注意力机制到底是什么——基于常识的基本结构介绍
摘要:注意力机制(Attention Mechanism)是人们在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。本文以一个基于注意力机制的机器翻译模型为例,从人的直觉、中英文翻译的常识、特征工程等角度,对注意力机制的思想和机理进行了阐述;并介绍了一种常见的注意力机制实现形式,即基于感知机的注意力机制;还介绍了一种比较经典的注意力机制,即自注意力机制(self-attention)。
1引言
注意力机制是上世纪九十年代,一些科学家在研究人类视觉时,发现的一种信号处理机制。人工智能领域的从业者把这种机制引入到一些模型里,并取得了成功。目前,注意力机制已经成为深度学习领域,尤其是自然语言处理领域,应用最广泛的“组件”之一。这两年曝光度极高的BERT、GPT、Transformer等等模型或结构,都采用了注意力机制。
由于对计算机视觉领域不是很熟,我在学习和整理注意力机制相关内容的时候,采用了注意力机制的思想:基本忽略CV相关内容,主要精力放在NLP方面。因此,本文基本不涉及CV同志们的工作。
2认知科学、特征工程与注意力机制
“注意力机制”是上个世纪90年代,认知科学领域的学者发现的一个人类处理信息时采用的机制。我们做数据科学类任务时,经常做的特征工程,看起来很像一个模型外挂的注意力模块。
2.1人身上的注意力机制
假设我和老婆在超市里买菜。由于超市里的情况如图1-1所示,我需要时不时地从人海里找到买了跳刀的老婆。我的眼睛真厉害,可以看到这么多东西,视线范围内所有事物的形状、颜色、纹路等等全都接收进来——大脑表示压力很大,实在处理不过来,于是选择忽略一部分信号,重点看每一个人的发型、衣服颜色、站姿等,而且重点分析靠近视线范围中心的区域。我转动脑袋,帮助眼睛扫描更大的范围,从而帮助大脑分析更多的人,终于找到了目标。
 图2‑1 环境噪声较大
图2‑1 环境噪声较大
像我这样,有选择性的处理信号,是包括人类在内的很多生物在处理外界信号时的策略,其背后的机制被认知科学领域的学者称为“注意力机制”。
2.2特征工程——模型外部的注意力机制
我们在用机器学习模型完成情感分析这类任务时,通常会做一点特征工程的工作,即将原始文本转换为数值向量。特征工程,就是注意力机制在数据科学领域里的一种体现,它帮助模型选择有效、适当规模的特征,进而让模型可以有效、高效地完成任务。比如说,我们用逐步回归分析方法对原始特征集进行筛选,得到一个高质量的特征子集,就可以让下游模型聚焦于和任务关系最密切的信号。
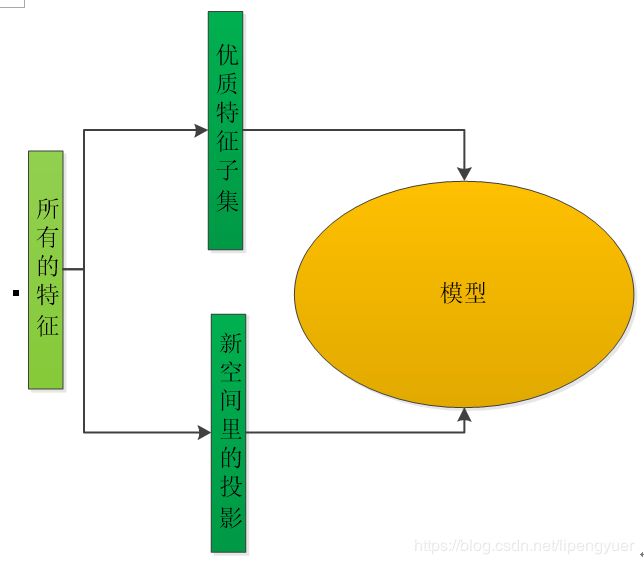 2‑2 特征工程的作用
2‑2 特征工程的作用
良好的特征工程,依赖于工程师对业务内容的深入理解。换句话说,数据科学从业者要花一定量的时间,用于了解研究对象。研究对象千千万,留给我们了解的时间不多了。
传统特征工程采用了一种静态的观点来观察事物。我了解的特征工程方法,都假设各个特征的重要性是固定不变的的——特征工程结束的时候,每个特征就被赋予了一个固定的权重值。(应该是)大部分机器学习模型,也假设输入数据的各个维度具有固定的权重,学习完毕后,就不再改变各个维度的权重了。
2.3传统特征工程不能解决的问题
然而,我们用静态的观点无法较好地刻画某些类型数据的动态特点。这里用一个简单的机器翻译任务来说明这一点。比如说我要做机器翻译(机器翻译是最能体现注意力机制特色的任务),构建一个模型,把”I am Chinese.”翻译成中文。
