一种数据类型,用来存放一组数据类型相同的数据,数据类型可以是任何数据类型(数字、字符串、日期、记录类型、集合类型)
①索引表:存放一组数据类型相同的数据,包含下标和值,下标可以是字符串类型,也可以是数字类型, 索引表只能在plsql代码中使用。
②嵌套表:存放一组数据类型相同的数据,它的下标只能是整数类型(pls_integer,binary_integer)嵌套表可以在plsql中使用,也可以在数据库中使用
③变长数组: 它的下标也是数字类型的,它可以指定默认长度(存放数据的个数),它的长度是可变。
2.属性及方法:
first:取集合第一个元素的下标
last:取集合最后一个元素的下标
count:取集合中存放的元素个数
limit:取集合能存放的数据个数
next(下标):取当前下标的下一个元素的下标
prior(下标):取当前下标的上一个元素的下标
extend(n,index):表示将集合扩展n个元素,index表示集合已有元素的下标,如果有第二个参数,表示扩展集合n个元素并且扩展后的对应值是index这个下标所对应的值
delete(n):删除集合中的元素
3.索引表
定义索引表类型语法:
type 类型名 is table of 存放的数据的类型 index by 下标的数据类型;
声名索引表变量:
变量名 类型名;
declare
--声名一个索引表类型
type ind is table of varchar2(30) index by varchar2(11);
--声名一个索引表变量
v_ind ind;
--声名一个变量保存索引表的下标;
i varchar2(11);
begin
--给索引表赋值
v_ind('a'):='张三';
v_ind('b'):='李四';
v_ind('c'):='王五';
dbms_output.put_line(v_ind('c'));
--取索引表第一个元素的下标
dbms_output.put_line(v_ind.first);
--取索引表最后一个元素的下标
dbms_output.put_line(v_ind.last);
--遍历索引表,逐个访问索引表中的值
--将索引表的第一个元素的下标放入i中
i:=v_ind.first;
loop
dbms_output.put_line(v_ind(i));
exit when i=v_ind.last;
--循环控制语句
i:=v_ind.next(i);
end loop;
end;
4.嵌套表
定义嵌套表类型:
type 类型名 is table of 存放数据的数据类型;
变量的声名:
变量 类型名;
使用:
1.初始化嵌套表变量
变量名:=嵌套表类型名(); --初始化一个空的嵌套表
变量名:=嵌套表类型名(值,值,…值);–初始化一个嵌套表变量,并给它赋初始值,(初始值的下标是从1开始连续的自然数)
2.初始完之后要添加值时,先要使用extend进行扩展
declare
--声名一个嵌套表类型
type tab is table of number(10);
--声名一个嵌套表变量
t tab;
t2 tab;
begin
--初始化一个空的嵌套表变量
t:=tab();
--扩展嵌套表,将嵌套表扩展1个长度
t.extend(1);
t(1):=1;
dbms_output.put_line(t.count);
t.extend(10,1);--将嵌套表扩展10个元素,并且扩展的元素的值是下标为1的元素值
--遍历嵌套表
for i in t.first..t.last loop
dbms_output.put_line(t(i));
end loop;
dbms_output.put_line(t.count);
--初始化一个非空嵌套表变量
t2:=tab(1,2,3,4,5);
--遍历嵌套表t2
for i in t2.first..t2.last loop
dbms_output.put_line(t2(i));
end loop;
--替换已有下标的元素值
t2(1):=100;
--遍历嵌套表t2
for i in t2.first..t2.last loop
dbms_output.put_line(t2(i));
end loop;
end;
嵌套表在数据库中使用(当作一种数据类型来使用,可以用在建表语句中)
语法:create type 嵌套表类型 is table of 存储的数据的数据类型;
--在数据库中创建一个能存储30个字符的嵌套表类型
create type tabType is table of varchar2(30);
--建表语句
create table tab(
id number(11) primary key,
create_time date,
--在建表时声明namelist列为嵌套表类型
namelist tabType
)nested table namelist store as names;
--插入数据
insert into tab(id,create_time,namelist) values(1,sysdate,tabType('smith','john','lucy'));
--查看嵌套表内容
select * from table(select namelist from tab);
