公钥密钥加密原理
转载自:https://www.jianshu.com/p/0bf1c3c047e5
第6章 网络编程与网络框架
2018.02.25 23:22:49字数 14531阅读 123
6.1 公钥密钥加密原理
6.1.1 基础知识
- 密钥:一般就是一个字符串或数字,在加密或者解密时传递给加密/解密算法。
- 对称加密算法:加密和解密都是使用的同一个密钥。因此对称加密算法要保证安全性的话,密钥要做好保密,只能让使用的人知道,不能对外公开。
- 非对称加密算法:加密使用的密钥和解密使用的密钥是不同的。 公钥密码体制就是一种非对称加密算法。
(1) 公钥密码体制
分为三个部分:公钥、私钥、加密/解密算法
加密解密过程如下:
加密:通过加密算法和公钥对内容(或者说明文)进行加密,得到密文。
解密:通过解密算法和私钥对密文进行解密,得到明文。
注意:由公钥加密的内容,只能由私钥进行解密。
公钥密码体制的公钥和算法都是公开的,私钥是保密的。在实际的使用中,有需要的人会生成一对公钥和私钥,把公钥发布出去给别人使用,自己保留私钥。
(2) RSA加密算法
一种公钥密码体制,公钥公开,私钥保密,它的加密解密算法是公开的。 RSA的这一对公钥、私钥都可以用来加密和解密,并且一方加密的内容可以由并且只能由对方进行解密。
(3) 签名
就是在信息的后面再加上一段内容,可以证明信息没有被修改过。
一般是对信息做一个hash计算得到一个hash值(该过程不可逆),在把信息发送出去时,把这个hash值加密后做为一个签名和信息一起发出去。 接收方在收到信息后,会重新计算信息的hash值,并和信息所附带的hash值(解密后)进行对比,如果一致,就说明信息的内容没有被修改过,因为这里hash计算可以保证不同的内容一定会得到不同的hash值,所以只要内容一被修改,根据信息内容计算的hash值就会变化。
当然,不怀好意的人也可以修改信息内容的同时也修改hash值,从而让它们可以相匹配,为了防止这种情况,hash值一般都会加密后(也就是签名)再和信息一起发送,以保证这个hash值不被修改。
6.1.2 基于RSA算法的加密通信的例子
“客户”->“服务器”:你好
“服务器”->“客户”:你好,我是服务器
“客户”->“服务器”:向我证明你就是服务器
“服务器”->“客户”:你好,我是服务器{你好,我是服务器}[私钥|RSA]
“客户”->“服务器”:{我们后面的通信过程,用对称加密来进行,这里是对称加密算法和密钥}[公钥|RSA]
“服务器”->“客户”:{OK,收到!}[密钥|对称加密算法]
“客户”->“服务器”:{我的帐号是aaa,密码是123,把我的余额的信息发给我看看}[密钥|对称加密算法]
“服务器”->“客户”:{你的余额是100元}[密钥|对称加密算法]
总结一下,RSA加密算法在这个通信过程中所起到的作用主要有两个:
1. 因为私钥只有“服务器”拥有,因此“客户”可以通过判断对方是否有私钥来判断对方是否是“服务器”。
2. 客户端通过RSA的掩护,安全的和服务器商量好一个对称加密算法和密钥来保证后面通信过程内容的安全。
但是这里还留有一个问题,“服务器”要对外发布公钥,那“服务器”如何把公钥发送给“客户”呢?
我们可能会想到以下的两个方法:
a) 把公钥放到互联网的某个地方的一个下载地址,事先给“客户”去下载。
b) 每次和“客户”开始通信时,“服务器”把公钥发给“客户”。
但是这个两个方法都有一定的问题,
对于a)方法,“客户”无法确定这个下载地址是不是“服务器”发布的,你凭什么就相信这个
地址下载的东西就是“服务器”发布的而不是别人伪造的呢,万一下载到一个假的怎么办?另外要所有的“客户”都在通信前事先去下载公钥也很不现实。
对于b)方法,也有问题,因为任何人都可以自己生成一对公钥和私钥,他只要向“客户”发送他
自己的私钥就可以冒充“服务器”了。示意如下:
“客户”->“黑客”:你好 //黑客截获“客户”发给“服务器”的消息
“黑客”->“客户”:你好,我是服务器,这个是我的公钥 //黑客自己生成一对公钥和私钥,把
公钥发给“客户”,自己保留私钥
“客户”->“黑客”:向我证明你就是服务器
“黑客”->“客户”:你好,我是服务器 {你好,我是服务器}[黑客自己的私钥|RSA] //客户收到
“黑客”用私钥加密的信息后,是可以用“黑客”发给自己的公钥解密的,从而会误认为“黑客”是“服务器”因此“黑客”只需要自己生成一对公钥和私钥,然后把公钥发送给“客户”,自己保留私钥,这样由于“客户”可以用黑客的公钥解密黑客的私钥加密的内容,“客户”就会相信“黑客”是“服务器”,从而导致了安全问题。这里问题的根源就在于,大家都可以生成公钥、私钥对,无法确认公钥对到底是谁的。 如果能够确定公钥到底是谁的,就不会有这个问题了。例如,如果收到“黑客”冒充“服务器”发过来的公钥,经过某种检查,如果能够发现这个公钥不是“服务器”的就好了。
6.1.3 数字证书
为了解决上述问题,数字证书出现了,它可以解决我们上面的问题。先大概看下什么是数字证书,一个证书包含下面的具体内容:
- 证书的发布机构
- 证书的有效期
- 证书所有者(Subject)
- 公钥
- 指纹和指纹算法
- 签名算法
指纹和指纹算法
这个是用来保证证书的完整性的,也就是说确保证书没有被修改过。 其原理就是在发布证书时,发布者根据指纹算法(一个hash算法)计算整个证书的hash值(指纹)并和证书放在一起,使用者在打开证书时,自己也根据指纹算法计算一下证书的hash值(指纹),如果和刚开始的值对得上,就说明证书没有被修改过,因为证书的内容被修改后,根据证书的内容计算的出的hash值(指纹)是会变化的。
注意,这个指纹会用"SecureTrust CA"这个证书机构的私钥用签名算法加密后和证书放在一起。
签名算法
就是指的这个数字证书的数字签名所使用的加密算法,这样就可以使用证书发布机构的证书里面的公钥,根据这个算法对指纹进行解密。指纹的加密结果就是数字签名
数字证书可以保证数字证书里的公钥确实是这个证书的所有者(Subject)的,或者证书可以用来确认对方的身份。也就是说,我们拿到一个数字证书,我们可以判断出这个数字证书到底是谁的。至于是如何判断的,后面会在详细讨论数字证书时详细解释。现在把前面的通信过程使用数字证书修改为如下:
“客户”->“服务器”:你好
“服务器”->“客户”:你好,我是服务器,这里是我的数字证书 //这里用证书代替了公钥
“客户”->“服务器”:向我证明你就是服务器
“服务器”->“客户”:你好,我是服务器 {你好,我是服务器}[私钥|RSA]
在每次发送信息时,先对信息的内容进行一个hash计算得出一个hash值,将信息的内容和这个hash值一起加密后发送。接收方在收到后进行解密得到明文的内容和hash值,然后接收方再自己对收到信息内容做一次hash计算,与收到的hash值进行对比看是否匹配,如果匹配就说明信息在传输过程中没有被修改过。如果不匹配说明中途有人故意对加密数据进行了修改,立刻中断通话过程后做其它处理。
如何向证书的发布机构去申请证书
举个例子,假设我们公司"ABC Company"花了1000块钱,向一个证书发布机构"SecureTrust CA"为我们自己的公司"ABC Company"申请了一张证书,注意,这个证书发布机构"SecureTrust CA"是一个大家公认并被一些权威机构接受的证书发布机构,我们的操作系统里面已经安装了"SecureTrust CA"的证书。"SecureTrust CA"在给我们发布证书时,把Issuer,Public key,Subject,Valid from,Valid to等信息以明文的形式写到证书里面,然后用一个指纹算法计算出这些数字证书内容的一个指纹,并把指纹和指纹算法用自己的私钥进行加密,然后和证书的内容一起发布,同时"SecureTrust CA"还会给一个我们公司"ABC Company"的私钥给到我们。
我们"ABC Company"申请到这个证书后,我们把证书投入使用,我们在通信过程开始时会把证书发给对方。
对方如何检查这个证书的确是合法的并且是我们"ABC Company"公司的证书呢?首先应用程序(对方通信用的程序,例如IE、OUTLook等)读取证书中的Issuer(发布机构)为"SecureTrust CA" ,然后会在操作系统中受信任的发布机构的证书中去找"SecureTrust CA"的证书,如果找不到,那说明证书的发布机构是个水货发布机构,证书可能有问题,程序会给出一个错误信息。 如果在系统中找到了"SecureTrust CA"的证书,那么应用程序就会从证书中取出"SecureTrust CA"的公钥,然后对我们"ABC Company"公司的证书里面的指纹和指纹算法用这个公钥进行解密,然后使用这个指纹算法计算"ABC Company"证书的指纹,将这个计算的指纹与放在证书中的指纹对比,如果一致,说明"ABC Company"的证书肯定没有被修改过并且证书是"SecureTrust CA" 发布的,证书中的公钥肯定是"ABC Company"的。对方然后就可以放心的使用这个公钥和我们"ABC Company"进行通信了。
6.2 Http协议原理
6.2.1 基础知识
1. TCP/IP协议族
- IP协议:网络层协议,保证了计算机之间可以发送和接收数据。
