PHP高级工程师面试题
准备
- 自我介绍:说上家公司负责的项目或者浓缩简历。
-
简历(最优.pdf格式)项目经验层次
- 项目背景
-
利用什么技术
- 面向(对象oop,切面aop)
- 设计模式(代理、工厂、单例)
- xx模块(socket,pdo,多进程)
- 中间件(codis,Mycat)协程
- 消息队列(RabitMq、Kafka)
- 容器及容器编排
- 底层(框架原理OR ZendVm)
- 实现了什么功能
- 遇到什么问题及解决方案
- 达到了什么结果(尽量量化,比如减少了多少成本)
- 项目周期及你的职责、角色
- 期望薪资
- 应用型的问题:要记得站高看远、架构分层
- 涉及管理经验及自身对相项目管理的理解
- 只是在人群中多看你了你眼~
知识点列表
一、Redis
-
redis(这块说的太乱了,回头我好好整理下~)
-
应用场景
- string:cache,incr(此时redisObject encoding为int)
- hash :key为key,value为Hashmap(少时用redisObject encoding ziplist OR 增大时为ht)
- set:去重(中奖只一次sismember),交,并,差(如微博社交关系),内部实现为value为null的hashmap
- zset: 或者叫sorted set。既去重又能保证按照score排序,比如按照帖子的关注个数排序,value为帖子id,个数为score。面试中常问其实现机制(跳跃列表(skiplist):用多个指针分层串起来+hashmap(本身hashmap无法进行二分查找,所以必须加持skiplist机制)),另外还有一个应用可以是消息优先级。
- list:(阻塞rpop)消息队列、列表旋转(常用于监控,rpoplpush)
- HyperLogLog:大量统计(非精确)
- bitmaps
-
内部数据结构
-
- 一图先胜个千言↓

- dict:底层数据库和hash结构都是key[ redis string obj] AND value [redis obj]组成的,其中 string是redis通过内部封装的SDS结构体实现,而value五种object对应redis中常见的五种数据类型。了解了dict是掌握redis数据结构的前提,见下图↓:

-
Hash:dictht->dickEntry,dict是对dictht结构再次封装。装拉链法(单向链表)解决冲突(同php),采用头插的方法;装载因子(哈希表已保存节点数量 / 哈希表大小)超过预定值自动扩充内, 引发(增量式|渐进式)rehash
- 根据ht[0]创建一个比原来size大一倍(也可能减少)的hashtable,
- 重新计算hash和index值,根据rehashindex逐步操作
- 到达一定阈值(ht[0]为空)操作停止
-
期间响应客户端
- 新增写操作:新增的写到新的ht[1]
- 删除、查找、更新操作:先读ht[0],再读ht[1]
-
sds:simple dynamic string
- string的底层实现为sds,但是string存储数字的时候,执行incr decr的时候,内部存储就不是sds了。
- 二进制安全binary safe(5种类型的header+falgs得到具体类型,进而匹配len和alloc)
-
robj:redis object,为多种数据类型提供一种统一的表示方式,同时允许同一类型的数据采用不同的内部表示,支持对象共享和引用计数。
- sds
- string
- long
- ziplist
- quicklist
- skiplist
-
typedef struct redisObject { unsigned type:4;//OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH unsigned encoding:4/*上述type的OBJ-ENCODING _XXX常量,四个位说明同一个type可能是不同的encoding,或者说同一个数据类型,可能不同的内部表示*/; unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr//真正指向的数据; } robj
-
-
OBJ_ENCODING_
-
string
- OBJ_ENCODING_RAW,代表sds ,原生string类型
- OBJ_ENCODING_INT,long类型
- OBJ_ENCODING_EMBSTR ,嵌入
-
OBJ_HASH
- OBJ_ENCODING_HT,表示成dict
- OBJ_ENCODING_ZIPLIST,hash用ziplist表示
-
OBJ_SET
- OBJ_ENCODING_INTSET,表示成intest
-
config
- set-max-intset-entries 512【是整型而且数据元素较少时,set使用intset;否则使用dict】
-
OBJ_ZSET
-
OBJ_ENCODING_SKIPLIST,表示成skiplist
- 思想:多层链表,指针来回查找,插入和更新采取随机层数的方法来规避
-
config
- zset-max-ziplist-entries 128
- zset-max-ziplist-value 64
-
-
OBJ_LIST
- OBJ_ENCODING_QUICKLIST
-
config
- list-max-ziplist-size -2
- list-compress-depth 0
-
-
内部结构实现(针对上面的再‘翻译一下’)
- string
-
hash(两种encoding,根据下面的config)
- ziplist
- dict
-
config
- hash-max-ziplist-entries 512【注意单位是“对儿”】
- hash-max-ziplist-value 64【单个value超过64】
-
list
- quicklist
- 定义:是一个ziplist型的双向链表
- 压缩算法:LZF
-
扩展问题:
-
zset如何根据两个属性排序?比如根据id和age
- 可以用位操作,把两个属性合成一个double
- 用zunionstore合并存储为新的key,再zrange
-
redis是如何保证原子性操作的?
- 因为他是tm单线程的!(ps:mysql是多线程)
- 在并发脚本中的get set等不是原子的~
- 在并发中的原子命令incr setnx等是原子的
- 事务是保证批量操作的原子性
-
主从复制过程:
- 从服务器向主服务器发送sync
- 主服务器收到sync命令执行BGSAVE,且在这期间新执行的命令保存到一个缓冲区
- 主执行(BGSAVE)完毕后,将.rdb文件发送给从服务器,从服务器将文件载入内存
- BGSAVE期间到缓冲区的命令会以redis命令协议的方式,将内容发送给从服务器。
-
-
特性:
- 单线程,自实现(event driver库,见下面四个io多路复用函数)
- 在/src/ae.c中:宏定义的方式
-
/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */ #ifdef HAVE_EVPORT #include "ae_evport.c" #else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif - io多路复用,最常用调用函数:select(epoll,kquene,avport等),同时监控多个文件描述符的可读可写
- reactor方式实现文件处理器(每一个网络连接对应一个文件描述符),同时监听多个fd的accept,read(from client),write(to client),close文件事件。
-
备份与持久化
-
rdb(fork 进程dump到file,但是注意触发节点的覆盖问题,导致数据不完整)
- 手动: save (阻塞) & bgsave(fork 子进程),但是这两个不会同时进行(避免竟态条件)
- 自动触发:
conf:save 900 1 save 300 10 save 60 10000 dbfilename dump.rdb - rdb优点:对服务进程影响小,记录原数据文件方式便于管理还原
- rdb缺点:可能数据不完整
- rdb为非纯文本文件,可以用od -c dump.rdb分析
-
aof(类似binlog)
-
三种写入同步方式
- appendfsync no
- appendfsync everysec(每个事件循环写入缓冲区,但是每隔一秒同步到磁盘文件)
- appendfsync always (每执行一个命令,每个事件循环都会执行写入aof 缓冲区并同步到磁盘文件,效率最慢,但是最安全)
- aof优点:数据最完整,可以通过数据重写rewrite来减少体积,存储内容为redis的纯文本协议
- aof缺点:文件相对rdb更大,导入速度比rdb慢
- 一般有了aof就不rdb,因为aof更新频率更高
-
-
-
过期策略:
- 定时过期:时间到了立即删除,cpu不友好,内存友好。
- 惰性过期:访问时判断是否过期:cpu友好,内存不友好
- 定期过期:expires dict中scan,清除已过期的key。cpu和内存最优解
-
内存淘汰机制
-
127.0.0.1:6379> config get maxmemory-policy 1) "maxmemory-policy" 2) "noeviction" - noeviction:新写入时回报错
- allkeys-lru:移除最近最少使用的key
- allkeys-random:随机移除某些key
- volatile-lru:设置了过期时间的key中,移除最近最少使用
- volatile-random:不解释
- volatile-ttl:设置类过期时间的键中,有更早过期时间的key优先移除
-
-
redis队列特殊关注(可能坑)之处
-
队列可能丢东西
- 比如redis挂了,producer没有停止,但是队列数据无法写入(除非同步落地到mysql)
-
队列的consumer 需要手动处理commit协议
- 如果consumer处理完,表示真正完成
- 如果没有处理完?放回队列?直接丢弃?
-
事件重放机制不支持
- 比如consumer消费错了,那能不能将队列回放呢再次处理呢?
-
队列最大长度及过期时间
- 如果producer远大于consumer,撑爆了怎么办
- 如果comsumer 一直没有处理,producer的数据如何处理
- exactly once
- 单机锁
sennx或者基于set众多参数没问题,集群下可利用tag机制 - 如何保证业务执行时间超过锁的过期时间,而引起误删除操作。答案是可以加一个唯一标识
-
-
vs memcache
-
memcached
-
优势
- 多线程(listen & woker),利用多核
- round robin
- cas(check and set,compare and swap)
-
劣势
- cache coherency、锁
- key大小有限制(1M)
-
特点
- 内存预分配:slab+trunk
-
-
redis
-
优势:
- 自己封装了一个AEEvent(epoll+select+kqueue),io多路复用
- 丰富的数据结构(对内+对外)
- 良好的持久化策略(rdb +aof)
- 单机可部署多实例,利用多核
-
劣势:
- 排序、聚合cpu密集操作会等影响吞吐量
- key 大小最大为1g
-
-
-
more | other
-
- redis ziplist与普通双向链表的区别:普通的链表每一项都占用独立的一块内存,各项之间用地址指针(引用)连接起来,这样会导致大量碎片。而ziplist是将表中每项放在前后连续地址空间内,而且对值存储采取变长编码。
- redis msetnx对应的del,可以采取lua脚本保证get del的原子性
-
redis 单线程如何实现阻塞队列?
- 阻塞是阻塞client,又不是阻塞server,server不发数据,client不就阻塞住了,当client想要阻塞在某个key上,server会把这个client放到一个block list里,等key发生变化,就send数据给client。
-
redis 阻塞队列的时间设置实现?
- blocklist里只存了列表,这个timeout存在连接上,靠serverCron来遍历检测,每次遍历5个,
- 高性能的方案是小堆或者红黑树或者时间轮实现的定时器结构,epoll wait那块timeout参数就设置成下次超时时间
- 每次poll loop里除了处理io事件,再把定时器的数据结构里处理下,堆和红黑只要检测到一个未超时就可以break了,时间轮这是当前槽都触发了就行
- 每次检测5个这种比较折中,因为他场景不是大量并发的服务器,rds cli的连接数量毕竟使用者内部可控,而且不需要精确打击,只要保障相对能及时清理就行,redis的网络部分相对比较简单,业务场景可控,足够了
- redis集群情况下如何做到两个key必hash到一个节点?用{}
-
redis 事务机制
- 基于乐观锁的watch multi exec
- redis call lua脚本(比如get+del一起)
- 2.6.12后set命令支持(setnx+expire就不需要写lua script了)
- redis 下的分布式锁,当主从不同步或者主重新被选举需要多想想,主从情况下一般采用从节点的大多数(es也是这样)
-
redis 主从哨兵配置,copy三份redis.conf文件,以下设置一主二从一哨兵
vim redis01.conf port 63791 vim redis02.conf port 63792 slaveof 127.0.0.1 63791 vim redis03.conf port 63793 slaveof 127.0.0.1 63791 vim sentinel.conf daemonize yes port 26379 sentinel monitor mymaster 127.0.0.1 63791 1 // mymaster为自定义命名,127.0.0.1 63791为master,1为选举主节点的时候投票数目的同意个数,1代表有一个哨兵同意就行。
-
redis cluster集群
- 集群会将数据自动按照算法分割在不同节点负责的槽上(data sharding)
- redis cluster官方文档简洁明了啦
二、MySql
-
mysql
-
索引
-
物理存储
- 聚簇索引
- 非聚簇索引
-
数据结构
- B+树
- hash
- fulltext
- R-tree
-
逻辑角度
- 唯一索引 unique
- 普通索引index
- 主键索引 primary key
- 全文索引 full index(myisam)
-
复合索引 (最左前缀原则)
- 类似 where a and b and c a b c 问题
- 联合索引(a,b,c) 能够正确使用索引的有(a=1), (a=1 and b=1),(a=1 and b=1 and c=1)(b=1 and c =1
-
-
引擎类型
- myisam
- innodb
-
区别:
- myisam采用非聚集索引,innodb采用聚集索引
- myisam索引myi与数据myd文件分离,索引文件仅保存数据记录指针地址。
- myisam的主索引与辅助索引在结构上没区别,而innodb不一样:innodb的所有辅助索引都引用主索引作为data域。
- innodb支持事务,行级锁。myisam不行。
- innodb必须有主键,而myisam可以没有。
-
相同点:
- 都是b+tree 索引
-
存储
-
innodb