假设我们用一个基于RNN的seq2seq结构来学习平行语料,并获得了一个翻译模型(循环神经网络相关内容可以参考https://zhuanlan.zhihu.com/p/67322903)。这个模型做翻译的过程更是这样的:
- 编码器接收英文词向量序列,并在各个时间步输出当时的隐藏状态(由于这一层有多个神经元,各个时间步的输出实际上是一维向量)
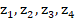 。
。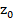 是一个元素全为0的一维向量,用来启动神经元迭代过程,一般不用来作为解码器的输入;这个神经元输出的隐藏状态合起来是一个二维数组
是一个元素全为0的一维向量,用来启动神经元迭代过程,一般不用来作为解码器的输入;这个神经元输出的隐藏状态合起来是一个二维数组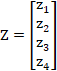
- 解码器基于自身历史输出值以及编码器输出的最终状态,计算当前时间步的状态,并判断当前时间步状态对应的中文词语。
- 重复(2)步,直到输出
标签。
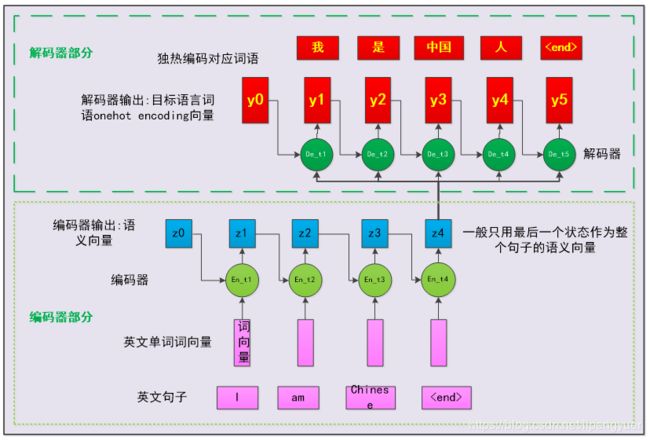 图2‑3 经典的基于RNN的seq2seq结构
图2‑3 经典的基于RNN的seq2seq结构
注意,这里解码器计算输出的方式是![]() 。由于编码器的权重已经固定,
。由于编码器的权重已经固定,![]() 里蕴含的各个英文单词的贡献已经固定,因此即在得到各个中文词语的时候,模型认为各个英文单词的贡献是固定不变的。
里蕴含的各个英文单词的贡献已经固定,因此即在得到各个中文词语的时候,模型认为各个英文单词的贡献是固定不变的。
显然,这种假设不符合我们的常识。在获得“我”这个词语时,如果考虑”am Chinese”,就有点多余了;而“人”这个字的获得,则必须综合考虑”I”、“am”和“Chinese”。也就是说,人类这个翻译达人在进行英-中翻译的时候,每确定一个中文词语,都要对英文句子里的所有单词的贡献重新审视一下,以充分地考虑源文本的句子结构和语义,进而得到尽量好的中文译文。
3深度学习领域的注意力机制
3.2注意力机制的思想和基本框架
一些学者尝试让模型自己学习如何分配自己的注意力,即为输入信号加权。他们用注意力机制的直接目的,就是为输入的各个维度打分,然后按照得分对特征加权,以突出重要特征对下游模型或模块的影响。这也是注意力机制的基本思想。
比较规范的文章里,一般会采用”key-query-value”理论来描述注意力机制的机理。对我来说,理解这个有点困难,因此这里虚构了一个符合本人直觉的框架。如图3-1,是一个针对RNN神经元的注意力机制框架。我们在图2-2所示的框架基础上,增加一个注意力模块,基于输入数据和神经元的历史输出,预测当前时间步,输入数据各个维度的权重。然后基于这份权重对输入数据加权求和,就得到了当前时间步,交给神经元的最终输入——神经元接收这份输入,以及历史输出,就可以计算当前时间步的输出了。
这样做有啥用呢,好使吗?接下来,本小节会介绍这种操作的细节,在3.2节说明其合理性 (有效性已经在大家的实战中得到了验证,这里就不多说啦)。
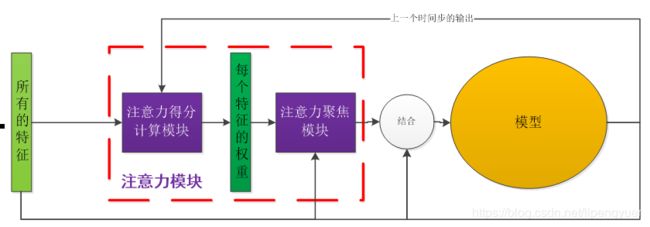 图3‑1 一个适合RNN的注意力机制框架
图3‑1 一个适合RNN的注意力机制框架
3.3注意力模块干了什么?