--子查询只能有一条结果,也就是说如果该表中有两列是嵌套表类型则只能查询其中一个嵌套表必须使用where筛选where id=1
5.变长数组
变长数组:下标是数字类型,定义时可以设置数组的默认长度,使用前同样要初始化。
定义变长数组类型语法:
type 数据类型 is varray|varry array(数组默认长度) of 存放的数据的数据类型;
变量的声名:
变量名 类型名;
使用前要初始化:变量名:=变长数组类型名([值,…值]);
declare
--定义一个变长数组类型
type arrtype is varray(10) of varchar2(30);
--声名一个变量
arr arrtype;
begin
--初始化变长数组
arr:=arrtype();
arr.extend(7);
--赋值
arr(2):='张三';
arr(3):='李四';
dbms_output.put_line(arr.count);
dbms_output.put_line(arr.limit);
end;
数据库中的使用:
create type 类型名 is varray(默认长度) of 存储的数据的数据类型;
--创建一个变长数组类型
create type arrtype is varray(10) of varchar2(30);
--变长数组类型在数据库中的使用和普通类型一样
--创建表
create table arr(
id number(11) primary key,
create_time date,
--定义namelist列为变长数组列
namelist arrtype
);
--插入数据
insert into arr(id,create_time,namelist) values(1,sysdate,arrtype('张三','李四','王五'));
--查看arr表中变长数组列
select * from table(select namelist from arr where id=1);
6.bulk collect
select … bulk collect into 集合变量;
–可以查出多条记录,集合变量如果是嵌套表或者变长数组时(不能初始化);
declare
--声名一个嵌套表类型
type ttype is table of emp%rowtype;
--声名一个变量
tab ttype;
begin
--根据输入的部门编号,查出部门下所有员工的姓名和工作
select * bulk collect into tab from emp where deptno=&deptno;
--遍历集合打印员工姓名
for i in tab.first..tab.last loop
dbms_output.put_line(tab(i).ename||','||tab(i).job||','||tab(i).sal);
end loop;
end;
7.批量绑定
forall
declare
--声明一个嵌套表类型
type ttype is table of number(10);
--声明一个嵌套表类型的变量
empno_list ttype;
begin
--输入一个部门编号并将所有该部门的员工编号保存到嵌套表变量empno_list中
select empno bulk collect into empno_list from emp where deptno=&deptno;
--将嵌套表变量empno_list中全部数据取出并绑定执行下面代码
forall i in empno_list.first..empno_list.last
--批量删除
delete from emp where empno=empno_list(i);
end;
八、异常
1.定义
异常:它是oracle在运行过程中,出现的一些错误,包括代码错误、软件错误、硬件、网络等异常信息。
2.分类
异常分为oracle内置异常和自定义异常
(1)内置异常
Oracle根据程序可能报错的情况定义的一类异常,常见的Oracle
①预定义异常如下:
ACCESS_INTO_NULL:ORA-06530 为了引用对象属性,必须首先初始化对象。直接引用未初始化的对象属性时,会发生异常
CASE_NOT_FOUND:ORA-06592 当CASE语句的WHEN子句没有包含必须条件分支或者ELSE子句时,会触发
LOGIN_DENIED:ORA-01017 连接Oracle数据库时,如果提供了不正解的用户名和口令时会触发
NO_DATA_FOUND:ORA-01403 执行SELECT INTO 未返回行或者引用了未初始化的PL/SQL表元素时会触发
NOT_LOGGED_ON:ORA-01012 没有连接数据库执行SQL时会触发
TIMEOUT_ON_RESOURCE:ORA-00051 当等待资源时如果出现超时会触发
TOO_MANY_ROWS:ORA-01422 当执行SELECT INTO时,如果返回超过一行、会触发
ZERO_DIVIDE:ORA-01476 如果用数字值除0,会触发
②非预定义异常:有oracle公司预先定义好错误编码(ORA-XXXXX),但是没有错误描述(需要用户在程序中自己定义)的常见SQL和PL/SQL错误。由用户在程序中显示定义,但由SQL自动触发(在条件被满足的时候)。
