PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network)论文详解
《Shape Robust Text Detection with Progressive Scale Expansion Network》,2018年7月发表于arxiv,代码地址:https://github.com/whai362/PSENet
该版本为pytorch版
本人的实现:https://github.com/liuheng92/tensorflow_PSENet
tensorflow版,如果对您有所帮助请star一下,谢谢
这篇文章是在看云从科技的一篇叫Pixel-Anchor的文章的时候看到的,因为他给出的数据效果不错,后来下载下来具体看了一下速度,速度也还可以resnet的主干网络,在ICDAR2015数据集上的最快能达到12.38fps,此时的f值为85.88%,而且该方法适用于弯曲文字的检测。
文章思想:文章认为其提出的方法能避免现有bounding box回归的方法产生的对弯曲文字的检测不准确的缺点(如下图b所示),也能避免现有的通过分割方法产生的对于文字紧靠的情况分割效果不好的缺点(如下图c所示)。该文章的网络框架是从FPN中受到启发采用了U形的网络框架,先通过将网络提取出的特征进行融合然后利用分割的方式将提取出的特征进行像素的分类,最后利用像素的分类结果通过一些后处理得到文本检测结果。

一、网络结构
文中的主干网络采用resnet,网络框架类似于FPN的结构,如下图所示。
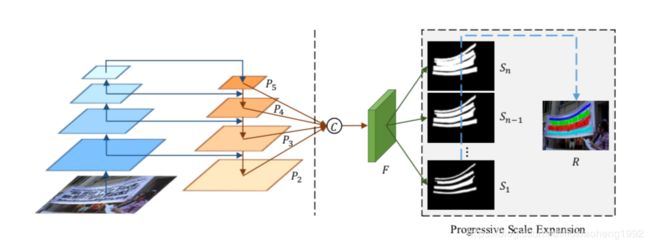
上图中先利用resnet提取出四层feature maps( P 2 , P 3 , P 4 , P 5 P_{2}, P_{3}, P_{4}, P_{5} P2,P3,P4,P5),将得到的四层特征图进行融合得到特征图用F表示,融合的方式用下面公式表示:
F = C ( P 2 , P 3 , P 4 , P 5 ) = P 2 ∣ ∣ U p × 2 ( P 3 ) ∣ ∣ ∣ U p × 4 ( P 4 ) ∣ ∣ ∣ U p × 8 ( P 5 ) F=C(P_{2}, P_{3}, P_{4}, P_{5})=P_{2}||Up_{\times 2}(P_{3})|||Up_{\times 4}(P_{4})|||Up_{\times 8}(P_{5}) F=C(P2,P3,P4,P5)=P2∣∣Up×2(P3)∣∣∣Up×4(P4)∣∣∣Up×8(P5)
上式中,“||”表示的是concatenation操作, U p × 2 , U p × 4 , U p × 8 Up_{\times 2}, Up_{\times 4}, Up_{\times 8} Up×2,Up×4,Up×8分别表示的是将feature map进行上采样,上采样的倍数分别是2,4,8倍。
特征图F送入 3 × 3 3 \times 3 3×3大小的卷积中输出通道数为256的特征图,将此特征图再送入 1 × 1 1 \times 1 1×1大小的卷积层中输出n个最终的结果,这n个结果用 S 1 , S 2 , … , S n S_{1},S_{2},\dots,S_{n} S1,S2,…,Sn表示。
最后将n个输出结果通过一定的后处理得到最终的文字检测结果。
这里还要说明的是 S 1 , S 2 , … , S n S_{1},S_{2},\dots,S_{n} S1,S2,…,Sn的区别, S i S_{i} Si是图像文字的分割结果,他们的不同点在于他们分割出的文字区域大小不同,例如 S 1 S_{1} S1给出的是最小的文字区域分割结果,而 S n S_{n} Sn给出的是最大的文字区域分割结果(理想情况下就是GroundTruth)
二、后处理算法(Progressive Scale Expansion Algorithm-PSE)
看这个名字就很容易理解为什么这篇文章被称为PSENet了。
该后处理算法如下图所示
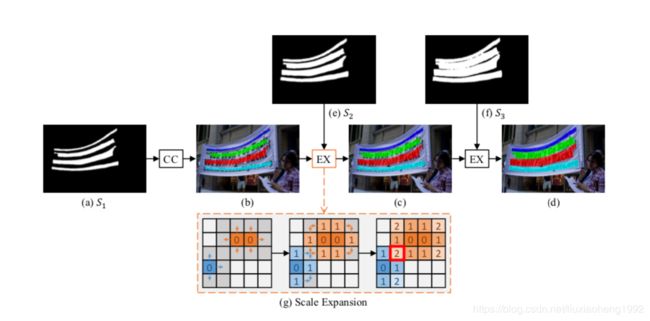
实际文章中n=6,但是为了更方便解释,这里假设n=3,即网络最终输出了3张分割结果 S = { S 1 , S 2 , S 3 } S=\{S_{1},S_{2},S_{3}\} S={S1,S2,S3},首先从最小的分割结果 S 1 S_{1} S1开始,如上图(a)所示,能够找出四个分割区域 C = { c 1 , c 2 , c 3 , c 4 } C=\{c_{1},c_{2},c_{3},c_{4}\} C={c1,c2,c3,c4}。这四个分割区域用四种不同的颜色表示,这样能得到所有文本的中心区域,然后将这些区域与 S 2 , S 3 S_{2},S_{3} S2,S3进行合并得到最终结果,结果分别如上图(c)和图(d)所示。上述依次合并的规则如上图(g)所示(Breadth-First-Search algorithm)。在合并的过程中可能会遇到如上图(g)中的冲突情况,在遇到冲突的情况下,采用"先到先得"的方式。