注意力模块内部分为两个子模块:(1)注意力得分计算模块;(2)注意力聚焦模块。注意,注意力模块内部结构,是我为了降低理解模型的难度,特意虚构的(同行们一般把注意力模块看做一个整体来介绍)。注意力得分计算模块,会基于解码器神经元的历史输出和编码器各个神经元的输出,计算出编码器各个时间步的输出,与解码器当前输出的“相关度”,也叫做注意力得分。用数学符号表达很简单:
![]()
![]()
…
![]()
权重的角标中,第一位表示解码器神经元的时间步,第二位表示编码器神经元的时间步。权重![]() 表示编码器神经元的第i个时间步输出,对解码器第j个时间步输出的贡献。为了让这些权重具有较好的数学性质,同时可解释性强一点,一般会用softmax或softmax回归层,保证它们的总和为1(这样看起来就像概率分布)。
表示编码器神经元的第i个时间步输出,对解码器第j个时间步输出的贡献。为了让这些权重具有较好的数学性质,同时可解释性强一点,一般会用softmax或softmax回归层,保证它们的总和为1(这样看起来就像概率分布)。
这几个权重合起来,就是图3-1中的一维向量![]() 。
。
函数g是一个模型,可以是一个多元线性回归模型,可以是一个输出维度为1的神经网络,也可以是其他结构。显然,这个模块的引入增加了整个模型的参数规模。