- TCP协议:传输层协议,一种端到端的协议,建立一个虚拟链路用于发送和接收数据,基于重发机制,提供可靠的通信连接。为了方便通信,将报文分割成多个报文段发送。
- UDP协议:传输层协议,一种无连接的协议,每个数据报都是一个独立的信息,包括完整的源地址或目的地址,它在网络上以任何可能的路径传往目的地,因此能否到达目的地,到达目的地的时间以及内容的正确性都是不能被保证的。
通信双方一方作为服务器等待客户提出请求并予以响应。客户则在需要服务时向服务器提出申请。服务器一般作为守护进程始终运行,监听网络端口,一旦有客户请求,就会启动一个服务进程来响应该客户,同时自己继续监听服务端口,使后来的客户也能及时得到服务。一个socket(通常都是server socket)等待建立连接时,另一个socket可以要求进行连接,一旦这两个socket连接起来,它们就可以进行双向数据传输,双方都可以进行发送或接收操作。
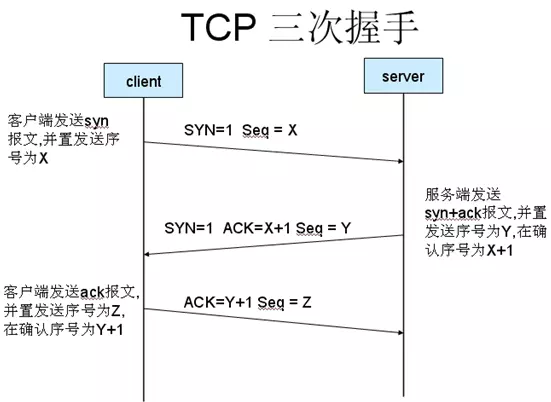
2. TCP3次握手,4次挥手过程
(1) 建立连接协议(三次握手)
a)客户端发送一个带SYN标志的TCP报文到服务器。(听得到吗?)
b)服务端回应客户端的报文同时带ACK(acknowledgement,确认)标志和SYN(synchronize)标志。它表示对刚才客户端SYN报文的回应;同时又标志SYN给客户端,询问客户端是否准备好进行数据通讯。(听得到,你能听到我吗?)
c)客户必须再次回应服务端一个ACK报文。(听到了,我们可以说话了)
为什么需要“三次握手”?
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”。 主要目的防止server端一直等待,浪费资源。
(2) 连接终止协议(四次挥手)
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
a) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
b) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
c) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
d) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)。

为什么需要“四次挥手”?
那可能有人会有疑问,在tcp连接握手时为何ACK是和SYN一起发送,这里ACK却没有和FIN一起发送呢。原因是因为tcp是全双工模式,接收到FIN时意味将没有数据再发来,但是还是可以继续发送数据。
3. 请求报文

(1) 请求行
由3部分组成,分别为:请求方法、URL以及协议版本,之间由空格分隔
请求方法:GET、HEAD、PUT、POST等方法,但并不是所有的服务器都实现了所有的方法,部分方法即便支持,处于安全性的考虑也是不可用的
协议版本:常用HTTP/1.1
(2) 请求头部
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔
Host接受请求的服务器地址,可以是IP:端口号,也可以是域名User-Agent发送请求的应用程序名称Accept-Charset通知服务端可以发送的编码格式Accept-Encoding通知服务端可以发送的数据压缩格式Accept-Language通知服务端可以发送的语言Range正文的字节请求范围,为断点续传和并行下载提供可能,返回状态码是206Authorization用于设置身份认证信息Cookie已有的Cookie
请求头部的最后会有一个空行,表示请求头部结束,接下来为请求正文,这一行非常重要,必不可少
(3) 请求正文
可选部分,比如GET请求就没有请求正文
4. 响应报文

由3部分组成,分别为:协议版本,状态码,状态码描述,之间由空格分隔
状态码:为3位数字,2XX表示成功,3XX表示资源重定向,4XX表示客户端请求出错,5XX表示服务端出错
206状态码表示的是:客户端通过发送范围请求头Range抓取到了资源的部分数据,得服务端提供支持
(1) 响应头部
Server服务器应用程序软件的名称和版本Content-Type响应正文的类型。如:text/plain、application/jsonContent-Length响应正文长度Content-Charset响应正文使用的编码Content-Language响应正文使用的语言Content-Range正文的字节位置范围Accept-Rangesbytes:表明服务器支持Range请求,单位是字节;none:不支持Set-Cookie设置Cookie
正文的内容可以用gzip等进行压缩,以提升传输速率
5. 通用首部
(1) Cache-Control
用于操作浏览器缓存的工作机制。取值如下:
- max-age:表示缓存的新鲜时间,在此时间内可以直接使用缓存。单位秒。
- no-cache:不做缓存。
- max-stale:可以接受过期多少秒的缓存。
(2) Connection
用于管理持久连接。目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求。所以是否能完成一个完整的Keep-Alive连接就看服务器设置情况。取值如下:
- keep-alive:使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,避免了建立或者重新建立连接。
- close:每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接。
(3) Transfer-Encoding
在Http/1.1中,仅对分块传输编码有效。Transfer-Encoding: chunked 表示输出的内容长度不能确定,普通的静态页面、图片之类的基本上都用不到这个,但动态页面就有可能会用到。一般使用Content-Length就够了。
Http/1.1 200 OK
....
Transfer-Encoding:chunked
Connection:keep-alive
cf0 //16进制,值为3312
...3312字节分块数据...
392 //16进制,值为914
...914字节分块数据...
0
(4) Content-Encoding
请求体/响应体的编码格式,如gzip
6. HTTP Authentication
两种常见的Authentication机制:HTTP Basic和Digest。(现在用的并不多,了解一下)
(1) Http Basic
最简单的Authentication协议。直接方式告诉服务器你的用户名(username)和密码(password)。
request头部:
GET /secret HTTP/1.1
Authorization: Basic QWxpY2U6MTIzNDU2//由“Alice:123456”进行Base64编码以后得到的结果
...
response头部:
HTTP/1.1 200 OK
...
因为我们输入的是正确的用户名密码,所以服务器会返回200,表示验证成功。如果我们用错误的用户的密码来发送请求,则会得到类似如下含有401错误的response头部:
HTTP/1.1 401 Bad credentials
WWW-Authenticate: Basic realm="Spring Security Application"
...
(2) Http Digest
当Alice初次访问服务器时,并不携带密码。此时服务器会告知Alice一个随机生成的字符串(nonce)。然后Alice再将这个字符串与她的密码123456结合在一起进行MD5编码,将编码以后的结果发送给服务器作为验证信息。
因为nonce是“每次”(并不一定是每次)随机生成的,所以Alice在不同的时间访问服务器,其编码使用的nonce值应该是不同的,如果携带的是相同的nonce编码后的结果,服务器就认为其不合法,将拒绝其访问。
curl和服务器通信过程:
curl -------- request1:GET ------->> Server
curl <<------ response1:nonce ------- Server
curl ---- request2:Digest Auth ---->> Server
curl <<------- response2:OK -------- Server
request1头部:
GET /secret HTTP/1.1
...
请求1中没有包含任何用户名和密码信息
response1头部:
HTTP/1.1 401 Full authentication is required to access this resource
WWW-Authenticate: Digest realm="Contacts Realm via Digest Authentication",
qop="auth",nonce="MTQwMTk3OTkwMDkxMzo3MjdjNDM2NTYzMTU2NTA2NWEzOWU2NzBlNzhmMjkwOA=="
...