更为详细的合并规则用下面的伪代码表示,其中 T , P T,P T,P表示的中间结果, Q Q Q表示的是队列, N e i g h b o r ( ⋅ ) Neighbor(\cdot) Neighbor(⋅)表示像素的邻域, G r o u p B y L a b e l ( ⋅ ) GroupByLabel(\cdot) GroupByLabel(⋅)表示属于某一类的中间结果的label。 S i [ q ] = T r u e S_{i}[q]=True Si[q]=True表示预测的 S i S_{i} Si中的像素q是文字。

三、标签的生成
因为网络输出有n个分割结果,所以对于一张输入图片来说groundtruth也要有n个。这里groundtruth就是简单的将标定的文本框进行不同尺度的缩小,如下图所示。下图中(b)就是标定框也是最大的groundtruth S n S_{n} Sn,如下图(c)的最右侧图所示。为了获得下图(c)中的其他图,文章采用Vatti clipping算法将原多边形 p n p_{n} pn缩小 d i d_{i} di个像素得到 p i p_{i} pi。最终得到的n个groundtruth用 G 1 , G 2 , … , G n G_{1},G_{2},\dots,G_{n} G1,G2,…,Gn表示。需要缩小的像素通过下面式子得到:
d i = A r e a ( p n ) × ( 1 − r 2 ) P e r i m e t e r ( p n ) d_{i}=\frac{Area(p_{n})\times (1-r^2)}{Perimeter(p_{n})} di=Perimeter(pn)Area(pn)×(1−r2)
上式中, d i d_{i} di表示要缩小的像素值, A r e a ( ⋅ ) Area(\cdot) Area(⋅)表示多边形的面积, P e r i m e t e r ( ⋅ ) Perimeter(\cdot) Perimeter(⋅)表示多边形的周长, r i r_{i} ri表示缩小的比例。
缩小比例 r i r_{i} ri的计算方式如下图所示:
r i = 1 − ( 1 − m ) × ( n − i ) n − 1 r_{i}=1-\frac{(1-m)\times (n-i)}{n-1} ri=1−n−1(1−m)×(n−i)
上式中, m m m表示最小的缩放比例,是一个超参数,取值范围为(0,1],本文取m=0.5。n为最终输出多少个尺度的分割结果,文章设为6。
四、损失函数的定义
损失函数的定义如下:
L = λ L c + ( 1 − λ ) L s L=\lambda L_{c}+(1-\lambda)L_{s} L=λLc+(1−λ)Ls
其中, L c L_{c} Lc表示没有进行缩放时候的损失函数,即相对于原始大小的groundtruth的损失函数, L s L_{s} Ls表示的是相对于缩放后的框的损失函数。
关于损失函数文章没有采用交叉熵而是采用的分割常用的dice coefficient,使用公式表示如下
D ( S i , G i ) = 2 ∑ x , y ( S i , x , y ∗ G i , x , y ) ∑ x , y S i , x , y 2 + ∑ x , y G i , x , y 2 D(S_{i}, G_{i})=\frac{2\sum_{x,y}(S_{i,x,y}*G_{i,x,y})}{\sum_{x,y}S^{2}_{i,x,y}+\sum_{x,y}G^{2}_{i,x,y}} D(Si,Gi)=∑x,ySi,x,y2+∑x,yGi,x,y22∑x,y(Si,x,y∗Gi,x,y)
上式中 S i , x , y S_{i,x,y} Si,x,y和 G i , x , y G_{i,x,y} Gi,x,y分别表示在位置(x,y)处分割结果 S i S_{i} Si和groundtruth G i G_{i} Gi的值。
文章使用了OHEM的方法,对于OHEM给出的训练mask为M的情况下, L c L_{c} Lc的计算方法如下:
L c = 1 − D ( S n ⋅ M , G n ⋅ M ) L_{c}=1-D(S_{n}\cdot M, G_{n}\cdot M) Lc=1−D(Sn⋅M,Gn⋅M)
因为其他缩小框的分割结果会被原始大小的框包围,文章说为了避免冗余,在计算缩小框的损失函数时去除了 S n S_{n} Sn结果中为非文本的区域,所以 L s L_{s} Ls计算方式如下:
L s = 1 − ∑ i = 1 n − 1 D ( S i ⋅ W , G i ⋅ W ) n − 1 L_{s}=1-\frac{\sum^{n-1}_{i=1}D(S_{i}\cdot W, G_{i}\cdot W)}{n-1} Ls=1−n−1∑i=1n−1D(Si⋅W,Gi⋅W)
其中
W x , y = { 1 , i f S n , x , y ≥ 0.5 ; 0 , o t h e r w i s e W_{x,y}=\left \{ \begin{array}{lr} 1, if \quad S_{n,x,y} \ge0.5; \\ 0,\quad otherwise\end{array} \right. Wx,y={1,ifSn,x,y≥0.5;0,otherwise
上式中S_{n,x,y}表示在 S n S_{n} Sn中像素(x,y)的值。
到这里这篇文章就讲完了。
中文本定位与识别的评测方法
欢迎加入OCR交流群:785515057(此群已满)
欢迎加入OCR交流群2:826714963