(2)自定义异常
自定义异常编码范围:-20000~-20999(20000以下的一般已由Oracle内部定义)另外,每一个错误描述的长度,最大长度均为512个字节。
declare
声名部分;
begin
代码;
exception
异常处理代码;
end;
declare
--自定义一个异常
myexc exception;
begin
--抛出一个异常
raise myexc;
exception
when myexc then
dbms_output.put_line('自定义异常');
end;
3.抛出异常
当数据库或PL/SQL在运行时发生错误时,一个异常被PL/SQL运行时引擎自动抛出。
①异常也可以通过RAISE语句抛出
RAISE exception_name;
比如下面一个订单输入的例子,若当库存数量小于订单,则抛出异常,并且捕获该异常,处理异常
DECLARE
--定义一个inventory_too_low异常
inventory_too_low EXCEPTION;
BEGIN
--如果订单大于库存
IF order_rec.qty>inventory_rec.qty THEN
--抛出异常
RAISE inventory_too_low;
END IF
--异常处理
EXCEPTION
WHEN inventory_too_low THEN
order_rec.staus:='backordered';
②另外一种抛出异常的方式:
dbms_standard.raise_application_error(异常编码,异常信息,boolean) --boolean表示异常抛出时是否覆盖系统内置异常,一般默认(false)
这种方式抛出的异常,可以定义异常显示的错误信息
4.异常捕获
一般异常捕获后用于异常处理
--捕获异常
exception
when 异常名称 then
异常处理代码;
....
when others then
异常处理代码;
--使用others可以捕获到任何异常
5.异常变量
①sqlcode:它获取异常码 100:表示没有找到数据 正数:表示系统内置异常 负数:自定义异常
②sqlerrm:获取到异常的信息
declare
begin
--抛出一个异常-200001,异常描述为“程序异常”
dbms_standard.raise_application_error(-20001,'程序异常');
--捕获异常
exception
when others then
--打印异常代码
dbms_output.put_line(sqlcode);
--打印异常内容
dbms_output.put_line(sqlerrm);
end;
运行结果:
-20001
ORA-20001: 程序异常
6.异常绑定
pragma exception_init(自定异常名称,异常编码);
它可以给没有名字的异常加上一个自定义的异常名称,可以使用自定义异常对该异常进行捕获
declare
--自定义一个异常
myexc exception;
--异常绑定
pragma exception_init(myexc,-00001);
begin
insert into dept values(10,'ss','qq');
exception
when myexc then
dbms_output.put_line(sqlerrm);
end;
代码运行结果:
ORA-00001: 违反唯一约束条件 (SCOTT.PK_DEPT)
异常预编译
PRAGMA EXCEPTION_INIT(locally_declared_exception, error_code);
--使用PRAGMA预编译指令映射错误代码
DECLARE
lv_a VARCHAR2(20);
invalid_userenv_parameter EXCEPTION;
PRAGMA EXCEPTION_INIT(invalid_userenv_parameter,-2003);
BEGIN
lv_a := SYS_CONTEXT('USERENV','PROXY_PUSHER');
EXCEPTION
WHEN invalid_userenv_parameter THEN
dbms_output.put_line(SQLERRM);
END;
异常映射
DECLARE
e EXCEPTION;
--将局部异常映射至用户自定义错误代码
PRAGMA EXCEPTION_INIT(e,-20001);
BEGIN
RAISE e;
EXCEPTION
WHEN e THEN
dbms_output.put_line(SQLERRM);
END;
九、文件
1.打开方式
r:只读模式
w: 写模式
a: 追加模式
可以配合使用
2.创建目录及文件变量
- 使用文件时首先需要创建一个目录来存放文件,如果目录存在则不用创建
create directory 目录名 as ‘路径’; - 声明一个文件变量f
f utl_file.file_type 文件类型
3.文件编辑
utl_file.fopen(目录名称(字符串类型),文件名称,打开方式)
utl_file.get_line(文件变量名,字符串变量):将当前文件中的一条记录读取到变量中
utl_file.put_line(文件变量,数据(可以值,变量)):将数据写入文件中(按行写)