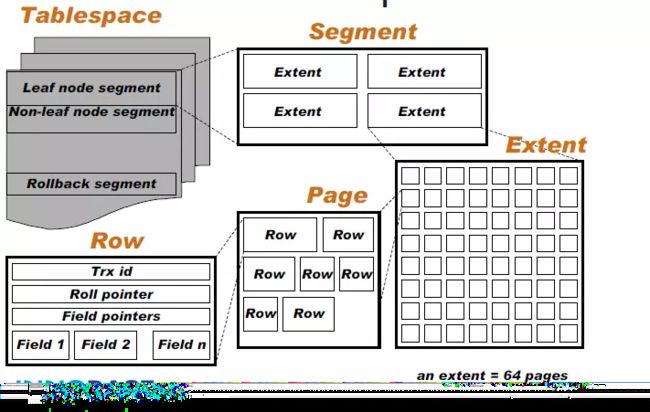
- 数据被逻辑的存在tablespace,extend(区)中有多个page,page(默认16kb)里放row(每一行,大概每个page放2-200行记录)
- .frm:table's format
- .ibd:table data & associated index data
- ubunut的frm文件和ibd文件可在目录
root@udev:/var/lib/mysql# ls中查看,下图为innodb行格式,由下到上,均向上兼容 -

-
Antelope 羚羊 对存放bolb或者大varchar存储极长的数据时,将行数据的前768字节存储在数据页中,后面通过偏移量指向溢出页。
- compact 紧凑的
- redundant 多余的
-
Barracuda 梭鱼
- antelope对存放blob的数据完全溢出,在数据页中只存在20个字节的指针,实际数据放在bolb page
- compressed
- dynamic
- more
-
-
myisam
- frm(与innodb通用),在磁盘的datadir文件
- myi
- myd
-
-
事务
- 原子性atomicity
- 一致性consistency
- 隔离性lsolation
- 持久性durability
-
分表数量级
- 单表在500w左右,性能最佳。BTREE索引树 在3-5之间
-
隔离级别
- 事务的隔离性是数据库处理数据的基础之一,隔离级别是提供给用户在性能和可靠性做除选择和权衡的配置项目,以下四种情况都有一个前提(在同一个事务中)
- 1.read_uncommited:脏读,未提交读。不加任何锁,能读取到其他会话中未提交事务修改的数据,主流数据库几乎没有这么用。的见下图

- 2.read_commit:RC,不可重复读,已提交读。注意这个与1的区别是,读取不加锁,但是数据的写入、修改和删除是需要加锁的,而1是啥锁都不加。啥都不加。只对记录加记录锁,而不会在记录间加间隙锁。所以允许新的记录插入到被锁定记录的附近,所以多次使用查询语句时,可能得到不同的结果,non_repeatable_read,见下图,第二个事务修改了id=1的数据后,第一个事务再次读取的时候结果不一样。这就是不可重复读,即两次结果不一样。

- 3.repeatable_read【默认级别】:RR,可重读,幻读,返回第一次的查询的快照(不会返回不同数据)。虽然事务2提交了更改,但是事务1仍然读到的是事务2未修改的状态。见下图

