一. Oozie简介
Apache Oozie是用于Hadoop平台的一种工作流调度引擎。
- 作用
统一调度hadoop系统中常见的mr任务启动hdfs操作、shell调度、hive操作等。
使得复杂的依赖关系时间触发事件触发使用xml语言进行表达开发效率提高。
一组任务使用一个DAG来表示,使用图形表达流程逻辑更加清晰。
支持很多种任务调度,能完成大部分hadoop任务处理。
程序定义支持EL常量和函数,表达更加丰富。
- 架构
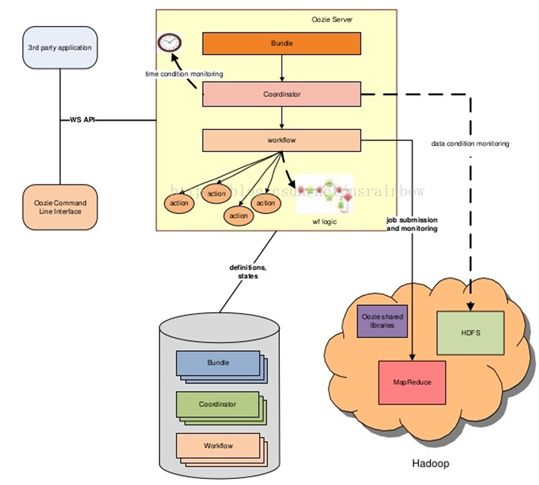
- 访问
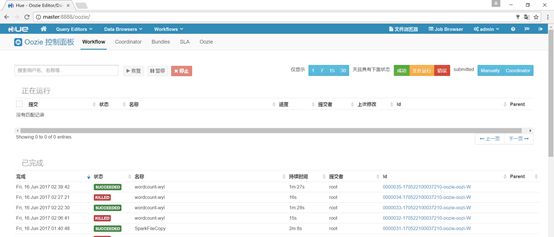
- 通过浏览器访问 http://master:11000/oozie/

- 通过HUE访问
- 概念
workflow:工作流
coordinator:多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后- 一个workflow的输入,也可以定义workflow的触发条件,来做定时触发
bundle:是对一堆coordinator的抽象
二. Oozie操作
- Oozie shell
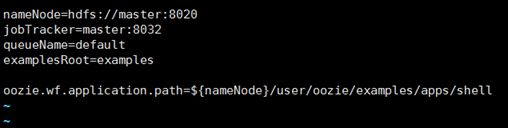
- 编写job.properties文件
- 编写workflow.xml文件
|
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
echo
my_output=Hello Oozie
${wf:actionData(‘shell-node‘)[‘my_output‘] eq ‘Hello Oozie‘}
Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
Incorrect output, expected [Hello Oozie] but was [${wf:actionData(‘shell-node‘)[‘my_output‘]}]
|
- 执行oozie cli命令
执行命令后会返回一个job的id,在web的监控页面或Hue的页面可以查看其信息。
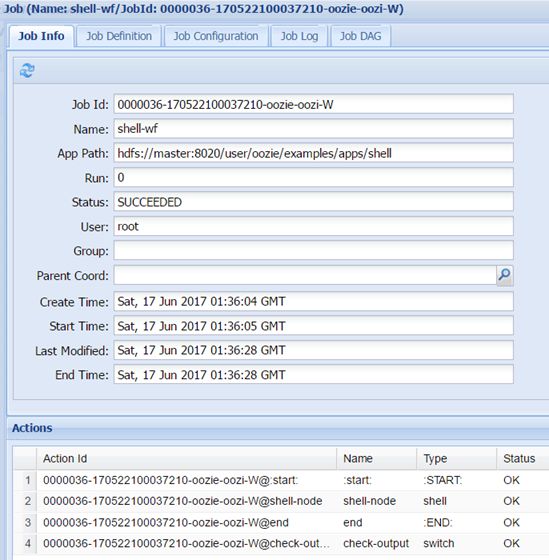
Job的有向无环图:

- Oozie fs
- 编写job.properties文件

- 编写workflow.xml文件
|
Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
|
- 执行oozie cli命令
- Oozie Sqoop
- 编写job.properties文件