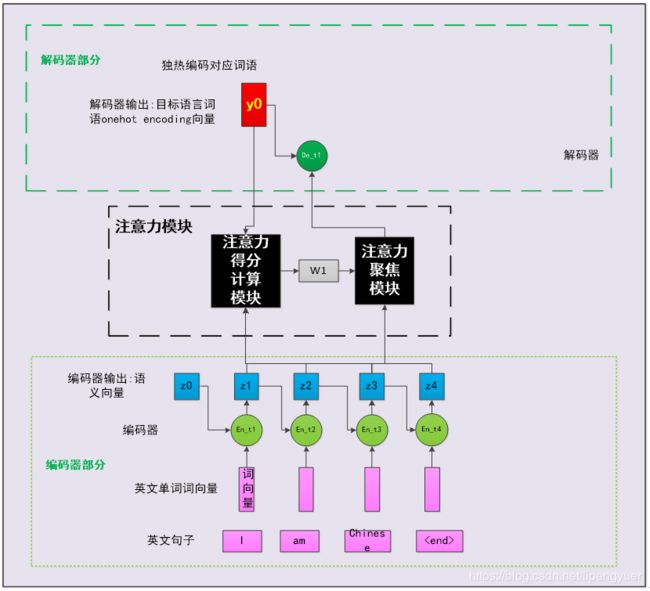 图3-2 注意力机制与解码器合作计算第一个时间步的输入
图3-2 注意力机制与解码器合作计算第一个时间步的输入
接下来,注意力聚焦模块,会基于![]() 来对编码器的输出进行加权求和,得到解码器当前时刻的输入:
来对编码器的输出进行加权求和,得到解码器当前时刻的输入:
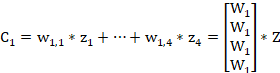
然后解码器神经元就可以基于历史输出和当前时间步输入,得到当前时间步的输出:
![]()
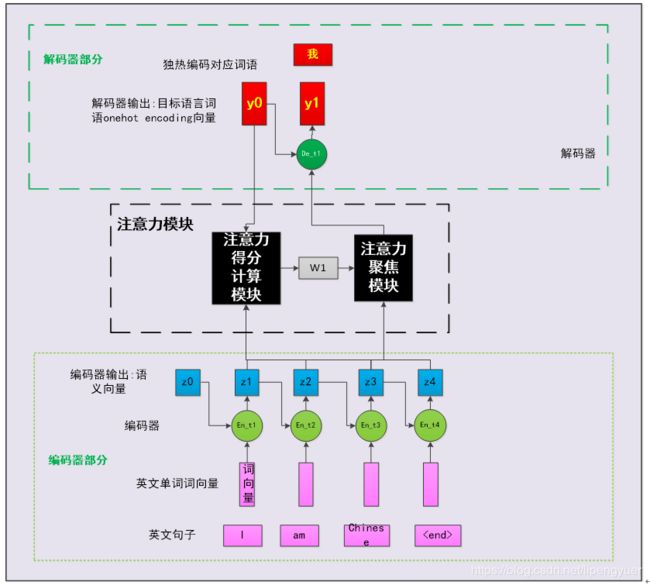 图3-3解码器基于注意力模块的输出和上一个时间步输出,计算当前时间步输出
图3-3解码器基于注意力模块的输出和上一个时间步输出,计算当前时间步输出
接下来,我们可以重复前面的操作,直到解码器输出终止符”
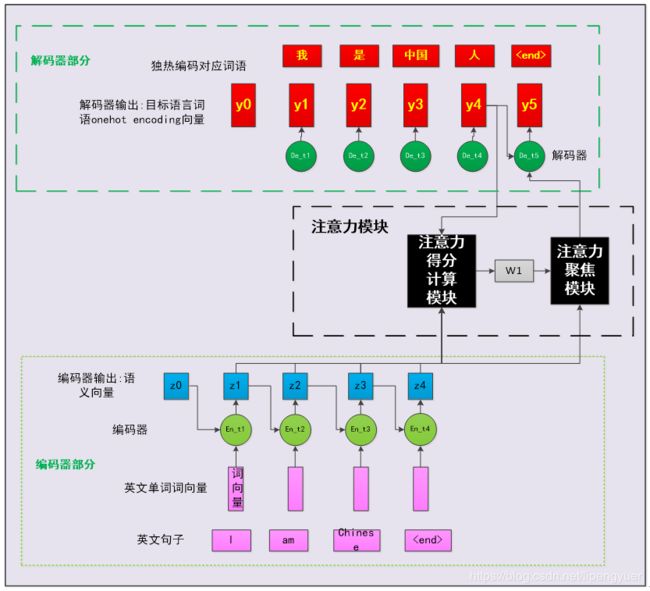 图3-4带有注意力机制的seq2seq结构
图3-4带有注意力机制的seq2seq结构
3.3从翻译的角度看,注意力模块干了什么?