- 4.serialize:解决了幻读,可串行化。幻读和可重复度读的区别在于导致幻读的是其他事务的insert。这样会引起第一个事务莫名其妙的多出来一条数据。幻读主要是依靠读锁写锁相互独立(互斥),但是会极大的降低并发能力。
-
索引机制(算法)
- hash
-
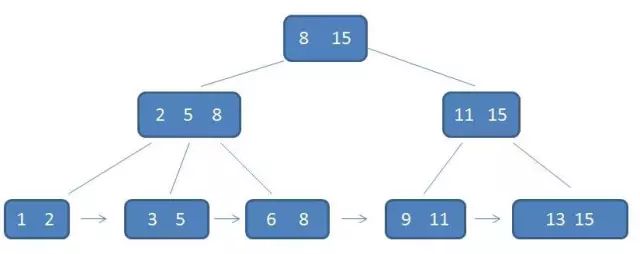
b+tree(m阶b+tree)
-
- 所有数据保存在叶子节点,有k个子树的中间节点包含有k个元素
- 所有叶子节点包含了全部的元素信息,及指向这些元素记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接
- 所有的中间节点元素都同时存在于子节点,在子节点元素中都是最大(或最小)元素(或者说:每一个父节点的元素都出现在子节点中,是子节点的最大或者最小元素)
- 插入的元素,要始终保持最大元素在根节点中,再次说:所有的叶子节点包含了全量元素信息。每个叶子节点都带有指向下个节点的指针,形成了有序链表
-
b-tree【不要念成b减tree,-只是个符号】
- 内存操作(单一节点数量很多时,注意并不比二叉查找树数量少,只是速度比硬盘要快)
- 自平衡
- 左旋、右旋
- mongoDB用的是balance tree
-
特点(m阶的B树)
- 根节点至少有两个子女
- 每个中间节点都包括k-1个元素和k个孩子(m/2<=k<=m)
- 每个叶子节点都包括k-1个元素,(m/2<=k<=m)
- 所有的叶子节点位于同一层
- 每个节点中的元素从小到大排序,节点当中k-1个元素正好是k个孩子包含元素的值域划分
-
b+与b-区别
- b+中间节点没有卫星数据,而b-tree有卫星数据(可以理解为key+data的二维数组),所以前者同样大小可以容纳更多的节点元素。这样又导致了b+比b更“矮胖”,更进一步减少了io查询次数。很好的解释了下面这句话:在cluster index(聚集索引中),叶子节点直接包含卫星数据;在非聚集索引中nonclustered index中,叶子节点带有指向卫星数据的指针。
- b-只要查找到匹配元素,直接返回,网络匹配元素处理中间节点还是叶子节点。而b+查询必须查找到叶子节,相对于b-,b+无需返回上层节点重复遍历查找工作,所以得出b-查找并不稳定,而b+是稳定的,b+树通过双向链表将叶子节点串联起来,基于空间换时间。目的就是支持倒叙和顺序查询。
- 针对范围查询,b-需要n次中序遍历,而b+只需要通过子节点链表指针遍历即可。
-
-
锁
-
种类
- optimistic lock乐观锁(并非真正的锁,是基于版本号基础的先尝试再更改,loop and try)
- 特点:不会真死锁,一定条件下有较高的冲突频率和重试成本,但是相对悲观可以有更好的并发量
-
pessimistic lock悲观锁
- 为了保证事务的隔离性,就需要一致性锁定读。读的时候要加锁,防止其他事务再次更改,修改的时候也要加锁,其他事务无法读取。主要就是依靠数据库的锁机制来实现,同时缺点很明显,就是会带来性能的开销,并发的减少。
-
innodb的MVCC(Multi-Version Concurrency Control)
- 翻译成中文叫心理医生 ,多版本并发控制,适用于行锁的、事务性的数据库模型。
- 适用于innodb的rc和rr级别,因为可串行化涉及到锁表
- 实现思想是在每行增加一个create_verison和delete_version字段
- update 是插入一个新行,先保存当前版本号到旧行的delete_version,且新建行的new_create_version也就是delete_version
- delete操作就是直接标记delete_version
- insert的时候,就是保存至create_version
-
selete的时候可以这样
- 读delete_version为空的
- 大于当前事务版本号的
- 创建版本号<=当前事务版本号的
-
粒度划分
- 行锁
- 表锁
-
意向锁 intention lock(表级锁)
- 场景:A对表中一行进行修改,B对整个表修改。如果没有以下的两个锁,B将对全表扫描是否被锁定。反之,A可以对某行添加意向互斥锁(表级),然后再添加互斥锁(行级),然后B只需要等待意向互斥锁释放)
- 意向共享锁
- 意向互斥锁
- 共享锁shard lock 读锁(行锁)
- 排它锁exclusive lock 写锁(行锁)
-
关于innodb必须要知道的
- 可以通过
SELECT \* FROM products WHERE id='3' FOR UPDATE进行锁,但是必须在事务中 - 上述语句必须是命中索引才会行锁,否则是table lock
- 可以通过
-
锁的算法
- record lock:加到索引记录上的锁,如果通过where条件上锁,而不知道具体哪行,这样会锁定整个表
- gap lock:间隙锁某个区间的锁定,对索引记录中的一段连续区域的锁。
- next-key lock:行锁和GAP(间隙锁)的合并,next-key锁是解决RR级别中 幻读问题的主要方案。可以搜索关键字 快照读(snapshot read)和当前读(current read)去了解~
- 死锁:

- 注意区分 deadlock VS lock wait timeout
-
- 分库分表
- 主从
- ACID
-
覆盖索引(复合索引)
- 定义:包含两个或多个属性列的索引称为复合索引。如果查询字段是普通索引,或者是联合索引的最左原则字段,查询结果是联合索引的字段或者是主键。这种就不必通过主键(聚集索引再次查询)
- 目的:减少磁盘io,不用回表
- b+树索引
-
聚集索引cluster index 一般为primary key
- 定义:按照每张表主键构建一棵B+TREE,叶子节点放的整张表的行记录数据
- 与之相对应的是辅助索引(secondary index)
- innodb存储引擎支持覆盖索引,即从辅助索引中可以查到查询记录,而不需要查询聚集索引中的记录。
- b平衡树+树索引

- 上图对应的表结构:
-
CREATE TABLE users( id INT NOT NULL, first_name VARCHAR(20) NOT NULL, last_name VARCHAR(20) NOT NULL, age INT NOT NULL, PRIMARY KEY(id), KEY(last_name, first_name, age) KEY(first_name) - 一张表一定包含一个聚集索引构成的b+树以及若干辅助索引构成的b+树
- 每次给字段建一个索引,字段中的数据就会被复制一份出来。用于生成索引,(考虑磁盘空间)。不管何种方式查表,最终都会利用主键通过聚集索引来定位到数据。聚集索引(主键)是通往真实数据的唯一出路。
-
辅助索引:非聚集索引都可以被称作辅助索引,其叶子节点不包含行记录的全部数据,仅包含索引中的所有键及一个用于查找对应行记录的【书签(即主键或者说聚集索引)】,下面两个图为辅助索引(first_name,age)以及通过主键再次查找的过程
- 联合索引:与覆盖索引没有区别,或者理解为覆盖索引是联合索引的最优解(无需通过主键回表)。
-
explain
-
extra
- using index :condition(用了索引,但是回表了)
- using where :uning index(查询的字段在索引中就能查到,无需回表)
- using index condition:using filesort(重点优化:表明查到数据后需要再进行排序,尽量利用索引的有序性。)
- using where:using index
-
type(连接类型:join type),以下逐步增大
- system 系统表,磁盘io忽略不计(有些数据就已经在内存中)
- const 常量连接(加了where条件限制,命中主键pk或者唯一unique索引)
- eq_ref 主键索引或者非空唯一索引、等值连接;如果把唯一索引改为普通索引+等值匹配,可能type只为ref,因为可能一对多
- range 区间范围 between and;where in,gt lt;(注意必须是索引)
- index 索引树扫描,即需要扫描索引上的全部数据,比如innodb的count
- all 全表扫描
- select * 与索引(看主要命中条数与总条数,如果相近,用不到索引,就全回表了,如果是一定范围,那就是range use indexcondition)
- rows(粗略统计,不是精确)
-
-
其他:
- varchar为啥为65535?compact行记录的第一个字段为变长字段长度列表,为2个字节16位。参考
- 一个表最多多少行?1023,具体也是看行格式的数据结构即可,参考上文的参考链接。
- 为什么建议给表加主键?主键的作用是把数据格式转为索引(平衡树)
- 联合索引在b+树中如何存储?
- 为什么索引不直接用二叉查找树,要用b树,b+树?主要考虑减少磁盘io(考虑磁盘物理原理及局部性与磁盘预读的特性:)
- myisam和innodb必须有主键吗?innodb必须有,数据文件需要按照主键聚集,如果没有innodb会自动生成。
- mysql 最大连接数默认多少(max_connections)?答案是151。(这里可以引申到php-fpm的pconnect相关问题)


三、算法&数据结构
- 最小堆:根节点为最小值,且节点比其他孩子小
- 平衡树(avl 红黑树)
- 最大堆:根节点为最大值,且节点比其他孩子大
- sikplist
-
hash
- hash 碰撞原因
-
hash 碰撞解决方案
- 拉链,塞到链表里。优点是相对简单,但是需要附加空间(
想到了php max_input_vars) -
开放寻址,优点是空间利用率高,一直找..
- 线性探测
- 二次探测再散列函数
- 伪随机数
- 拉链,塞到链表里。优点是相对简单,但是需要附加空间(
- 给定数值n,判断n是斐波那契数列的第几项?写算法
- 反转列表如A->B->C->D 到A->D->C->B
- 插入排序
- 数组与链表区别与联系
-
链表操作
-
单链表删除
p->next=p->next->next; if(head->next===null){ head=null } -
单链表插入
new_node->next=p->next; p->next=new_node if(head===null){ head=new_node; }- 快慢指针判断环路、找链表中点(注意奇偶)
-
-
应用问题
- 如何实现一个LRU功能?【双向链表】
- 如何实现浏览器前进后退功能?【两个栈】
四、设计模式
-
设计模式
-
单例模式 (static ,consturct)
static private $instance; private $config; private funciton __construct($config){ $this->config=$config; } private funciton __clone(){ } static public function instance($config){ if(!self::$instance instanceof self){ self::$instance=new self($config); } return self::$instance; } } -
简单工厂(switch case include new return )
{ public function makeModule($moduleName, $options) { switch ($moduleName) { case 'Fight': return new Fight($options[0], $options[1]); case 'Force': return new Force($options[0]); case 'Shot': return new Shot($options[0], $options[1], $options[2]); } } } # 使用工厂方式 001 class Superman { protected $power; public function __construct() { // 初始化工厂 $factory = new SuperModuleFactory; // 通过工厂提供的方法制造需要的模块 $this->power = $factory->makeModule('Fight', [9, 100]); // $this->power = $factory->makeModule('Force', [45]); // $this->power = $factory->makeModule('Shot', [99, 50, 2]); /* $this->power = array( $factory->makeModule('Force', [45]), $factory->makeModule('Shot', [99, 50, 2]) ); */ } } # 使用工厂方式 002 class Superman { protected $power; public function __construct(array $modules) { // 初始化工厂 $factory = new SuperModuleFactory; // 通过工厂提供的方法制造需要的模块 foreach ($modules as $moduleName => $moduleOptions) { $this->power[] = $factory->makeModule($moduleName, $moduleOptions); } } } // 创建超人 $superman = new Superman([ 'Fight' => [9, 100], 'Shot' => [99, 50, 2] -
门面模式
- 对客户屏蔽子系统组件,减少子系统与客户之间的松耦合关系
- 依赖注入(DI)与AOP思想
-
五、正则表达式
-
正则表达式
-
应用场景
- 范匹配
- 模版引擎
- 词法分析器(lex)
- 常见正则
-
六、PHP
-
php
-
代码解释过程(大多的非编译语言)
- lexical词法分析,输入为源代码,输出为token
-
语法分析 工具为文法(LALR),输出为表达式,7.0为AST,涉及:
- 注释
- 分号 & 分隔符
- 变量
- 常量
- 操作数
-
类型检查、关键字处理、导入,输出为中间代码。工具为选定的的编译器优化工具
- 中间代码生成(Opcodes)
- 机器码生成(编译语言)
- session共享配置
- phpunit用法
- cookie购物车和session购物车的实现
- 弱类型实现
-zval(不仅是变量名) & zend_val变量值 -
代码规范
- 自动化:sonarquebe+jenkins
- 单元测试
-
php进程间如何通信
- 信号量(消息同步|互斥)(pv操作) sem_*
- 信号(信号触发事件)(pcntl_signal, pcntl_wait*)
- 消息队列 msg_*
- 管道(pipe)
- socket |unix _*.sock
- 共享内存(shm_,shmop_)
- php并发模型
- php执行流程