utl_file.fclose(文件变量):关闭文件
declare
--声名一个文件变量
f utl_file.file_type;
begin
--打开文件
f:=utl_file.fopen('FILEPATH','a.txt','w');
--给文件写内容
utl_file.put_line(f,'Hello World');
utl_file.put_line(f,'Good Morning');
utl_file.put_line(f,'Goodbye');
--关闭文件
utl_file.fclose(f);
end;
declare
--声名一个文件变量
f utl_file.file_type;
--声名一个变量保存文件的一行记录
str varchar(30);
begin
--打开文件
f:=utl_file.fopen('FILEPATH','a.txt','r');
loop
begin
--读取文件内容
utl_file.get_line(f,str);
--打印文件内容,也就是str的值
dbms_output.put_line(str);
exception
when no_data_found then
exit;
end;
end loop;
--关闭文件
utl_file.fclose(f);
end;
十、存储过程
1.介绍:
存储过程:它是一个有名字的plsql代码块,它是保存到数据库中的,数据启动时会加载到内存中,一般用来实现某个业务或功能。存储过程没有返回值,而函数有返回值。
2.语法:
创建存储过程语法:
create procedure 存储过程名[(形式参数 in|out|in out 参数数据类型,...)]
is|as
声名部分;
begin
plsql代码;
exception
异常处理代码;
end;
3.存储过程的调用
1.首先我们定义一个简单的存储过程p1
--定义一个简单的存储过程,打印九九乘法表
create procedure p1
is
begin
for i in 1..9 loop
for j in 1..i loop
dbms_output.put(i||'*'||j||'='||i*j||' ');
end loop;
dbms_output.put_line('');
end loop;
end;
2.存储过程P1定义之后就会一直保存在内存中,随时可以调用
1.在plsql代码块中调用
begin
p1();--如果存储过程定义了形参那括号里面就添加形参的值
end;
2.call命令调用(sqlplus,sql命令)
call p1();
3.exec命令调用(sqlplus命令)
exec p1();
4.传参
in:输入参数,它可以传值,传变量,按位传值,传入参数是只读的(不可以修改)
out:输出参数,它只能传变量,变量的值在存储过程中可以改变,可以在存储过程外使用存储过程修改后的值
in out:输入输出参数,它有in和out的特点,只能传变量
①in参数
--写一个存储过程,输入一个部门编号,打印部门下的所有员工信息
create or replace procedure p2(dno in number)
is
--声名一个集合类型
type indtype is table of emp%rowtype index by pls_integer;
--声名一个集合变量
emplist indtype;
begin
--输入参数不可以修改
--dno:=20; 不允许的
select * bulk collect into emplist from emp where deptno=dno;
for i in emplist.first..emplist.last loop
dbms_output.put_line(emplist(i).ename||','||emplist(i).job||','||emplist(i).sal||','||emplist(i).deptno);
end loop;
end;
调用代码:
begin
p2(20);
end;
②out参数
--写一个存储过程传入一个员工编号,查询这个员工的信息,并将查询结果传给外部调用程序
create or replace procedure p3(eno in emp.empno%type,v_emp out emp%rowtype)
is
begin
select * into v_emp from emp where empno=eno;
exception
when no_data_found then
dbms_output.put_line(sqlerrm);
end;
调用代码:
declare
v emp%rowtype;
begin
p3(7369,v);
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end;
③in out参数
--写一个存储过程传入一个员工编号,查询这个员工的信息,并将查询结果传给外部调用程序
create or replace procedure p4(v in out emp%rowtype)
is
begin
select * into v from emp where empno=v.empno;
exception