现在,我们回过头来看看注意力模块干了什么。注意力模块实际上是我们嵌入到经典seq2seq中的一个小模型,在翻译模型的训练阶段,它负责学习编码器输出的隐藏状态序列Z,与解码器当前要预测的![]() 输出的关系密切程度。
输出的关系密切程度。
问题来了,我如何在不知道![]() 是啥的情况下,考察它和一堆数据的相关性呢?当然不能。这是符合常识的:人在翻译的时候,在决定目标文本的某个词语时,会基于原文本的句法和语义,以及已确定的目标文本片段,从大脑的词汇表中找一个候选词语集合,然后在候选集中选一个最佳词语。
是啥的情况下,考察它和一堆数据的相关性呢?当然不能。这是符合常识的:人在翻译的时候,在决定目标文本的某个词语时,会基于原文本的句法和语义,以及已确定的目标文本片段,从大脑的词汇表中找一个候选词语集合,然后在候选集中选一个最佳词语。
有思路了,让解码器基于自身历史输出(已确定的目标文本片段),来计算![]() 与
与 ![]() (源文本语义向量序列)的相关性。这就是注意力模块真正在做的事情。
(源文本语义向量序列)的相关性。这就是注意力模块真正在做的事情。
3.4注意力机制的设计是灵活的
注意力机制本质上就是嵌入到原有模型的一个小模型,具体结构是可以灵活设计的。比方说,我们可以用一个如图3-5的神经网络来作为注意力模块。我们可以把![]() 和
和![]() 拼接成一个较长的一位向量,然后输入到一个”一层感知机+多元线性回归”结构,来计算
拼接成一个较长的一位向量,然后输入到一个”一层感知机+多元线性回归”结构,来计算![]() 对解码器当前时间步输出的贡献大小。而
对解码器当前时间步输出的贡献大小。而
![]()
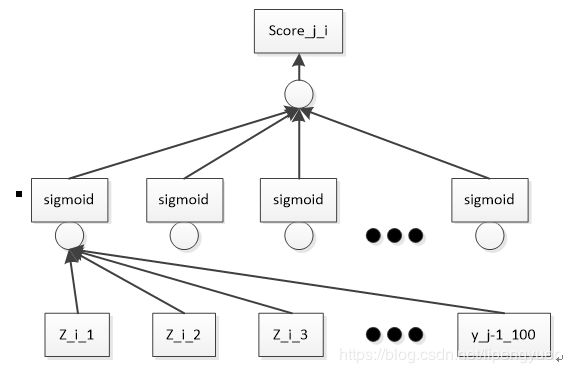 图3‑5 一个简单的注意力机制模块的核心结构
图3‑5 一个简单的注意力机制模块的核心结构
3.6自注意力机制
某些情况下,我们希望对英文句子的句法结构和语义有更清晰的认识,我们主要关注的是英文单词之间的相关性,就会采用一种叫做自注意力机制的版本。这时。在自注意力机制中,我们会计算编码器的输出![]() 与各个时间步的输出的相关性:
与各个时间步的输出的相关性:
![]() 是的,它就是这么simple。当然了,高玩们在这个基础上发展出了一大堆精妙或者复杂的注意力机制形式,效果各有千秋。
是的,它就是这么simple。当然了,高玩们在这个基础上发展出了一大堆精妙或者复杂的注意力机制形式,效果各有千秋。
相比经典注意力机制,自注意力机制不再依赖解码器的输出。这样的话,我们就可以想象:撤掉解码器,换成多层感知机之类的东西,我们就可以做分类等其他类型的任务啦。
4结语
最近在看哈工大计院李治军老师的课程(https://www.bilibili.com/video/av51437944?p=13)时,听到了一些关于学习方法的内容,感觉挺有道理。他认为,任何一个人造复杂系统的出现,都有一个过程,即以简单系统的形式出现,然后逐渐发展,最终成为比较复杂、越来越复杂的系统。我们在学习或者设计一个复杂的东西时,可以想办法模拟这个事物的发展过程——从它最初、最简单的时候开始,逐渐增加其复杂度。这样,我们不仅可以相对轻松地完成学习或设计任务,还可以体会和提升自己的智慧。以本文所述的注意力机制为例,要想搞明白其基本原理还是是比较费力气的。一个比较友好的学习策略是:回忆没有注意力机制的经典模型,思考它们的窘境,然后引出注意力机制救场。这样的话,我就是在经典seq2seq结构的基础上做探索了,相对轻松一些。
学习过程中,遇到瓶颈是常有的事,这时候需要想办法脱困,比如换个思路或者借用别人的思路。在整理注意力机制相关知识的过程中,有那么几天,我隐约感觉自己所理解的东西有较大的错误,但是又确定不了哪里有错(主观上懒得再进一步,客观上确实是没学明白)。于是我在同事微信群群里弱弱地问了一句:”大家是如何看待注意力机制的?”这招抛砖引玉是有效果的,大家纷纷发言:姚光南同志提到了“维度不变”这个特点;吕少松同志提到了“在有意识的区域内采用注意力机制”;许达同志提到了“在家办公不用钉钉打卡”。这几个方面是我之前没有考虑到的,这下算是打消了好几个疑惑点,之后的学习就容易很多了。
注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即https://zhuanlan.zhihu.com/p/105335191。如有疑问,可发邮件至我的邮箱:[email protected]。