- 变量底层存储结构
-
常用的数组函数(列出10个)
- array_combine(前面数组作为其键,后面数组做为其值)
- array_merage(合并两个数组,后面覆盖前面,但数字索引会重新索引,不会覆盖)
- array_multisort
-
php垃圾回收机制(gc)
- zend.enable_gc
php.ini - gc_enable()
funciton - 引入计数(zval指向zend_value个数为0时)+写时拷贝(copy on write)
- 循环引用问题(array、object引用自身成员),垃圾回收器将其收集至于一个buffer(_zend_gc_global->gc_root_buffer)后启动垃圾鉴定程序
- zend.enable_gc
-
把session放入redis里面还会触发类似文件的state session
- session.gc_probability (default 1)
- session.gc_divisor (default 100)
- session.gc_maxlifetime(单位秒)
- session.cookie_lifetime(单位秒,0表示直到关闭浏览器)
- session.save_path,如果你真的想实现不同应用目录分层,一定去找下面这个文件(大概率不会有这种需求)

- session_write_close (显示关闭,后期使用需要显示开启)
- 说明:因为php的语言特性,针对session的gc只能是session模块启动的时候去执行。默认的概率为1%,另外默认所有的站点都是在一个目录下,如果多站点在同一目录设置了不同的session时间,gc不会区分站点。只按照当前时间-文件创建|更新时间是否大于gc_maxlifetime来判断。当然现在一般都放到redis实现了sessionhander接口,就不用gc了。(Not necessary, Redis takes care of that.
-
内存模型
- 整型、浮点、bool、NULL、内部字符串、不可变数组都是通过zval直接保存,不会用到引用计数
- string、array都会使用引入计数(支持复制cow),object、resource本身可以理解为引用
-
fpm三种配置及场景
-
dynamic
- pm.start_servers
- pm.max_children
- pm.max_spare_servers
- pm.min_spare_servers
-
static
- pm.max_children
-
ondaemon
- pm.process_idle_timeout
-
-
数组底层
- 如何保证有序:又加了一层映射表(与bucket大小相同)
- 如何解决hash冲突:拉链法(头插)
- 扩容:逻辑删除(考虑unset内存情况、是否需要重建索引)
-
fpm状态查看
curl localhost/php_fpm-status pool: www process manager: dynamic start time: 13/May/2017:09:50:43 +0800 start since: 986 accepted conn: 2 listen queue: 0 max listen queue: 0 listen queue len: 0 idle processes: 1 active processes: 1 total processes: 2 max active processes: 1 max children reached: 0 slow requests: 0
-
七、操作系统
-
操作系统
- 多线程
- 多进程
- 协程的理解
- socket和管道的区别
-
进程间通信手段
- 共享内存
- rpc
- 管道
-
线程间通信手段
- 读写进程数据段
八、网络协议
-
网络协议
-
http
- 构成:起始行(GET =>200),首部头 (ACCEPT=>CONTENT-TYPE),主体 name =》tongbo
-
版本:
- 1.0
- 1.1
- 2.0 :多路复用、流量控制
-
长连接
- 在一个连接上发送多个数据包
- 心跳、如何发送心跳
-
httpdns
- 定义:用http协议代替原始的udp dns协议,可以绕过运营商的local dns
- 解决问题:避免local dns造成的域名劫持问题和调度不精确问题(更多是在移动客户端)
-
其他解决方案
- 客户端dns缓存
- 热点域名解析
- 懒更新策略(ttl过期后再同步)
- post请求分割head 和body
-
get vs post:
-
get(
- 安全幂等,请求实体资源
- 参数只能url编码,且参数长度有限制
- 浏览器会自动加cache
-
post
- 附加请求实体于服务器
- 产生两个tcp数据包
- 数据支持多种编码格式
-
-
resultful
- get:获取资源
- post:新建资源
- put:更新完整资源
- delete:删除资源
- patch:更新部分资源
-
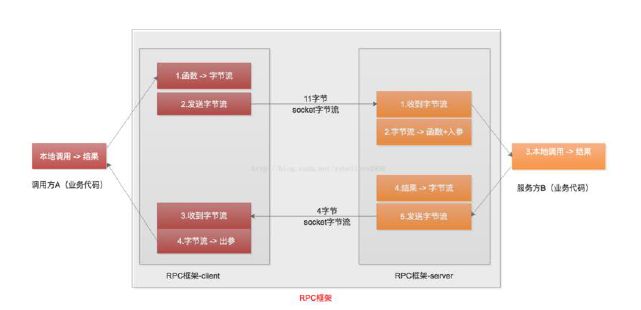
RPC
- 看张图↓
-
RPC框架涉及基本组件服务
- 客户端、服务端自动代码生成、多语言支持
- 消息序列化、反序列化
- 连接池、负载、故障、队列、超时、异步
-
常见协议
- soap(http |jsonrpc)
- GRPC:protocol buffer,(HTTP2 AND Tcp)
- thrift(tcp)
-
tcp
-
- 面向连接,先建立(握手),然后释放(挥手确认拜拜)
- 只能点对点
- 可靠交付(相对来说),全双工,接收和发送端都设有发送和接收cache
- 面向字节流(流:一连串,无结构的的信息流,流入到进程或从进程流出的字节序列,而一个报文段多少字节是根据窗口值和网络拥塞程度动态变化的)
-
释放:
- 客户端:FIN_WAIT 1,停止发送数据给服务端。等待服务端确认
- 服务端:ack ,进入CLOSE_WAIT(关闭等待),此时如果服务端有数据要发送,客户端还可以接收。
- 客户端收到服务端确认后,进入FIN_WAIT 2,等待服务器发出连接释放报文段。
- 此时如果服务端没有数据要发送,发送上步骤客户端等待的释放报文段,然后服务端进入LAST_ACK
- 客户端收到服务端的last_ack后,发出确认,进入TIME_WAIT,经过2MSL后,客户端关闭
- 服务端收到客户端报文段后,进入CLOSE
-
以下这张图明确的指出了syn、ack的交互及对应的转换状态,值得收藏!!
- 关于两个重要的队列:半连接队列syns-quene & 全连接队列accept quene,如下图