当服务器接收到request1以后,认为request1没有任何的Authentication信息,所以返回401,并且告诉curl nonce的值是MTQwMTk3OTkwMDkxMzo3MjdjNDM2NTYzMTU2NTA2NWEzOWU2NzBlNzhmMjkwOA
request2头部:
GET /secret HTTP/1.1
Authorization: Digest username="Alice", realm="Contacts Realm via Digest
Authentication",nonce="MTQwMTk3OTkwMDkxMzo3MjdjNDM2NTYzMTU2NTA2NWEzOWU2NzBlNzhmMjkwOA==", uri="/secret",
cnonce="MTQwMTk3", nc=00000001, qop="auth",response="fd5798940c32e51c128ecf88472151af"
...
curl接收到服务器的nonce值以后,就可以把如密码等信息和nonce值放在一起然后进行MD5编码,得到一个response值,如前面红色标出所示,这样服务器就可以通过这个值验证Alice的密码是否正确。
response2头部:
HTTP/1.1 200 OK
...
当我们完成Authentication以后,如果我们再次使用刚才的nonce值,将会收到错误信息。Digest Authentication比Basic安全,但是并不是真正的什么都不怕了,Digest Authentication这种容易方式容易收到Man in the Middle式攻击。
7. 请求体的3种形式
据应用场景的不同,HTTP请求的请求体有三种不同的形式。
第一种:
移动开发者常见的,请求体是任意类型,服务器不会解析请求体,请求体的处理需要自己解析,如 POST JSON时候就是这类。
第二种:
这里的格式要求就是URL中Query String的格式要求:多个键值对之间用&连接,键与值之前用=连接,且只能用ASCII字符,非ASCII字符需使用UrlEncode编码。
第三种:
请求体被分成为多个部分,文件上传时会被使用,这种格式最先应该是被用于邮件传输中,每个字段/文件都被boundary(Content-Type中指定)分成单独的段,每段以-- 加 boundary开头,然后是该段的描述头,描述头之后空一行接内容,请求结束的标制为boundary后面加--。(见下面详细说明)
8. http协议中的多部分对象(multipart/form-data)
默认是application/x-www-form-urlencoded,但是在传输大型文件的时候效率比较低下。所以需要multipart/form-data。
报文的主体内可以包含多部分对象,通常用来发送图片、文件或表单等。
Connection: keep-alive
Content-Length: 123
X-Requested-With: ShockwaveFlash/16.0.0.296
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36
Content-Type: multipart/form-data; boundary=Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1
Accept: */*
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Range: bytes=0-1024
Cookie: bdshare_firstime=1409052493497
--Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1
Content-Disposition: form-data; name="position"
1425264476444
--Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1
Content-Disposition: form-data; name="pics"; filename="file1.txt"
Content-Type: text/plain
...(file1.txt的数据)...
ue_con_1425264252856
--Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1
Content-Disposition: form-data; name="cm"
100672
--Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1--
a)在请求头中Content-Type: multipart/form-data; boundary=Ij5ei4KM7KM7ae0KM7cH2ae0Ij5Ef1是必须的,boundary字符串可以随意指定
b)上面有3个部分,分别用--boundary进行分隔。Content-Disposition: form-data; name="参数的名称" + "\r\n" + "\r\n" + 参数值
c)--boundary-- 作为结束
6.2.2Https
(1) Http的缺点
- 通信使用明文,内容可能会被窃听 —— 加密通信线路
- 不验证通信方,可能遭遇伪装 —— 证书
- 无法验证报文的完整性,可能已被篡改 —— 数字签名
Http+加密+认证+完整性保护=Https
Https就是身披SSL(Secure Socket Layer,安全套接层)协议这层外壳的Http。当使用了SSL之后,Http先和SSL通信,SSL再和TCP通信。
SSL(secure sockets layer):安全套接层,它是在上世纪90年代中期,由网景公司设计的,为解决 HTTP 协议传输内容会被偷窥(嗅探)和篡改等安全问题而设计的,到了1999年,SSL成为互联网上的标准,名称改为TLS(transport layer security):安全传输层协议,两者可视为同一种东西的不同阶段。

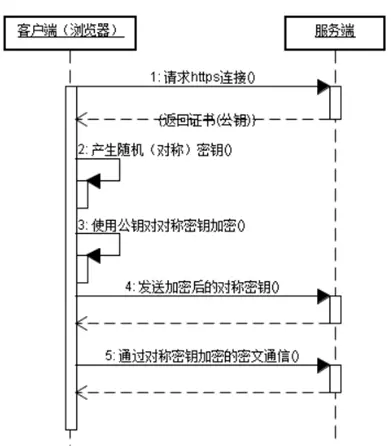
(2) Https的工作原理
HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的具体描述如下:
- 浏览器将自己支持的一套加密规则发送给网站。
- 网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
- 浏览器获得网站证书之后浏览器要做以下工作:
a) 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。
b) 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。
c) 使用约定好的HASH算法计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。 - 网站接收浏览器发来的数据之后要做以下的操作:
a) 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。
b) 使用密码加密一段握手消息,发送给浏览器。 - 浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
这里浏览器与网站互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。另外,HTTPS一般使用的加密与HASH算法如下:
- 非对称加密算法:RSA,DSA/DSS
- 对称加密算法:AES,RC4,3DES
- HASH算法:MD5,SHA1,SHA256
HTTPS对应的通信时序图如下:
(3) 证书分类
SSL 证书大致分三类:
- 认可的证书颁发机构(如: VeriSign), 或这些机构的下属机构颁发的证书.
- 没有得到认可的证书颁发机构颁发的证书.
- 自签名证书, 自己通过JDK自带工具keytool去生成一个证书,分为临时性的(在开发阶段使用)或在发布的产品中永久性使用的两种.
只有第一种, 也就是那些被安卓系统认可的机构颁发的证书, 在使用过程中不会出现安全提示。对于向权威机构(简称CA,Certificate Authority)申请过证书的网络地址,用OkHttp或者HttpsURLConnection都可以直接访问 ,不需要做额外的事情 。但是申请需要$$ (每年要交 100 到 500 美元不等的费用)。
CA机构颁发的证书有3种类型:
域名型SSL证书(DV SSL):信任等级普通,只需验证网站的真实性便可颁发证书保护网站;
企业型SSL证书(OV SSL):信任等级强,须要验证企业的身份,审核严格,安全性更高;
增强型SSL证书(EV SSL):信任等级最高,一般用于银行证券等金融机构,审核严格,安全性最高,同时可以激活绿色网址栏。
(4) HTTPS协议和HTTP协议的区别:
- https协议需要到ca申请证书,一般免费证书很少,需要交费。
- http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的 。
- HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议, 要比http协议安全。
6.3 Android SDK支持
6.3.1 InetAddress
(1) 简介
- 代表IP地址,还有两个子类,Inet4Address、Inet6Address
- 没有构造方法
(2) 方法
InetAddress.getByAddress(byte[] addr)根据IP地址获取InetAddress对象,如:new byte[]{127,0,0,1}InetAddress.getByName(String host)根据主机名获取InetAddress对象 www.baidu.com 没有http://InetAddress.getLocalHost()返回本机getHostAddress() String返回IP地址getHostName() String返回主机名isReachable(int timeout) boolean测试是否可以达到该地址,毫秒数
2. URLDecoder和URLEncoder
(1) 简介
- URLDecoder和URLEncoder用于完成普通字符串和
application/x-www-form-urlencoded MIME字符串之间的相互转换 - 若每个中文占2个字节,每个字节转换成2个十六进制的数字,所以每个中文字符转换成“%XX%XX”的形式
(2) 方法
URLEncoder.encode(String s, String enc) StringURLDecoder.decode(String s, String enc) String
6.3.2 Socket通信
1. Socket通信简介
Socket又称套接字,是程序内部提供的与外界通信的端口,即端口通信。通过建立socket连接,可为通信双方的数据传输传提供通道。主要特点有数据丢失率低,使用简单且易于移植。
(1) Socket的分类
在TCP/IP协议族当中主要的Socket类型为流套接字(streamsocket)和数据报套接字(datagramsocket)。流套接字将TCP作为其端对端协议,提供了一个可信赖的字节流服务。数据报套接字使用UDP协议,提供数据打包发送服务。
2. Socket 基本通信模型
(1) Socket通信模型
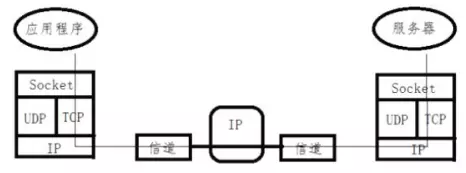
Socket基本通信模型
(2) TCP通信模型

TCP通信模型
(3) UDP通信模型

UDP通信模型
4. Demo
首先添加权限:
(1) 使用TCP协议通信
客户端实现:
protected void connectServerWithTCPSocket() {
Socket socket;
try {// 创建一个Socket对象,并指定服务端的IP及端口号