when no_data_found then
dbms_output.put_line(sqlerrm);
end;
调用代码:
declare
v emp%rowtype;
begin
v.empno:=7369;
p4(v);
if v.ename is not null then
dbms_output.put_line(v.empno||','||v.ename||','||v.job||','||v.sal||','||v.deptno);
end if;
end;
5.应用
写一个存储过程输入一个表名,打印这个表的所有列的列名:
--写一个存储过程输入一个表名,打印这个表的所有列的列名
CREATE OR REPLACE PROCEDURE P_COL_CAT(TNAME IN VARCHAR2) IS
BEGIN
FOR I IN (SELECT COLUMN_NAME
FROM USER_TAB_COLS
WHERE TABLE_NAME = UPPER(TNAME)) LOOP
DBMS_OUTPUT.PUT(I.COLUMN_NAME || CHR(10));
END LOOP;
DBMS_OUTPUT.NEW_LINE();
END;
调用代码:
CALL p_col_cat('emp');
结果如下:
EMPNO
ENAME
JOB
MGR
HIREDATE
SAL
COMM
DEPTNO
十一、函数
1.介绍
函数:它也是一个有名字的plsql代码块,它一般用来完成一种记录或功能,它保存在数据中,数据库启动时加载在内存中,函数可以用在sql语句中也可以在plsql代码块中调用,函数必须有一个返回值,调用时必须使用其返回值
2.语法
创建函数的语法:
create or replace function 函数名称[(形式参数 参数数据类型,...)]
return 返回值类型
is
声名部分;
begin
plsql代码;
return 值(返回值类型一致);
exception
异常处理;
end;
3.应用
1.用递归声明一个函数REC用来计算N的阶乘
CREATE OR REPLACE FUNCTION REC(N PLS_INTEGER) RETURN NUMBER IS
BEGIN
--如果输入一个小于1的数就返回1
IF N <= 1 THEN
RETURN 1;
ELSE
RETURN N * REC(N - 1);
END IF;
END;
利用for循环计算N的阶乘
create or replace function f1(n number)
return number
is
--声名一个变量
res number(10):=1;
begin
for i in 1..n loop
res:=res*i;
end loop;
return res;
end;
调用代码:
--计算4的阶乘
select f1(4) from dual;
2.利用递归定义一个函数用来生成斐波那契数列
CREATE OR REPLACE FUNCTION FIBO(N PLS_INTEGER) RETURN NUMBER IS
BEGIN
IF N <= 2 THEN
RETURN N;
ELSE
RETURN FIBO(N - 1) + FIBO(N - 2);
END IF;
END
调用代码:
--查看斐波那契数列前10个元素
BEGIN
FOR I IN 1 .. 10 LOOP
DBMS_OUTPUT.PUT(FIBO(I) || ' ');
END LOOP;
DBMS_OUTPUT.NEW_LINE();
END;
--输出结果:
1 2 3 5 8 13 21 34 55 89
3.编写查看用户表中列名的函数
CREATE OR REPLACE FUNCTION COL_CAT(TNAME IN VARCHAR2) RETURN VARCHAR2 IS
RES VARCHAR2(1000);
BEGIN
FOR I IN (SELECT COLUMN_NAME
FROM USER_TAB_COLS
WHERE TABLE_NAME = UPPER(TNAME)) LOOP
RES := RES || I.COLUMN_NAME || CHR(10);
END LOOP;
RES := SUBSTR(RES, 1, LENGTH(RES) - 1);
RETURN RES;
END;
调用代码:
SELECT COL_CAT('emp') FROM DUAL;
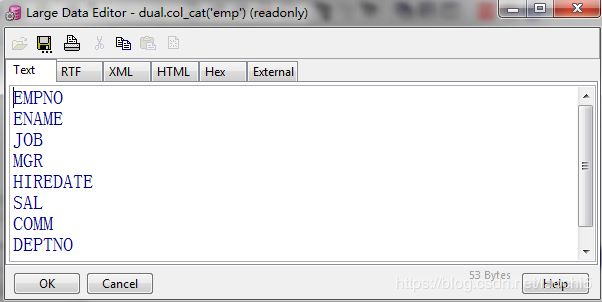
4.写一个函数传入一个数组变量,实现对这个数组的排序
- 首先先创建一个变长数组(集合)类型:
--在数据库创建一个数组类型
create type arrtype is varray(10) of number(10);
- 函数实现代码:
--定义一个函数输入和返回值类型都为arrtype
create or replace function f_rank(arr arrtype)
return arrtype
is
--定义一个返回值对象用于存储数组
v_arr arrtype;
--声名一个变量,用来做数据的交换
tep number(10);
begin
--初始化v_arr对象
v_arr:=arrtype();