-
关于TIME_WAIT:
- time_wait是一种TCP状态,等待2msl可以保证客户端最后一个报文段能够到达服务器,如果未到达,服务器则会超时重传连接释放报文段。使得客户端、服务器都可以正常进入到CLOSE状态。
-
关于'粘包'
- 分包:在一个消息体或一帧数据时,通过一定的处理,让接收方能从字节流中识别并截取(还原)出一个个消息体。
- 短连接tcp分包:发送方关闭连接,接收方read 0,就知道消息尾了
-
长连接TCP分包:
- 消息长度固定or消息头中加长度字段
- 固定消息边界,比如http:rn
- 利用消息本身格式,如
xml,json
-
关于syn flood
- 基本思想:恶意像某个服务器端口发送大量SYN包,服务器会分配一个transmission control block,并返回ack。然后服务端转为syn-recv状态。系统保持这个资源
-
常见防攻击方法
- 入门级:系统监视半连开连接和不活动的连接。一视同仁,超过一个阈值后全部rst这些连接。
-
延缓tcp分配:当三次握手后再分配tcb,这样可以有效的减轻对服务器资源消耗(常见方法是使用syn cache,syn cookie)
-
syn cache
- 保存对应的序列号和报文(这里特指半连接)到hash表中,直到收到正确的ack报文再分配tcp
-
syn cookie
- 使用特殊算法生成sequence number,主要涉及到对方无法了解到的己方固定的一些信息(比如己方mss 时间等)。这样如果对方真的发送过来了ack报文,对其ack-1.如果相等,那么就分配这个tcb。没有或者不相等,那就不分配。
- syn proxy防火墙:我简单理解为是一层代理,中间有验证,或者涉及到序列号的修改。具体的不了解。。
-
-
-
特性协议
- 停等
- 超时重传
- 慢启动
- 滑动窗口
- 快速重传
-
udp
- 无连接、best effort、面向报文(不合并、不拆分,保留边界)
- 无拥塞控制、流量控制、首部开销小(8个字节,而tcp有20个首部)
- 支持一对一,一对多,多对一
- 自定义协议
- rpc