socket = new Socket("192.168.1.32", 1989);
// 创建一个InputStream用户读取要发送的文件。
InputStream inputStream = new FileInputStream("e://a.txt");
// 获取Socket的OutputStream对象用于发送数据。
OutputStream outputStream = socket.getOutputStream();
// 创建一个byte类型的buffer字节数组,用于存放读取的本地文件
byte buffer[] = new byte[4 * 1024];
int temp = 0;
// 循环读取文件
while ((temp = inputStream.read(buffer)) != -1) {
// 把数据写入到OuputStream对象中
outputStream.write(buffer, 0, temp);
}
// 发送读取的数据到服务端
outputStream.flush();
/** 或创建一个报文,使用BufferedWriter写入**/
//String socketData = "[2143213;21343fjks;213]";
//BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(
//socket.getOutputStream()));
//writer.write(socketData.replace("\n", " ") + "\n");
//writer.flush();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
服务端实现:
public void serverReceviedByTcp() {
// 声明一个ServerSocket对象
ServerSocket serverSocket = null;
try {
// 创建一个ServerSocket对象,并让这个Socket在1989端口监听
serverSocket = new ServerSocket(1989);
// 调用ServerSocket的accept()方法,接受客户端所发送的请求,
// 如果客户端没有发送数据,那么该线程就阻塞,等到收到数据,继续执行。
Socket socket = serverSocket.accept();
// 从Socket当中得到InputStream对象,读取客户端发送的数据
InputStream inputStream = socket.getInputStream();
byte buffer[] = new byte[1024 * 4];
int temp = 0;
// 从InputStream当中读取客户端所发送的数据
while ((temp = inputStream.read(buffer)) != -1) {
System.out.println(new String(buffer, 0, temp));
}
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
5. 方法
(1) ServerSocket
监听来自于客户端的Socket连接,如果没有连接,它将一直处于等待状态
ServerSocket(int port, int backlog, InetAddress bindAddr)在机器存在多IP的情况下,允许通过bindAddr来指定绑定到哪个IP;backlog是队列中能接受的最大socket客户端连接数(accept()之后将被取出)ServerSocket()创建非绑定服务器套接字ServerSocket(int port)创建绑定到特定端口的服务器套接字,等价于ServerSocket(port, 50, null)accept() Socket如果接收到一个客户端Socket的连接请求,返回一个与客户端Socket相对应的Socketclose()
(2) Socket
Socket()创建未连接套接字Socket(String host, int port)Socket(InetAddress address, int port)创建一个流套接字并将其连接到指定 IP 地址的指定端口号,默认使用本地主机默认的IP和系统动态分配的端口Socket(InetAddress address, int port, InetAddress localAddr, int localPort)创建一个套接字并将其连接到指定远程地址上的指定远程端口,多IP时getOutputStream() OutputStream返回此套接字的输出流getInputStream() inputStream返回此套接字的输入流connect(SocketAddress endpoint, int timeout)将此套接字连接到服务器,并指定一个超时值close()
6.3.3HttpURLConnection
1. URL
1)对象代表统一资源定位器,是指向互联网“资源”的指针
2)通常由协议名、主机、端口、资源路径组成
3)URL包含一个可打开到达该资源的输入流,可以将URL理解成为URI的特例
URL(String spec)openConnection() URLConnectiongetProtocol() StringgetHost() StringgetPort() intgetPath() String获取路径部分,/search.htmlgetFile() String获取资源名称,/search.html?keyword='你好'getQuery() String获取查询字符串,keyword='你好'openStream() InputStream
2. URLConnection
抽象类,表示应用程序和URL之间的通信连接,可以向URL发送请求,读取URL指向的资源
setDoInput(boolean doinput)发送POST请求,必须设置,设置为truesetDoOutput(boolean dooutput)发送POST请求,必须设置,设置为truesetUseCaches(boolean usecaches)是否使用缓存setRequestProperty(String key, String value)设置普通的请求属性setConnectTimeout(int timeout)设置连接超时的时间setReadTimeout(int timeoutMillis)读取输入流的超时时间connect()抽象方法,建立实际的连接getHeaderField(String key) StringgetHeaderFields() Map获取所有的响应头;getHeaderField(String name)获取指定的响应头getOutputStream() OutputStreamgetInputStream() InputStreamgetContentLength() int
3. HttpURLConnection
(1) 简介
抽象类,是URLConnection的子类,增加了操作Http资源的便捷方法
- 对象不能直接构造,需要通过URL类中的openConnection()方法来获得。
- connect()函数,实际上只是建立了一个与服务器的TCP连接,并没有实际发送HTTP请求。HTTP请求实际上直到我们获取服务器响应数据(如调用getInputStream()、getResponseCode()等方法)时才正式发送出去。
- 对HttpURLConnection对象的配置都需要在connect()方法执行之前完成。
- HttpURLConnection是基于HTTP协议的,其底层通过socket通信实现。如果不设置超时(timeout),在网络异常的情况下,可能会导致程序僵死而不继续往下执行。
- HTTP正文的内容是通过OutputStream流写入的, 向流中写入的数据不会立即发送到网络,而是存在于内存缓冲区中,待流关闭时,根据写入的内容生成HTTP正文。
- 调用getInputStream()方法时,返回一个输入流,用于从中读取服务器对于HTTP请求的返回信息。
- 我们可以使用connect()方法手动的发送一个HTTP请求,但是如果要获取HTTP响应的时候,请求就会自动的发起,比如我们使用getInputStream()方法的时候,所以完全没有必要调用connect()方法。
(2) 方法
setRequestMethod(String method)setInstanceFollowRedirects(boolean followRedirects)getResponseCode() int获取服务器的响应码getResponseMessage() String获取响应消息getRequestMethod() String获取发送请求的方法,GET或POSTdisconnect()抽象方法
(3) 实现多线程下载
步骤:
①:创建URL对象
②:获取URL对象指向资源的大小(getContentLength()方法)
③:在本地创建一个与网路资源相同大小的空文件
④:计算每条线程应该下载网络资源的哪个部分(从哪个字节开始,到哪个字节结束)
⑤:依次创建,启动多条线程来下载网络资源的指定部分
(4) 实例
使用GET方式访问HTTP
public static void main(String[] args) {
try {
// 1. 得到访问地址的URL
URL url = new URL(
"http://localhost:8080/Servlet/do_login.do?username=test&password=123456");
// 2. 得到网络访问对象java.net.HttpURLConnection
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
/* 3. 设置请求参数(过期时间,输入、输出流、访问方式),以流的形式进行连接 */
// 设置是否向HttpURLConnection输出
connection.setDoOutput(false);
// 设置是否从httpUrlConnection读入
connection.setDoInput(true);
// 设置请求方式
connection.setRequestMethod("GET");
// 设置是否使用缓存
connection.setUseCaches(true);
// 设置此 HttpURLConnection 实例是否应该自动执行 HTTP 重定向
connection.setInstanceFollowRedirects(true);
// 设置超时时间
connection.setConnectTimeout(3000);
// 连接
connection.connect();
// 4. 得到响应状态码的返回值 responseCode
int code = connection.getResponseCode();
// 5. 如果返回值正常,数据在网络中是以流的形式得到服务端返回的数据
String msg = "";
if (code == 200) { // 正常响应
// 从流中读取响应信息
BufferedReader reader = new BufferedReader(
new InputStreamReader(connection.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null) { // 循环从流中读取
msg += line + "\n";
}
reader.close(); // 关闭流
}
// 6. 断开连接,释放资源
connection.disconnect();
// 显示响应结果
System.out.println(msg);
} catch (IOException e) {
e.printStackTrace();
}
}
使用POST方式访问HTTP
public static void main(String[] args) {