- 编写配置文件
#HSQL Database Engine 1.8.0.5
#Tue Oct 05 11:20:19 SGT 2010
hsqldb.script_format=0
runtime.gc_interval=0
sql.enforce_strict_size=false
hsqldb.cache_size_scale=8
readonly=false
hsqldb.nio_data_file=true
hsqldb.cache_scale=14
version=1.8.0
hsqldb.default_table_type=memory
hsqldb.cache_file_scale=1
hsqldb.log_size=200
modified=no
hsqldb.cache_version=1.7.0
hsqldb.original_version=1.8.0
hsqldb.compatible_version=1.8.0
- 编写sql文件
CREATE SCHEMA PUBLIC AUTHORIZATION DBA
CREATE MEMORY TABLE TT(I INTEGER NOT NULL PRIMARY KEY,S VARCHAR(256))
CREATE USER SA PASSWORD ""
GRANT DBA TO SA
SET WRITE_DELAY 10
SET SCHEMA PUBLIC
INSERT INTO TT VALUES(1,‘a‘)
INSERT INTO TT VALUES(2,‘a‘)
INSERT INTO TT VALUES(3,‘a‘)
- 编写workflow.xml文件
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
import --connect jdbc:hsqldb:file:db.hsqldb --table TT --target-dir /user/oozie/${examplesRoot}/output-data/sqoop -m 1
db.hsqldb.properties#db.hsqldb.properties
db.hsqldb.script#db.hsqldb.script
Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
|
- 执行oozie cli命令
- Oozie Java
- 编写job.properties文件
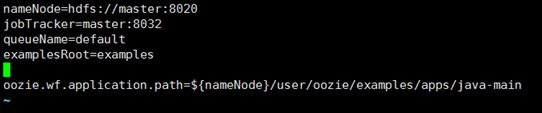
- 编写workflow.xml文件
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
org.apache.oozie.example.DemoJavaMain
Hello
Oozie!
Java failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
- 执行oozie cli命令
- Oozie Hive
- 编写job.properties文件
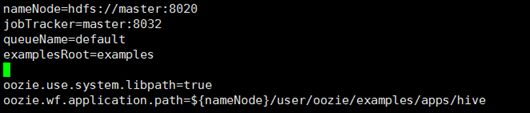
- 编写workflow.xml文件
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${jdbcURL}
INPUT=/user/oozie/${examplesRoot}/input-data/table
OUTPUT=/user/oozie/${examplesRoot}/output-data/hive2
Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
- 编写hive脚本
INSERT OVERWRITE DIRECTORY ‘${OUTPUT}‘ SELECT * FROM test_machine;
- 执行oozie cli命令
- Oozie Impala
- 编写job.properties文件
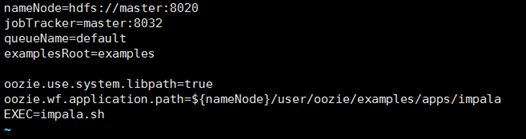
- 编写workflow.xml文件
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${EXEC}
${EXEC}#${EXEC}
Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
- 编写impala脚本文件
#!/bin/bash
impala-shell -i slave2:21000 -q "
select count(*) from test_machine"
echo ‘Hello Shell‘
- 执行oozie cli命令
- Oozie MapReduce
- 编写job.properties文件

- 编写workflow.xml文件
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
mapred.mapper.class
org.apache.oozie.example.SampleMapper
mapred.reducer.class
org.apache.oozie.example.SampleReducer
mapred.map.tasks
1
mapred.input.dir
/user/oozie/${examplesRoot}/input-data/text
mapred.output.dir
/user/oozie/${examplesRoot}/output-data/${outputDir}
Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
- 执行oozie cli命令
- Oozie Spark
- 编写job.properties文件

