因子分解机(Factorization Machine)详解(一)
Factorization Machine
因子分解机(Factorization Machine, FM)是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法。目前,被广泛的应用于广告预估模型中,相比LR而言,效果强了不少。我们可以认为,这个模型结合了SVM的优点与分解模型的优点。与SVM类似的是,FM是一个广泛的预测器,可以兼容任意实值的特征向量。而与FM不同的是,FM对于所有变量之间的联系使用了分解的参量去建模。
- 主要目标: 解决数据稀疏的情况下,特征怎样组合的问题。
- FM优点:
主要考虑到,FM模型是SVM模型与factorization模型的结合。- FM模型可以在非常稀疏的数据中进行合理的参数轨迹,而SVM做不到这点。(FMs allow parameter estimation under very sparse data wher SVMs fails.)
- FM模型的复杂度是线性的,优化效果很好,而且不需要像SVM一样依赖于支持向量。(FMs have linear complexity, can be optimized in the primal and do not rely on support vectors like SVM.)
- FM是一个通用模型,它可以用于任何特征值为实值的情况。而其他因式分解模型只能用于一些输入数据比较固定的情况。(FMs are a general predictor that can work with any real valued feature vector. In contrast to this, other state-of-the-art factorization models work only on very restricted input data)
关于FM, peghoty的博文比较清晰,大家可以点击链接先阅读一下,并与本文章进行对比。
1. FM模型简介
1.1 FM模型
本质上是SVM模型的拓展,主要考虑到多维特征之间的交叉关系,其中参数的训练使用的是矩阵分解的方法。
参数模型的表示如下:我们的预测任务是估计一个函数 y : R n → T y : \mathbb{R}^{n} \rightarrow T y:Rn→T表示从实值向量 x ∈ R n \mathbf{x} \in \mathbb{R}^{n} x∈Rn到目标域 T T T中,(比如对回归问题 T = R T=\mathbb{R} T=R,分类问题 T = { + , − } T=\{+,-\} T={+,−})。在监督模型中,我们假设存在一个训练数据集 D = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , … } D=\left\{\left(\mathbf{x}^{(1)}, y^{(1)}\right),\left(\mathbf{x}^{(2)}, y^{(2)}\right), \ldots\right\} D={(x(1),y(1)),(x(2),y(2)),…}。另外,也调查了推荐任务的函数 y y y,以及 T = R T = \mathbb{R} T=R可以被用来表示向量 x \mathbf x x。分数函数可以被用来训练成对训练集,这里特征元组 ( x ( A ) , x ( B ) ) ∈ D \left(\mathbf{x}^{(A)}, \mathbf{x}^{(B)}\right) \in D (x(A),x(B))∈D表示 x ( A ) \mathbf{x}^{(A)} x(A)应该比 x ( B ) \mathbf{x}^{(B)} x(B)排名更高。
1.2 FM 模型的超平面分类公式
-
二阶FM的公式(2-order, 2-way FM):
y ^ F M ( x ) : = ⟨ w , x ⟩ + ∑ j ′ > j ⟨ p ‾ j , p ‾ j ′ ⟩ x j x j \hat { y } _ { \mathrm { FM } } ( \boldsymbol { x } ) : = \langle \boldsymbol { w } , \boldsymbol { x } \rangle + \sum _ { j ^ { \prime } > j } \left\langle \overline { \boldsymbol { p } } _ { j } , \overline { \boldsymbol { p } } _ { j ^ { \prime } } \right\rangle x _ { j } x _ { j } y^FM(x):=⟨w,x⟩+j′>j∑⟨pj,pj′⟩xjxj
或者更为普遍的写法:
y ^ ( x ) : = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j \hat{y}(\mathbf{x}) :=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} y^(x):=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩xixj
其中,各个参数的size为:
w 0 ∈ R , w ∈ R n , V ∈ R n × k w_{0} \in \mathbb{R}, \quad \mathbf{w} \in \mathbb{R}^{n}, \quad \mathbf{V} \in \mathbb{R}^{n \times k} w0∈R,w∈Rn,V∈Rn×k
内积定义如下:
⟨ v i , v j ⟩ : = ∑ f = 1 k v i , f ⋅ v j , f \left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle :=\sum_{f=1}^{k} v_{i, f} \cdot v_{j, f} ⟨vi,vj⟩:=f=1∑kvi,f⋅vj,f
其中 k ∈ N 0 + k \in \mathbb{N}_{0}^{+} k∈N0+表示的是决定分解机维度的超参。 n n n表示的是模型参数的维度。2-way的FM捕捉了所有的单独的特征以及变量之间的特征,各参数的意义表示如下:- w 0 w_0 w0是全局偏置量
- w i w_i wi建模了第i个变量的强度
- w ^ i , j : = ⟨ v i , v j ⟩ \hat{w}_{i, j}:=\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle w^i,j:=⟨vi,vj⟩。建模了第i和第j个变量之间的联系。
-
高阶FM的公式:
y ^ H O F M ( x ) : = ⟨ w , x ⟩ + ∑ j ′ > j ⟨ p ‾ j ( 2 ) , p ‾ j ′ ( 2 ) ⟩ x j x j ′ + ⋯ + ∑ j m > ⋯ > j 1 ⟨ p ‾ j 1 ( m ) , … , p ‾ j m ( m ) ⟩ x j 1 x j 2 … x j m \hat { y } _ { \mathrm { HOFM } } ( \boldsymbol { x } ) : = \langle \boldsymbol { w } , \boldsymbol { x } \rangle + \sum _ { j ^ { \prime } > j } \left\langle \overline { \boldsymbol { p } } _ { j } ^ { ( 2 ) } , \overline { \boldsymbol { p } } _ { j ^ { \prime } } ^ { ( 2 ) } \right\rangle x _ { j } x _ { j ^ { \prime } } + \cdots + \sum _ { j _ { m } > \cdots > j _ { 1 } } \left\langle \overline { \boldsymbol { p } } _ { j _ { 1 } } ^ { ( m ) } , \ldots , \overline { \boldsymbol { p } } _ { j _ { m } } ^ { ( m ) } \right\rangle x _ { j _ { 1 } } x _ { j _ { 2 } } \ldots x _ { j _ { m } } y^HOFM(x):=⟨w,x⟩+j′>j∑⟨pj(2),pj′(2)⟩xjxj′+⋯+jm>⋯>j1∑⟨pj1(m),…,pjm(m)⟩xj1xj2…xjm
与二阶FM类似,但是其考虑了更多特征之间的关联性质。
1.3 关于FM三点优点的解释
首先,对于稀疏数据的计算,通常没有足够的数据来直接独立地估计变量之间的关联性。FM可以评估,则是因为FM通过分解的方式打破了数据参数的独立性。
具体可以参见图1:

在FM中,每个评分记录被放在一个矩阵的一行中,从列数看特征矩阵 x \mathbf x x的前面 u u u列即为User矩阵,每个User对应一列,接下来的 i i i列即为item特征矩阵,之后数列是多余的非显式的特征关系。后面一列表示时间关系,最后 i i i列则表示同一个user在上一条记录中的结果,用于表示用户的历史行为。
例子,可以考虑用户A以及电影ST之间的关系。首先,二者没有直接的联系,也就是 w A , S T = 0 w_{A, \mathrm{ST}}=0 wA,ST=0,通过分解联系的变量 ⟨ v A , v S T ⟩ \left\langle\mathbf{v}_{A}, \mathbf{v}_{\mathrm{ST}}\right\rangle ⟨vA,vST⟩我们能够估计在这种情况下的联系。因此,对于稀疏数据而言,FM可以挖掘出更深层次的信息。
第二,假设 n , k n, k n,k如前述定义,那么计算前驱过程的时间复杂度为 O ( k n 2 ) O\left(k n^{2}\right) O(kn2)。但是通过重组计算公式能够得到线性的时间复杂度 O ( k n ) O(k n) O(kn)。证明如下:
∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j = 1 2 ∑ i = 1 n ∑ j = 1 n ⟨ v i , v j ⟩ x i x j − 1 2 ∑ i = 1 n ⟨ v i , v i ⟩ x i x i = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i , f v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v i , f x i x i ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) \begin{aligned} & \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\&=\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\&=\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \end{aligned} ==i=1∑nj=i+1∑n⟨vi,vj⟩xixj21i=1∑nj=1∑n⟨vi,vj⟩xixj−21i=1∑n⟨vi,vi⟩xixi21⎝⎛i=1∑nj=1∑nf=1∑kvi,fvj,fxixj−i=1∑nf=1∑kvi,fvi,fxixi⎠⎞=21f=1∑k((i=1∑nvi,fxi)(j=1∑nvj,fxj)−i=1∑nvi,f2xi2)=21f=1∑k⎝⎛(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2⎠⎞
可以看到我们只需要计算 v i , f v_{i,f} vi,f以及 x i x_i xi相关的结果。另外,由上式可以看到,在稀疏的情况下,我们只需要计算非0的结果。假设 x \mathbf x x中非0的数量为 m ( x ) m(\mathbf{x}) m(x),时间复杂度为 O ( k m ‾ D ) O\left(k \overline{m}_{D}\right) O(kmD)。另外,FM也具有多线性(multi-linearity)的性质,对任意参数 θ \theta θ,FM的预测模型如下:
y ^ ( x ) = g θ ( x ) + θ h θ ( x ) ∀ θ ∈ Θ \hat{y}(\mathbf{x})=g_{\theta}(\mathbf{x})+\theta h_{\theta}(\mathbf{x}) \quad \forall \theta \in \Theta y^(x)=gθ(x)+θhθ(x)∀θ∈Θ
可以轻易求得梯度:
h θ ( x ) = ∂ y ^ ( x ) ∂ θ = { 1 , if θ is w 0 x l , if θ is w l x l ∑ j ≠ l v j , f x j , if θ is v l , f h_{\theta}(\mathbf{x})=\frac{\partial \hat{y}(\mathbf{x})}{\partial \theta}=\left\{\begin{array}{ll}{1,} & {\text { if } \theta \text { is } w_{0}} \\ {x_{l},} & {\text { if } \theta \text { is } w_{l}} \\ {x_{l} \sum_{j \neq l} v_{j, f} x_{j},} & {\text { if } \theta \text { is } v_{l, f}}\end{array}\right. hθ(x)=∂θ∂y^(x)=⎩⎨⎧1,xl,xl∑j̸=lvj,fxj, if θ is w0 if θ is wl if θ is vl,f
关于第三个优点,分别考虑FM与传统的线性分类器SVM与常见的分解方法MF, SVD++, PITF( factorizing pairwise interactions)以及FPMC( Factorized Personalized Markov Chains)等方法进行对比。具体的对比我会再写一篇文章进行详细分析。
2. FM的训练方法
对于FM而言,其可以被应用于很多预测任务,包括:
- 回归问题: 可以使用最小均方误差进行优化
- 二分类问题: 可以使用hinge loss或者logit loss进行优化
- Ranking问题: 向量 x \mathbf x x以预测的分数函数 y ^ ( x ) \hat{y}(\mathbf{x}) y^(x)为基准进行排列,优化是使用实例向量 ( x ( a ) , x ( b ) ) ∈ D \left(\mathbf{x}^{(\mathbf{a})}, \mathbf{x}^{(\mathbf{b})}\right) \in D (x(a),x(b))∈D成对的分类误差进行的。
具体的优化方法包括SGD, ALS以及MCMC。
2.1 优化问题介绍
对于特定的观测集 S S S,我们得到目标函数为:
OPT ( S ) : = argmin Θ ∑ ( x , y ) ∈ S l ( y ^ ( x ∣ Θ ) , y ) \operatorname{OPT}(S) :=\underset{\Theta}{\operatorname{argmin}} \sum_{(\mathbf{x}, y) \in S} l(\hat{y}(\mathbf{x} | \Theta), y) OPT(S):=Θargmin(x,y)∈S∑l(y^(x∣Θ),y)
loss function:
- 回归问题: l L S ( y 1 , y 2 ) : = ( y 1 − y 2 ) 2 l^{\mathrm{LS}}\left(y_{1}, y_{2}\right) :=\left(y_{1}-y_{2}\right)^{2} lLS(y1,y2):=(y1−y2)2
- 二分类问题: l C ( y 1 , y 2 ) : = − ln σ ( y 1 y 2 ) l^{\mathrm{C}}\left(y_{1}, y_{2}\right) :=-\ln \sigma\left(y_{1} y_{2}\right) lC(y1,y2):=−lnσ(y1y2)
对Stochastic的目标函数分布:
- 回归问题: p ( y ∣ x , Θ ) ∼ N ( y ^ ( x , Θ ) , 1 / α ) p(y|\mathbf{x}, \Theta) \sim \mathcal{N}(\hat{y}(\mathbf{x}, \Theta), 1 / \alpha) p(y∣x,Θ)∼N(y^(x,Θ),1/α)
- 二分类问题: p ( y ∣ x , Θ ) ∼ Bernoulli ( b ( y ^ ( x , Θ ) ) ) p(y|\mathbf{x}, \Theta) \sim \operatorname{Bernoulli}(b(\hat{y}(\mathbf{x}, \Theta))) p(y∣x,Θ)∼Bernoulli(b(y^(x,Θ)))
其概率图模型可表示如下:
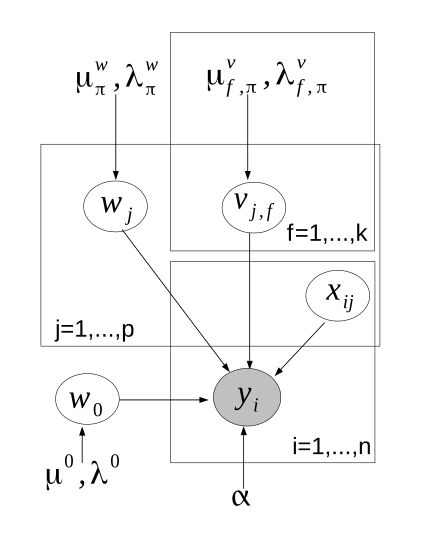
其中 μ , λ \mu, \lambda μ,λ等均为超参。
梯度计算公式如下:
- 回归问题:
∂ ∂ θ l L S ( y ^ ( x ∣ Θ ) , y ) = ∂ ∂ θ ( y ^ ( x ∣ Θ ) − y ) 2 = 2 ( y ^ ( x ∣ Θ ) − y ) ∂ ∂ θ y ^ ( x ∣ Θ ) \frac{\partial}{\partial \theta} l^{\mathrm{LS}}(\hat{y}(\mathbf{x} | \Theta), y)=\frac{\partial}{\partial \theta}(\hat{y}(\mathbf{x} | \Theta)-y)^{2}=2(\hat{y}(\mathbf{x} | \Theta)-y) \frac{\partial}{\partial \theta} \hat{y}(\mathbf{x} | \Theta) ∂θ∂lLS(y^(x∣Θ),y)=∂θ∂(y^(x∣Θ)−y)2=2(y^(x∣Θ)−y)∂θ∂y^(x∣Θ)
- 二分类问题:
∂ ∂ θ l C ( y ^ ( x ∣ Θ ) , y ) = ∂ ∂ θ − ln σ ( y ^ ( x ∣ Θ ) y ) = ( σ ( y ^ ( x ∣ Θ ) y ) − 1 ) y ∂ ∂ θ y ^ ( x ∣ Θ ) \frac{\partial}{\partial \theta} l^{\mathrm{C}}(\hat{y}(\mathbf{x} | \Theta), y)=\frac{\partial}{\partial \theta}-\ln \sigma(\hat{y}(\mathbf{x} | \Theta) y)=(\sigma(\hat{y}(\mathbf{x} | \Theta) y)-1) y \frac{\partial}{\partial \theta} \hat{y}(\mathbf{x} | \Theta) ∂θ∂lC(y^(x∣Θ),y)=∂θ∂−lnσ(y^(x∣Θ)y)=(σ(y^(x∣Θ)y)−1)y∂θ∂y^(x∣Θ)
2.2 SGD方法
不多说,直接上算法:

比较容易理解,缺点是必须确定学习率 η \eta η。
2.3 ALS
ALS即为Alternating Least-Squares,也是Coordinate Descent,是对SGD方法的改进。具体是将参数 Θ \Theta Θ拆分成若干个部分,公式为:
θ ∗ = argmin θ ( ∑ ( x , y ) ∈ S ( y ^ ( x ∣ Θ ) − y ) 2 + ∑ θ ∈ Θ λ θ θ 2 ) = argmin θ ( ∑ ( x , y ) ∈ S ( g θ ( x ∣ Θ \ { θ } ) + θ h θ ( x ∣ Θ \ { θ } ) − y ) 2 + ∑ θ ∈ Θ λ θ θ 2 ) = ∑ i = 1 n h θ 2 ( x i ∣ Θ \ { θ } ) h θ ( x i ∣ Θ \ { θ } ) ∑ i = 1 n h θ ( x i ) 2 + λ θ = θ ∑ i = 1 n h θ 2 ( x i ∣ Θ \ { θ } ) h θ ( x i ) e i ∑ i = 1 n h θ ( x i ) 2 + λ θ \begin{aligned} \theta^{*} &=\underset{\theta}{\operatorname{argmin}}\left(\sum_{(\mathbf{x}, y) \in S}(\hat{y}(\mathbf{x} | \Theta)-y)^{2}+\sum_{\theta \in \Theta} \lambda_{\theta} \theta^{2}\right) \\ &=\underset{\theta}{\operatorname{argmin}}\left(\sum_{(\mathbf{x}, y) \in S}\left(g_{\theta}(\mathbf{x} | \Theta \backslash\{\theta\})+\theta h_{\theta}(\mathbf{x} | \Theta \backslash\{\theta\})-y\right)^{2}+\sum_{\theta \in \Theta} \lambda_{\theta} \theta^{2}\right) \\ &=\frac{\sum_{i=1}^{n} h_{\theta}^{2}\left(\mathbf{x}_{i} | \Theta \backslash\{\theta\}\right) h_{\theta}\left(\mathbf{x}_{i} | \Theta \backslash\{\theta\}\right)}{\sum_{i=1}^{n} h_{\theta}\left(\mathbf{x}_{i}\right)^{2}+\lambda_{\theta}} \\ &=\frac{\theta \sum_{i=1}^{n} h_{\theta}^{2}\left(\mathbf{x}_{i} | \Theta \backslash\{\theta\}\right) h_{\theta}\left(\mathbf{x}_{i}\right) e_{i}}{\sum_{i=1}^{n} h_{\theta}\left(\mathbf{x}_{i}\right)^{2}+\lambda_{\theta}} \end{aligned} θ∗=θargmin⎝⎛(x,y)∈S∑(y^(x∣Θ)−y)2+θ∈Θ∑λθθ2⎠⎞=θargmin⎝⎛(x,y)∈S∑(gθ(x∣Θ\{θ})+θhθ(x∣Θ\{θ})−y)2+θ∈Θ∑λθθ2⎠⎞=∑i=1nhθ(xi)2+λθ∑i=1nhθ2(xi∣Θ\{θ})hθ(xi∣Θ\{θ})=∑i=1nhθ(xi)2+λθθ∑i=1nhθ2(xi∣Θ\{θ})hθ(xi)ei
其中 e i : = y i − y ^ ( x i ∣ Θ ) e_{i} :=y_{i}-\hat{y}\left(\mathbf{x}_{i} | \Theta\right) ei:=yi−y^(xi∣Θ),为残差项。算法如下:
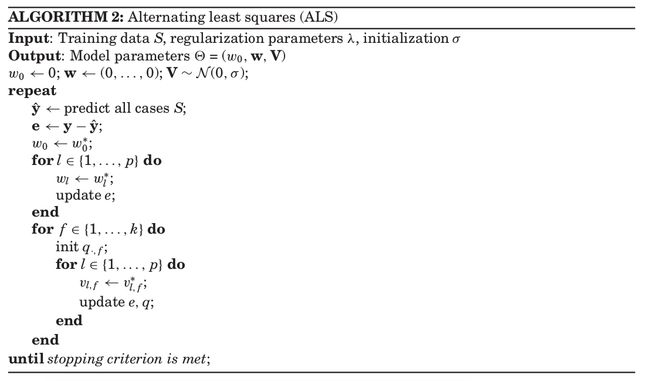
对于更加详细的ALS算法,可以表现为下图:

其中,ALS的主要改进为不需要学习率,但是仍然需要确定regularization的超参。
2.4 MCMC方法
使用概率图推断以及最大后验估计(MAP)的方法。概率图如下:

其实就是针对原方法对各个超参进行MCMC采样操作。具体采用Gibbs采样器。通过确定各个超参的先验概率,使用贝叶斯推断方法,以及对各个参数的后验概率求导,即可对整个模型进行优化。参数集 Θ \Theta Θ为:
Θ 0 : = { α 0 , β 0 , α λ , β λ , μ 0 , γ 0 } \Theta_{0} :=\left\{\alpha_{0}, \beta_{0}, \alpha_{\lambda}, \beta_{\lambda}, \mu_{0}, \gamma_{0}\right\} Θ0:={α0,β0,αλ,βλ,μ0,γ0}
后续将继续介绍FM与深度学习相结合的应用,以及解决高阶FM的方法。
3. Reference
[1] Rendle S. Factorization machines[C]//2010 IEEE International Conference on Data Mining. IEEE, 2010: 995-1000.
[2] Rendle S. Factorization machines with libfm[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2012, 3(3): 57.
[3] Blondel M, Fujino A, Ueda N, et al. Higher-order factorization machines[C]//Advances in Neural Information Processing Systems. 2016: 3351-3359.