try {
// 1. 获取访问地址URL
URL url = new URL("http://localhost:8080/Servlet/do_login.do");
// 2. 创建HttpURLConnection对象
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
/* 3. 设置请求参数等 */
// 请求方式
connection.setRequestMethod("POST");
// 超时时间
connection.setConnectTimeout(3000);
// 设置是否输出
connection.setDoOutput(true);
// 设置是否读入
connection.setDoInput(true);
// 设置是否使用缓存
connection.setUseCaches(false);
// 设置此 HttpURLConnection 实例是否应该自动执行 HTTP 重定向
connection.setInstanceFollowRedirects(true);
// 设置使用标准编码格式编码参数的名-值对
connection.setRequestProperty("Content-Type",
"application/x-www-form-urlencoded");
// 连接
connection.connect();
/* 4. 处理输入输出 */
// 写入参数到请求中
String params = "username=test&password=123456";
OutputStream out = connection.getOutputStream();
out.write(params.getBytes());
out.flush();
out.close();
// 从连接中读取响应信息
String msg = "";
int code = connection.getResponseCode();
if (code == 200) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(connection.getInputStream()));
String line;
while ((line = reader.readLine()) != null) {
msg += line + "\n";
}
reader.close();
}
// 5. 断开连接
connection.disconnect();
// 处理结果
System.out.println(msg);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
4. HttpClient
(Android6.0之后的SDK中移除了对于HttpClient的支持,仅作了解)
在一般情况下,如果只是需要向Web站点的某个简单页面提交请求并获取服务器响应,HttpURLConnection完全可以胜任。但在绝大部分情况下,Web站点的网页可能没这么简单,这些页面并不是通过一个简单的URL就可访问的,可能需要用户登录而且具有相应的权限才可访问该页面。在这种情况下,就需要涉及Session、Cookie的处理了,如果打算使用HttpURLConnection来处理这些细节,当然也是可能实现的,只是处理起来难度就大了。
为了更好地处理向Web站点请求,包括处理Session、Cookie等细节问题,Apache开源组织提供了一个HttpClient项目。HttpClient就是一个增强版的HttpURLConnection,HttpURLConnection可以做的事情HttpClient全部可以做;HttpURLConnection没有提供的有些功能,HttpClient也提供了,但它只是关注于如何发送请求、接收响应,以及管理HTTP连接。
(1) HttpClient的使用
步骤:
①:创建HttpClient对象
②:需要GET请求,创建HttpCet对象;需要POST请求,创建HttpPost对象
③:需要发送请求参数,调用HttpGet、HttpPost共同的setParams(HttpParams params),HttpPost对象还可以使用setEntity(HttpEntity entity)方法来设置请求参数。
④:调用HttpClient对象的execute(HttpUriRequest request) HttpResponse发送请求,执行该方法返回一个HttpResponse。
⑤:调用HttpResponse的getAllHeaders(),getHeader(String name)获取响应头;调用HttpResponse的getEntity()获取HttpEntity对象(包装了服务器的响应内容)
(2) 使用GET方式访问HTTP
public static void main(String[] args) {
// 1. 创建HttpClient对象
CloseableHttpClient httpClient = HttpClientBuilder.create().build();
// 2. 创建HttpGet对象
HttpGet httpGet = new HttpGet(
"http://localhost:8080/Servlet/do_login.do?username=test&password=123456");
CloseableHttpResponse response = null;
try {
// 3. 执行GET请求
response = httpClient.execute(httpGet);
System.out.println(response.getStatusLine());
// 4. 获取响应实体
HttpEntity entity = response.getEntity();
// 5. 处理响应实体
if (entity != null) {
System.out.println("长度:" + entity.getContentLength());
System.out.println("内容:" + EntityUtils.toString(entity));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 6. 释放资源
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
(3) 使用POST方式访问HTTP
public static void main(String[] args) {
// 1. 创建HttpClient对象
CloseableHttpClient httpClient = HttpClientBuilder.create().build();
// 2. 创建HttpPost对象
HttpPost post = new HttpPost(
"http://localhost:8080/Servlet/do_login.do");
// 3. 设置POST请求传递参数
List params = new ArrayList();
params.add(new BasicNameValuePair("username", "test"));
params.add(new BasicNameValuePair("password", "12356"));
try {
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(params);
post.setEntity(entity);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 4. 执行请求并处理响应
try {
CloseableHttpResponse response = httpClient.execute(post);
HttpEntity entity = response.getEntity();
if (entity != null) {
System.out.println("响应内容:");
System.out.println(EntityUtils.toString(entity));
}
response.close();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 释放资源
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
6.4 OkHttp
6.4.1 简介
HttpClient是Apache基金会的一个开源网络库,功能十分强大,API数量众多,但正是由于庞大的API数量使得我们很难在不破坏兼容性的情况下对它进行升级和扩展,所以Android团队在提升和优化HttpClient方面的工作态度并不积极。官方在Android 2.3以后就不建议用了,并且在Android 5.0以后废弃了HttpClient,在Android 6.0更是删除了HttpClient。
HttpURLConnection是一种多用途、轻量极的HTTP客户端,提供的API比较简单,可以容易地去使用和扩展。不过在Android 2.2版本之前,HttpURLConnection一直存在着一些令人厌烦的bug。比如说对一个可读的InputStream调用close()方法时,就有可能会导致连接池失效了。那么我们通常的解决办法就是直接禁用掉连接池的功能。因此一般推荐是在2.2之前使用HttpClient,因为其bug较少。在2.2之后推荐使用HttpURLConnection,因为API简单、体积小、有压缩和缓存机制,并且Android团队后续会继续优化HttpURLConnection。
自从Android4.4开始,google已经开始将源码中的HttpURLConnection替换为OkHttp,而市面上流行的Retrofit同样是使用OkHttp进行再次封装而来的。
OkHttp是一个快速、高效的网络请求库,它的设计和实现的首要目标便是高效,有如下特性:
- 支持HTTP/2, HTTP/2通过使用多路复用技术在一个单独的TCP连接上支持并发, 通过在一个连接上一次性发送多个请求来发送或接收数据;
- 如果HTTP/2不可用, 连接池复用技术也可以极大减少延时;
- 支持Gzip压缩响应体,降低传输内容的大小;
- 支持Http缓存,避免重复请求;
- 如果您的服务器配置了多个IP地址, 当第一个IP连接失败的时候, OkHttp会自动尝试下一个IP;
- 使用Okio来简化数据的访问与存储,提高性能;
- OkHttp还处理了代理服务器问题和SSL握手失败问题;
6.4.2 OkHttp类与Http请求响应的映射
1. Http请求
http请求包含:请求方法, 请求地址, 请求协议, 请求头, 请求体这五部分。这些都在okhttp3.Request的类中有体现, 这个类正是代表http请求的类。
public final class Request {
final HttpUrl url;//请求地址
final String method;//请求方法
final Headers headers;//请求头
final RequestBody body;//请求体
final Object tag;
...
}
2. Http响应
Http响应由访问协议, 响应码, 描述信息, 响应头, 响应体来组成。
public final class Response implements Closeable {
final Request request;//持有的请求
final Protocol protocol;//访问协议
final int code;//响应码
final String message;//描述信息
final Handshake handshake;//SSL/TLS握手协议验证时的信息,
final Headers headers;//响应头
final ResponseBody body;//响应体
...