--扩展它的长度和传入的数组变量的元素个数相同
v_arr.extend(arr.count);
--把传入的数组中的值复制到v_arr中
for i in arr.first..arr.last loop
v_arr(i):=arr(i);
end loop;
--对v_arr进行冒泡排序
for i in 1..v_arr.count-1 loop
for j in i+1..v_arr.count loop
if v_arr(i)>v_arr(j) then --交换数据
--将数组的值两两比较,较大的保存到变量tep中
tep:=v_arr(i);
--将小的数放入v_arr(i)中
v_arr(i):=v_arr(j);
--将保存的tep中原来v_arr(i)(较大)值放到v_arr(j)的位置
v_arr(j):=tep;
end if;
end loop;
end loop;
return v_arr;
end;
调用代码
declare
arr arrtype;
begin
--初始化
arr:=arrtype(14,53,12,34,25,192,11,512);
arr:=f_rank(arr);
for i in arr.first..arr.last loop
dbms_output.put_line(arr(i));
end loop;
end;
十二、触发器
1.介绍
触发器是在执行update、delete、insert语句时执行的一个plsql代码,它可以在sql执行前运行,sql执行后运行,也可以替换掉原有的sql语句。一个表或视图上,只能有一个触发器(在一个时间内只能有一个触发器生效)
行级触发器:当表中一条数据发生改变,就会执行一次触发器代码
语句级触发器(表级):当执行一条sql语句,不管sql语句改变了表中的多少条数据,只会执行一次触发器代码
2.表级触发器
创建语法:
create or replace trigger 触发器名 after|before update[ or delete or insert] on 表名
--创建一个触发器
create or replace trigger t1
--当dept表中数据改变时触发
before update or delete or insert on dept
begin
--当数据更新触发
if updating then
--打印update
dbms_output.put_line('update');
--当数据被删除时
elsif deleting then
--打印delete
dbms_output.put_line('delete');
--当插入新数据时(elsif insserting then)
else
--打印insert
dbms_output.put_line('insert');
end if;
end;
updating:布尔类型变量,如果是update语句它返回true,否则返回false
deleting:布尔类型变量,如果是delete语句它返回true,否则返回false
inserting:布尔类型变量,如果是insert语句它返回true,否则返回false
3.行级触发器
语法:
create or replace trigger 触发器名 after|before update[ or delete or insert] on 表名 for each row
--创建一个触发器
create or replace trigger t1
--当dept表中一条记录被插入时触发
after insert on dept for each row
begin
--打印
dbms_output.put_line(11111111);
end;
行级触发器中有两个变量(记录类型的变量):
:new 可以获取sql语句中传入的新值(数据修改后值)
:old 可以获取sql语句修改前表中存放的值
create or replace trigger t1
before update on dept for each row
begin
--打印修改前的数据
dbms_output.put_line('修改前的数据:'||:old.deptno||','||:old.dname||','||:old.loc);
--打印sql语句中要修改的值
dbms_output.put_line('修改后的数据:'||:new.deptno||','||:new.dname||','||:new.loc);
end;
4.替换触发器
替换触发器:它会替换掉原sql语句来执行触发器内部的代码,替换触发器只能使用在视图上,不能使用在表上
语法:
create or replace trigger 触发器名 instead of update [or delete or insert] on 视图名称 for each row
1.首先创建一个emp、dept表的视图
create view dept_emp as select t1.deptno dno,t1.dname,t1.loc,t2.* from dept t1,emp t2 where t1.deptno=t2.deptno;
2.替换触发器
向dept_emp这个视图中添加一条数据,如果添加的部门不存在,则插入一条新部门信息,如果部门存在修改原部门的信息;如果员工存在,修改员工信息,如果不存在插入一条新员工信息。
