Redis cluster配置
环境:
三台CentOS7.6,redisa-10.3.8.235,redisb-10.3.8.236,redisc-10.3.8.237
生产环境中redis集群要6台机器,分别是3台master及它的备份机器。这里在虚拟机上测试,一台master的备份在另一台master上,这样挂掉一台机器时,集群仍然能正常运转。
$ cat > /etc/hosts <
::1 localhost
10.3.8.235 redisa redisa.example.com
10.3.8.236 redisb redisb.example.com
10.3.8.237 redisc redisc.example.com
EOF
配置免密登录
ssh-keygen
ssh-copy-id redisb
ssh-copy-id redisc
echo ‘vm.overcommit_memory = 1
net.core.somaxconn = 2048’ >> /etc/sysctl.d/redis.conf
sysctl -p
yum install gcc-c++ tcl
wget http://download.redis.io/releases/redis-stable.tar.gz
tar zxf redis-stable.tar.gz -C /usr/local/src/
cd /usr/local/src/redis-stable/
make -j 2
如果报错:
zmalloc.h:50:31: fatal error: jemalloc/jemalloc.h: No such file or directory
#include
解决方法:
先make distclean再尝试make,还不行就加个参数:make -j 2 MALLOC=libc
推荐运行test:
make test
出现\o/ All tests passed without errors!就表示没问题了。
make install
说明:make命令执行完成编译后,会在src目录下生成6个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-check-aof、redis-check-rdb、redis-sentinel。执行make install,会将这6个可执行文件拷贝到/usr/local/bin目录下。
创建/etc/redis目录,把配置文件以port.conf形式放在此目录下,以符合启动文件中的配置。
mkdir /etc/redis
cp /usr/local/src/redis-stable/redis.conf /etc/redis/6379.conf
cp /usr/local/src/redis-stable/redis.conf /etc/redis/6380.conf
mkdir -p /var/redis-cluster/{6379,6380}
$ vi /etc/redis/6379.conf
#bind 127.0.0.1
protected-mode no
port 6379
daemonize yes
cluster-node-timeout 5000
cluster-enabled yes
cluster-config-file nodes.conf
requirepass Redis+234]
masterauth Redis+234]
maxmemory 1073741824 # 最大内存使用量:1GB,最多32G,一般不超过物理内存3/4
maxmemory-policy volatile-lru #根据LRU算法生成的过期时间来删除键值对
dir /var/redis-cluster/6379
appendonly yes
创建6380.redis
cp /etc/redis/{6379.conf,6380.conf}
sed -i “s/6379/6380/g” /etc/redis/6380.conf
创建redis启动文件
cp /usr/local/src/redis-stable/utils/redis_init_script /etc/init.d/redis-6379
cp /usr/local/src/redis-stable/utils/redis_init_script /etc/init.d/redis-6380
sed -i “s/6379/6380/g” /etc/init.d/redis-6380
sed -i ‘/# Description/i# chkconfig: 2345 90 10’ /etc/init.d/redis-63*
chkconfig --add redis-6379
chkconfig redis-6379 on
/etc/init.d/redis-6379 start
chkconfig --add redis-6380
chkconfig redis-6380 on
/etc/init.d/redis-6380 start
注意文件redis_init_script中指定的配置文件是/etc/redis/${REDISPORT}.conf
ps -ef | grep redis
root 15511 1 0 17:15 ? 00:00:00 /usr/local/bin/redis-server *:6379 [cluster]
root 15519 1 0 17:15 ? 00:00:00 /usr/local/bin/redis-server *:6380 [cluster]
部署到另外两台机器:
$ vi depoly.sh
#!/bin/bash
nodes=('redisb' 'redisc')
for ip in ${nodes[@]}; do
scp /etc/hosts $ip:/etc/hosts
scp /etc/sysctl.d/redis.conf $ip:/etc/sysctl.d/redis.conf
scp /usr/local/bin/redis-* $ip:/usr/local/bin/
ssh $ip "mkdir -p /etc/redis && mkdir -p /var/redis-cluster/{6379,6380} && sysctl -p"
scp /etc/redis/*.conf $ip:/etc/redis/
scp /etc/init.d/redis-63* $ip:/etc/init.d/
ssh $ip "chkconfig --add redis-6379 && chkconfig redis-6379 on && /etc/init.d/redis-6379 start"
ssh $ip "chkconfig --add redis-6380 && chkconfig redis-6380 on && /etc/init.d/redis-6380 start"
ssh $ip "ps -ef | grep redis | grep -v grep"
done
执行脚本:
$ bash deploy.sh
三台机器启动完成后,再将每台机器的6380配置为另一台机器的从redis,如下图所示:
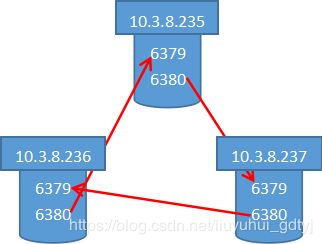
每台机器的redis副本都在另一台机器上,这样可容忍一台机器故障。
创建不含slave的集群:
redis-cli -a Redis+234] --cluster create 10.3.8.235:6379 10.3.8.236:6379 10.3.8.237:6379 --cluster-replicas 0
手动指定从节点
使用上一步创建时产生的cluster-master-id或者运行redis-cli -a 密码 --cluster check 10.3.8.235:6379查看cluster-master-id,然后挂载slave节点:
redis-cli -a Redis+234] --cluster add-node 10.3.8.235:6380 10.3.8.235:6379 --cluster-slave --cluster-master-id 9781aecc4ca8233c7b4098398ee6768aba75795d
解析:10.3.8.235:6380→10.3.8.237:6379,cluster-master-id=9781aecc4ca8233c7b4098398ee6768aba75795d
redis-cli -a Redis+234] --cluster add-node 10.3.8.236:6380 10.3.8.235:6379 --cluster-slave --cluster-master-id 12561183bd3ce3a616e77cc9a602f40caabafbd7
解析:10.3.8.236:6380→10.3.8.235:6379,cluster-master-id=12561183bd3ce3a616e77cc9a602f40caabafbd7
redis-cli -a Redis+234] --cluster add-node 10.3.8.237:6380 10.3.8.235:6379 --cluster-slave --cluster-master-id 2f4d859bb9c9a4fc6692446a0aa958f2b1123e56
解析:10.3.8.237:6380→10.3.8.236:6379,cluster-master-id=2f4d859bb9c9a4fc6692446a0aa958f2b1123e56
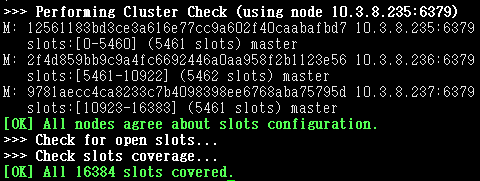
检查集群状态
redis-cli -c -h 10.3.8.235 -p 6379 -a Redis+234]

查看数据目录:
$ ls /var/redis-cluster/63*
/var/redis-cluster/6379:
appendonly.aof dump.rdb nodes.conf
/var/redis-cluster/6380:
appendonly.aof dump.rdb nodes.conf
故障测试:
关闭10.3.8.237的网络连接,然后连接到10.3.8.236:6379上查看集群节点。
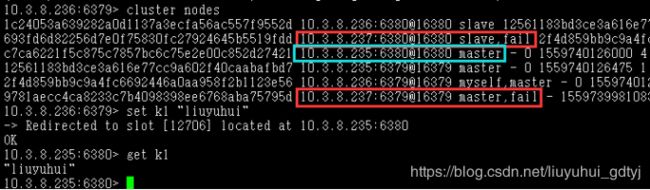
由于10.3.8.237关闭了网络连接,所以红色所示部分都是fail,但是10.3.8.237的从库在10.3.8.235:6380,所以这个从库现在提升为主库了,蓝色所示。最后创建一个key并能查询到,证实redis-cluster的成功。
现在恢复10.3.8.237的网络连接,随后登录redis查看节点信息如下:

可以看到10.3.8.237:6379是从库,而主库是10.3.8.235:6380。这样10.3.8.235上就有两个主库了,这样显然不合适。这时只要登录从库10.3.8.237:6379,执行cluster failover命令即可互换主从关系。
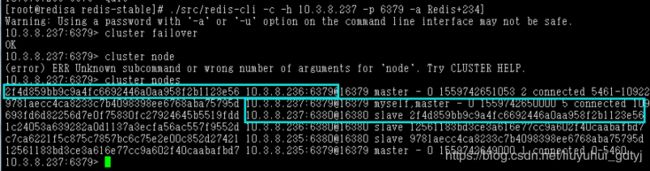
可见,10.3.8.237恢复到之前的主从关系了。
该命令只能在群集slave节点执行,让slave节点进行一次人工故障切换。
人工故障切换是预期的操作,而非发生了真正的故障,目的是以一种安全的方式(数据无丢失)将当前master节点和其中一个slave节点(执行cluster-failover的节点)交换角色。
参考:http://www.redis.cn/commands/cluster-failover.html
删除节点命令就是redis-cli --cluster del-node host:port node_id,node_id可以通过命令cluster nodes查看。
删除所有从节点:
redis-cli -a Redis+234] --cluster del-node 10.3.8.235:6379 693fd6d82256d7e0f75830fc27924645b5519fdd
redis-cli -a Redis+234] --cluster del-node 10.3.8.235:6379 1c24053a639282a0d1137a3ecfa56ac557f9552d
redis-cli -a Redis+234] --cluster del-node 10.3.8.235:6379 c7ca6221f5c875c7857bc6c75e2e00c852d27421
如果要删除集群重新配置,一般步骤如下:
停止所有redis进程:
kill -9 $(ps -ef | grep redis-server | grep -v “grep” | awk ‘{print $2}’)
删除/var/redis-cluster/端口号/内所有文件。
欢迎转载~~