}
6.4.3 相关方法
1. OkHttpClient
OkHttpClient()OkHttpClient(OkHttpClient.Builder builder)newCall(Request request) Call
OkHttpClient.Builder
connectTimeout(long timeout, TimeUnit unit)readTimeout(long timeout, TimeUnit unit)writeTimeout(long timeout, TimeUnit unit)pingInterval(long interval, TimeUnit unit)cache(Cache cache)入参如:new Cache(File directory, long maxSize)cookieJar(CookieJar cookieJar)CookieJar是一个接口hostnameVerifier(HostnameVerifier hostnameVerifier)HostnameVerifier是一个接口,只有boolean verify(String hostname, SSLSession session)sslSocketFactory(SSLSocketFactory sslSocketFactory, X509TrustManager trustManager)
2. Request
Request(Request.Builder builder)
Request.Builder
addHeader(String name, String value)添加键值对,不会覆盖header(String name, String value)添加键值对,会覆盖url(String url)method(String method, RequestBody body)post(RequestBody body)本质:method("POST", body)build() Request
RequestBody
create(MediaType contentType, final File file) RequestBodycreate(MediaType contentType, String content) RequestBodycreate(MediaType contentType, byte[] content) RequestBody
FormBody
RequestBody的子类
FormBody.Builder
add(String name, String value) FormBody.Builderbuild() FormBody
MultipartBody
RequestBody的子类
MultipartBody.Builder
Builder()Builder(String boundary)setType(MediaType type)addPart(Headers headers, RequestBody body)addFormDataPart(String name, String filename, RequestBody body)build() MultipartBody
3. Call
Call负责发送请求和读取响应
enqueue(Callback responseCallback)加入调度队列,异步执行execute() Response同步执行cancel()
4. Response
body() ResponseBodycode() inthttp请求的状态码isSuccessful()code为2XX时,返回true,否则falseheaders() Headers
ResponseBody
string() Stringbytes() byte[]byteStream() InputStreamcharStream() ReadercontentLength() long
5. MediaType
RequestBody的数据格式都要指定Content-Type,就是指定MIME,常见的有三种:
- application/x-www-form-urlencoded 数据是个普通表单(默认)
- multipart/form-data 数据里有文件
- application/json 数据是个json
方法:
parse(String string) MediaType
| 参数 | 说明 |
|---|---|
| text/html | HTML格式 |
| text/plain | 纯文本格式 |
| image/gif | gif图片格式 |
| image/jpeg | jpg图片格式 |
| image/png | png图片格式 |
| application/json | JSON数据格式 |
| application/pdf | pdf格式 |
| application/msword | Word文档格式 |
| application/octet-stream | 二进制流数据 |
| application/x-www-form-urlencoded | 普通表单数据 |
| multipart/form-data | 表单数据里有文件 |
6. 自动管理Cookie
Request经常都要携带Cookie,request创建时可以通过header设置参数,Cookie也是参数之一。就像下面这样:
Request request = new Request.Builder()
.url(url)
.header("Cookie", "xxx")
.build();
然后可以从返回的response里得到新的Cookie,你可能得想办法把Cookie保存起来。
但是OkHttp可以不用我们管理Cookie,自动携带,保存和更新Cookie。
方法是在创建OkHttpClient设置管理Cookie的CookieJar:
private final HashMap> cookieStore = new HashMap<>();
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.cookieJar(new CookieJar() {
@Override
public void saveFromResponse(HttpUrl httpUrl, List list) {
cookieStore.put(httpUrl.host(), list);
}
@Override
public List loadForRequest(HttpUrl httpUrl) {
List cookies = cookieStore.get(httpUrl.host());
return cookies != null ? cookies : new ArrayList();
}
})
.build();
这样以后发送Request都不用管Cookie这个参数也不用去response获取新Cookie什么的了。还能通过cookieStore获取当前保存的Cookie。
最后,new OkHttpClient()只是一种快速创建OkHttpClient的方式,更标准的是使用OkHttpClient.Builder()。后者可以设置一堆参数,例如超时时间什么的。
6.4.4 get请求
1. 异步的get请求
//step 1: 创建 OkHttpClient 对象
OkHttpClient okHttpClient = new OkHttpClient();
//step 2: 创建一个请求,不指定请求方法时默认是GET。
Request.Builder requestBuilder = new Request.Builder().url("http://www.baidu.com");
//可以省略,默认是GET请求
requestBuilder.method("GET", null);
//step 3:创建 Call 对象
Call call = okHttpClient.newCall(requestBuilder.build());
//step 4: 开始异步请求
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
//获得返回体
ResponseBody body = response.body();
}
});
首先要将OkHttpClient的对象与Request的对象建立起来联系,使用okHttpClient的newCall()方法得到一个Call对象,这个Call对象的作用就是相当于将请求封装成了一个任务,既然是任务,自然就会有execute()和cancel()等方法。
最后,我们希望以异步的方式去执行请求,所以我们调用的是call.enqueue,将call加入调度队列,然后等待任务执行完成,我们在Callback中即可得到结果。但要注意的是,call的回调是子线程,所以是不能直接操作界面的。当请求成功时就会回调onResponse()方法,我们可以看到返回的结果是Response对象,在此我们比较关注的是请求中的返回体body(ResponseBody类型),大多数的情况下我们希望获得字符串从而进行json解析获得数据,所以可以通过body.string()的方式获得字符串。如果希望获得返回的二进制字节数组,则调用response.body().bytes();如果你想拿到返回的inputStream,则调用response.body().byteStream()。
2. 同步的get请求
调用Call#execute()方法,在主线程运行
6.4.5 post请求
1. Post上传表单(键值对)
//step1: 同样的需要创建一个OkHttpClick对象
OkHttpClient okHttpClient = new OkHttpClient();
//step2: 创建 FormBody.Builder
FormBody formBody = new FormBody.Builder()
.add("name", "dsd") //添加键值对
.build();
//step3: 创建请求
Request request = new Request.Builder().url("http://www.baidu.com")
.post(formBody)
.build()
//step4: 建立联系 创建Call对象
okHttpClient.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
2. Post异步上传文件
// step 1: 创建 OkHttpClient 对象
OkHttpClient okHttpClient = new OkHttpClient();
//step 2:创建 RequestBody 以及所需的参数
//2.1 获取文件
File file = new File(Environment.getExternalStorageDirectory() + "test.txt");
//2.2 创建 MediaType 设置上传文件类型
MediaType MEDIATYPE = MediaType.parse("text/plain; charset=utf-8");
//2.3 获取请求体
RequestBody requestBody = RequestBody.create(MEDIATYPE, file);
//step 3:创建请求
Request request = new Request.Builder().url("http://www.baidu.com")
.post(requestBody)
.build();
//step 4 建立联系
okHttpClient.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
3. Post方式提交流
以流的方式POST提交请求体. 请求体的内容由流写入产生. 这个例子是流直接写入Okio的BufferedSink. 你的程序可能会使用OutputStream, 你可以使用BufferedSink.outputStream()来获取. OkHttp的底层对流和字节的操作都是基于Okio库, Okio库也是Square开发的另一个IO库, 填补I/O和NIO的空缺, 目的是提供简单便于使用的接口来操作IO.
public static final MediaType MEDIA_TYPE_MARKDOWN = MediaType.parse("text/x-markdown; charset=utf-8");
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
RequestBody requestBody = new RequestBody() {
@Override
public MediaType contentType() {
return MEDIA_TYPE_MARKDOWN;
}
@Override
public void writeTo(BufferedSink sink) throws IOException {
sink.writeUtf8("Numbers\n");
sink.writeUtf8("-------\n");
for (int i = 2; i <= 997; i++) {
sink.writeUtf8(String.format(" * %s = %s\n", i, factor(i)));
}
}
private String factor(int n) {
for (int i = 2; i < n; i++) {
int x = n / i;
if (x * i == n) return factor(x) + " × " + i;
}
return Integer.toString(n);
}
};
Request request = new Request.Builder()
.url("https://api.github.com/markdown/raw")
.post(requestBody)
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println(response.body().string());
}
4. Post方式提交String
下面是使用HTTP POST提交请求到服务. 这个例子提交了一个markdown文档到web服务, 以HTML方式渲染markdown. 因为整个请求体都在内存中, 因此避免使用此api提交大文档(大于1MB).
public static final MediaType MEDIA_TYPE_MARKDOWN = MediaType.parse("text/x-markdown; charset=utf-8");
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
String postBody = ""
+ "Releases\n"
+ "--------\n"
+ "\n"
+ " * _1.0_ May 6, 2013\n"
+ " * _1.1_ June 15, 2013\n"
+ " * _1.2_ August 11, 2013\n";
Request request = new Request.Builder()
.url("https://api.github.com/markdown/raw")
.post(RequestBody.create(MEDIA_TYPE_MARKDOWN, postBody))
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println(response.body().string());
}
5、Post方式提交分块请求
MultipartBody.Builder可以构建复杂的请求体, 与HTML文件上传形式兼容. 多块请求体中每块请求都是一个请求体, 可以定义自己的请求头. 这些请求头可以用来描述这块请求, 例如它的Content-Disposition. 如果Content-Length和Content-Type可用的话, 他们会被自动添加到请求头中.
private static final String IMGUR_CLIENT_ID = "...";
private static final MediaType MEDIA_TYPE_PNG = MediaType.parse("image/png");
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
// Use the imgur image upload API as documented at https://api.imgur.com/endpoints/image
RequestBody requestBody = new MultipartBody.Builder()
.setType(MultipartBody.FORM)
.addFormDataPart("title", "Square Logo")
.addFormDataPart("image", "logo-square.png",
RequestBody.create(MEDIA_TYPE_PNG, new File("website/static/logo-square.png")))
.build();
Request request = new Request.Builder()
.header("Authorization", "Client-ID " + IMGUR_CLIENT_ID)
.url("https://api.imgur.com/3/image")
.post(requestBody)
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println(response.body().string());
}
六、其他用法
1、提取响应头
典型的HTTP头是一个Map
当写请求头的时候, 使用header(name, value)可以设置唯一的name、value. 如果已经有值, 旧的将被移除, 然后添加新的. 使用addHeader(name, value)可以添加多值(添加, 不移除已有的).