--创建一个触发器
create or replace trigger t2 instead of insert on dept_emp for each row
declare
n number(1);
--声名一个变量保存员工信息
v_emp emp%rowtype;
begin
--查询部门是否存在
select count(*) into n from dept where deptno=:new.dno;
if n=0 then
--n=0时,表示部门不存在,插入一条新部门信息
insert into dept values(:new.dno,:new.dname,:new.loc);
else
--n!=0时,表示部门存在,将部门信息修改为新部门信息
update dept set dname=:new.dname,loc=:new.loc where deptno=:new.dno;
end if;
begin
--查询员工信息
select * into v_emp from emp where empno=:new.empno;
--如果查出了信息,修改员工信息
update emp set ename=:new.ename,job=nvl(:new.job,:old.job),mgr=:new.mgr,hiredate=:new.hiredate,sal=:new.sal,comm=:new.comm,deptno=:new.dno where empno=:new.empno;
exception
when no_data_found then
--如果没有员工的信息,插入一条新员工信息
insert into emp values(:new.empno,:new.ename,:new.job,:new.mgr,:new.hiredate,:new.sal,:new.comm,:new.deptno);
end;
end;
3.当执行insert语句时就会触发上面的触发器,这条insert语句就不会执行,转而去执行触发器内部代码
insert into dept_emp values(11,'aa','bb',7999,'张三','job',7369,sysdate,4311,111,11);
十三、包
1.介绍
它是将一些功能或业务相似的函数、存储过程封装到一起,统一调用,包含存储过程、函数、变量、常量等对象。包分为声名部分和实现部分(包体),对外只提供包声名中包含的对象,即包中私有变量在包外无法调用。
2.包的声明
create or replace package 包名
is
–声名类型集合类型,记录类型、游标类型等
–声名变量
变量名 类型名
–声名常量
常量名 constant 类型名:=常量值;
–声名存储过程
procedure 存储过程名;
–声名函数
function 函数名 return 返回值类型;
end 包名;
包声名中的返回对象,都属于公有对象(可以使用,包名.对象名 来调用)
--声明一个包,PI、p1、f1都是公有对象,包外可以调用
create or replace package pk1
is
--声名一个常量
PI constant number(10,9):=3.1415926;
--声名一个存储过程
procedure p1;
--声名一个函数
function f1(r number) return number;
end pk1;
3.定义包体
--包体定义,包体定义必须在该包声明之后
create or replace package body pk1
is
--私有对象只能在包体的内容使用,而且一般定义在所有公有对象的前面
--声名私有变量(即包声明部分没有声明的变量)
--私有函数
function f2
return number
is
begin
return 1;
end;
--私有存储过程
procedure p2
is
begin
dbms_output.put_line('Hello World');
end;
--存储过程的实现
procedure p1
is
begin
p2(); --在包实现中调用的私有对象必须在当前对象的前面定义
for i in 1..9 loop
for j in 1..i loop
dbms_output.put(i||'*'||j||'='||i*j||' ');
if i*j<10 then
dbms_output.put(' ');
end if;
end loop;
dbms_output.put_line('');
end loop;
end;
--函数的实现
function f1(r number)
return number
is
res number(15,5);
begin
res:=power(r,2)*PI;
return res;
end;
end pk1;
调用代码
--调用包中常量PI
begin
dbms_output.put_line(pk1.PI);
end;
--调用包中存储过程p1
begin
pk1.p1;
end;
--调用包中函数f1
begin
dbms_output.put_line(pk1.f1(2));
end;
注意:包中私有对象p2和f2在包外部是不可调用的