MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision
MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision
谷歌最新论文:从图像中进行3-D目标检测
https://arxiv.org/pdf/2003.03522.pdf
转自知乎 https://zhuanlan.zhihu.com/p/112836340
大家都看到谷歌博客的介绍,最新开源工作,手机端的实时3-D目标检测。这里看一下这个软件的论文,即3月7日上载arXiv的论文“MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision“。


摘要:本文解决的是从RGB图像中检测出没见过的目标并估计其3D姿态的问题。包括两个移动端友好网络:MobilePose-Base和MobilePose-Shape。前者用于只进行姿势监督的情况,而后者用于形状监督,甚至是较弱的情况。回顾一下之前人们使用的形状特征,包括分割和坐标图(coordinate map)。然后解释了什么时候以及为什么像素级形状监督可以改善姿态估计。因此,在MobilePose-Shape中将形状预测添加为中间层,并让网络从形状中学习姿势。其模型在混合真实数据和合成数据上进行训练,并做弱和含噪的形状监督。模型非常轻巧,可以在现代移动设备上实时运行(例如Galaxy S20上为36 FPS)。与以前的单样本学习解决方案相比,该方法具有更高的准确性,使用的模型也要小得多(模型大小或参数数量仅仅占2-3%)。
实例-觉察(instance-aware)方法从一组已知目标中学习姿势,并有望在相同实例上工作。模型-觉察(model-aware)的方法在后期处理中需要目标的3D CAD模型。深度-觉察(depth-aware)方法除RGB图像外还需要深度图像用于姿势估计。检测-觉察(detection-aware)的方法依赖于现有的2D检测器来找到目标边框或ROI。
形状特征已被用于估计姿势,采用的方法在后处理中而不是在网络中使用形状预测。 也就是说,它们首先通过CNN推断形状特征,然后使用多视角几何的PnP或点云ICP将其与3D模型对齐。实时解决方案使姿态估计技术更接近于应用,只是这些模型必须轻巧才能实时运行,最好是单次运行。
首先,MobilePose-Base作为基准网络,它可以检测到无锚点的未见目标,并采用单样本估计目标姿势。这种主干网设计为流行的编码器-解码器体系结构。为了构建一个超轻量级的模型,选择MobileNetv2 来构建编码器,该编码器被证明可以在移动设备上实时运行,并且胜过YOLOv2。 MobileNetv2建立在倒残差块上(inverted residual blocks),其中快连接(shortcut connections)放在薄的瓶颈层之间。块中使用了ES(expansion-and-squeeze)方案。为使模型更轻,移除了瓶颈处某些带较大通道的块,减少了一半的参数。
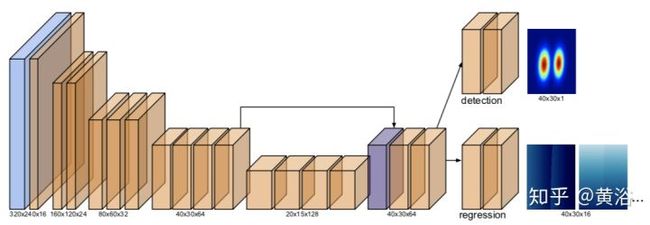
如图所示,蓝色和紫色框分别是卷积和反卷积块。橙色框代表反向残差块。图中所示的块数及其尺寸在实现中完全相同。输入是大小为640×480×3的图像。编码器以卷积层开始,然后是五级倒残差块。瓶颈处使用了四个128-通道块,而不是MobileNetv2的四个160-通道块和一个320-通道块。解码器由一个反卷积层、一个和编码器相同尺度层跳连接(skip connection)的连接层和两个倒残差块组成。
在主干之后附加两个头:检测和回归。 检测头(detection head)的想法来自2D目标检测中的无锚(anchor-free)方法。 将目标建模为围绕它们中心的分布,检测头输出40×30×1的热图(heat map),最终损失函数使用了简单的L2(均方误差)。

锚点图、分割图和分布图
如上图比较了单样本(single shot)姿势估计中使用的不同检测方法。 基于锚点(anchor-based)的方法在网格单元处设置锚,并在正的锚点(绿点)处回归边框。 临时分配多个锚点可处理同一网格单元的多个目标。 分割方法通过分割实例查找目标。 对同一类别的多个目标,需要实例分割以区分不同目标。 目标建模为高斯分布,并通过峰值搜索进行检测。 为了更好地说明,图中使用了高分辨率,而模型的实际分辨率为(40×30)。
上图中多个目标的位移场(Displacement fields)根据它们的热度可合并在一起。回归头(regression head)输出一个40×30×16的张量,其中每个矩形顶点贡献两个位移通道。 在图中,只显示了两个位移场。 为了容忍峰值提取的误差,带明显热度的那些像素位移参与回归。 为此,该头使用L1-损失(平均绝对误差)函数,更为稳健。
反过来,看看形状。即使是薄弱的监督,MobilePose- Shape可以预测中间层的形状特征。其思想是引导网络学习与姿势估计有关的高分辨率形状特征。 其实,在没有监督的情况下简单引入高分辨率特征不会改善姿势估计,这是因为边框顶点的回归是在低维空间。 在无监督情况下,网络可能会在小尺度上过拟合特定于目标的特征。 此问题对于实例-觉察的姿势估计方法无效,但不包括这里的未知目标情况。
与先前的方法相似,选择坐标图和分割作为类内(intra-category)形状特征。坐标图具有三通道,分别对应于3-D的坐标轴。 如果训练数据有目标的CAD模型,则可以使用归一化坐标作为颜色来渲染坐标图。 坐标图是像素级信号的强大特征,但是,它需要目标的CAD模型和姿势,而这些模型和姿势很难获取。 因此这里将分割作为另一个形状特征添加。 为简单起见,使用语义分割,在形状监督中增加了一个通道。 分割是姿势估计的弱项,仅仅给定未见目标的分割,不足以确定其姿势。 但是,也不需要目标的CAD模型和姿势,而且更容易获得。