当读取响应头时, 使用header(name)返回最后出现的name、value. 通常情况这也是唯一的name、value. 如果没有值, 那么header(name)将返回null. 如果想读取字段对应的所有值, 使用headers(name)`会返回一个list.
为了获取所有的Header, Headers类支持按index访问.
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
Request request = new Request.Builder()
.url("https://api.github.com/repos/square/okhttp/issues")
.header("User-Agent", "OkHttp Headers.java")
.addHeader("Accept", "application/json; q=0.5")
.addHeader("Accept", "application/vnd.github.v3+json")
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println("Server: " + response.header("Server"));
System.out.println("Date: " + response.header("Date"));
System.out.println("Vary: " + response.headers("Vary"));
}
2、使用Gson来解析JSON响应
Gson是一个在JSON和Java对象之间转换非常方便的api库. 这里我们用Gson来解析Github API的JSON响应.
注意: ResponseBody.charStream()使用响应头Content-Type指定的字符集来解析响应体. 默认是UTF-8.
private final OkHttpClient client = new OkHttpClient();
private final Gson gson = new Gson();
public void run() throws Exception {
Request request = new Request.Builder()
.url("https://api.github.com/gists/c2a7c39532239ff261be")
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
Gist gist = gson.fromJson(response.body().charStream(), Gist.class);
for (Map.Entry entry : gist.files.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue().content);
}
}
static class Gist {
Map files;
}
static class GistFile {
String content;
}
3、响应缓存
OKHTTP如果要设置缓存,首要的条件就是设置一个缓存文件夹,在Android中为了安全起见,一般设置为私密数据空间。通过getExternalCacheDir()获取。
如然后通过调用OKHttpClient.Builder中的cache()方法。如下面代码所示:
//缓存文件夹
File cacheFile = new File(getExternalCacheDir().toString(),"cache");
//缓存大小为10M
int cacheSize = 10 * 1024 * 1024;
//创建缓存对象
Cache cache = new Cache(cacheFile,cacheSize);
OkHttpClient client = new OkHttpClient.Builder()
.cache(cache)
.build();
设置好Cache我们就可以正常访问了。我们可以通过获取到的Response对象拿到它正常的消息和缓存的消息。
Response的消息有两种类型,CacheResponse和NetworkResponse。CacheResponse代表从缓存取到的消息,NetworkResponse代表直接从服务端返回的消息。
示例代码如下:
private void testCache(){
//缓存文件夹
File cacheFile = new File(getExternalCacheDir().toString(),"cache");
//缓存大小为10M
int cacheSize = 10 * 1024 * 1024;
//创建缓存对象
final Cache cache = new Cache(cacheFile,cacheSize);
new Thread(new Runnable() {
@Override
public void run() {
OkHttpClient client = new OkHttpClient.Builder()
.cache(cache)
.build();
//官方的一个示例的url
String url = "http://publicobject.com/helloworld.txt";
Request request = new Request.Builder()
.url(url)
.build();
Call call1 = client.newCall(request);
Response response1 = null;
try {
//第一次网络请求
response1 = call1.execute();
Log.i(TAG, "testCache: response1 :"+response1.body().string());
Log.i(TAG, "testCache: response1 cache :"+response1.cacheResponse());
Log.i(TAG, "testCache: response1 network :"+response1.networkResponse());
response1.body().close();
} catch (IOException e) {
e.printStackTrace();
}
Call call12 = client.newCall(request);
try {
//第二次网络请求
Response response2 = call12.execute();
Log.i(TAG, "testCache: response2 :"+response2.body().string());
Log.i(TAG, "testCache: response2 cache :"+response2.cacheResponse());
Log.i(TAG, "testCache: response2 network :"+response2.networkResponse());
Log.i(TAG, "testCache: response1 equals response2:"+response2.equals(response1));
response2.body().close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
我们在上面的代码中,用同一个url地址分别进行了两次网络访问,然后分别用Log打印它们的信息。打印的结果主要说明了一个现象,第一次访问的时候,Response的消息是NetworkResponse消息,此时CacheResponse的值为Null.而第二次访问的时候Response是CahceResponse,而此时NetworkResponse为空。也就说明了上面的示例代码能够进行网络请求的缓存。
其实控制缓存的消息头往往是服务端返回的信息中添加的如”Cache-Control:max-age=60”。所以,会有两种情况。
- 客户端和服务端开发能够很好沟通,按照达成一致的协议,服务端按照规定添加缓存相关的消息头。
- 客户端与服务端的开发根本就不是同一家公司,没有办法也不可能要求服务端按照客户端的意愿进行开发。
第一种办法当然很好,只要服务器在返回消息的时候添加好Cache-Control相关的消息便好。
第二种情况,就很麻烦,你真的无法左右别人的行为。怎么办呢?好在OKHTTP能够很轻易地处理这种情况。那就是定义一个拦截器,
人为地添加Response中的消息头,然后再传递给用户,这样用户拿到的Response就有了我们理想当中的消息头Headers,从而达到控制缓存的意图,正所谓移花接木。
缓存之拦截器
因为拦截器可以拿到Request和Response,所以可以轻而易举地加工这些东西。在这里我们人为地添加Cache-Control消息头。
class CacheInterceptor implements Interceptor{
@Override
public Response intercept(Chain chain) throws IOException {
Response originResponse = chain.proceed(chain.request());
//设置缓存时间为60秒,并移除了pragma消息头,移除它的原因是因为pragma也是控制缓存的一个消息头属性
return originResponse.newBuilder().removeHeader("pragma")
.header("Cache-Control","max-age=60").build();
}
}
定义好拦截器中后,我们可以添加到OKHttpClient中了。
private void testCacheInterceptor(){
//缓存文件夹
File cacheFile = new File(getExternalCacheDir().toString(),"cache");
//缓存大小为10M
int cacheSize = 10 * 1024 * 1024;
//创建缓存对象
final Cache cache = new Cache(cacheFile,cacheSize);
OkHttpClient client = new OkHttpClient.Builder()
.addNetworkInterceptor(new CacheInterceptor())
.cache(cache)
.build();
.......