九、大前端
-
js
-
百度统计的实现
- 基于cookie,引入js脚本及baidu个人账户id,读取当前信息,适当节点发送请求给百度服务器
- 前后端分离 百度fis3
-
十、中间件
-
中间件
- rebbitmq
-
kafka
- 源自linkedin,用于处理活动流和运营数据。主要是同一消息为多个应用程序消费
- f分布式流处理,持久化,leader负责读写,follower负责数据同步,leader不可用后通过in-sync-replica来选择一个leader
- broker(服务器),其中producer发消息到brokder,consumer向brokder读取
- topic:逻辑上消息类别
- partition:物理分区,一个topic可能存在多个partition上,一个分区中设置一个偏移量。具体数据存在partition的segment中,包括数据文件和索引
- consumer group:每个consumer可以指定特定group
- 消费端消费确认(commit),支持换group的方式数据回放。默认保存7天,可以 frpm beginining again
- 需要自己扩展的:丢数据(生产方or消费方)、数据重复(at-least-once)的场景
-
Redis 队列
- 支持优先级队列brpop
- 延迟队列:sortSet+timestatmp+cron轮询(ZRANGEBYSCORE)
- 不支持自动commit offset
十一、php框架
-
php框架
-
ci
- ci大对象
-
hyperf
- 注解()
- ioc&aop
- co协程相关
- yii
-
laravel
-
核心关键字:
- Container
- ServerProvider
- facade &contraces
- binding & make &reflection
- AppServiceProvider register:服务提供者注册
-
IocContainer:(工厂模式的升华:ioc容器)
-
控制反转(inversion of control)可以降低计算机代码之间的耦合,其中最常见的方式叫做依赖注入。(Dependence Injection),还有一种方式为依赖查找。可以理解简单的工厂可以实现依赖的转移(简单理解不需要在A类中依次new ABCDE,只需要传递ABCDE这个参数(必要的时候循环就可以了),然后调用工厂的makeObj方法就可以)
-
实现方式
- 基于接口:实现特定接口以供外部容器注入所依赖类型的对象。
- 基于set方法:就是一个属性
- 基于构造函数:实现特定参数(比如一个已经new出来的Object)的构造函数
- 管理类依赖
- 执行(依赖注入DI):通过构造函数或者某些情况下通过setter方法将类依赖注入到类中,容器并不需要被告知如何构建对象,因为他会使用php的反射服务自动解析出具体的对象。
- 可以参考spring的相关思想。
-
-
-
- swoole
-
十二 、运维
-
运维&架构
- 服务器cpu99%如何分析
- mysql 占cpu如何分析
- php占cpu较高如何分析
- sso实现方法
- mysql优化方法
- 如何提高监测数据的准确性
- docker 原理及引用及编排管理
十三、golang
-
golang
- golang的协程和swoole的协程的区别是什么
- swoole的协程和php自带的yield的场景有哪些?
十四、 Linux
-
linux
- epoll select
- netstat 查看tcp udp unixsock网络
- 查看负载cat /proc/loadavg | w | top
- df
- lstat:strace的时候常常可见他
- top shift+M
- free
- lsof 查看当前进程id,进程名等占用的文件描述符
# 一般用 -p pid,-u username,-c redis,lsof -i :6379等命令 lsof -n /usr/bin/php7.3 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME php 19852 root txt REG 252,0 4704192 146309 /usr/bin/php7.3- ipstat
- strace
- grep [-A ,-B, -C]'HTTP/1.1" 200' access.log |wc -l
- socket和管道(pipe)的区别:socket全双工,pipe半双工*2
-
awk & sed
- awk '{print $1}' access.log |sort |uniq |wc -l
十五、nginx
-
nginx
- worker_connections
- upstream weight
-
负责均衡实现方式
- 轮询
- ip 哈希
- 指定权重
-
第三方
- fair
- url_hash
十六、分布式 | 微服务
-
分布式
- redis 分布式锁问题
- cap 及常见应用关注cap哪两点
-
微服务
-
优点:
- 相对于单体服务更简单,注重单一功能
- 每个服务可以独立开发打包测试部署,且语言环境无关
- 可以水平、高效扩展
-
缺点:(或者难点)
- 运维成本,服务发现、治理、降级、熔断
- 网络消息传输、安全、延迟
- 服务调用排查追踪
-
最佳原则
- 高内聚:修改一个功能,只需要改一个服务
- 低耦合:修改了一个地方,不需要改其他的地方(下游消费者不受影响)
-
业务内原则:
- 新服务用新的微服务,确定无误后保留推进,否则调整
- 老的保留,直到新服务稳定再切换
- 必需的的监控与日志|生产-订阅—消费模型
- 尝试对外不可见的服务先做试点,错误邮件、日志、系统内调用、api内部分成熟接口
-
服务发现及相关工具

- consul(go)
- zookpper(java)
- etcd(go)
- doozerd
-
考虑问题
- 分布式数据一致性问题?CAP如何权衡
- 调用链追踪(基于OpenTracing协议的JeagerORZipkin)
-
其他
-
其他
- 两个绝对路径,求之间的相对路径
-
分布式
-
基础
- cap原理
- 解决多个节点数据一致性的方案其实就是共识算法
-
分布式协议
- Paxos:Proposer, Acceptor, Learner
- ZAB:Follower, Leader, Observer
- raft:leader ,follower,candidate

-
分布式工具
- zk:zab(base paxos)protocol,
- etcd:raft protocol(mini PAXOS),k-v database
-
具体
-
如何对一个大文件排序(装不进内存的)-好未来
-
思路:
- map reduce
- 分割成小文件(临时文件)
- 去重
- awk grep end for sort
- 输入输出缓冲区
-
- 快速排序代码
-
冒泡排序代码
- 外层循环 0到n-1 //控制比较轮数 n 表示元素的个数
- 内层循环 0到n-i-1 //控制每一轮比较次数
- 两两比较做交换
- 外层循环开始声明 is_switch flag为false,内层循环有交换为true,外层循环结束时判断无switch break
- 归并排序代码
面试完成后
- 自身定位与公司给定技术评级
- 没拿到offer不要慌,也许就是给HR刷kpi,面试就是照照自己。
- todo
其他参考
- [感觉php要求好高?](zhihu.com/question/21866412/answer/349627984)