- 编写workflow.xml文件
${jobTracker}
${nameNode}
${master}
Spark-FileCopy
org.apache.oozie.example.SparkFileCopy
${nameNode}/user/oozie/${examplesRoot}/apps/spark/lib/oozie-examples.jar
${nameNode}/user/oozie/${examplesRoot}/input-data/text/data.txt
${nameNode}/user/oozie/${examplesRoot}/output-data/spark
Workflow failed, error
message[${wf:errorMessage(wf:lastErrorNode())}]
- 执行oozie cli命令
- Oozie 定时任务
- 定义job.properties
nameNode=hdfs://localhost:8020
jobTracker=localhost:8021
queueName=default
examplesRoot=examples
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/aggregator/coordinator.xml
start=2010-01-01T01:00Z
end=2010-01-01T03:00Z
- 定义coordinator.xml
1
${nameNode}/user/${coord:user()}/${examplesRoot}/input-data/rawLogs/${YEAR}/${MONTH}/${DAY}/${HOUR}/${MINUTE}
${nameNode}/user/${coord:user()}/${examplesRoot}/output-data/aggregator/aggregatedLogs/${YEAR}/${MONTH}/${DAY}/${HOUR}
${coord:current(-2)}
${coord:current(0)}
${coord:current(0)}
${nameNode}/user/${coord:user()}/${examplesRoot}/apps/aggregator
jobTracker
${jobTracker}
nameNode
${nameNode}
queueName
${queueName}
inputData
${coord:dataIn(‘input‘)}
outputData
${coord:dataOut(‘output‘)}
三. Oozie实例
- 设计工作流
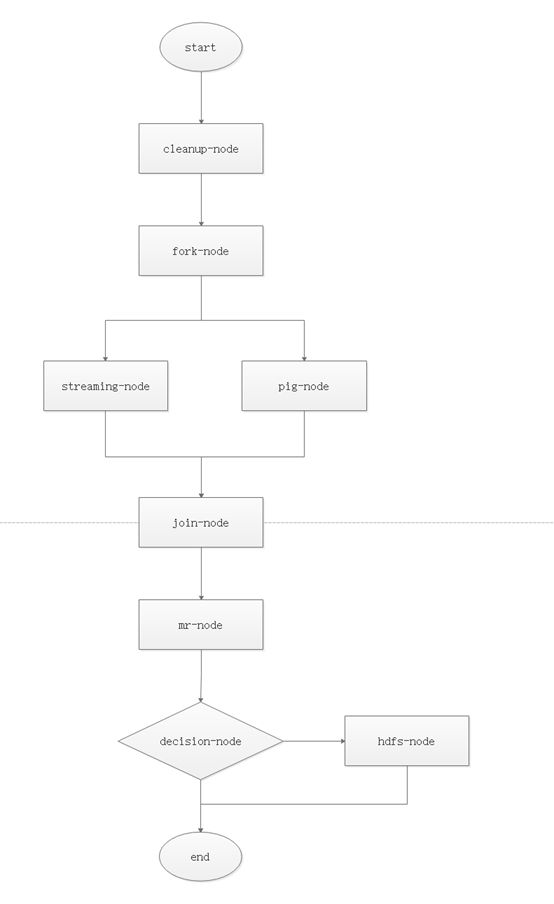
- 编写job.properties文件
nameNode=hdfs://localhost:8020
jobTracker=localhost:8021
queueName=default
examplesRoot=examples
streamingMapper=/bin/cat
streamingReducer=/usr/bin/wc
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/demo
- 在workflow.xml文件定义节点
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
mapred.map.output.compress
false
INPUT=/user/oozie/${examplesRoot}/input-data/text
OUTPUT=/user/oozie/${examplesRoot}/output-data/demo/pig-node
${jobTracker}
${nameNode}
${streamingMapper}
${streamingReducer}
mapred.job.queue.name
${queueName}
mapred.input.dir
/user/oozie/${examplesRoot}/input-data/text
mapred.output.dir
/user/oozie/${examplesRoot}/output-data/demo/streaming-node
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
mapred.mapper.class
org.apache.oozie.example.DemoMapper
mapred.mapoutput
.key.class
org.apache.hadoop.io.Text
mapred.mapoutput.value.class
org.apache.hadoop.io.IntWritable
mapred.reducer.class
org.apache.oozie.example.DemoReducer
mapred.map.tasks
1
mapred.input.dir
/user/oozie/${examplesRoot}/output-data/demo/pig-node,/user/oozie/${examplesRoot}/output-data/demo/streaming-node
mapred.output.dir
/user/oozie/${examplesRoot}/output-data/demo/mr-node
${fs:exists(concat(nameNode, ‘/user/oozie/examples/output-data/demo/mr-node‘)) == "true"}
Demo workflow failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
- 提交命令
Hue页面提交作业

- 查看执行状态

四. 总结
- EL函数
- 基本的EL函数
String firstNotNull(String value1, String value2)
String concat(String s1, String s2)
String replaceAll(String src, String regex, String replacement)
String appendAll(String src, String append, String delimeter)
String trim(String s)
String urlEncode(String s)
String timestamp()
String toJsonStr(Map) (since Oozie 3.3)
String toPropertiesStr(Map) (since Oozie 3.3)
String toConfigurationStr(Map) (since Oozie 3.3)
- WorkFlow EL
String wf:id() – 返回当前workflow作业ID
String wf:name() – 返回当前workflow作业NAME
String wf:appPath() – 返回当前workflow的路径
String wf:conf(String name) – 获取当前workflow的完整配置信息
String wf:user() – 返回启动当前job的用户
String wf:callback(String stateVar) – 返回结点的回调URL,其中参数为动作指定的退出状态
int wf:run() – 返回workflow的运行编号,正常状态为0
Map wf:actionData(String node) – 返回当前节点完成时输出的信息
int wf:actionExternalStatus(String node) – 返回当前节点的状态
String wf:lastErrorNode() – 返回最后一个ERROR状态推出的节点名称
String wf:errorCode(String node) – 返回指定节点执行job的错误码,没有则返回空
String wf:errorMessage(String message) – 返回执行节点执行job的错误信息,没有则返回空
- HDFS EL
boolean fs:exists(String path)
boolean fs:isDir(String path)
long fs:dirSize(String path) – 目录则返回目录下所有文件字节数;否则返回-1
long fs:fileSize(String path) – 文件则返回文件字节数;否则返回-1
long fs:blockSize(String path) – 文件则返回文件块的字节数;否则返回
- 注意事项
job.properties文件可以不上传到hdfs中,是在执行oozie job ...... -config时,批定的linux本地路径
workflow.xml文件,一定要上传到job.properties的oozie.wf.application.path对应的hdfs目录下。
job.properties中的oozie.use.system.libpath=true指定oozie使用系统的共享目录。
job.properties中的oozie.libpath={user.name}/apps/mymr,可以用来执行mr时,作业导出的jar包存放位置,否则可能报找不到类的错误。
oozie调度作业时,本质也是启动一个mapreduce作业来调度,workflow.xml中设置的队列名称为调度作业mr的队列名称。所以如果想让作业运行在指定的队列时,需要在mr或hive中指定好。