}
代码后面部分有省略。主要通过在OkHttpClient.Builder()中addNetworkInterceptor()中添加。而这样也挺简单的,就几步完成了缓存代码。
拦截器进行缓存的缺点
- 网络访问请求的资源是文本信息,如新闻列表,这类信息经常变动,一天更新好几次,它们用的缓存时间应该就很短。
- 网络访问请求的资源是图片或者视频,它们变动很少,或者是长期不变动,那么它们用的缓存时间就应该很长。
那么,问题来了。
因为OKHTTP开发建议是同一个APP,用同一个OKHTTPCLIENT对象这是为了只有一个缓存文件访问入口。这个很容易理解,单例模式嘛。但是问题拦截器是在OKHttpClient.Builder当中添加的。如果在拦截器中定义缓存的方法会导致图片的缓存和新闻列表的缓存时间是一样的,这显然是不合理的,真实的情况不应该是图片请求有它的缓存时间,新闻列表请求有它的缓存时间,应该是每一个Request有它的缓存时间。 那么,有解决的方案吗? 有的,okhttp官方有建议的方法。
okhttp官方文档建议缓存方法
okhttp中建议用CacheControl这个类来进行缓存策略的制定。
它内部有两个很重要的静态实例。
/**强制使用网络请求*/
public static final CacheControl FORCE_NETWORK = new Builder().noCache().build();
/**
* 强制性使用本地缓存,如果本地缓存不满足条件,则会返回code为504
*/
public static final CacheControl FORCE_CACHE = new Builder()
.onlyIfCached()
.maxStale(Integer.MAX_VALUE, TimeUnit.SECONDS)
.build();
我们看到FORCE_NETWORK常量用来强制使用网络请求。FORCE_CACHE只取本地的缓存。它们本身都是CacheControl对象,由内部的Buidler对象构造。下面我们来看看CacheControl.Builder
CacheControl.Builder
它有如下方法:
noCache()//不使用缓存,用网络请求noStore()//不使用缓存,也不存储缓存onlyIfCached()//只使用缓存noTransform()//禁止转码maxAge(10, TimeUnit.MILLISECONDS)//设置超时时间为10ms。maxStale(10, TimeUnit.SECONDS)//超时之外的超时时间为10sminFresh(10, TimeUnit.SECONDS)//超时时间为当前时间加上10秒钟。
知道了CacheControl的相关信息,那么它怎么使用呢?不同于拦截器设置缓存,CacheControl是针对Request的,所以它可以针对每个请求设置不同的缓存策略。比如图片和新闻列表。下面代码展示如何用CacheControl设置一个60秒的超时时间。
private void testCacheControl(){
//缓存文件夹
File cacheFile = new File(getExternalCacheDir().toString(),"cache");
//缓存大小为10M
int cacheSize = 10 * 1024 * 1024;
//创建缓存对象
final Cache cache = new Cache(cacheFile,cacheSize);
new Thread(new Runnable() {
@Override
public void run() {
OkHttpClient client = new OkHttpClient.Builder()
.cache(cache)
.build();
//设置缓存时间为60秒
CacheControl cacheControl = new CacheControl.Builder()
.maxAge(60, TimeUnit.SECONDS)
.build();
Request request = new Request.Builder()
.url("http://blog.csdn.net/briblue")
.cacheControl(cacheControl)
.build();
try {
Response response = client.newCall(request).execute();
response.body().close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
强制使用缓存
前面有讲CacheControl.FORCE_CACHE这个常量。
public static final CacheControl FORCE_CACHE = new Builder()
.onlyIfCached()
.maxStale(Integer.MAX_VALUE, TimeUnit.SECONDS)
它内部其实就是调用onlyIfCached()和maxStale方法。
它的使用方法为
Request request = new Request.Builder()
.url("http://blog.csdn.net/briblue")
.cacheControl(Cache.FORCE_CACHE)
.build();
但是如前面后提到的,如果缓存不符合条件会返回504.这个时候我们要根据情况再进行编码,如缓存不行就再进行一次网络请求。
Response forceCacheResponse = client.newCall(request).execute();
if (forceCacheResponse.code() != 504) {
// 资源已经缓存了,可以直接使用
} else {
// 资源没有缓存,或者是缓存不符合条件了。
}
不使用缓存
前面也有讲CacheControl.FORCE_NETWORK这个常量。
public static final CacheControl FORCE_NETWORK = new Builder().noCache().build();
它的内部其实是调用noCache()方法,也就是不缓存的意思。
它的使用方法为
Request request = new Request.Builder()
.url("http://blog.csdn.net/briblue")
.cacheControl(Cache.FORCE_NETWORK)
.build();
还有一种情况将maxAge设置为0,也不会取缓存,直接走网络。
Request request = new Request.Builder()
.url("http://blog.csdn.net/briblue")
.cacheControl(new CacheControl.Builder()
.maxAge(0, TimeUnit.SECONDS))
.build();
4、取消一个Call
使用Call.cancel()可以立即停止掉一个正在执行的call. 如果一个线程正在写请求或者读响应, 将会引发IOException. 当call没有必要的时候, 使用这个api可以节约网络资源. 例如当用户离开一个应用时, 不管同步还是异步的call都可以取消.
你可以通过tags来同时取消多个请求. 当你构建一请求时, 使用RequestBuilder.tag(tag)来分配一个标签, 之后你就可以用OkHttpClient.cancel(tag)来取消所有带有这个tag的call.
private final ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://httpbin.org/delay/2") // This URL is served with a 2 second delay.
.build();
final long startNanos = System.nanoTime();
final Call call = client.newCall(request);
// Schedule a job to cancel the call in 1 second.
executor.schedule(new Runnable() {
@Override public void run() {
System.out.printf("%.2f Canceling call.%n", (System.nanoTime() - startNanos) / 1e9f);
call.cancel();
System.out.printf("%.2f Canceled call.%n", (System.nanoTime() - startNanos) / 1e9f);
}
}, 1, TimeUnit.SECONDS);
try {
System.out.printf("%.2f Executing call.%n", (System.nanoTime() - startNanos) / 1e9f);
Response response = call.execute();
System.out.printf("%.2f Call was expected to fail, but completed: %s%n",
(System.nanoTime() - startNanos) / 1e9f, response);
} catch (IOException e) {
System.out.printf("%.2f Call failed as expected: %s%n",
(System.nanoTime() - startNanos) / 1e9f, e);
}
}
5、超时
没有响应时使用超时结束call. 没有响应的原因可能是客户点链接问题、服务器可用性问题或者这之间的其他东西. OkHttp支持连接超时, 读取超时和写入超时.
private final OkHttpClient client;
public ConfigureTimeouts() throws Exception {
client = new OkHttpClient.Builder()
.connectTimeout(10, TimeUnit.SECONDS)
.writeTimeout(10, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.build();
}
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://httpbin.org/delay/2") // This URL is served with a 2 second delay.
.build();
Response response = client.newCall(request).execute();
System.out.println("Response completed: " + response);
}
6、每个call的配置
使用OkHttpClient, 所有的HTTP Client配置包括代理设置、超时设置、缓存设置. 当你需要为单个call改变配置的时候, 调用OkHttpClient.newBuilder(). 这个api将会返回一个builder, 这个builder和原始的client共享相同的连接池, 分发器和配置.
下面的例子中,我们让一个请求是500ms的超时、另一个是3000ms的超时。
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://httpbin.org/delay/1") // This URL is served with a 1 second delay.
.build();
try {
// Copy to customize OkHttp for this request.
OkHttpClient copy = client.newBuilder()
.readTimeout(500, TimeUnit.MILLISECONDS)
.build();
Response response = copy.newCall(request).execute();
System.out.println("Response 1 succeeded: " + response);
} catch (IOException e) {
System.out.println("Response 1 failed: " + e);
}
try {
// Copy to customize OkHttp for this request.
OkHttpClient copy = client.newBuilder()
.readTimeout(3000, TimeUnit.MILLISECONDS)
.build();
Response response = copy.newCall(request).execute();
System.out.println("Response 2 succeeded: " + response);
} catch (IOException e) {
System.out.println("Response 2 failed: " + e);
}
}
七、处理验证
这部分和HTTP AUTH有关.
1、HTTP AUTH
使用HTTP AUTH需要在server端配置http auth信息, 其过程如下:
- 客户端发送http请求(没有Authorization header)
- 服务器发现配置了http auth, 于是检查request里面有没有"Authorization"的http header
如果有, 则判断Authorization里面的内容是否在用户列表里面, Authorization header的典型数据为"Authorization: Basic jdhaHY0=", 其中Basic表示基础认证, jdhaHY0=是base64编码的"user:passwd"字符串. 如果没有,或者用户密码不对,则返回http code 401页面给客户端. - 标准的http浏览器在收到401页面之后, 应该弹出一个对话框让用户输入帐号密码; 并在用户点确认的时候再次发出请求, 这次请求里面将带上Authorization header.
- 服务器端认证通过,并返回页面
- 浏览器显示页面
一次典型的访问场景是:
2、OkHttp认证
OkHttp会自动重试未验证的请求. 当响应是401 Not Authorized时,Authenticator会被要求提供证书. Authenticator的实现中需要建立一个新的包含证书的请求. 如果没有证书可用, 返回null来跳过尝试.
使用Response.challenges()来获得任何authentication challenges的 schemes 和 realms. 当完成一个Basic challenge, 使用Credentials.basic(username, password)来解码请求头.
private final OkHttpClient client;
public Authenticate() {
client = new OkHttpClient.Builder()
.authenticator(new Authenticator() {
@Override public Request authenticate(Route route, Response response) throws IOException {
System.out.println("Authenticating for response: " + response);
System.out.println("Challenges: " + response.challenges());
String credential = Credentials.basic("jesse", "password1");
return response.request().newBuilder()
.header("Authorization", credential)
.build();
}
})
.build();
}
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://publicobject.com/secrets/hellosecret.txt")
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
System.out.println(response.body().string());
}
当认证无法工作时, 为了避免多次重试, 你可以返回空来放弃认证. 例如, 当exact credentials已经尝试过, 你可能会直接想跳过认证, 可以这样做:
if (credential.equals(response.request().header("Authorization"))) {
return null; // If we already failed with these credentials, don't retry.
}
当重试次数超过定义的次数, 你若想跳过认证, 可以这样做:
if (responseCount(response) >= 3) {
return null; // If we've failed 3 times, give up.
}
private int responseCount(Response response) {
int result = 1;
while ((response = response.priorResponse()) != null) {
result++;
}
return result;
}