有了形状特征,用解码器中的高分辨率层和形状预测层来修改网络。如上图所示,在解码器中组合了多尺度特征。 在解码器的末尾添加一个形状层,以预测形状特征。 然后将其与解码器连接起来,在下采样后连接姿势头(pose heads)。 具体来说,用四个倒残差块来降低分辨率,并最终连接检测头和回归头。 形状头(shape head),大小160×120×4,具有四个具有L2-损失(均方误差)的通道。 在计算该损失时,将跳过没有形状标签的训练示例。 通过实验,发现即使在监督不力的情况下,通过引入高分辨率形状预测也可以改善姿势估计。
尽管模型很轻巧,但后处理对移动应用程序也是至关重要的组件。 昂贵的算法是不考虑的,比如RANSAC,大规模PnP和ICP。 这里将后处理简化为两个便宜的操作:峰提取和EPnP。
为了计算3D边框的投影顶点,提取检测输出的峰值,即40×30热图。
给定投影的2D边框顶点和相机标定的内参数,采用EPnP算法来恢复3D边框的大小。 该算法具有恒定的复杂度,可以解决12×12矩阵的特征分解,它不需要已知目标的大小。
缺乏训练数据是6自由度(DoF)姿势估计仍然存在的挑战。 先前大多数方法都是实例-觉察方法,由一个小数据集进行监督训练。 为了解决未见目标的问题,这里开发了一个流水线来收集和注释由AR移动设备记录的视频片段。
尖端AR解决方案(例如ARKit和ARCore)可以用视觉-惯性-里程计(VIO)实时估算摄像机的姿势和稀疏3D特征。这种设备能够以可承受且可扩展的方式生成3D训练数据。
数据流水线的关键是高效,准确的3D边框标注。这里构建了一个记录序列显示2D和3D视图的可视化工具。注释者在3D视图绘制3D边框,在整个序列的多个2D视图进行验证。基于AR估计的相机姿态,绘制的边框将自动填充到序列中的所有帧。
实际结果是,对1800个鞋子的视频进行了剪辑和添加注释。在各种环境下,不同鞋子的视频片断有几秒钟。只为一个或一双鞋子接受一个视频片断,因此,每个片断的目标完全不同。在这些剪辑中,随机选择了1500个用于训练,其余300个用于评估。最后,考虑到同一剪辑中的相邻帧非常相似,随机选择了10万个图像进行训练,并选择1000个图像进行评估。如下表数据集(一共包括三个,即真实数据、合成3D数据和合成2D数据)所示,真实数据仅具有3D边框标签,这是因为,逐帧注释像素级的形状标签非常昂贵。

为了提供形状监督并丰富现有的实际数据集,也生成了两组合成数据。 第一个合成3D数据具有3D标签。收集只有背景的场景AR视频剪辑,并将虚拟目标放置到场景中。 具体来说,在场景检测的平面上,例如桌子或地板,以随机的姿势渲染虚拟目标。 重用估计的灯光在AR会话(AR Session)进行照明。 AR 会话数据的度量单位为公制。 因此,其一致地渲染虚拟目标与周围的几何形状。 收集了100个常见场景的视频片段:家庭、办公室和室外。 对每个场景,通过渲染50个随机姿势的鞋子来生成100个序列,每个序列包含许多鞋子。 从生成的图像随机选择8万进行训练。下图展示一些合成的视频例子。

尽管合成3D数据具有准确的标签,但是目标和背景的数量仍然有限。 因此,还从互联网上抓取图像来构建合成2D数据集。 这里抓取了透明背景下的鞋子图像7.5万个和背景(例如办公室和家庭)图像4万个。 滤除有微小错误(例如无透明背景下的)的鞋子图片。 按Alpha通道(channel)对鞋子进行细分,然后将它们随机粘贴到背景图像中。 如上图所示,生成的图像不真实,标签噪声很大。 粗略估计大约有20%的图像有轻微的标签错误(例如,小缺失部分和阴影),约10%的图像有严重的标签错误(例如,非鞋子物体和较大的额外背景区域)。
整个训练流程在TensorFlow中实现。 使用Adam优化器在8个GPU上训练批量(batch)大小为128的网络。 初始学习率是0.01,在30个时期(epochs)内逐渐下降到0.001。 为了在移动设备上部署经过训练的模型,将它们转换为TFLite模型。 转换时将删除一些层,例如批处理归一化(batch normalization),推理时它们是没有用的。 基于MediaPipe框架(注:它是一个跨平台框架,即安卓、IOS 、网页和边缘设备等各种平台,用于构建多模态应用机器学习流水线,详细内容见网页https://mediapipe.dev),这里构建了一个可以在各种移动设备上运行的应用程序。
最后,看看一些实验定性结果例子:
